







 正则表达式,又称正规表达式、常规表达式,使用字符串来描述、匹配一些列符合某个规则的字符串正则表达式是由普通字符与元字符组成普通字符包括大小写字母、数字、标点符号及一些其他符号元字符是指在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符)在目标对象中的出现模式Linux 中常用的有两种正则表达式引擎基础正则表达式:BRE扩展正则表达式: EREBRE——Basic Register Express 基本的正则表达式作用基础正则表达式常见元字符如下:注意:egrep、
正则表达式,又称正规表达式、常规表达式,使用字符串来描述、匹配一些列符合某个规则的字符串正则表达式是由普通字符与元字符组成普通字符包括大小写字母、数字、标点符号及一些其他符号元字符是指在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符)在目标对象中的出现模式Linux 中常用的有两种正则表达式引擎基础正则表达式:BRE扩展正则表达式: EREBRE——Basic Register Express 基本的正则表达式作用基础正则表达式常见元字符如下:注意:egrep、
正则
文章目录
引言:
正则表达式,又称规则表达式(Reqular Expression)。正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本,正则表达式不只有一种,而且 Linux 中不同的程序可能会使用不同的正则表达式。
一.正则表达式定义
正则表达式,又称正规表达式、常规表达式,使用字符串来描述、匹配一些列符合某个规则的字符串
正则表达式是由普通字符与元字符组成
普通字符包括大小写字母、数字、标点符号及一些其他符号
元字符是指在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符)在目标对象中的出现模式
Linux 中常用的有两种正则表达式引擎
基础正则表达式:BRE
扩展正则表达式: ERE
二.正则表达式元字符
1.基础正则表达式元字符
BRE——Basic Register Express 基本的正则表达式
作用
- 匹配字符
- 匹配字数
- 位置锚定
基础正则表达式常见元字符如下:
| 元字符 | 作用 |
|---|---|
| \ | 转义字符,用于取消特殊符号的含义 |
| ^ | 尖角符,匹配字符串开始的位置 |
| $ | 美元符,匹配字符串结束的位置 |
| ^$ | 组合符,匹配空行 |
| . | 匹配除\n、\r之外的任何一个字符 |
| * | 匹配前面子表达式0次或多次,重复0次代表空,即匹配所有内容 |
| .* | 组合符,匹配所有内容 |
| ^.* | 组合符,匹配任意多个字符开头的内容 |
| .*$ | 组合福,匹配人鱼多个字符结尾的内容 |
| [list] | 匹配list列表中的一个字符,例:[abc]匹配a或b或c,也可写[a-c] |
| [^list] | 匹配任意非列表中的一个字符,表示取反。 |
注意:egrep、awk使用{}匹配时不用加\转义
2.扩展正则表达式元字符
ERE一Extend Register Express扩展的正则表达式
扩展正则表达式元子符如下:
ERE集合
| 元字符 | 作用 |
|---|---|
| + | 匹配前面子表达式一次或多次 |
| ? | 匹配前面子表达式0次或一次 |
| () | 分组过滤,将括号内的字符作为一个整体 |
| 丨 | 以或的方式匹配字符条串 |
| [😕]+ | 匹配括号内的":"或者“/”字符1次或多次 |
| a{n} | 匹配前面一个字符正好n次 |
| a{n,} | 匹配前一个字符最少n次 |
| a{,m} | 匹配前一个字符最多m次 |
| a{n,m} | 匹配前一个字符n到m次 |
==注意:==扩展正则必须用grep -E才能生效
3.单引,双引和反撇等一些符号的区别
单引号变量和命令都不识别,当成了普通的字符串
双引号弱引用,不能识别命令,可以识别变量
反撇号 可以执行的一个结果,里面放的是命令的集合=$()
${} 引用变量
$[] 运算
[[]] 运算 处理逻辑命令 处理字符串是否相等
(()) 比较数字、支持变量计算(且不用转义<>、 计算的时候运算符与数字之间不能有空格)
$0 脚本名字 $1 位置变量 $n(n表示数字)
$# 个数 $* 一个字符串 $@ 单个字符串
4.脚本的思路
1、明确脚本的功能 分析脚本的作用
2、编写脚本时会使用到哪些命令?awk sed useradd find
3、把变化的数据使用变量表示
4、选择合适的流程控制语句 (循环、分支(单多))
grep
全拼:Global search REgular expression and Print out the line.
作用:文本搜索工具,根据用户指定的“模式(过滤条件)”对目标文本逐行进行匹配检查,打印匹配到的行
模式:由正则表达式的元字符及文本字符所编写出的过滤条件;
语法:
grep[options] [pattern] file
命令 参数 匹配模式 文件数据
-a --text # 不要忽略二进制数据。
-A <显示行数> --after-context=<显示行数> # 除了显示符合范本样式的那一行之外,并显示该行之后的内容。
-b --byte-offset # 在显示符合范本样式的那一行之外,并显示该行之前的内容。
-B<显示行数> --before-context=<显示行数> # 除了显示符合样式的那一行之外,并显示该行之前的内容。
-c --count # 计算符合范本样式的列数。
-C<显示行数> --context=<显示行数>或-<显示行数> # 除了显示符合范本样式的那一列之外,并显示该列之前后的内容。
-d<进行动作> --directories=<动作> # 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep命令将回报信息并停止动作。
-e<范本样式> --regexp=<范本样式> # 指定字符串作为查找文件内容的范本样式。
-E --extended-regexp # 将范本样式为延伸的普通表示法来使用,意味着使用能使用扩展正则表达式。
-f<范本文件> --file=<规则文件> # 指定范本文件,其内容有一个或多个范本样式,让grep查找符合范本条件的文件内容,格式为每一列的范本样式。
-F --fixed-regexp # 将范本样式视为固定字符串的列表。
-G --basic-regexp # 将范本样式视为普通的表示法来使用。
-h --no-filename # 在显示符合范本样式的那一列之前,不标示该列所属的文件名称。
-H --with-filename # 在显示符合范本样式的那一列之前,标示该列的文件名称。
-i --ignore-case # 忽略字符大小写的差别。
-l --file-with-matches # 列出文件内容符合指定的范本样式的文件名称。
-L --files-without-match # 列出文件内容不符合指定的范本样式的文件名称。
-n --line-number # 在显示符合范本样式的那一列之前,标示出该列的编号。
-q --quiet或--silent # 不显示任何信息。
-R/-r --recursive # 此参数的效果和指定“-d recurse”参数相同。
-s --no-messages # 不显示错误信息。
-v --revert-match # 反转查找。
-V --version # 显示版本信息。
-w --word-regexp # 只显示全字符合的列。
-x --line-regexp # 只显示全列符合的列。
-y # 此参数效果跟“-i”相同。
-o # 只输出文件中匹配到的部分。
正则grep实践
1、输出所有以n开头的行

2、找出空行

3、输出以o结尾的行

4、找出所有允许登陆的用户,解释器是/bin/bash的行

tips
注意在Liux平台下,所有文件的结尾都有一个$符
可以用cat-A查看文件
5、输出所有有内容的行,不包括空行
. 表示任意一个字符
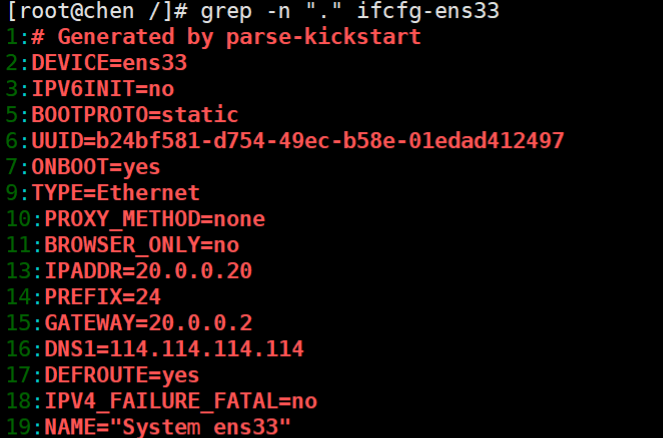
6、匹配任意一个和s连用的行
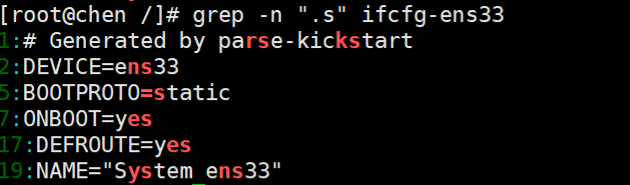
7、转义用法
grep -n -i "\." file
需要用到转义
8、贪婪匹配 .* 用法
grep -n -i ".*e" file
找出任意以e结尾的内容
9、[]中括号用法
[a-z]匹配所有小写单个字母
[A-Z]匹配所有单个大写字母
[a-zA-Z] [a-Z]匹配所有的单个大小写字母
[0-9]匹配所有单个数字
[a-zA-Z0-9]匹配所有数字和字母
扩展用法
egrep=grep -E
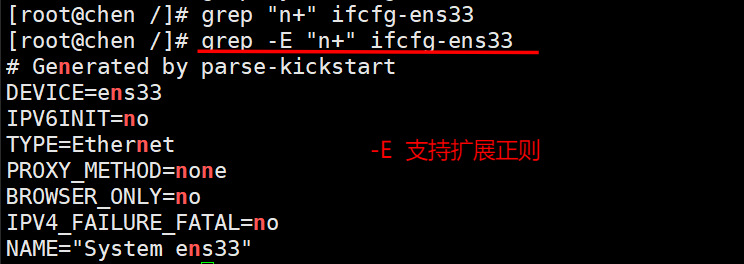
1、匹配n一次或多次
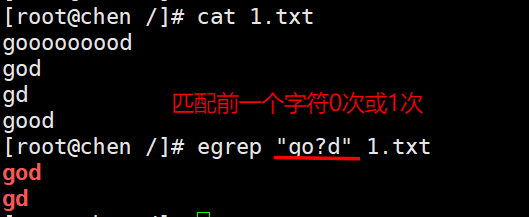
2、匹配0次或1次
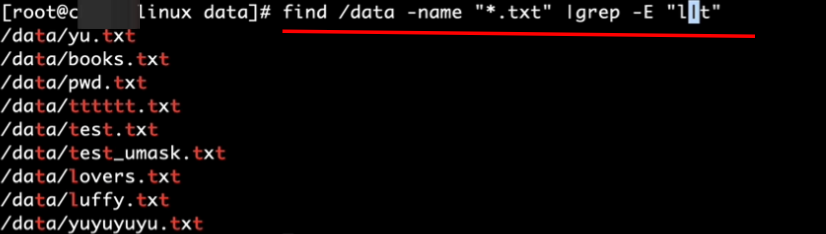
3、找出data目录下的txt文件并且路径里有l或t
4、找出包含good 和 glad 的行

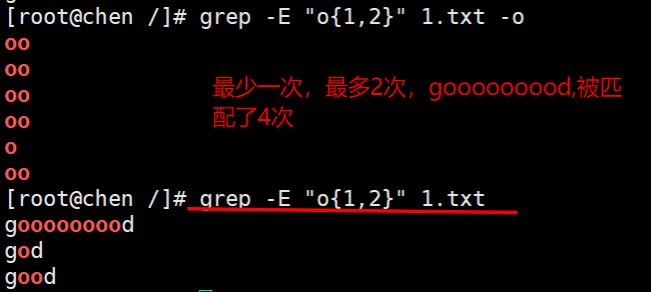
5、匹配次数
sed
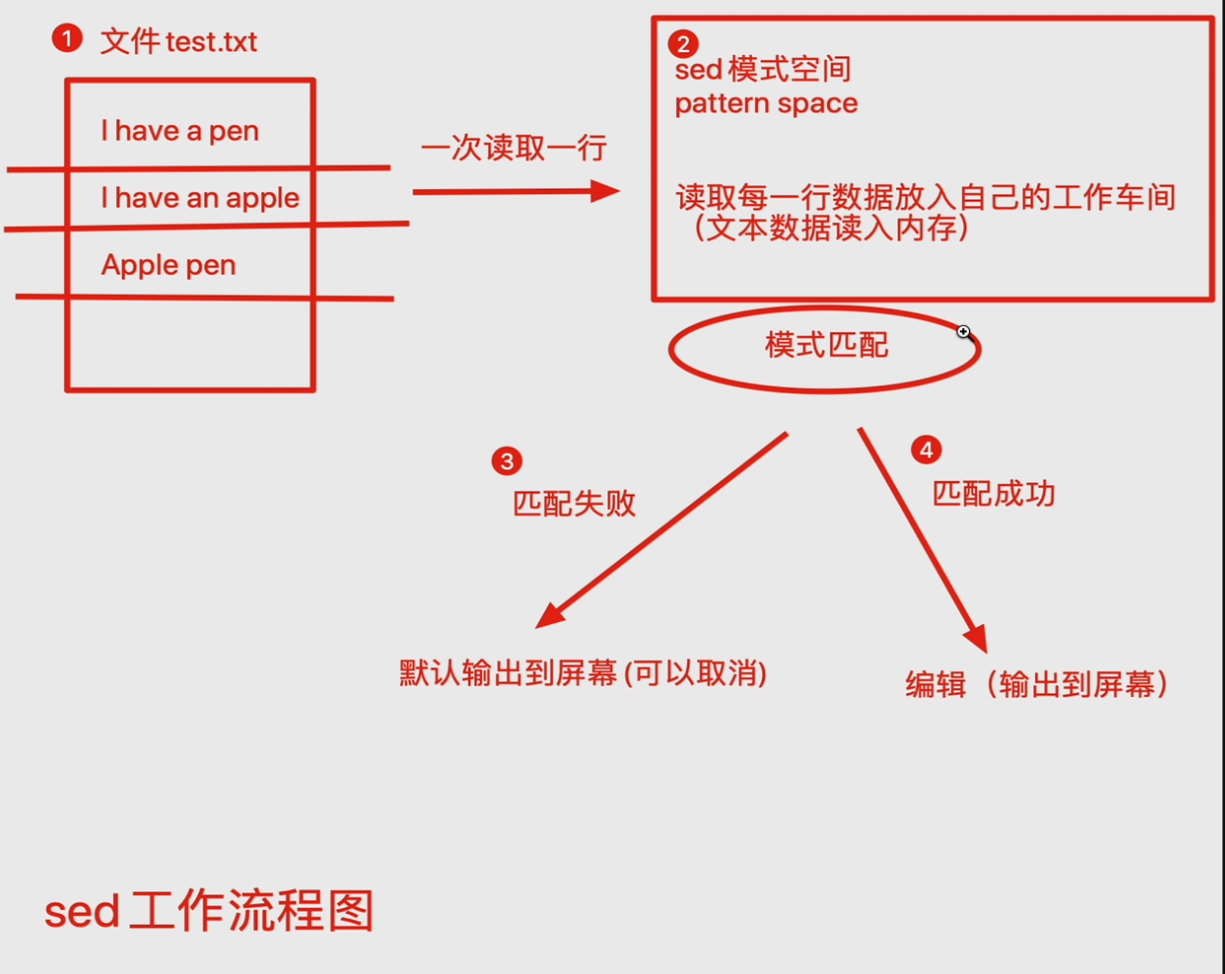
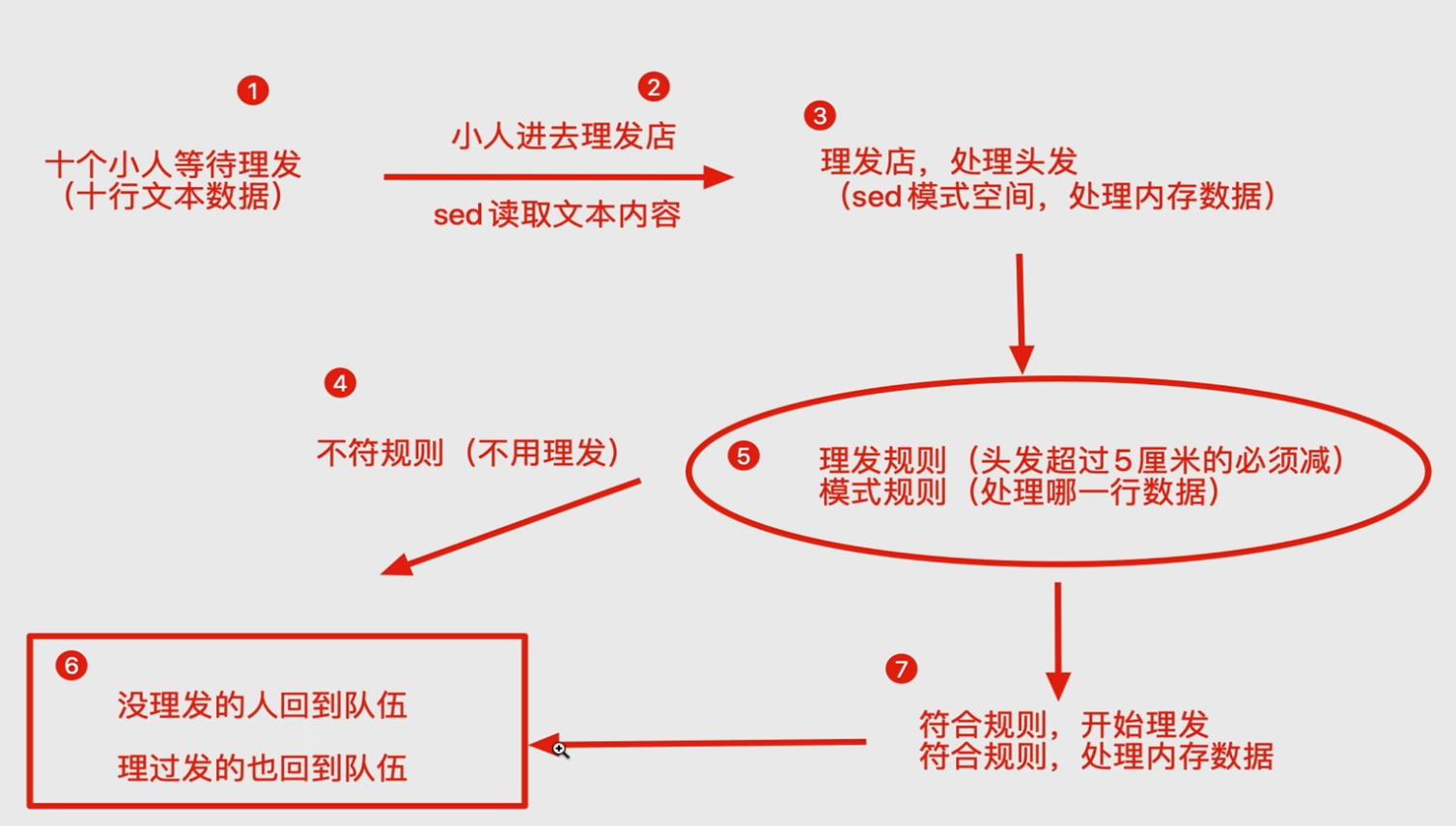
sed是Stream Editor(字符流编辑器)的缩写,简称流编辑器。
sed是操作、过滤和转换文本内容的强大工具。
注意sed和awk使用单引号,双引号有特殊解释
常用功能包括结合正则表达式对文件实现快速增删改查,其中查询的功能中最常用的两大功能是过滤(过滤
指定字符串)、取行(取出指定行)。
语法:
sed [选项] [sed 内置命令字符][输入文件]
| 参数选项 | 解释 |
|---|---|
| -n | 取消默认sed的输出,常与sed内置命令p一起用 |
| -i | 直接将修改结果写入文件,不用-i,sed修改的是内存数据 |
| -e | 多次编辑,不需要管道符了 |
| -r,-E | 支持正则扩展 |
| -f | 表示用指定的脚本文件来处理输入的文本文件。 |
| -s | 将多个文件视为独立文件,而不是单个连续的长文件流 |
sed 内置命令字符用于对文件的增删改查
sed 常用的内置命令提示符
| sed的内置命令字符 | 解释 |
|---|---|
| a | apper,对文本追加,在指定行后面添加一行/多行文本 |
| d | Delete,删除匹配行 |
| i | insert,表示插入文本,在指定行前添加一行/多行文本 |
| p | Print,打印匹配行的内容,通常p与-n一起用 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1808
1808











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









