







数据库模式
三级模式两级映射:
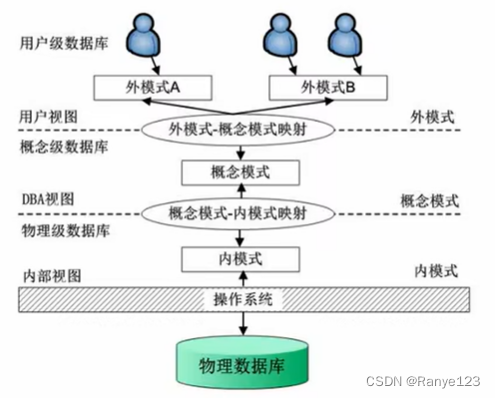
三级模式:
- 内模式:和物理数据库直接关联,管理如何存放数据
- 概念模式:数据库的表
- 外模式:数据库的视图,应用程序调用的是视图,这样表变化了不影响应用程序调用
两级映射:
- 概念模式-内模式映射
- 外模式-概念模式映射
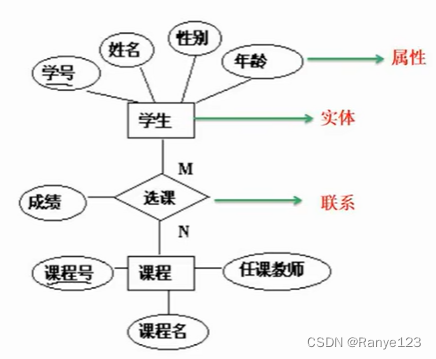
ER 模型
用于概念结构设计
方框:实体
椭圆:属性
菱形:联系
把局部 ER 图合成全局 ER 图的方式
- 多个局部 ER 图一次集成
- 逐步集成,用累加的方式一次集成两个局部 ER 图
集成产生的冲突
- 属性冲突
- 命名冲突
- 结构冲突
- 不同抽象级别上的冲突:如“老师”,既是一个表,又是另一张表上的一个字段
- 同一实体在不同局部 ER 图中所包含的属性不同
ER 模型转关系模式
关系模式的格式类似于:
教师(性别,职工号,手机号,年龄,姓名)
班级(班级名称,班级号)
负责(职工号,班级号)
原则:
- 一个
实体转成一个关系模式 - 1:1 的
联系,既可以将它单独作为一个关系模式,也可以将它合并到任意一个实体中 - 1:n 的
联系,既可以将它单独作为一个关系模式,也可以将它合并到 n 那边的实体中(如部门-员工,在员工那边加一个部门名称字段) - n:m 的
联系,必须将它单独作为一个关系模式
关系代数与元组演算
关系代数的基本运算:
- 并
- 交
- 差
- 笛卡尔积
- 投影:选列
- 选择:选行
- 联接:共有的字段,要都一样
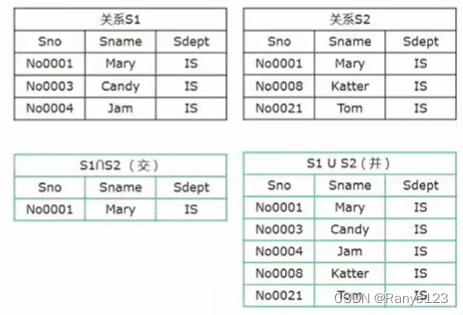
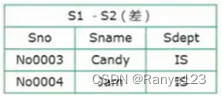
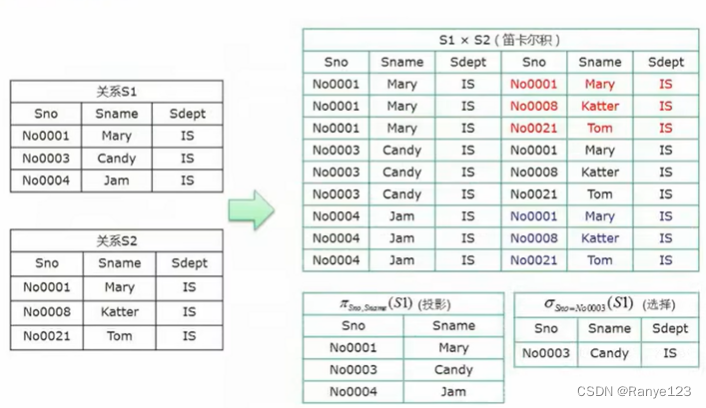
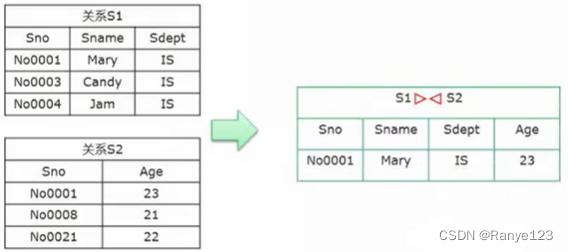
在联接之后选择只显示第 1,2,4 列: Π 1 , 2 , 4 ( S 1 ⋈ S 2 ) \Pi_{1,2,4}(S1⋈S2) Π1,2,4(S1⋈S2)
规范化理论
函数依赖
X
→
Y
X\rightarrow Y
X→Y(X 函数决定 Y / Y 函数依赖 于 X):X 和 Y 的关系像函数一样,知道 X 可以确定 Y
如
学号
→
姓名
学号\rightarrow 姓名
学号→姓名
部分函数依赖:
如
(
学号
,
课程号
)
→
姓名
(学号,课程号)\rightarrow 姓名
(学号,课程号)→姓名,但是也有
学号
→
姓名
学号\rightarrow 姓名
学号→姓名,所以称
姓名
姓名
姓名部分依赖于
(
学号
,
课程号
)
(学号,课程号)
(学号,课程号)
传递函数依赖:知道 A 可以确定 B,知道 B 可以确定 C,则知道 A 可以确定 C
价值与用途
解决以下问题:
- 数据冗余:专业 id,专业名同时出现在一个表上
- 更新异常:更新专业名,专业 id 却没有同步更新
- 插入异常:两个属性的组合作为主键,若两个属性中的一个还没有明确,无法插入数据
- 删除异常:两个属性的组合作为主键,若两个属性中的一个还没有明确,无法删除数据
键
- 超键:能够唯一标识元组,可以是单个属性也可以是属性组合
- 候选键:与超键功能相同,不同的是超键可能存在冗余属性,超键消除冗余属性就是候选键
- 主键:从候选键中任选一个成为主键
- 外键:其他关系的主键
题型 1:图示法求候选键
- 将关系模式的函数依赖关系用有向图的方式表示
- 以
入度为 0 的属性集合为起点,遍历有向图- 若能遍历,则该属性集即为关系模式的候选键
- 若不能,尝试将其他结点并入该集合中,直至能遍历为止,此时集合为候选键
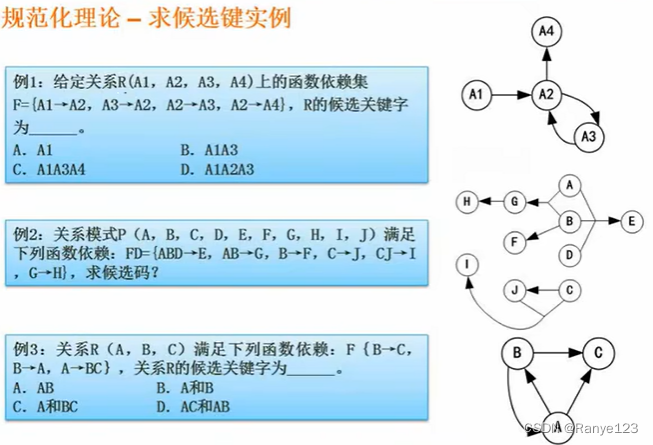
A ABCD B
范式
要达到第二范式,必先达到第一范式,以此类推
- 1NF:属性值都是不可分的原子值(一个属性不能拆分成几个属性)
- 2NF:消除
非主属性对候选键的部分依赖 - 3NF:消除
非主属性对候选键的传递依赖 - BCNF:消除
主属性对候选键的传递依赖
目的:解决
- 插入异常
- 删除异常
- 数据冗余
1NF
2NF
如一张表:课程号,学号,成绩,学分,主键是(课程号,学号)
但是学分是可以由课程号单独决定的,部分依赖于主键,不满足 2NF
带来的问题:
- 数据冗余:学分被存了多次
- 更新异常:学分被存了多次,要更新得全部更新,只更新部分会出问题
- 插入异常:考虑一门课程暂时没人选,但是需要将其学分录入进去,这时候是录入不进去的,因为学号也是主键的一部分
- 删除异常:学生毕业,将所有信息删除,同时学分的信息也被删除了
解决方案:
将课程号和学分独立出来作为一个新的关系模式
主键为单属性一定满足 2NF
3NF
如一张表:学号,姓名,系号,系名,主键是学号
系名是由系号决定的,系号是由学号决定的,所以是传递关系依赖
- 数据冗余:系名被存了多次
- 更新异常:系名被存了多次,要更新得全部更新,只更新部分会出问题
- 插入异常:没有学生的情况下,想将系名信息录入,这时候是录入不进去的,因为学号是主键
- 删除异常:学生毕业,将所有信息删除,同时系的信息也被删除了
解决方案:
将系号和系名独立出来作为一个新的关系模式
BCNF
判断是否符合 BCNF:每个依赖关系,被依赖的决定因素必定包含候选码
如一张表:学生,老师,课程,候选键有(学生,老师)、(学生,课程),所以这三个属性都是主属性,没有非主属性
依赖关系如下:
(学生,课程)->老师
老师->课程
其中老师不是候选码,所以不符合 BCNF
模式分解
保持函数依赖分解
在分解后可以保持原先的函数依赖
如
R
(
A
,
B
,
C
)
,
A
→
B
,
B
→
C
R(A,B,C),A\rightarrow B,B\rightarrow C
R(A,B,C),A→B,B→C
拆成
R
1
(
A
,
B
)
、
R
2
(
B
,
C
)
R1(A,B)、R2(B,C)
R1(A,B)、R2(B,C)
在 R1 里仍然有
A
→
B
A\rightarrow B
A→B,R2 里仍然有
B
→
C
B\rightarrow C
B→C,原先的函数依赖被保留了
无损分解
分解后可以还原
无损联接分解
可以通过自然联接和投影运算还原到原来的关系模式
并发控制
事务
- 原子性
- 一致性:事务执行前执行后一致,如转帐前后双方钱总数一致
- 隔离性:事务之间互不影响
- 持续性:事务执行结果的影响是持续的
并发产生的问题
丢失更新
假如有 T1、T2 同时更新一个值 x,顺序是(T1 取数、T2 取数、T1 更新、T2 更新) T2 拿到的初始值不是被 T1 更新后的,而是原始的 x,那 T1 对其更新就被覆盖了
不可重复读
T1 有计算和验算两个步骤,若 T2 在计算与验算之间修改了值,那计算和验算的结果就不同了,发生错误
读“脏”数据
脏数据指计算过程中的临时值,不是真正应该被读的数据
解决协议
X 锁:写锁 & S 锁:读锁
S 本意是共享锁,本意 X 是排他锁
加了 S 锁之后还能继续加 S 锁,但是不能加 X 锁
加了 X 锁之后什么锁都不能加
一级封锁协议
事务 T 在 修改 数据 R 之前必须先对其加 X 锁,直到事务结束才释放
- 防止丢失更新
二级封锁协议
在一级封锁协议的基础上,在 读取 数据 R 之前先对其加 S 锁,读完 才释放
- 防止丢失更新
- 防止读“脏”数据
三级封锁协议
在一级封锁协议的基础上,在 读取 数据 R 之前先对其加 S 锁,事务结束 才释放
- 防止丢失更新
- 防止读“脏”数据
- 防止数据重复读
两段锁协议
可串行化,可能发生死锁
产生的新问题
两段锁协议可能产生死锁问题
解决方法:
- 死锁的预防
- 死锁的解除
数据库完整性约束
目的:提升数据的可靠性
实体完整性约束
数据表主键不能为空,不能重复
参照完整性约束
外界对数据库表的完整性约束,外键的值必须属于对应的表主键的内容(也可以为空,但是不能填错误的值)
用户自定义完整性约束
用户可以自定义某个属性的值的要求
触发器
写脚本来定义对于某属性的要求
数据库安全
用户标识和鉴定
存取控制
对不同用户进行不同授权
密码存储和传输
视图的保护
不同权限的用户可以使用不同的视图
审计
将用户对数据库的所有操作记录下来,对这些操作进行分析
分布式数据库
数据备份
冷备份 vs 热备份
- 冷备份(静态备份):在数据库
停止状态下,将数据库的文件全部备份(复制)下来- 优点:简单,速度快,低度维护,高度安全
- 缺点:业务会暂停,无法精确到表
- 热备份(动态备份):在数据库
运行状态下,将数据库的数据文件备份出来- 优点:灵活(可精确地恢复/备份某一个表),速度快
- 缺点:复杂度高,不能出错(因为正在跑业务)
完全备份 vs 增量备份 vs 差量备份
- 完全备份:备份所有数据
- 增量备份:备份上一次
备份后变化的数据 - 差量备份:备份上一次
完全备份后变化的数据
静态海量转储 vs 静态增量转储 vs 动态海量转储 vs 动态增量转储
静态:在系统中无运行事务时进行
动态:转储期间允许对熟即可进行存取
海量:转储全部数据库
增量:只转储上一次转储后更新的数据
转储:备份
- 静态海量转储:
- 静态增量转储:
- 动态海量转储:
- 动态增量转储:
日志文件
记录针对数据库的任何操作
数据库故障与恢复
| 故障 | 恢复 |
|---|---|
| 事务本身可预期的故障(本身逻辑) | 在程序中预先设置 Rollback 语句 |
| 事务本身不可预期的故障(溢出、违反存储保护) | 通过日志回滚到事务初始状态 |
| 系统故障(系统停止运转) | 检查点法 |
| 介质故障(外存被破坏) | 使用日志重做业务 |
数据仓库与数据挖掘
数据仓库
数据库与数据仓库的区别
数据库是按业务组织数据,数据仓库是按主题组织数据
例:数据库主要负责“购买商品”、“进货”这方面的逻辑,数据仓库则是把所有商品的信息进行汇总
数据仓库的特点
- 面向主题
- 集成的
- 相对稳定的(存进去就不进行修改删除操作)
- 反映历史变化(隔一段时间会把新的数据导入进来)
组织数据仓库
- 数据源到数据仓库
- 抽取
- 清理:统一数据格式,去重,去冗余
- 装载
- 刷新
- 数据仓库到数据集市
- 数据集市:部门级的数据仓库
- 先分别建立部门级的数据仓库(数据集市),然后整合成企业级的数据仓库
- 数据集市到 OLAP 服务器
- OLAP 服务器:联机分析处理服务器,做数据的分析处理工作
- OLAP 服务器到前端分析工具
- 查询工具、报表工具、分析工具、数据挖掘工具等
数据挖掘
数据挖掘是挖掘出数据之间的潜在联系
数据挖掘方法分类
方法:
- 决策树
- 神经网络
- 遗传算法
- 关联规则挖掘算法
分类:
- 关联分析:数据间的潜在关系
- 序列模式分析:数据间的前后(因果)关系
- 分类分析:根据类别将数据打 tag
- 聚类分析:由多个个体的共性聚合成类别,分类分析的逆过程
反规范化
为何出现反规范化:
规范化会使得表不断拆分,增加查询的工作量(系统需要多次连接才能查询),系统效率下降
目的:提高查询效率
反规范化技术
- 增加派生性冗余列
- 在有
数量、单价列的情况下,仍然加上总销售额这一列
- 在有
- 增加冗余列
- 原本是(学号,课程号,成绩)+(学号,姓名)+(课程号,课程名),增加为(姓名,学号,课程号,课程名,成绩)
- 重新组表
- 分割表
- 垂直分割,水平分割
大数据
对海量数据处理相关的技术
海量数据的特点:
- 数据量大
- 要求处理速度快
- 多样性高
- 有一定价值
大数据 vs 传统数据
| 比较维度 | 传统数据 | 大数据 |
|---|---|---|
| 数据量 | GB/TB | PB |
| 数据分析需求 | 现有数据的分析与预测 | 深度分析 |
| 硬件平台 | 高端服务器 | 集群平台 |
大数据处理系统应有的特征
- 高性能
- 低成本
- 高扩展性
- 高容错性
…















 854
854











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









