







最近看一些基本的算法实现,在一些博客上看了快速排序算法,但是看了大多博客在代码实现上都有或多或少的问题出现。
以下是作者对一些博客中快速排序算法的整合。
一.快速排序原理
原理:快速排序算法通过多次比较和交换来实现排序,其排序流程如下
- 首先设定一个分界值,通过该分界值将数组分成左右两部分。
- 将大于或等于分界值的数据集中到数组右边,小于分界值的数据集中到数组的左边。此时,左边部分中各元素都小于或等于分界值,而右边部分中各元素都大于或等于分界值。
- 然后,左边和右边的数据可以独立排序。对于左侧的数组数据,又可以取一个分界值,将该部分数据分成左右两部分,同样在左边放置较小值,右边放置较大值。右侧的数组数据也可以做类似处理。
- 重复上述过程,可以看出,这是一个递归定义。通过递归将左侧部分排好序后,再递归排好右侧部分的顺序。当左、右两个部分各数据排序完成后,整个数组的排序也就完成了。
其中快排的第一步需要找基准点也就是上面所说的分界值。
-
固定基准数
通常的、没有经过充分考虑的选择是将第一个元素做为"基准“。如果输入数是随机的,那么这是可以接受的,但是如果输入是预排序的或是反序的,那么这样的”基准“就是一个劣质的分割,因为所以的元素不是被划入Sort1就是被划入Sort2。实际上,如果第一个元素用作”基准“而且输入是预先排序的,那么快速排序花费的时间将是二次的,可是实际上却没干什么事,因此,使用第一个元素作为”基准“是绝对糟糕的,被称为一种错误的方法。
-
随机基准数
这是一种相对安全的策略。由于基准数的位置是随机的,那么产生的分割也不会总是出现劣质的分割。但在数组所有数字完全相等的时候,仍然会是最坏情况。实际上,随机化快速排序得到理论最坏情况的可能性仅为1/(2^n)。所以随机化快速排序可以对于绝大多数输入数据达到 O(nlogn) 的期望时间复杂度,被成为一种安全的方法。
-
三数中值分割法
一组N个数的中值是第[N/2]个最大的数。”基准“的最好选择是数组的中值。但是这很难算出,且减慢快速排序的速度。这样的中值的估计量可以通过随机选取三个元素并用它们的中值作为”基准”而得到。实际上,随机性并没有多大的帮助,因此一般的做法是使用左端、右端和中心位置上的三个元素的中值作为“基准”。
快速排序的效率跟基准数的选择有很大关系。
如果基准数选得好,每次基准数都能够刚好排在中间的位置,递归的时候,两个子问题的大小就是平衡的,不停地二分下去,最终的时间复杂度就是
T(n)=T(n/2)+T(n/2)+O(n)=O(nlogn)
如果基准数选得差,每次基准数刚好是最大值或者最小值,每次子问题的规模只减小了1,这样无疑效率会差很多,最终的时间复杂度为
T(n)=T(n-1)+T(1)+O(n)=O(n^2)
二.快排实现
作者主要提供两种情况,不同体现在一些细节方面,但是中心思想不变
1.第一种情况

代码如下:
public class QuickSort{
public static void main(String[] args) {
int[] nums = new int[]{6,7,3,6,3,2,1};
new QuickSort().sort(nums,0,nums.length-1);
for (int i = 0; i < nums.length; i++) {
System.out.println(nums[i]);
}
}
public void sort(int[] nums,int left,int right){
if (left < right){
//index是每一次执行每一部分执行排序后的分界
int index = position(nums,left,right);
//分界左边部分进入递归
sort(nums,left,index-1);
//分界右边部分进入递归
sort(nums,index+1,right);
}
}
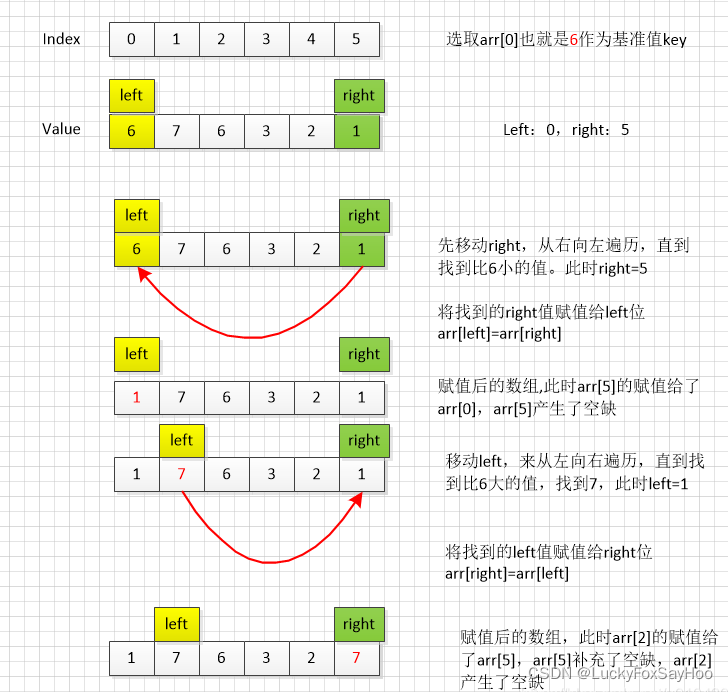
public int position(int[] nums,int left,int right){
//以每部分排序的最左边元素为基准点
//pos用来记录基准值
int pos = nums[left];
while(left < right){
//因为选择了左基准点,为了方便先从右边界开始遍历
//如果找到了比基准大的树且满足left<right的条件进入循环
while(nums[right] > pos && left < right)
right--;
//关键点 具体看上面的图理解
nums[left] = nums[right];
//从左边进行再一次操作
while(nums[left] <= pos && left < right)
left ++;
nums[right] = nums[left];
}
//把基准值放在交换结束后空缺的位置
nums[left] = pos;
//返回下一次空缺索引作为下一次sort的分界
return left;
}
}
执行结果如下

2.第二种情况
- 首先设置第一位为基准值,分别设置left和right两个指针。

- 此时开始遍历,先从右边开始遍历,如果遇到比基准值5小的数停止,使用right记录索引,然后开始左边遍历,遇到比基准值大的数停止,使用left记录索引。如下图

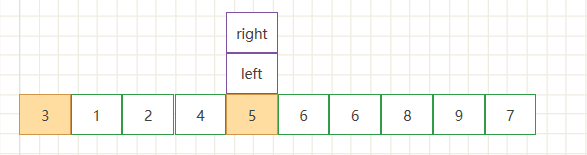
- 此时进行交换索引left和right中的值,然后把left后移,right前移,结果如下图。
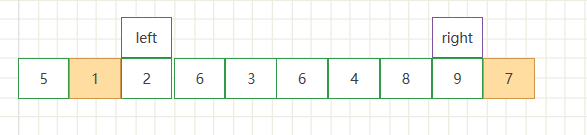
- 继续循环操作,交换节点数据 .此时为第二次交换节点数据
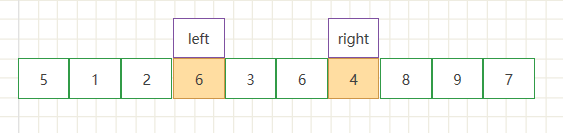
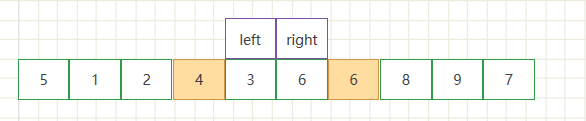
- 直到左右指针相遇停止循环,因为把5当作了基准点,也就是第一次总体交换的分界值,此时要把基准值所处的节点和左右指针所指向的节点进行交换,以保证小的元素在左边、大的元素位于右侧。
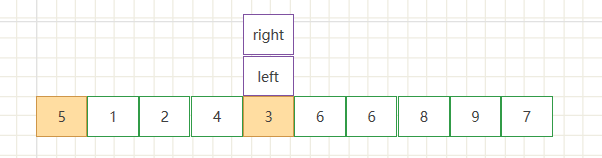
- 到了这一步就是第一次总体的交换结束,可以看到基准值左侧的数字都比基准值小,右侧的数都比基准值大。此时就把数组从left处分为两个部分分别进入递归,每一个部分都重复以上操作。
代码如下
package Test;
/**
* @author Fox
* @date 2022/01/11 22:57
*/
public class QuickSort{
public static void main(String[] args) {
int[] nums = new int[]{5,7,2,6,3,6,4,8,9,1};
new QuickSort().sort(nums,0,nums.length-1);
for (int i = 0; i < nums.length; i++) {
System.out.println(nums[i]);
}
}
public void sort(int[] nums,int left,int right){
if (left < right){
int index = position(nums,left,right);
//分界后递归
sort(nums,left,index-1);
sort(nums,index+1,right);
}
}
//进行两节点的数据交换
public void swap(int[] nums,int left,int right){
int tem = nums[left];
nums[left] = nums[right];
nums[right] = tem;
}
public int position(int[] nums,int left,int right){
//使用index来记录每次的基准值的索引
int index = left;
//pos来记录基准值
int pos = nums[index];
while(left < right){
while(nums[right] > pos && left < right)
right--;
while(nums[left] <= pos && left < right)
left ++;
if (left < right){
swap(nums,left,right);
//每次交换数据后就把进行指针移动
left++;
right--;
}
}
//把基准值和分界节点的数据进行交换
nums[index] = nums[left];
nums[left] = pos;
return left;
}
}
执行结果如下

3.总结
两种实现是同样的思想,但是其中略有不同,第一种使用占坑法,但必须有一个值来记录基准值。
第二种情况进行实时交换。主要还是看个人理解。
参考文章:
https://www.cnblogs.com/y3w3l/p/6444837.html
https://blog.csdn.net/u010430495/article/details/88388057
https://blog.csdn.net/weixin_30363263/article/details/82462088















 275
275











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









