







1. zookeeper简介
1.1 zookeeper是什么
- ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务。它是Google的Chubby(闭源)一个开源的实现,目前。在分布式协调技术方面做得比较好的就是Google的Chubby还有Apache的ZooKeeper。
- 在构建一些分布式系统的时候,可以以这类系统为起点来构建整体的系统,这将节省不少成本,而且bug也会更少。
- Zookeeper是Hadoop和Hbase的重要组件。Zookeeper 分布式服务框架是Apache Hadoop 的一个子项目。它可以为分布式应用提供一致性服务,如:配置维护、分布式同步等
1.2 zookeeper角色及作用
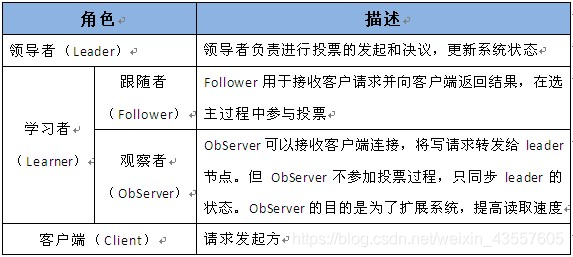
在上述角色中 leader和follower是比较常见的,observer用到的比较少,一般如果Zookeeper集群的读取负载很高,或者客户端多到跨机房,可以设置一些observer服务器,以提高读取的吞吐量。Observer和Follower比较相似,只有一些小区别:
- 首先observer不属于法定人数,即不参加选举也不响应提议(Leader和Follower构成Zookeeper集群的法定人数,只有他们才能参与新Leader的选举)
- 其次是observer不需要将事务持久化到磁盘,一旦observer被重启,需要从leader重新同步整个名称空间
如果要使用Observer模式,可以在对应节点的配置文件添加如下配置:
peerType=observer
2. 大数据为什么选择zookeeper
zookeeper是作为一个分布式协调工具,在很多大数据组件中都有出现。
Zookeeper有自己的文件系统 ,而这个文件系统可以监控目录的变化,这也就是协调工具的核心。通过对文件系统中目录的变化,可以感知集群中节点的状态变化,从而做后续的处理,如主备切换。
下边以基于zookeeper的kafka集群来做说明

每个kafka节点上都会有一个zkclient zkclient会想zookeeper注册一个临时目录,左右的zkclient都会监控注册的目录的状态,如果两个kafka从节点发现主的注册目录发生变化 如目录消失 就可以调用自身的回调函数 完成相应的逻辑处理 如新master的选举
3. zookeeper工作流程和znode
3.1 工作流程
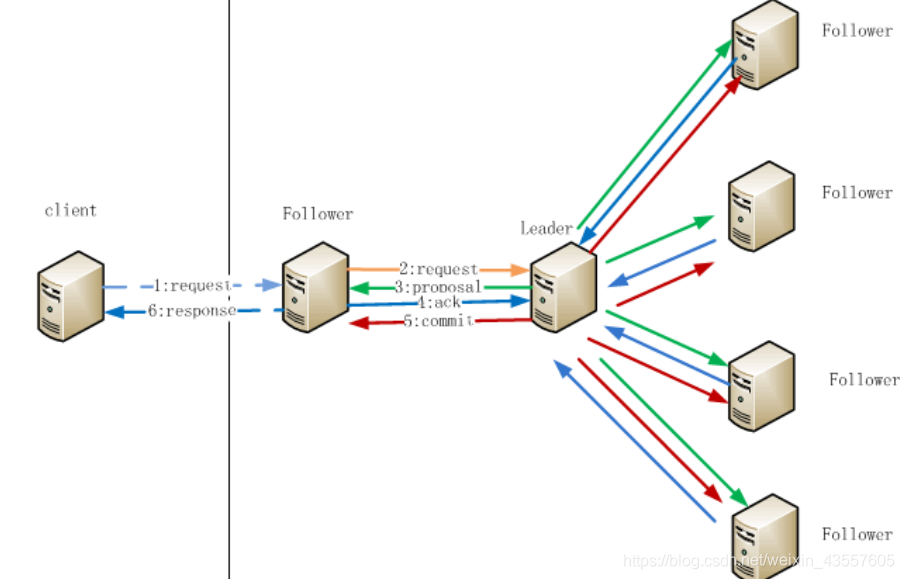
- 在Client向Follwer发出一个写的请求
- Follwer把请求发送给Leader
- Leader接收到以后开始发起投票并通知Follwer进行投票
- Follwer把投票结果发送给Leader
- Leader将结果汇总后如果需要写入,则开始写入同时把写入操作通知给所有follower,然后leader进行commit,所有的follower也跟随leader在本地进行提交;
- 最初与client交互的Follwer把请求结果返回给Client
3.2 关于znode
zookeeper数据是存储在znode上的,znode以树状结构存在,从外表看,像是一个根文件系统 如下

关于znode 特点如下
- 节点以绝对路径表示,不存在相对路径,且路径最后不能以 / 结尾(根节点除外)
- 节点分为临时节点和永久节点,临时节点依赖于客户端回话,客户端回话结束则临时节点销毁,永久节点默认一直存在,除非手动删除
- zookeeper规定节点的数据大小不能超过1M,但实际上我们在znode的数据量应该尽可能小,否则会影响zookeeper集群的性能。如果确实需要保存大量数据,可以在另外的分布式存储上进行数据的存储,而在zookeeper集群中存储那些数据的元数据
4. zookeeper集群的实现
安装JDK
mkdir -p /data/{install,app,logs,pid,appData}
mkdir /data/appData/tmp
cd /data/install
wget -c http://118.186.220.66:8002/jdk-7u51-linux-x64.gz
tar xf jdk-7u51-linux-x64.gz -C /data/app
cd /data/app
ln -s jdk1.7.0_51 jdk1.7
cat >> /etc/profile << _PATH_
export JAVA_HOME=/data/app/jdk1.7
export CLASSPATH=.:\$JAVA_HOME/lib/dt.jar:\$JAVA_HOME/lib/tools.jar
export PATH=\$JAVA_HOME/bin:\$PATH
_PATH_
source /etc/profile
安装zookeeper
cd /data/install
tar xf zookeeper-3.4.5.tar.gz -C /data/app
cd /data/app
ln -s zookeeper-3.4.5 zookeeper
设置环境变量
sed -i '/^export PATH=/i\export ZOOKEEPER_HOME=/data/app/zookeeper' /etc/profile
sed -i 's#export PATH=#&\$ZOOKEEPER_HOME/bin:#' /etc/profile
source /etc/profile
配置
cat > $ZOOKEEPER_HOME/conf/zoo.cfg << _ZOO_
tickTime=2000
initLimit=10
syncLimit=5
clientPort=2181
dataDir=/data/appData/zookeeper/data
dataLogDir=/data/appData/zookeeper/logs
server.1=cdh-m1:2888:3888
server.2=cdh-m2:2888:3888
server.3=cdh-s1:2888:3888
_ZOO_
修改zookeeper的日志打印方式与路径
vim $ZOOKEEPER_HOME/bin/zkEnv.sh
#27行后加入
ZOO_LOG_DIR=/data/logs/zookeeper
ZOO_LOG4J_PROP="INFO,ROLLINGFILE"
创建myid(数字与配置文件中的 相对应)
echo 1 >/data/appData/zookeeper/data/myid
创建运行用户并运行
useradd -u 600 run
chown -R run.run /data/{app,appData,logs}
runuser - run -c 'zkServer.sh start'
集群创建并运行成功
参考资料
https://www.jianshu.com/p/fe6f807735b4
https://www.cnblogs.com/Coolkaka/p/6101273.html
https://www.cnblogs.com/raphael5200/p/5285583.html
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









