







 本文深入探讨了数据结构中的抽象数据类型与编程语言数据类型的关系,详细阐述了线性表、栈和队列的特性,并分析了数组、广义表、树和二叉树的操作。此外,还讲解了图的性质、查找与排序算法的性能比较,以及具体操作实例。内容涵盖基础理论与实践应用,适合复习和学习。
本文深入探讨了数据结构中的抽象数据类型与编程语言数据类型的关系,详细阐述了线性表、栈和队列的特性,并分析了数组、广义表、树和二叉树的操作。此外,还讲解了图的性质、查找与排序算法的性能比较,以及具体操作实例。内容涵盖基础理论与实践应用,适合复习和学习。
个人复习整理,持续更新……
一、概念
1、简述数据结构中的抽象数据类型和编程语言中的数据类型有什么异同点。(彭波P8)
抽象数据类型:一个数据模型以及定义在该模型上的一组操作。
数据类型:一个值的集合和定义在这个值集上的一组操作的总称。用来刻画抽象操作对象的特性。
抽象数据类型可以理解为对数据类型的进一步抽象,其区别仅在于:
数据类型指的是高级程序设计语言中已经实现的数据结构;抽象数据类型的范畴更广,它不再局限于各处理器中已经定义并实现的数据类型,还包括用户在设计软件系统时自己定义的数据类型。
二、线性表
1、线性表的链式存储结构与顺序存储结构的区别。
| 顺序存储 | 链式存储 | ||
| 空间性能 | 分配方式 | 静态存储 (适合长度变化不大的线性表) | 动态存储 (适合长度变化大的线性表) |
| 存储密度 | =1 (存储空间利用率高) | 小于1 (需额外设置指针域,存储空间利用率低) | |
| 时间性能 | 存取方式 | 随机存取O(1) | 顺序存取O(n) |
| 插入删除操作 | 平均移动一半元素,时间开销大 适宜于做查找这样的静态操作 | 只需修改指针,插入删除这样的动态操作方便 |
(存储密度:数据本身所占存储量和整个结点所占存储量之比)
2、已知p指向双向循环链表中的一个结点,交换p所指向的结点及其前驱结点的顺序
typedef struct DNode{
int data;
struct DNode* prior; //前驱
struct DNode* next; //后继
}DNode, *LinkList;
void swap(DNode *p) //交换p结点与其前驱结点的位置
{
DNode *q=p->prior; //q是p的前驱结点
q->prior->next=p;
p->prior=q->prior;
p->next->prior=q;
q->next=p->next;
q->prior=p;
p->next=q;
}
分三个阶段:
1、p与新前驱建立联系:
q->prior->next=p;
p->prior=q->prior;
.
2、q与新后继建立联系:
p->next->prior=q;
q->next=p->next;
.
3、p与q互连:
p->next=q;
q->prior=p;
注意:在交换过程中不能丢掉前后两端结点的地址,也就是在任何时候都应该可以得到两端的结点。

3、描述以下三个概念的区别:头指针、头结点、首元结点(第一个元素结点)。在单链表中设置头结点的作用是什么?
首元结点是指链表中存储线性表中第一个数据元素的结点。为了操作方便,通常在链表的首元结点之前附设一个结点,称为头结点,该结点的数据域中不存储线性表的数据元素,其作用是为了对链表进行操作时,可以对空表、非空表的情况以及对首元结点进行统一处理。头指针是指向链表中第一个结点(或为头结点或为首元结点)的指针。若链表中附设头结点,则不管线性表是否为空表,头指针均不为空,否则表示空表的链表的头指针为空。这三个概念对单链表、双向链表和循环链表均适用。是否设置头结点,是不同的存储结构表示同一逻辑结构的问题。
简而言之,
头指针是指向链表中第一个结点(或为头结点或为首元结点)的指针;
头结点是在链表的首元结点之前附设的一个结点,数据域为空或者只放空表标志和表长等附加信息。当头结点的指针域为“空”时,单链表为空链表。
首元结点是指链表中存储线性表中第一个数据元素的结点。
.
三、栈和队列
1、铁路进行列车调度时,常把站台设计成栈式结构的。试问:
(1) 设有编号为1, 2, 3, 4, 5, 6的六辆列车, 顺序开入栈式结构的站台, 则可能的出栈序列有多少种?
(2) 若进站的六辆列车顺序如上所述,那么是否能够得到435612,325641,154623和135426的出站序列,如果不能,说明为什么不能;如果能,说明如何得到(即写出"进栈"或"出栈"的序列)。
出栈序列数:卡特兰数 C 2 n n / ( n + 1 ) C^{n}_{2n}/(n+1) C2nn/(n+1).
出栈序列应满足:对序列中任何一个数其后面所有比它小的数应该是倒序的。

.
四、数组和广义表
1、试从空间复杂度和时间复杂度角度分析分别用邻接矩阵、三元组存储的稀疏矩阵进行转置运算的优劣之处。(彭波P116)
矩阵行数mu,列数nu,非零元素个数tu。
(1)邻接矩阵
邻接矩阵存储 = 二维数组顺序存储
邻接矩阵的转置通过两个for循环直接交换每个元素的行列值,时间复杂度为 O ( m u × n u ) O(mu×nu) O(mu×nu),空间复杂度为 O ( m u × n u ) O(mu×nu) O(mu×nu)。
(2)三元组
三元组存储的稀疏矩阵转置有两种实现方法:直接取-顺序存(“按需点菜”法、简单转置法)、顺序取-直接存(“按位就座”法、快速转置法)
i. 直接取-顺序存
算法中基本操作的执行次数主要依赖于嵌套的两个for循环,因此时间复杂度为 O ( n u × t u ) O(nu×tu) O(nu×tu)。
空间复杂度为O(tu)。
当矩阵中非零元素个数tu和其元素总数mu×nu同数量级时,时间复杂度为 O ( m u × n u 2 ) O(mu×nu^{2}) O(mu×nu2),其时间性能劣于一般矩阵转置算法,因此该算法仅适用于tu << mu×nu的情况。
ii. 顺序取-直接存
算法中的执行次数依赖于四个并列的for循环,时间复杂度为 O ( n u + t u ) O(nu+tu) O(nu+tu)。
存储空间增加了 num[col] 和 cpot[col] 两个数组,空间复杂度 O ( t u + n u ) O(tu+nu) O(tu+nu)。
当矩阵中非零元素个数tu和其元素总数 m u × n u mu×nu mu×nu同数量级时,时间复杂度为 O ( m u × n u ) O(mu×nu) O(mu×nu),与一般矩阵的转置算法一致,由此可见,该算法优于直接取-顺序存算法。
五、树和二叉树
1、树、二叉树、森林的遍历对应关系。
| 树 | 二叉树 | 森林 |
|---|---|---|
| 先序 | 先序 | 先序 |
| 后序 | 中序 | 中序 |
| 层序 |
层序不对应二叉树的任何遍历
森林的中序遍历 = 森林中各树的后序遍历
当二叉树存在度为1的结点时,先序和后序序列不能唯一确定二叉树的形状。
2、若平衡二叉树的高度为6,且所有非叶结点的平衡因子均为 1,则该平衡二叉树的结点总数为()。(构造6层平衡二叉树至少需要的结点数)

.
3、在结点个数为n(n>1)的各棵树中,(1)高度最小的树的高度是多少,有多少个叶结点,多少个分支结点。(2)高度最大的树的高度是多少,有多少个叶结点,多少个分支结点。
(1)高度最小为2,第一层为一个根结点,第二层为n-1个叶子结点,有1个分支结点(即根结点)。
(2)高度最大为n,即每一层上一个结点,有1个叶结点,n-1个分支结点。
附加:若要求树的度为m,则
(1)当树的高度最大时,最后一层为m个结点,其他每层一个结点,此时树的高度为n-m+1,有m个叶子结点,有n-m个分支结点。
(2)当树的高度最小时,每个非终端结点均有m个孩子结点,
总结点数 n ≤ 1 + m 1 + m 2 + . . . + m h − 1 = 1 − m h 1 − m = m h − 1 m − 1 n\le1+m^{1}+m^{2}+...+m^{h-1}=\frac{1-m^{h}}{1-m}=\frac{m^{h}-1}{m-1} n≤1+m1+m2+...+mh−1=1−m1−mh=m−1mh−1
所以 h ≥ ⌊ l o g m ( ( m − 1 ) n + 1 ) ⌋ h\ge \lfloor log_{m}((m-1)n+1) \rfloor h≥⌊logm((m−1)n+1)⌋.
叶子结点个数为 n 0 = 1 + n 2 + 2 n 3 + . . . + ( m − 1 ) n m n_{0}=1+n_{2}+2n_{3}+...+(m-1)n_{m} n0=1+n2+2n3+...+(m−1)nm (其中 n i n_{i} ni表示度为i的结点数)
分支结点个数为 n − n 0 n-n_{0} n−n0.
叶子结点数计算:
n = n 0 + n 1 + . . . + n m = 1 + n 1 + 2 n 2 + . . . m ∗ n m n=n_{0}+n_{1}+...+n_{m} = 1+n_{1}+2n_{2}+...m*n_{m} n=n0+n1+...+nm=1+n1+2n2+...m∗nm
所以 n 0 = 1 + n 2 + 2 n 3 + . . . + ( m − 1 ) n m n_{0}=1+n_{2}+2n_{3}+...+(m-1)n_{m} n0=1+n2+2n3+...+(m−1)nm.
4、试分别找出满足以下条件的所有二叉树。
(1)二叉树的前序序列与中序序列相同 。
(2)二叉树的中序序列与后序序列相同 。
(3)二叉树的前序序列与后序序列相同 。
前序和中序相同:只有右子树的二叉树,所有的分支均不包含左子树。
中序和后序相同:只有左子树的二叉树,所有的分支均不包含右子树。
前序和后序相同:只有一个根结点的二叉树。
六、图
1、证明:对于一个无向图 G=(V,E),若 G中各顶点的度均大于或等于 2,则 G中必有回路。
证1:(简答方法)若G中没有回路,则必有叶子节点(即度为1的节点),这与G中顶点度均大于等于2矛盾,所以G中必有回路。
.
证2:
反证:如果G中不存在回路,则必有一个节点的度为1。
可以说明:任意找一个节点,开始遍历,那么最终会访问到一个叶子节点。
任何一个访问到的节点u,存在以下3种情况:
(1)是叶子节点(证明结束);
(2)存在节点v,v尚未被访问,且边(u,v)存在,则继续访问v;
(3)任何与u有边相连的节点都已经被访问,这种情况会构成回路(与假设矛盾,证明结束)。
因为节点个数有限,所以只有有限次可能会落入情况2,随着遍历的进行,必然会落入情况1和3。
.
证3:
假设该图无环,那么图G中存在一条最长路径P,设起点为vs,终点为v;
考察v的邻点,易知v的所有邻点都在P上,否则,若u是v的一个不在P上的邻点,则最长路径为P+(vu),与最长路径为P矛盾;
由于G中每个顶点的度都大于等于2,故v存在一个顶点x,x在P上,但x与v在P上不相邻,此时路xPv与vx的并就是一个回路。
七、查找
1、同时具有较高的查找、插入和删除性能的数据结构是()

从表中可以看出,数组的删除性能比较差,而链表的查找性能比较差,平衡二叉树的查找、插入和删除性能都是 O(logN)。
哈希表的查找、插入和删除性能都是 O(1) ,都是最好的。
2、设有 150个记录要存储到 Hash表中,要求利用线性测试法解决冲突,同时要 求找到所需记录的平均比较次数不超过 2次,试问 Hash表需要设计多大?
设 α \alpha α是哈希表的装载因子,则有 A S L s u c c = 1 2 ( 1 + 1 1 − α ) ASL_{succ}=\frac{1}{2}(1+\frac{1}{1-\alpha}) ASLsucc=21(1+1−α1).
设表长为 L L L,则 α = 150 / L \alpha=150/L α=150/L,
要求 A S L s u c c = 1 2 ( 1 + 1 1 − α ) ≤ 2 ASL_{succ}=\frac{1}{2}(1+\frac{1}{1-\alpha})\leq2 ASLsucc=21(1+1−α1)≤2,得 α ≤ 2 / 3 \alpha\le2/3 α≤2/3,所以 L ≥ 225 L\ge225 L≥225.
3、哈希表HT[13],哈希函数 H(k)=k%13,关键字序列{12,23,45,57,20,03,78,31,15,36},用线性探测法和链地址法解决冲突,计算等概率下查找成功和失败的平均查找长度。
(1)线性探测法:
A
S
L
s
u
c
c
=
(
1
×
8
+
4
+
2
)
/
10
=
7
/
5
ASL_{succ}=(1×8+4+2)/10=7/5
ASLsucc=(1×8+4+2)/10=7/5
A
S
L
u
n
s
u
c
c
=
(
2
+
1
+
3
+
2
+
1
+
5
+
4
+
3
+
2
+
1
+
5
+
4
+
3
)
/
13
=
36
/
13
ASL_{unsucc}=(2+1+3+2+1+5+4+3+2+1+5+4+3)/13=36/13
ASLunsucc=(2+1+3+2+1+5+4+3+2+1+5+4+3)/13=36/13
(查找不成功时的查找次数:第n个位置到它后面第1个关键字为空的位置的距离。)
(2)链地址法:
首先计算序列的哈希值,H(k)={12,10,6,5,7,3,0,5,2,10}
链地址法图解:
0 ->78
1
2 ->15
3 ->03
4
5 ->57->31
6 ->45
7 ->20
8
9
10 ->23->36
11
12 ->12
所以
查找成功时,
A
S
L
s
u
c
c
=
(
8
∗
1
+
2
∗
2
)
/
10
=
6
/
5
ASL_{succ}=(8*1+2*2)/10=6/5
ASLsucc=(8∗1+2∗2)/10=6/5
查找不成功时,
第一次查找不成功:13-8=5
第二次查找不成功:13-2=11
A
S
L
u
n
s
u
c
c
=
(
5
∗
1
+
11
∗
2
)
/
13
=
27
/
13
ASL_{unsucc}=(5*1+11*2)/13=27/13
ASLunsucc=(5∗1+11∗2)/13=27/13
4、有序表顺序查找和折半查找的平均查找长度
顺序查找:
成功时:对于n个记录的顺序表,查找第 i i i个记录时,需要进行 n − i + 1 n-i+1 n−i+1次关键字的比较。设每个记录的查找概率相等,即 p i = 1 n ( 1 ≤ i ≤ n ) p_{i}=\frac{1}{n}(1\le i \le n) pi=n1(1≤i≤n),则在查找成功时,
A S L 成 功 = ∑ i = 1 n p i c i = 1 n ∑ i = 1 n ( n − i + 1 ) = ASL_{成功}=\sum_{i=1}^np_{i}c_{i}=\frac{1}{n}\sum_{i=1}^n(n-i+1)= ASL成功=∑i=1npici=n1∑i=1n(n−i+1)=(n+1)/2
.
不成功时:画出判定树,失败的一共有n+1个结点(n个结点的二叉树中空指针域有n+1个),所以每个结点的概率就是 1 n + 1 \frac{1}{n+1} n+11,比较次数是每个失败结点上一层的层数,所以查找不成功时,
A S L 不 成 功 = ( 1 + 2 + . . . + n + n ) 1 n + 1 = ( n ( n + 1 ) 2 + n ) 1 n + 1 = n 2 + n n + 1 ASL_{不成功}=(1+2+...+n+n)\frac{1}{n+1}=(\frac{n(n+1)}{2}+n)\frac{1}{n+1}=\mathbf{\frac{n}{2}+\frac{n}{n+1}} ASL不成功=(1+2+...+n+n)n+11=(2n(n+1)+n)n+11=2n+n+1n
.折半查找:
成功时:在折半查找中,用二叉树描述查找过程,查找区间中间位置( m i d = ( n + 1 ) / 2 mid=(n+1)/2 mid=(n+1)/2)作为根,左子表为左子树,右子表为右子树,因此这颗树被称为判定树(decision tree)或比较树(Comparison tree)。
在n个元素的折半查找判定树中,由于关键字序列是用树构建的,所以查找路径实际为树中从根节点到被查结点的一条路径,因为比较次数刚好为该元素在树中的层数。
设pi为查找ki的概率,level(ki)为ki对应内部结点的层次,则
A S L 成 功 = ∑ i = 1 n p i ∗ l e v e l ( k i ) ASL_{成功}=\sum_{i=1}^n p_{i}*level(k_{i}) ASL成功=∑i=1npi∗level(ki)
.
不成功时:查找不成功的过程就是走了一条从根结点到外部结点的路径,和给定值比较的关键字个数等于路径上内部结点的个数(即该外部结点层次减一)。(n个结点的二叉树,有n个内部结点,n+1个外部结点,也就是有n+1个空指针域)
设qi为待查找值ki属于外部结点的概率,level(ki)为对应外部结点的层次,则
A S L 不 成 功 = ∑ i = 1 n + 1 q i ∗ l e v e l ( k i ) ASL_{不成功}=\sum_{i=1}^{n+1}q_{i}*level(k_{i}) ASL不成功=∑i=1n+1qi∗level(ki)
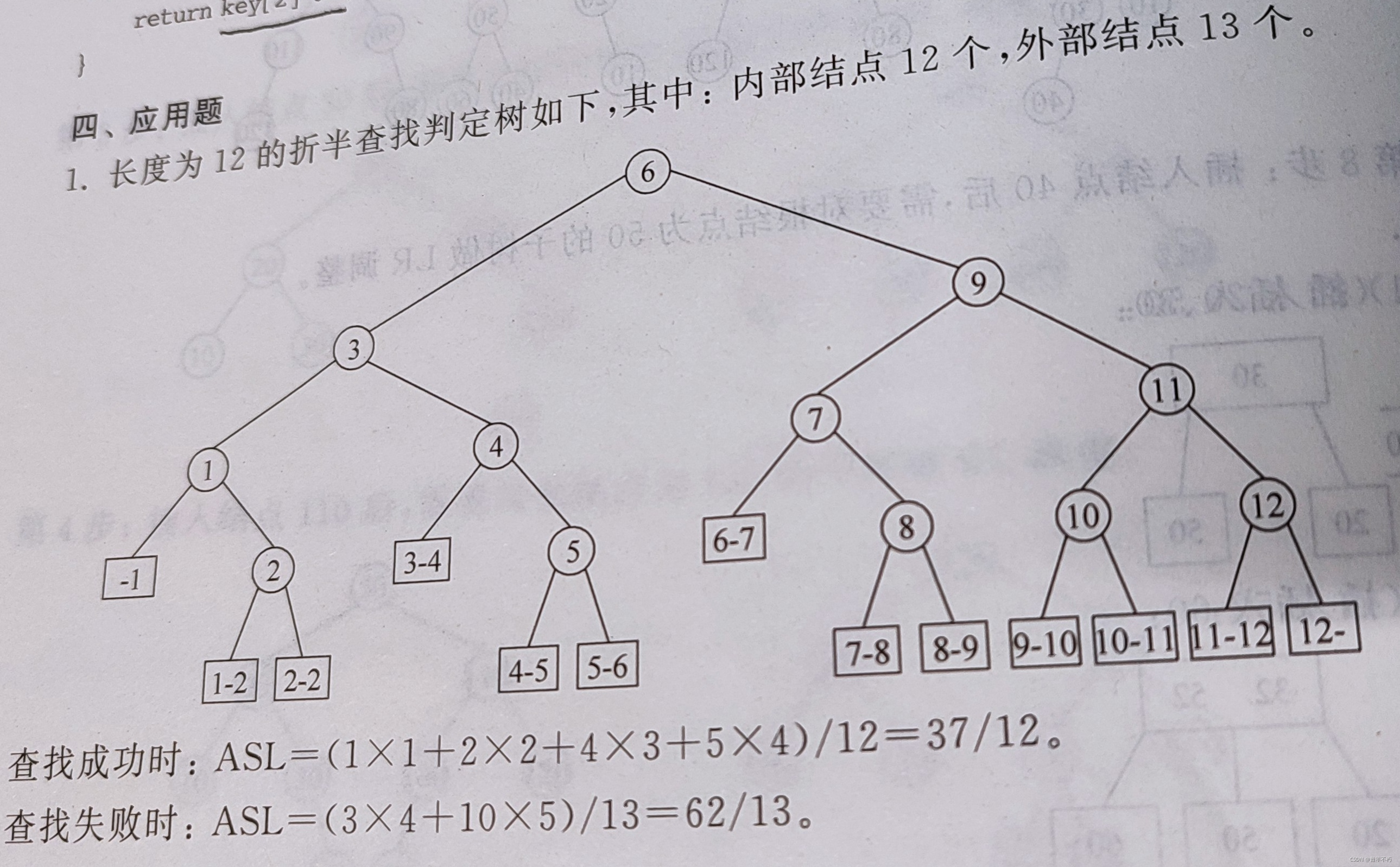
例题:给11个数据元素的有序表(2,3,10,15,20,25,28,29,30,35,40),采用折半查找,则查找成功和不成功时ASL分别是多少?
判定树:

查找成功时,
A
S
L
成
功
=
(
1
∗
1
+
2
∗
2
+
4
∗
3
+
4
∗
4
)
/
11
=
3
ASL_{成功}=(1*1+2*2+4*3+4*4)/11=3
ASL成功=(1∗1+2∗2+4∗3+4∗4)/11=3
查找不成功时,
A
S
L
不
成
功
=
(
4
∗
3
+
8
∗
4
)
/
12
=
11
/
3
ASL_{不成功}=(4*3+8*4)/12=11/3
ASL不成功=(4∗3+8∗4)/12=11/3
位于第4层上的3个外部结点查找次数为4-1=3次,位于第5层上的8个外部结点的查找次数为5-1=4次。
.
彭波P265四1:
彭波书上这里查找不成功时候是每层上的外部结点个数乘以该外部结点的层数。
至于哪个对,我觉得前面分析的有道理。但是考试是按这个书来,怎么取舍看自己吧。
.
八、排序
1、在冒泡排序过程中,什么情况下关键码会朝向与排序相反方向移动,试举例说明。
当待排序序列后面的若干关键码比前面的关键码小的时候,在冒泡排序过程中,关键码会朝向与排序相反方向移动。
比如待排序序列4,3,2,1
第一趟:3,2,1,4
第二趟:2,1,3,4
第三趟:1,2,3,4
其中,第一趟中3朝向其排序反方向,第二趟中2朝向其排序反方向。
2、各种排序算法性能比较。
| 算法 | 平均时间复杂度 | 最好时间复杂度 | 最坏时间复杂度 | 空间复杂度 | 稳定性 | 排序方式 |
|---|---|---|---|---|---|---|
| 直接插入排序 | O( n 2 n^{2} n2) | O(n) | O( n 2 n^{2} n2) | O(1) | 稳定 | 内部排序 |
| 希尔排序 | O( n l o g 2 n nlog_{2}n nlog2n) | O( n 1.3 n^{1.3} n1.3) | O( n 2 n^{2} n2) | O(1) | 不稳定 | 内部 |
| 冒泡排序 | O( n 2 n^{2} n2) | O(n) | O( n 2 n^{2} n2) | O(1) | 稳定 | 内部 |
| 快速排序 | O( n l o g 2 n nlog_{2}n nlog2n) | O( n l o g 2 n nlog_{2}n nlog2n) | O( n 2 n^{2} n2) | O( l o g 2 n log_{2}n log2n)~O(n) | 不稳定 | 内部 |
| 简单选择排序 | O( n 2 n^{2} n2) | O( n 2 n^{2} n2) | O( n 2 n^{2} n2) | O(1) | 不稳定 | 内部 |
| 堆排序 | O( n l o g 2 n nlog_{2}n nlog2n) | O( n l o g 2 n nlog_{2}n nlog2n) | O( n l o g 2 n nlog_{2}n nlog2n) | O(1) | 不稳定 | 外部 |
| 归并排序 | O( n l o g 2 n nlog_{2}n nlog2n) | O( n l o g 2 n nlog_{2}n nlog2n) | O( n l o g 2 n nlog_{2}n nlog2n) | O(n) | 稳定 | 外部 |
| 基数排序 | O(d(n+rd)) | O(d(n+rd)) | O(d(n+rd)) | O(n+rd) | 稳定 | 外部 |
| 计数排序 | O(n+k) | O(n+k) | O(n+k) | O(k) | 稳定 | 外部 |
| 桶排序 | O(n+k) | O(n+k) | O( n 2 n^{2} n2) | O(n+k) | 稳定 | 外部 |
(1)从时间复杂度角度比较
直接插入排序、冒泡排序、简单选择排序的时间复杂度为O(
n
2
n^{2}
n2),其中直接插入排序算法最常用,特别是对于已按关键字基本有序的记录序列。
快速排序、堆排序、归并排序的时间复杂度为O(
n
l
o
g
2
n
nlog_{2}n
nlog2n),其中快速排序被认为是目前最快的一种排序方法。
在待排序记录个数较多的情况下,归并排序比堆排序更快。
希尔排序的时间复杂度介于O(
n
2
n^{2}
n2)和O(
n
l
o
g
2
n
nlog_{2}n
nlog2n)之间。
从最好情况看,直接插入排序和冒泡排序的时间复杂度最好,为O(n),其他排序算法的最好情况和平均情况相同。
从最坏情况看,快速排序为O(
n
2
n^{2}
n2),直接插入排序和冒泡排序虽然与平均情况相同,都为O(
n
2
n^{2}
n2),但系数大约增加一倍,因此运行速度将降低一半;最坏情况对简单选择排序、堆排序和归并排序影响不大。
从平均时间性能看,快速排序最佳,所需时间最少。
(2)从空间复杂度角度比较
归并排序为O(n);快速排序为O(
l
o
g
2
n
log_{2}n
log2n)~O(n);
直接插入排序、希尔排序、冒泡排序、简单选择排序、堆排序的空间复杂度为O(1);
基数排序为O(n+rd)(其中rd为关键字的基数)。
(3)算法稳定性
直接插入排序、冒泡排序、归并排序、基数排序是稳定的;
希尔排序、快速排序、简单选择排序、堆排序是不稳定的(速记:“希尔快速选择堆”)。
一般说来,排序过程中的“比较”是在“相邻的两个记录关键字”之间进行的排序方法是稳定的。
(4)算法简单性
简单排序算法:直接插入排序、冒泡排序、简单选择排序。
改进排序算法:希尔排序、快速排序、堆排序、归并排序。
(5)待排序记录数n的大小
待排序记录数n越小,O(
n
2
n^{2}
n2)和O(
n
l
o
g
2
n
nlog_{2}n
nlog2n)的差距越小,且输入和调试简单算法比输入和调试改进算法要少用许多时间。
所以当n越小时,采用简单排序方法越合适;当n越大时,采用改进的排序方法越合适。
快速排序和归并排序在待排序记录数n较小时的性能不如直接插入排序,因此在实际应用时,可以将它们和直接插入排序“混合”使用。
(6)待排序记录本身信息量的大小
记录本身信息量越大,占用的存储空间就越多,移动记录所花费的时间就越多,所以对记录的移动次数较多的算法不利。
三种简单排序算法中记录移动次数的平均时间复杂度分别为:直接插入排序O(
n
2
n^{2}
n2),冒泡排序O(
n
2
n^{2}
n2),简单选择排序O(n)。当记录本身信息量较多时,对简单选择排序算法有利,对直接插入排序和冒泡排序算法不利 。
四种改进排序算法中,记录本身信息量大小对它们的影响不大。
(7)待排序记录关键字的分布情况
当待排序记录序列为正序时,直接插入排序、冒泡排序能达到O(n)的时间复杂度,而对于快速排序而言是最坏情况,它将蜕化为冒泡排序,时间复杂度蜕化为O(
n
2
n^{2}
n2)。
简单选择排序、堆排序和归并排序的时间性能不随记录序列中关键字的分布而改变。
几种排序方法选择建议:
①待排序记录数n较大、关键字分布较随机、且对稳定性不做要求时,采用快速排序为宜。
②待排序记录数n较大、内存空间允许、且要求排序稳定时,采用归并排序为宜。
③待排序记录数n较大、关键字分布可能出现正序或逆序的情况,采用堆排序或归并排序为宜。
④待排序记录数n较大、只要找出最小的前几个记录时,采用堆排序或简单选择排序为宜。
⑤待排序记录数n较小、记录已基本有序、且要求稳定时,采用直接插入排序为宜。
⑥待排序记录数n较小、记录所含数据项较多、所占存储空间较大时,采用简单选择排序为宜。
⑦待排序记录数n较大、关键字值较小、关键字具有字符串和整数这类有明显结构特征时,采用基数排序为宜。
参考:
彭波.数据结构——基于C语言的描述
十大经典排序算法动画与解析
3、已知下列各种初始状态(长度为N)的记录关键字序列,试问当利用直接插入排序进行排序时,至少需要进行多少次比较。(要求排序后记录由小到大顺序排列)(彭波数据结构P296 三5)
(1)关键字从小到大排序。
n-1次。插入第i(2≤i≤n)个元素比较次数为1,总比较次数为1+1+…+1=n-1.
(2)关键字从大到小排序。
(n-1) ∗ * ∗(n+2)/2次。插入第i(2≤i≤n)个元素比较次数为i,总比较次数为2+3+…+n=(n-1)*(n+2)/2.
(3)奇数关键字顺序有序,偶数关键字顺序有序。
n-1次。比较次数最少的情况是所有记录关键字按升序排列,和(1)的情况相同,总比较次数为n-1.
(4)前半部分元素按关键字有序,后半部分元素按关键字有序。
n-1次。后半部分元素关键字均大于前半部分元素关键字时比较次数最少,此时和(1)的情况相同,总比较次数为n-1.
4、构造排序 5 个整数最多用 7 次比较的算法。
5、假设对 5 个不同记录关键字排序,则至少需要比较___4___次,至多需要比较__10__次。
至少需要比较4次(当有序的时候),
至多需要比较10次(两两比较,4+3+2+1=10)。
.
插入排序:最少n-1次,最多n(n-1)/2次
冒泡排序:最少n-1次,最多n(n-1)/2次
选择排序 :n(n-1)/2次
快速排序:NlogN ~ N^2
归并排序:NlogN ~ (2N-1)logN

















 3349
3349

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









