







BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
0.摘要
BERT的设计目的是通过在所有层中联合调节左右上下文,从未标记的文本中预训练深度双向表示。模型在概念性更加简单,结构性更加有力。结果在各方面特别好
1.介绍
语言模型预训练在改善很多自然语言处理过程任务时候很高效,包括两类任务,一类句子层面任务,另一类词层面任务。在使用预训练模型做特征表示的策略有两类,一种是基于特征的,一种是基于微调的。基于特征就是把学习好的特征和输入一起组成新的输入。基于微调的就是把预训练好的模型不需要改动太多放在下游任务,模型训练好的参数会根据下游的数据进行微调。这两种都使用相同的目标函数。
当前的技术具有局限性,因为当前的技术都是单向的,如果我在句子层面的分析时,从左到右和看完全部都可以,如果我们把这两结合可以得到一个更好的输入,因此提出了BERT。基本思想就是我们每次随机选一些词元进行覆盖,使用目标函数来预测那些被掩盖的字,类似于完形填空。另外一个任务是下一个句子的预测。
三点贡献:
- 展示了双向信息的重要性
- BERT是第一个基于微调的预训练模型
- 提供了代码和模型
BERT=ELMo双向的想法+GPT的transformer
2.相关工作
-
基于非监督的基于特征的工作
-
基于非监督的基于微调的工作
-
在有标号的数据上做迁移学习
3. BERT算法
两个任务:预训练和微调
在预训练任务中,模型在没有标记的数据上训练来完成不同的预训练任务。对于微调来说,BERT首先被预训练参数初始化,但是对每一个下游任务都会根据自己的数据训练自己的额模型。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xNp4XnXp-1668409262250)(C:\Users\zym\AppData\Roaming\Typora\typora-user-images\image-20221114105345421.png)]](https://img-blog.csdnimg.cn/7b10529446e6409fb4076a564e23ed13.png)
BERT模型是双层的双向的transformer编码器。我们有三个参数,L(层数),H(隐藏层大小),A(多头注意力的头的个数)。BERT base(L=12, H=768, A=12, Total Parameters=110M)和BERT large(L=24, H=1024,A=16, Total Parameters=340M)。
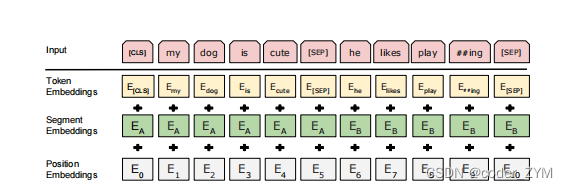
输入可以是一个句子也可以是一个句子对。我们引入了WordPiece来切词。每个句子的第一个词是一个CLS。BERT希望他最后的输出代表的是一个序列的输出,代表句子层面的信息。因为放入的是句子对,那么我们引入了SEP来划分句子,放在每个句子的后面。然后我们学习一个嵌入层来表示这个句子是第一个句子还是第二个句子。对于给定的token,他的输入形式是这个词本身的embedding加上句子的embedding加上位置的embedding。
3.1预训练BERT
任务1:
如果输入的是一个WordPiece序列,他有15% 的概率被替换成一个掩码MSK,但是对于特殊词元如CLS,SEP就不进行替换。因为在预训练的时候存在15%MSK,但是在微调时候我们不适用MSK,那么就会导致预训练和微调所看到的数据存在差异。对此我们引入了一个策略就是,我们在替换MSK的时候,我对MSK有80%的概率真的替换MSK,10%替换成随机词元,10%什么都不做。
e.g.
- 80%: My dog is hairy My dog is MSK
- 10%: My dog is hairy My dog is apple
- 10% :My dog is hairy My dog is hairy
**任务2:**下一个句子预测(NSP)
因为输入的是句子对,所以要预测句子在文章中的位置。在AB句子对之中,B有50%真的出现在A的后面,有50%的概率来自原文的其他位置。
3.2 BERT微调
BERT使用了注意力机制来统一两个阶段。每一个任务,我们只是简单的把特定的输入和输出输入到BERT中来进行微调。具体如何构建输入输出会在第四节进行详细介绍。
4.实验
使用了四个数据集,这些数据集已经有了对应的输入和输出,只需要拿过来直接微调,不多叙述。
5. 可供学习的地方
5.1预训练任务的影响
当我们不使用下一个句子预测或者采用从左到右访问(不使用双向)加上不使用下一个句子预测都会对结果的精度产生影响
5.2 模型大小的影响
当模型越大对NLP的效果越好。
5.3 基于特征的方式的BERT
效果没有使用微调的好。
6.结论
最近的一些实验表明使用非监督的预训练是非常好的,这样子可以在数据不多的情况下也能够享受深度神经网络,我们的贡献是把前人的结果拓展到深的双向架构上,使得同样的预训练模型可以处理大量的自然语言处理任务。
补充
样子可以在数据不多的情况下也能够享受深度神经网络,我们的贡献是把前人的结果拓展到深的双向架构上,使得同样的预训练模型可以处理大量的自然语言处理任务。
补充
使用双向的缺点:不能适用于机器翻译。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









