









 本文探讨了PCA、ZCA等五种白化方法的原理及应用,通过理论推导和实验证明了不同场景下最佳选择。适用于数据预处理、特征提取等领域。
本文探讨了PCA、ZCA等五种白化方法的原理及应用,通过理论推导和实验证明了不同场景下最佳选择。适用于数据预处理、特征提取等领域。
Paper Reading《Optimal Whitening and Decorrelation》
@author:Heisenberg

论文发表自2016《 The American Statistician》,主要涉及了PCA、PCA-cor、ZCA、ZCA-cor以及Cholesky分解五种白化方法的理论推导证明以及在鸢尾花数据集上的测试表现。最终结论是ZCA-cor白化得到与原始变量最大相似的球形变量;PCA-cor白化能得到与原始变量最大压缩的球形变量。
1. Introduction and Notation
对于数据矩阵
x
=
(
x
1
,
⋯
,
x
d
)
T
x=(x_1,\cdots,x_d)^T
x=(x1,⋯,xd)T,数学期望为
E
(
x
)
=
μ
=
(
μ
1
,
μ
2
,
⋯
,
μ
d
)
E(x)=\mu=(\mu_1,\mu_2,\cdots,\mu_d)
E(x)=μ=(μ1,μ2,⋯,μd),协方差矩阵
v
a
r
(
x
)
=
Σ
var(x)=\Sigma
var(x)=Σ。通过线性变换
z
=
(
z
1
,
z
2
,
⋯
,
z
d
)
=
W
x
,
s
.
t
.
v
a
r
(
z
)
=
I
z=(z_1,z_2,\cdots,z_d)=Wx,\quad s.t.var(z)=I
z=(z1,z2,⋯,zd)=Wx,s.t.var(z)=I的过程称为白化或者球化。其中
W
∈
R
d
×
d
W\in\R^{d\times d}
W∈Rd×d ,
v
a
r
(
z
)
=
I
=
W
T
x
T
x
W
=
W
T
Σ
W
var(z)=I=W^Tx^TxW=W^T\Sigma W
var(z)=I=WTxTxW=WTΣW,也即
W
T
W
=
Σ
−
1
W^TW=\Sigma^{-1}
WTW=Σ−1
下面介绍几个推导过程中常用的矩阵分解:
- 根据 ρ = C o v ( X , Y ) V a r ( X ) V a r ( Y ) \rho=\frac{Cov(X,Y)}{\sqrt{Var(X)Var(Y)}} ρ=Var(X)Var(Y)Cov(X,Y),我们令 P P P为皮尔逊自相关系数矩阵则有 Σ = V 1 2 P V 1 2 \Sigma=V^{\frac{1}{2}}PV^{\frac{1}{2}} Σ=V21PV21。 其中 V V V是形如 V = diag ( σ 1 2 , ⋯ , σ d 2 ) V=\text{diag}(σ_1^2,\cdots, σ^2_d) V=diag(σ12,⋯,σd2)的对角阵。
- 由特征值分解 Σ = U Λ U T \Sigma=U\Lambda U^T Σ=UΛUT, Λ \Lambda Λ是 Σ \Sigma Σ的特征值按照大小顺序组成的对角阵,形如 Λ = diag ( λ 1 , ⋯ , λ r , ⋯ , 0 ) , r ≤ d \Lambda=\text{diag}(\lambda_1,\cdots,\lambda_r,\cdots,0), r\leq d Λ=diag(λ1,⋯,λr,⋯,0),r≤d。 U U U是对应的特征值单位化后的特征向量组成的正交阵, s . t . U T U = I , U T = U − 1 s.t. U^TU=I,U^T=U^{-1} s.t.UTU=I,UT=U−1;同理, Σ − 1 2 = U Λ − 1 2 U T \Sigma^{-\frac{1}{2}}=U\Lambda^{-\frac{1}{2}} U^T Σ−21=UΛ−21UT
- 同样地,对自相关矩阵 P P P做特征值分解有 P = G Θ G T P=G\Theta G^T P=GΘGT和 P − 1 2 = G T Θ − 1 2 G T P^{-\frac{1}{2}}=G^T\Theta^{-\frac{1}{2}} G^T P−21=GTΘ−21GT,其中 G T G = I G^TG=I GTG=I且 Θ \Theta Θ是 P P P的特征值按照大小顺序组成的对角阵。
2. Rotational freedom
2.1 非标准化数据
根据约束**(1)**其实我们无法唯一确定线性变换 W W W。我们可以通过极分解将 W W W分解为 W = Q 1 Σ − 1 2 W=Q_1\Sigma^{-\frac{1}{2}} W=Q1Σ−21,其中 Q 1 Q_1 Q1是正交阵,满足于 Q 1 T Q 1 = I d Q_1^TQ_1=I_d Q1TQ1=Id。
为什么可以这么分解呢?
W T W = ( Σ − 1 2 ) T Q 1 T Q 1 Σ − 1 2 = ( Σ − 1 2 ) T I d Σ − 1 2 = Σ − 1 W^TW=(\Sigma^{-\frac{1}{2}})^TQ_1^TQ_1\Sigma^{-\frac{1}{2}}=(\Sigma^{-\frac{1}{2}})^TI_d\Sigma^{-\frac{1}{2}}=\Sigma^{-1} WTW=(Σ−21)TQ1TQ1Σ−21=(Σ−21)TIdΣ−21=Σ−1.
相当于对原数据进行了 Σ − 1 2 \Sigma^{-\frac{1}{2}} Σ−21的放缩,和一个 Q 1 Q_1 Q1的旋转变换。(正交阵的几何意义即是保持两点的欧式距离不变的线性变换,可以实现旋转以及镜像变换等)。
对 Σ − 1 2 \Sigma^{-\frac{1}{2}} Σ−21进行特征值分解可得: W = Q 1 ( U Λ − 1 2 U T ) = ( Q 1 U ) Λ − 1 2 U T W=Q_1(U\Lambda^{-\frac{1}{2}}U^T)=(Q_1U)\Lambda^{-\frac{1}{2}}U^T W=Q1(UΛ−21UT)=(Q1U)Λ−21UT,可以视为对矩阵 W W W进行的SVD分解。 Q 1 U Q_1U Q1U即左奇异矩阵,可以理解原矩阵进行了 U T U^T UT的旋转之后,进行了 Λ − 1 2 \Lambda^{-\frac{1}{2}} Λ−21的放缩后又进行了由 Q 1 Q_1 Q1决定的旋转。
2.2 标准化数据
很多情况下我们要处理标准化数据 i . e . V − 1 2 x i.e. V^{-\frac{1}{2}}x i.e.V−21x.
基于此对W进行矩阵分解可得 W = Q 2 P − 1 2 V − 1 2 W=Q_2P^{-\frac{1}{2}}V^{-\frac{1}{2}} W=Q2P−21V−21,其中 Q 2 Q_2 Q2是正交阵,满足于 Q 2 T Q 2 = I d Q_2^TQ_2=I_d Q2TQ2=Id。
为什么可以这么分解呢?
W T W = ( V − 1 2 ) T ( P − 1 2 ) T Q 2 T Q 2 P − 1 2 V − 1 2 = ( V − 1 2 ) T ( P − 1 2 ) T I d P − 1 2 V − 1 2 = ( V − 1 2 ) T P − 1 V − 1 2 = Σ − 1 W^TW=(V^{-\frac{1}{2}})^T(P^{-\frac{1}{2}})^TQ_2^TQ_2P^{-\frac{1}{2}}V^{-\frac{1}{2}}=(V^{-\frac{1}{2}})^T(P^{-\frac{1}{2}})^TI_dP^{-\frac{1}{2}}V^{-\frac{1}{2}}=(V^{-\frac{1}{2}})^TP^{-1}V^{-\frac{1}{2}}=\Sigma^{-1} WTW=(V−21)T(P−21)TQ2TQ2P−21V−21=(V−21)T(P−21)TIdP−21V−21=(V−21)TP−1V−21=Σ−1
对 P − 1 2 P^{-\frac{1}{2}} P−21进行特征值分解可得: W = Q 2 G Θ − 1 2 G T V − 1 2 W=Q_2G\Theta^{-\frac{1}{2}}G^TV^{-\frac{1}{2}} W=Q2GΘ−21GTV−21,可以视为对矩阵 W W W进行的SVD分解。 Q 2 G Q_2G Q2G即左奇异矩阵,可以理解原矩阵先进行方差矩阵 V − 1 2 V^{-\frac{1}{2}} V−21的放缩,而后经历了 G T G^T GT的旋转,再经过 Θ − 1 2 \Theta^{-\frac{1}{2}} Θ−21的放缩,又进行了由 Q 2 Q_2 Q2决定的旋转。
2.3 两种旋转自由度的关系
所以矩阵 W W W可以有两种自由旋转的方式,分别由 Q 1 , Q 2 Q_1,Q_2 Q1,Q2决定。
由 Q 1 P − 1 2 V − 1 2 = Q 2 Σ − 1 2 Q_1P^{-\frac{1}{2}}V^{-\frac{1}{2}}=Q_2\Sigma^{-\frac{1}{2}} Q1P−21V−21=Q2Σ−21,可得 Q 1 = Q 2 A , w h e r e A = P 1 2 V 1 2 Σ − 1 2 Q_1=Q_2A, where\quad A=P^{\frac{1}{2}}V^{\frac{1}{2}}\Sigma^{-\frac{1}{2}} Q1=Q2A,whereA=P21V21Σ−21
3 互协方差与互相关
Cross-covariance and cross-correlation
互协方差矩阵定义为:
Φ
=
(
ϕ
i
j
)
=
cov
(
z
,
x
)
=
cov
(
W
x
,
x
)
=
W
Σ
=
Q
1
Σ
1
/
2
\begin{aligned} \boldsymbol{\Phi}=\left(\phi_{i j}\right) &=\operatorname{cov}(\boldsymbol{z}, \boldsymbol{x})=\operatorname{cov}(\boldsymbol{W} \boldsymbol{x}, \boldsymbol{x}) =\boldsymbol{W} \boldsymbol{\Sigma}=Q_{1} \boldsymbol{\Sigma}^{1 / 2} \end{aligned}
Φ=(ϕij)=cov(z,x)=cov(Wx,x)=WΣ=Q1Σ1/2
互自相关矩阵定义为:(互自相关矩阵对角线元素不一定为1)
Ψ
=
(
ψ
i
j
)
=
cor
(
z
,
x
)
=
Φ
V
−
1
/
2
=
Q
2
A
Σ
1
/
2
V
−
1
/
2
=
Q
2
P
1
/
2
\begin{aligned} \boldsymbol{\Psi}=\left(\psi_{i j}\right) &=\operatorname{cor}(z, \boldsymbol{x})=\boldsymbol{\Phi} \boldsymbol{V}^{-1 / 2} =Q_{2} A \Sigma^{1 / 2} \boldsymbol{V}^{-1 / 2}=Q_{2} \boldsymbol{P}^{1 / 2} \end{aligned}
Ψ=(ψij)=cor(z,x)=ΦV−1/2=Q2AΣ1/2V−1/2=Q2P1/2
互相关函数是信号分析里的概念,表示的是两个时间序列之间的相关程度,即描述信号x(t),y(t)在任意两个不同时刻t1,t2的取值之间的相关程度。具体计算方法可以参考互相关(cross-correlation)及其在Python中的实现
可以看到互协方差和互自相关分别由旋转变量 Q 1 , Q 2 Q_1,Q_2 Q1,Q2决定,这为我们通过适当地选择或限制 Φ \Phi Φ或 Ψ \Psi Ψ来选择和区分白化变换提供了衡量标准。
对 Ψ \Psi Ψ的讨论:
由 x = W − 1 z x=W^{-1}z x=W−1z对于列维度的向量 x j x_j xj都分别由不相关的 z 1 , ⋯ , z d z_1,\cdots,z_d z1,⋯,zd线性组合而成,所以 S M C ( x j , z ) = 1 SMC(x_j,z)=1 SMC(xj,z)=1.
SMC,即squared multiple correlations:一个变量与其他变量的多重相关性平方,作为对一个变量公共性的评估。可以理解为在OLS中的 ρ ( y i , Y ^ ) \rho(y_i,\mathbb{\hat{Y}}) ρ(yi,Y^)
用矩阵表示则为 d i a g ( Ψ T Ψ ) = d i a g ( P 1 / 2 Q 2 T Q 2 P 1 / 2 ) = d i a g ( P ) = ( 1 , ⋯ , 1 ) d T diag(\Psi^T\Psi)=diag(P^{1/2}Q^T_2Q_2P^{1/2})=diag(P)=(1,\cdots,1)^T_d diag(ΨTΨ)=diag(P1/2Q2TQ2P1/2)=diag(P)=(1,⋯,1)dT。即 z , x z,x z,x的组内关系是确定的, x j x_j xj这一列完全由 z j z_j zj这一列线性变换而来,故 ρ ( z j , x j ) = 1 \rho(z_j,x_j)=1 ρ(zj,xj)=1.
而组间关系 ρ ( x i , z i ) \rho(x_i,z_i) ρ(xi,zi)则要用 d i a g ( Ψ Ψ T ) diag(\Psi\Psi^T) diag(ΨΨT)来表示,不同的白化方法对应着不同的值。
4 不同的白化方法
由上文所述方法我们确定了范式后可知,一种白化方法我们确定了旋转矩阵 Q 1 , Q 2 Q_1,Q_2 Q1,Q2,也就可以推出白化矩阵 W W W.反之亦然。
4.1 ZCA
ZCA 也即zero-phase components analysis
W Z C A = Σ − 1 / 2 W^{ZCA}=\Sigma^{-1/2} WZCA=Σ−1/2, Q 1 = I Q_1=I Q1=I.
4.2 PCA
W P C A = Λ − 1 / 2 U T \boldsymbol{W}^{\mathrm{PCA}}=\boldsymbol{\Lambda}^{-1 / 2} \boldsymbol{U}^{T} WPCA=Λ−1/2UT
4.3 Cholesky分解
cholesky分解即将一个方阵分解为一个上三角形和一个下三角形矩阵的乘积,两者互为转置。
W C h o l = L T \boldsymbol{W}^{\mathrm{Chol}}=\boldsymbol{L}^{T} WChol=LT
4.4 ZCA-cor分解
由Zummer(2009)等人首先用于变量重要性以及变量筛选统计上。
W Z C A − c o r = P − 1 / 2 V − 1 / 2 \boldsymbol{W}^{\mathrm{ZCA}-\mathrm{cor}}=\boldsymbol{P}^{-1 / 2} \boldsymbol{V}^{-1 / 2} WZCA−cor=P−1/2V−1/2,相当于按照标准差进行了标准化,然后又做了自相关系数 P − 1 / 2 P^{-1/2} P−1/2的放缩。
4.5 PCA-cor分解
W P C A − c o r = Θ − 1 / 2 G T V − 1 / 2 \boldsymbol{W}^{\mathrm{PCA}-\mathrm{cor}}=\Theta^{-1 / 2} G^{T} \boldsymbol{V}^{-1 / 2} WPCA−cor=Θ−1/2GTV−1/2
五种白化方法总结:
Sphering matrix
W
Cross-covariance
Φ
Cross-correlation
Ψ
Rotation mat
Q
1
Rotation mat
Q
2
ZCA
Σ
−
1
/
2
Σ
1
/
2
Σ
1
/
2
V
−
1
/
2
I
I
PCA
Λ
−
1
/
2
U
T
Λ
1
/
2
U
T
Λ
1
/
2
U
T
V
−
1
/
2
U
T
U
T
A
T
Cholesky
L
T
L
T
Σ
L
T
Σ
V
−
1
/
2
L
T
Σ
1
/
2
L
T
V
1
/
2
P
1
/
2
ZCA-cor
P
−
1
/
2
V
−
1
/
2
P
1
/
2
V
1
/
2
P
1
/
2
A
I
PCA-cor
Θ
−
1
/
2
G
T
V
−
1
/
2
Θ
1
/
2
G
T
V
1
/
2
Θ
1
/
2
G
T
G
T
A
G
T
\begin{array}{lrrrll} \hline & \begin{array}{r} \text {Sphering matrix} \\ W \end{array} & \begin{array}{r} \text {Cross-covariance} \\ \boldsymbol{\Phi} \end{array} & \begin{array}{r} \text {Cross-correlation} \\ \boldsymbol{\Psi} \end{array} & \begin{array}{l} \text {Rotation mat} \\ \boldsymbol{Q_1} \end{array} & \begin{array}{l} \text {Rotation mat} \\ \boldsymbol{Q_2} \end{array} \\ \hline \text { ZCA } & \boldsymbol{\Sigma^{-1 / 2}} & \boldsymbol{\Sigma^{1 / 2}} & \boldsymbol{\Sigma^{1 / 2}}\boldsymbol{V^{-1/2}} & \boldsymbol{I} & \boldsymbol{I} \\ \text { PCA } & \boldsymbol{\Lambda}^{-1 / 2} \boldsymbol{U}^{T} & \boldsymbol{\Lambda}^{1 / 2} \boldsymbol{U}^{T} & \boldsymbol{\Lambda}^{1 / 2} \boldsymbol{U}^{T} \boldsymbol{V}^{-1 / 2} & \boldsymbol{U}^{T} & \boldsymbol{U}^{T} \boldsymbol{A}^{T} \\ \text { Cholesky } & \boldsymbol{L}^{T} & \boldsymbol{L}^{T} \boldsymbol{\Sigma} & \boldsymbol{L}^{T} \boldsymbol{\Sigma} V^{-1 / 2} & \boldsymbol{L}^{T} \boldsymbol{\Sigma}^{1 / 2} & \boldsymbol{L}^{T} \boldsymbol{V}^{1 / 2} \boldsymbol{P}^{1 / 2} \\ \text { ZCA-cor } & \boldsymbol{P}^{-1 / 2} \boldsymbol{V}^{-1 / 2} & \boldsymbol{P}^{1 / 2} \boldsymbol{V}^{1 / 2} & \boldsymbol{P}^{1 / 2} & \boldsymbol{A} & \boldsymbol{I} \\ \text { PCA-cor } & \Theta^{-1 / 2} G^{T} \boldsymbol{V}^{-1 / 2} & \Theta^{1 / 2} \boldsymbol{G}^{T} \boldsymbol{V}^{1 / 2} & \Theta^{1 / 2} \boldsymbol{G}^{T} & \boldsymbol{G}^{T} \boldsymbol{A} & \boldsymbol{G}^{T} \\ \hline \end{array}
ZCA PCA Cholesky ZCA-cor PCA-cor Sphering matrixWΣ−1/2Λ−1/2UTLTP−1/2V−1/2Θ−1/2GTV−1/2Cross-covarianceΦΣ1/2Λ1/2UTLTΣP1/2V1/2Θ1/2GTV1/2Cross-correlationΨΣ1/2V−1/2Λ1/2UTV−1/2LTΣV−1/2P1/2Θ1/2GTRotation matQ1IUTLTΣ1/2AGTARotation matQ2IUTATLTV1/2P1/2IGT
5 优化白化过程
优化目标是通过最小的额外调整来消除相关性,目的是使转换后的变量z保持尽可能类似于原始向量x。PCA侧重于前者,有利于数据压缩降维;ZCA侧重于后者,有利于映射回向量源空间。
5.1 ZCA
ZCA中我们采用最小化原始变量
x
x
x和白化变量
z
z
z之间总平方距离的白化变换。在下列变换中
E
(
z
c
)
=
E
(
x
c
)
=
0
\mathrm{E}(z_c)=\mathrm{E}(x_c)=0
E(zc)=E(xc)=0。
E
(
(
z
c
−
x
c
)
T
(
z
c
−
x
c
)
)
=
E
(
z
c
T
z
c
T
)
−
2
E
(
z
c
x
c
T
)
+
E
(
x
c
T
x
c
)
=
tr
(
I
)
−
2
E
(
tr
(
z
c
x
c
T
)
)
+
tr
(
Σ
)
=
d
−
2
tr
(
Φ
)
+
tr
(
V
)
\begin{aligned} \mathrm{E}\left(\left(\boldsymbol{z}_{c}-\boldsymbol{x}_{\mathcal{c}}\right)^{T}\left(\boldsymbol{z}_{c}-\boldsymbol{x}_{\mathcal{c}}\right)\right) &=\mathrm{E}(z^T_cz_c^T)-2\mathrm{E}(\boldsymbol{z}_{c} \boldsymbol{x}_{c}^{T})+\mathrm{E}(x_c^Tx_c) \\&=\operatorname{tr}(\boldsymbol{I})-2 \mathrm{E}\left(\operatorname{tr}\left(\boldsymbol{z}_{c} \boldsymbol{x}_{c}^{T}\right)\right)+\operatorname{tr}(\boldsymbol{\Sigma}) \\ &=d-2 \operatorname{tr}(\boldsymbol{\Phi})+\operatorname{tr}(\boldsymbol{V}) \end{aligned}
E((zc−xc)T(zc−xc))=E(zcTzcT)−2E(zcxcT)+E(xcTxc)=tr(I)−2E(tr(zcxcT))+tr(Σ)=d−2tr(Φ)+tr(V)
维度
d
d
d与
t
r
(
V
)
=
∑
i
=
1
d
σ
i
2
tr(V)=\sum_{i=1}^d\sigma_i^2
tr(V)=∑i=1dσi2与矩阵
W
W
W都无关,最小化平方距离等价于最大化
tr
(
Φ
)
\operatorname{tr}(\boldsymbol{\Phi})
tr(Φ)。
tr
(
Φ
)
=
∑
i
=
1
d
cov
(
z
i
,
x
i
)
=
tr
(
Q
1
Σ
1
/
2
)
≡
g
1
(
Q
1
)
\operatorname{tr}(\boldsymbol{\Phi})=\sum_{i=1}^{d} \operatorname{cov}\left(z_{i}, x_{i}\right)=\operatorname{tr}\left(Q_{1} \Sigma^{1 / 2}\right) \equiv g_{1}\left(Q_{1}\right)
tr(Φ)=i=1∑dcov(zi,xi)=tr(Q1Σ1/2)≡g1(Q1)
可以证明当且仅当
W
=
W
Z
C
A
W=W^{ZCA}
W=WZCA的时候
g
1
(
Q
1
)
g_1(Q_1)
g1(Q1)取得最大值。
Proof:
先对 Λ \Lambda Λ进行特征值分解,后半部分可视为对矩阵 B B B的帖子分解,最后一个等号由 Λ \Lambda Λ是对角阵所保证
g 1 ( Q 1 ) = tr ( Q 1 U Λ 1 / 2 U T ) = tr ( Λ 1 / 2 U T Q 1 U ) ≡ tr ( Λ 1 / 2 B ) = ∑ i Λ i i 1 / 2 B i i g_{1}\left(\boldsymbol{Q}_{1}\right)=\operatorname{tr}\left(\boldsymbol{Q}_{1} \boldsymbol{U} \boldsymbol{\Lambda}^{1 / 2} \boldsymbol{U}^{T}\right)=\operatorname{tr}\left(\boldsymbol{\Lambda}^{1 / 2} \boldsymbol{U}^{T} \boldsymbol{Q}_{1} \boldsymbol{U}\right) \equiv \operatorname{tr}\left(\boldsymbol{\Lambda}^{1 / 2} \boldsymbol{B}\right)=\sum_{i} \boldsymbol{\Lambda}_{i i}^{1 / 2} B_{i i} g1(Q1)=tr(Q1UΛ1/2UT)=tr(Λ1/2UTQ1U)≡tr(Λ1/2B)=∑iΛii1/2Bii
而 Q 1 , U Q_1,U Q1,U的正交性则保证了 B = U T Q 1 U B=U^TQ_1U B=UTQ1U的正交性。
∴ B i i ≤ 1 \therefore B_{ii}\leq1 ∴Bii≤1. (正交阵行列向量都为单位向量,则对角线数值必≤1)
i f f B = I , i . e . Q 1 = I , i . e . W = W Z C A iff \quad \mathbf{B}=\mathbf{I}, i.e. \mathbf{Q_1}=\mathbf{I} ,i.e. \mathbf{W}=\mathbf{W^{ZCA}} iffB=I,i.e.Q1=I,i.e.W=WZCA , g 1 ( Q 1 ) g_1(Q_1) g1(Q1)可以取最大值
因而,我们发现ZCA白化是最大化了 z z z和 x x x每一个成分之间的平均互协方差。
5.2 ZCA-cor
同样的,对于标准化的向量 V − 1 / 2 x c V^{-1/2}x_c V−1/2xc
W P C A = Λ − 1 / 2 U T \boldsymbol{W}^{\mathrm{PCA}}=\boldsymbol{\Lambda}^{-1 / 2} \boldsymbol{U}^{T} WPCA=Λ−1/2UT
4.3 Cholesky分解
cholesky分解即将一个方阵分解为一个上三角形和一个下三角形矩阵的乘积,两者互为转置。
E
(
(
z
c
−
V
−
1
/
2
x
c
)
T
(
z
c
−
V
−
1
/
2
x
c
)
)
=
2
d
−
2
tr
(
Ψ
)
\mathrm{E}\left(\left(\boldsymbol{z}_{c}-\boldsymbol{V}^{-1 / 2} \boldsymbol{x}_{c}\right)^{T}\left(\boldsymbol{z}_{c}-\boldsymbol{V}^{-1 / 2} \boldsymbol{x}_{c}\right)\right)=2 d-2 \operatorname{tr}(\boldsymbol{\Psi})
E((zc−V−1/2xc)T(zc−V−1/2xc))=2d−2tr(Ψ)
可以证明当且仅当
W
=
W
Z
C
A
−
c
o
r
W=W^{ZCA-cor}
W=WZCA−cor的时候
g
2
(
Q
2
)
g_2(Q_2)
g2(Q2)取得最大值。
结果,我们确定ZCA-cor是确保 z z z的分量保持最大限度地与相应的 x x x的分量的相似性。
5.3 PCA
PCA目标是数据压缩,我们的目标是用重构的数据 z 1 , ⋯ , z d z_1,\cdots,z_d z1,⋯,zd中的前几个向量就能够尽可能的表示出原来的向量所 x 1 , ⋯ , x d x_1,\cdots,x_d x1,⋯,xd包含的信息。
PCA中我们的目标是找到一个白化向量 z z z,使得 z z z与 x x x的组间向量(即行向量)互协方差 ∑ j = 1 d ϕ i j 2 = ∑ j = 1 d cov ( z i , x j ) 2 \sum_{j=1}^{d} \phi_{i j}^{2}=\sum_{j=1}^{d} \operatorname{cov}\left(z_{i}, x_{j}\right)^{2} ∑j=1dϕij2=∑j=1dcov(zi,xj)2
( ϕ 1 , … , ϕ d ) T = diag ( Φ Φ T ) = diag ( Q 1 Σ Q 1 T ) ≡ h 1 ( Q 1 ) \left(\phi_{1}, \ldots, \phi_{d}\right)^{T}=\operatorname{diag}\left(\Phi \Phi^{T}\right)=\operatorname{diag}\left(Q_{1} \Sigma Q_{1}^{T}\right) \equiv h_{1}\left(Q_{1}\right) (ϕ1,…,ϕd)T=diag(ΦΦT)=diag(Q1ΣQ1T)≡h1(Q1),满足于 ϕ i ≥ ϕ i + 1 \phi_i\geq\phi_{i+1} ϕi≥ϕi+1,使得 ϕ i \phi_i ϕi最大。
h 1 ( Q 1 ) = diag ( Q 1 Σ Q 1 T ) = diag ( Q 1 U Λ U T Q 1 T ) h_1(Q_1)=\text{diag}(Q_{1} \Sigma Q_{1}^{T})=\text{diag}(Q_{1} U\Lambda U^T Q_{1}^{T}) h1(Q1)=diag(Q1ΣQ1T)=diag(Q1UΛUTQ1T)
当且仅当 Q 1 = U , i . e . W = W P C A Q_1=U^, i.e. W=W^{PCA} Q1=U,i.e.W=WPCA时, h 1 ( Q 1 ) = ∑ j Λ j j D i j 2 , w h e r e D = Q 1 U = I h_1(Q_1)=\sum_j\Lambda_{jj}D^2_{ij}, where \quad D=Q_1U=I h1(Q1)=∑jΛjjDij2,whereD=Q1U=I
可以取得最大值。
因此,PCA基于互协协方差作为基础度量,最大化了球形向量 z z z的每个分量对应的原始向量 x x x的所有分量的积分或压缩。因此,PCA在降维方面是最优排序的。
5.4 PCA-cor
同样地,PCA-cor中我们的目标是找到一个白化向量 z z z,使得 z z z与 x x x的组间向量(即行向量)互自相关系数 ∑ j = 1 d ψ i j 2 = ∑ j = 1 d cov ( z i , x j ) 2 \sum_{j=1}^{d} \psi_{i j}^{2}=\sum_{j=1}^{d} \operatorname{cov}\left(z_{i}, x_{j}\right)^{2} ∑j=1dψij2=∑j=1dcov(zi,xj)2
( ψ 1 , … , ψ d ) T = diag ( Ψ Ψ T ) = diag ( Q 2 P Q 2 T ) = h 2 ( Q 2 ) \left(\psi_{1}, \ldots, \psi_{d}\right)^{T}=\operatorname{diag}\left(\Psi \Psi^{T}\right)=\operatorname{diag}\left(Q_{2} P Q_{2}^{T}\right)=h_{2}\left(Q_{2}\right) (ψ1,…,ψd)T=diag(ΨΨT)=diag(Q2PQ2T)=h2(Q2)
同理可证 W = W P C A − c o r W=W^{PCA-cor} W=WPCA−cor时成立。
因此,PCA-cor白化变换是用互相关ψ为基础测度,将原始向量 x x x的所有分量在白化向量 z z z的每个分量中的积分或压缩最大化的唯一变换。
5.5 Cholesky
Cholesky能够由下三角正对角互协方差和互自相关矩阵这两个特征唯一确定。
使用Cholesky因子分解进行白化的一个结果是,我们隐含地假定了变量的排序。这对于解释自相关的时间过程分析是非常有用的。
6 实验与结论分析
6.1 实验结果
选用了鸢尾花 4 × 150 4\times150 4×150的数据进行实验,分别进行五种白化方法进行实验:
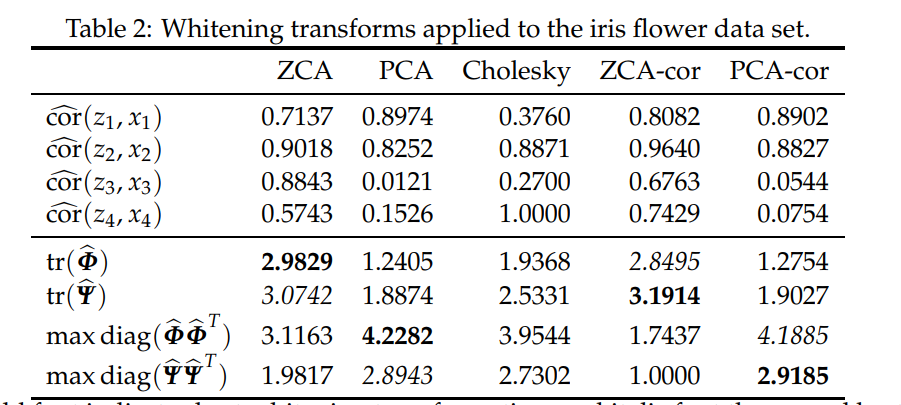
最好的结果加粗表示;第二好的结果斜体表示
-
可以看到 t r ( Ψ ^ ) , t r ( Φ ^ ) tr(\hat{\Psi}),tr(\hat{\Phi}) tr(Ψ^),tr(Φ^)中表现最好和第二好的都是ZCA/ZCA-cor,数值越大表明 z , x z,x z,x的平方距离越小,拟合能力越强;
-
max diag ( Ψ Ψ T ) , max , diag ( Φ Φ T ) \max\operatorname{diag}\left(\Psi \Psi^{T}\right),\max,\operatorname{diag}\left(\Phi \Phi^{T}\right) maxdiag(ΨΨT),max,diag(ΦΦT)中表现最好和第二好的都是PCA/PCA-cor,数值越大说明最大的对角线元素打,在相同压缩力度下,第一个元素 z 1 z_1 z1所能代表 x x x的能力强。
-
且根据上半部分可以看出,ZCA/ZCA-cor中 z i , x i z_i,x_i zi,xi的相关系数整体都很高,而PCA/PCA-cor中 c o r ^ ( x 1 , z 1 ) , c o r ^ ( x 2 , z 2 ) \hat{cor}(x_1,z_1),\hat{cor}(x_2,z_2) cor^(x1,z1),cor^(x2,z2)自相关系数很高,但后面 c o r ^ ( x 3 , z 3 ) , c o r ^ ( x 4 , z 4 ) \hat{cor}(x_3,z_3),\hat{cor}(x_4,z_4) cor^(x3,z3),cor^(x4,z4)就很低了,说明前两维已经能很好地刻画 x x x。
-
无论如何,Cholesky白化总是排名第三,要么排在ZCA/ZCA-cor白化之后,要么排在PCA/PCA-cor白化之后。此外,它是唯一能通过构造一对 ( z 4 , x 4 ) (z_4,x_4) (z4,x4)在完美地相互关联。
6.2 结论
一个合适的白化变换取决于应用目的,特别是是否需要最小的调整,还是数据压缩。
在前者中,白化后的变量与原始变量保持高度相关,从而保持其原始的解释。这在如变量选择上市有利的。
相比之下,在压缩环境中,通过构造而变白的变量与原始数据没有可解释的关系,而是反映了它们内在的有效维度。
总的来说,作者提倡使用以互自相关系数矩阵
Ψ
\boldsymbol{\Psi}
Ψ为优化基础的尺度不变的最优性函数。
如果目的是获得与原始变量最大相似的球形变量,我们建议采用ZCA-cor白化;相反,如果需要最大压缩,我们建议使用PCA-cor白化。
7 总结
作者通过理论推导对五种白化方法的进行了原理性的解释和证明,并结合经典数据集的实验给出了何种情况下适合何种白化方法。
但也存在着一定的问题:
- 只用一个经典数据集是否缺乏共性(可能是数理统计学的普遍做法)
- 并没有给出为何基于Self-cor mat Ψ \Psi Ψ 是更合理做法的更详尽的解释。实验结果中ZCA、PCA白化也都在 t r ( Φ ^ ) tr(\hat{\Phi}) tr(Φ^), max diag ( Φ ^ Φ ^ T ) \max \text{diag}(\hat{\Phi}\hat{\Phi}^T) maxdiag(Φ^Φ^T)取得了最好。可能是ZCA-cor,PCA-cor都是基于 P P P的分解所以在 t r ( Ψ ^ ) tr(\hat{\Psi}) tr(Ψ^), max diag ( Ψ ^ Ψ ^ T ) \max \text{diag}(\hat{\Psi}\hat{\Psi}^T) maxdiag(Ψ^Ψ^T)的尺度上更统一?
- 在文章开头引出 V V V的时候并没有指明 Σ = V 1 / 2 P V 1 / 2 \Sigma=V^{1/2}PV^{1/2} Σ=V1/2PV1/2是哈达玛积,即element-wise按照位置相乘的。 V V V其实是形如 ∣ V a r ( X ) V a r ( X ) ⋅ V a r ( Y ) V a r ( X ) ⋅ V a r ( Z ) V a r ( Y ) ⋅ V a r ( X ) V a r ( Y ) V a r ( Y ) ⋅ V a r ( Z ) V a r ( Z ) ⋅ V a r ( X ) V a r ( Z ) ⋅ V a r ( Y ) V a r ( Z ) ∣ \left|\begin{array}{lll}Var(X) &\sqrt{Var(X)\cdot Var(Y)} & \sqrt{Var(X)\cdot Var(Z)} \\ \sqrt{Var(Y)\cdot Var(X) } & Var(Y) & \sqrt{Var(Y)\cdot Var(Z)} \\ \sqrt{Var(Z)\cdot Var(X)}&\sqrt{Var(Z)\cdot Var(Y)} &Var(Z) \end{array}\right| ∣∣∣∣∣∣Var(X)Var(Y)⋅Var(X)Var(Z)⋅Var(X)Var(X)⋅Var(Y)Var(Y)Var(Z)⋅Var(Y)Var(X)⋅Var(Z)Var(Y)⋅Var(Z)Var(Z)∣∣∣∣∣∣的方差-标准差矩阵。 d i a g ( V ) = ( σ 1 , σ 2 , ⋯ , σ d ) diag(V)=(\sigma_1,\sigma_2,\cdots,\sigma_d) diag(V)=(σ1,σ2,⋯,σd)。而第二部分Notation开始就说"the diagonal varience matirx V",不严谨。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









