







EasyExcel生成带下拉列表或二级级联列表的Excel模版+自定义校验导入数据(附仓库)
系列文章
前言
项目需求, 导入数据的Excel模版使用下拉数据限制用户输入, 以配合服务端的数据模型; 支持级联处理
模块基于Spring AOP能力, 参考 Pig4Cloud 项目的Excel模块, 在请求和响应时, 通过AOP能力将数据封装, 实现类似 @RequestBody 等注解的能力, 具体体现为: 收到请求时, 将Excel中的记录直接封装为集合, 响应时将数据序列化生成Excel文件等. 但这不是本文主要讨论的要点, 这里不赘述. 但本质还是基于EasyExcel的, 其原生方式照样写.
新版本主要变化: 优化部分设计和实现逻辑, 清晰命名, 改用SpEL替换指定接口等. 并更新本文的生成下拉部分内容.
下面将着重说明如何生成带下拉菜单的Excel文件.
一、说明
仓库: excel-common-spring-boot-starter (请参考最新代码, 文档内容更新不会很勤快, 没License看得上就随便用)
- 新版使用SpEL技术: SpEL Documentation 用起来很简单, 别怕
- EasyExcel文档: EasyExcel Documentation
- 多级级联无非就是任意相邻两级为二级级联而已.
- 不要同时使用@ExcelProperty的Index和order.
二、实现
本节可完全通过单纯使用EasyExcel实现
2.1 注解
2.1.1 @ExcelSelect
- 通过ExcelOptions定义下拉数据
- 指定父列名称生成级联下拉
- 后三个属性主要是配合validation的设计, 做校验
/**
* @author hp
*/
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.FIELD)
@Inherited
@Constraint(validatedBy = ExcelSelectConstraintValidator.class)
public @interface ExcelSelect {
@MethodDesc("下拉项")
ExcelOptions options();
@MethodDesc("父列列名")
String parentColumnName() default "";
@MethodDesc("设置下拉的起始行,默认为第二行")
int firstRow() default 1;
@MethodDesc("设置下拉的结束行")
int lastRow() default 0x10000;
@MethodDesc("校验相关,提示信息")
String message() default "请填写规定范围的值";
@MethodDesc("校验相关,分组")
Class<?>[] groups() default {};
@MethodDesc("校验相关,元数据")
Class<? extends Payload>[] payload() default {};
}
2.1.2 @ExcelOptions
- 定义下拉数据, 通过SpEL表达式的方式指定数据源
- Convention:
- 普通下拉返回
Collection<Object>及子类 - 级联第一级看作普通下拉
- 级联第二级开始返回
Map<Object, Collection<Object>>及子类- key为父级元素
- 普通下拉返回
- Convention:
- 后续迭代将增加传递自定义查询条件的支持
- @Language由IDE依赖提供语义解析
/**
* @author hp
*/
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.FIELD)
@Inherited
public @interface ExcelOptions {
@MethodDesc("动态数据, 通过SpEL表达式加载")
@Language("SpEL")
String expression() default "";
}
2.2 下拉元数据对象
2.2.1 抽象
- 获取表头层级
- 后续迭代, 取所有列中的最大层级, 目前根据每列实际情况取也没问题
- 获取下拉数据, 通过SpEL解析, 代码里的SpELHelper在结尾附录提供
- 记录列索引
- 可用下拉范围等
/**
* @author hp
* @date 2022/11/7
*/
@Slf4j
@Getter
@Setter
public abstract class AbstractExcelSelectModel<T> {
protected int headLayerCount;
protected T options;
protected String columnName;
protected int columnIndex;
protected String parentColumnName;
protected int parentColumnIndex;
protected int firstRow;
protected int lastRow;
public AbstractExcelSelectModel(@Nonnull Field field, @Nonnull ExcelSelect excelSelect, @Nullable ExcelProperty excelProperty, int defaultSort, @Nullable Map<String, Object> parameters) {
final Optional<ExcelProperty> excelPropertyOpt = Optional.ofNullable(excelProperty);
this.headLayerCount = excelPropertyOpt.map(property -> property.value().length).orElse(1);
this.firstRow = Math.max(excelSelect.firstRow(), this.headLayerCount);
this.lastRow = excelSelect.lastRow();
this.parentColumnName = excelSelect.parentColumnName();
this.columnName = excelPropertyOpt.map(property -> property.value()[this.headLayerCount - 1]).orElse(field.getName());
this.columnIndex = excelPropertyOpt.map(property -> property.index() > -1 ? property.index() : defaultSort).orElse(defaultSort);
this.options = resolveOptions(excelSelect, parameters);
}
public boolean hasParentColumn() {
return StrUtil.isNotEmpty(this.parentColumnName);
}
@SuppressWarnings("unchecked")
@Nullable
protected T resolveOptions(@Nonnull ExcelSelect excelSelect, @Nullable Map<String, Object> parameters) {
final ExcelOptions excelOptions = excelSelect.options();
if (StrUtil.isEmpty(excelOptions.expression())) {
log.warn("The ExcelSelect on {} has no options whatsoever.", this.columnName);
return null;
}
final SpELHelper spELHelper = SpringUtil.getBean(SpELHelper.class);
return (T) spELHelper.newGetterInstance(excelOptions.expression()).apply(
null,
(evaluationContext -> Optional.ofNullable(parameters).ifPresent(map -> map.forEach(evaluationContext::setVariable)))
);
}
}
2.2.2 常规下拉元数据对象
- Convention
/**
* @author hp
* @date 2022/11/7
*/
@EqualsAndHashCode(callSuper = false)
public class ExcelSelectModel extends AbstractExcelSelectModel<Collection<Object>> {
public ExcelSelectModel(@NotNull Field field, @NotNull ExcelSelect excelSelect, @Nullable ExcelProperty excelProperty, int defaultSort, @Nullable Map<String, Object> parameters) {
super(field, excelSelect, excelProperty, defaultSort, parameters);
}
}
2.2.3 级联下拉元数据对象
- Convention
/**
* @author hp
* @date 2022/11/7
*/
@EqualsAndHashCode(callSuper = false)
public class ExcelCascadeModel extends AbstractExcelSelectModel<Map<Object, Collection<Object>>> {
public ExcelCascadeModel(@NotNull Field field, @NotNull ExcelSelect excelSelect, @Nullable ExcelProperty excelProperty, int defaultSort, @Nullable Map<String, Object> parameters) {
super(field, excelSelect, excelProperty, defaultSort, parameters);
}
}
2.3 解析模版类并配置处理器
2.3.1 解析并构建元数据
- 主要逻辑是在Enhance类中配置 ExcelWriterBuilder 或 ExcelWriterSheetBuilder 而已, 很简单
- Enhance类主要是为了配合@ResponseExcel的处理逻辑而已
- 原生EasyExcel只需要针对上述两个Builder配置对应的SelectData处理器即可
/**
* @author hp
*/
@Slf4j
public class ExcelSelectExcelWriterBuilderEnhance implements ExcelWriterBuilderEnhance {
protected final AtomicInteger selectionColumnIndex = new AtomicInteger(0);
protected Map<Class<?>, Map<Integer, ? extends AbstractExcelSelectModel<?>>> selectionMapMapping = Maps.newHashMap();
@SuppressWarnings("unchecked")
@Override
public ExcelWriterBuilder enhanceExcel(
ExcelWriterBuilder writerBuilder,
ResponseExcel responseExcel,
Collection<? extends Class<?>> dataClasses,
HttpServletRequest request,
HttpServletResponse response
) {
final Object attribute = Objects.requireNonNull(request).getAttribute(ExcelConstants.DROPDOWN_QUERY_PARAMS_ATTRIBUTE_KEY);
final Map<String, Object> parameters = Optional.ofNullable(attribute)
.map(attr -> {
Preconditions.checkArgument(attr instanceof Map<?, ?>);
return (Map<String, Object>) attribute;
}).orElse(null);
dataClasses.forEach(dataClass -> selectionMapMapping.put(dataClass, ExcelSelectHelper.createSelectionMapping(dataClass, parameters)));
return writerBuilder.registerWriteHandler(new SelectDataWorkbookWriteHandler());
}
@Override
public ExcelWriterSheetBuilder enhanceSheet(
ExcelWriterSheetBuilder writerSheetBuilder,
Integer sheetNo,
String sheetName,
Class<?> dataClass,
Class<? extends HeadGenerator> headEnhancerClass,
String templatePath) {
if (selectionMapMapping.containsKey(dataClass)) {
final Map<Integer, ? extends AbstractExcelSelectModel<?>> selectionMapping = selectionMapMapping.get(dataClass);
writerSheetBuilder.registerWriteHandler(new SelectDataSheetWriteHandler(selectionColumnIndex, selectionMapping));
}
return writerSheetBuilder;
}
}
2.3.2 workbook处理器
- 仅创建一个Sheet用于存放所有的下拉数据
- ExcelHelper 将在 附录 中提供
/**
* @author hp
*/
@Slf4j
public class SelectDataWorkbookWriteHandler implements WorkbookWriteHandler {
@Override
public void afterWorkbookCreate(WriteWorkbookHolder writeWorkbookHolder) {
final Sheet sheet = ExcelHelper.createSheet(writeWorkbookHolder.getWorkbook(), ExcelConstants.SELECTION_HOLDER_SHEET_NAME, true);
ExcelHelper.hideSheet(writeWorkbookHolder.getWorkbook(), sheet);
}
}
2.3.3 sheet处理器
- 原生方式也需要提供一个计数器, 记录生成下拉到哪列
/**
* @author hp
*/
@Slf4j
public class SelectDataSheetWriteHandler implements SheetWriteHandler {
protected final AtomicInteger selectionColumnIndex;
protected final Map<Integer, ? extends AbstractExcelSelectModel<?>> selectionMapping;
public SelectDataSheetWriteHandler(
AtomicInteger selectionColumnIndex,
Map<Integer, ? extends AbstractExcelSelectModel<?>> selectionMapping
) {
this.selectionColumnIndex = selectionColumnIndex;
this.selectionMapping = selectionMapping;
}
@Override
public void afterSheetCreate(WriteWorkbookHolder writeWorkbookHolder, WriteSheetHolder writeSheetHolder) {
final Workbook workbook = writeWorkbookHolder.getWorkbook();
final Sheet sheet = writeSheetHolder.getSheet();
selectionMapping.forEach((colIndex, model) -> {
if (model.hasParentColumn()) {
ExcelHelper.addCascadeDropdownToSheet(
workbook,
sheet,
writeWorkbookHolder.getWorkbook().getSheet(ExcelConstants.SELECTION_HOLDER_SHEET_NAME),
selectionColumnIndex,
(ExcelCascadeModel) model
);
} else {
ExcelHelper.addDropdownToSheet(
sheet,
writeWorkbookHolder.getWorkbook().getSheet(ExcelConstants.SELECTION_HOLDER_SHEET_NAME),
selectionColumnIndex,
(ExcelSelectModel) model
);
}
});
}
}
三、用例
3.1 生成模版
3.1.1 模版类
这个类比较特殊
- 多级表头
- 复用级联数据方法
/**
* @author hp
*/
@EqualsAndHashCode(callSuper = true)
@Data
public class MultipleLayersOfHeaderExcelTemplate extends ExcelTemplate {
private static final String _1ST_LAYER_HEADER = "公共标题";
@ExcelProperty({_1ST_LAYER_HEADER, "普通列"})
private String regularColumn;
@ExcelSelect(
options = @ExcelOptions(expression = "@excelSelectStaticDataHandler.findAll()")
)
@ExcelProperty({_1ST_LAYER_HEADER, "静态单列下拉列表"})
private Integer staticSelectColumn;
@ExcelSelect(
options = @ExcelOptions(expression = "@excelSelectDynamicDataHandler.findAll()")
)
@ExcelProperty({_1ST_LAYER_HEADER, "动态单列下拉列表"})
private LocalDate dynamicSelectColumn;
@ExcelSelect(
options = @ExcelOptions(expression = "@excelSelectDynamicParentDataHandler.findAll()")
)
@ExcelProperty({_1ST_LAYER_HEADER, "级联下拉列表第一级"})
private String dynamicSelectPrimaryColumn;
@ExcelSelect(
parentColumnName = "级联下拉列表第一级",
options = @ExcelOptions(expression = "@excelSelectDynamicChildDataHandler.findAllV2()")
)
@ExcelProperty({_1ST_LAYER_HEADER, "级联下拉列表第二级"})
private Integer dynamicSelectSecondaryColumn;
@ExcelSelect(
options = @ExcelOptions(expression = "@excelSelectDynamicParentDataHandler.findAll()")
)
@ExcelProperty("级联下拉列表第一级复用,在同一个sheet")
private String dynamicSelectPrimaryColumn2;
@ExcelSelect(
parentColumnName = "级联下拉列表第一级复用,在同一个sheet",
options = @ExcelOptions(expression = "@excelSelectDynamicChildDataHandler.findAllV2()")
)
@ExcelProperty("级联下拉列表第二级复用,在同一个sheet")
private Integer dynamicSelectSecondaryColumn2;
}
3.1.2 加载下拉
/**
* @author hp
*/
@Component
public class ExcelSelectDynamicParentDataHandler {
public List<String> findAll() {
return List.of("A","B","C");
}
}
/**
* @author hp
*/
@Component
public class ExcelSelectDynamicChildDataHandler {
public Map<String, List<Integer>> findAll() {
final Map<String, List<Integer>> map = Maps.newHashMap();
map.put("A",List.of(10,20,30));
map.put("B",List.of(100,200,300));
return map;
}
public Map<String, List<String>> findAllV2() {
final Map<String, List<String>> map = Maps.newHashMap();
map.put("A",List.of("一","二","三"));
map.put("B",List.of("一百","二百","三百"));
return map;
}
}
3.1.3 框架用例
- 复用级联数据
- 多级表头
- 不写@ExcelProperty
- 多个sheet
- etc.
@Slf4j
@RestController
public class ExcelExampleController {
@PostMapping("/upload")
public String upload(
@RequestExcel(filename = "upload_file") List<DummyModel> dataSet
) {
Assert.isTrue(CollUtil.isNotEmpty(dataSet), "dataSet is empty");
dataSet.forEach(System.out::println);
return "Successfully uploaded";
}
@Data
public static class DummyModel {
@ExcelProperty("公司名称")
private String a;
@ExcelProperty("适用集团标准控制点")
private String b;
@ExcelProperty("适用率")
private String c;
@ExcelProperty("不适用内控点")
private String d;
@ExcelProperty("个性化内控点")
private String e;
@ExcelProperty("IT固化率")
private String f;
@ExcelProperty("固化程度强")
private String g;
@ExcelProperty("固化程度中")
private String h;
@ExcelProperty("固化程度弱")
private String i;
}
@ResponseExcel(
name = "RegularWithoutExcelPropertyExcelTemplate",
sheets = {
@Sheet(sheetName = "sheet", sheetNo = 0),
},
enhancement = {ExcelSelectExcelWriterBuilderEnhance.class}
)
@PostMapping("template/sheet/single/RegularWithoutExcelPropertyExcelTemplate")
public List<RegularWithoutExcelPropertyExcelTemplate> singleSheet2() {
return Collections.singletonList(new RegularWithoutExcelPropertyExcelTemplate());
}
@ResponseExcel(
name = "ReuseCascadeOnTheSameSheetExcelTemplate",
sheets = {
@Sheet(sheetName = "sheet", sheetNo = 0),
},
enhancement = {ExcelSelectExcelWriterBuilderEnhance.class}
)
@PostMapping("template/sheet/single/ReuseCascadeOnTheSameSheetExcelTemplate")
public List<ReuseCascadeOnTheSameSheetExcelTemplate> singleSheet3() {
return Collections.singletonList(new ReuseCascadeOnTheSameSheetExcelTemplate());
}
@ResponseExcel(
name = "MultipleLayersOfHeaderExcelTemplate",
sheets = {
@Sheet(sheetName = "sheet", sheetNo = 0),
},
enhancement = {ExcelSelectExcelWriterBuilderEnhance.class}
)
@PostMapping("template/sheet/single/MultipleLayersOfHeaderExcelTemplate")
public List<MultipleLayersOfHeaderExcelTemplate> singleSheet4() {
return Collections.singletonList(new MultipleLayersOfHeaderExcelTemplate());
}
@ResponseExcel(
name = "MultipleSheet",
sheets = {
@Sheet(sheetName = "sheet", sheetNo = 0),
@Sheet(sheetName = "sheet2", sheetNo = 1)
},
enhancement = {ExcelSelectExcelWriterBuilderEnhance.class}
)
@PostMapping("template/sheet/multiple")
public List<List<ExcelTemplate>> multipleSheets() {
return Lists.newArrayList(Collections.singletonList(new MultipleSheetNo1ExcelTemplate()), Collections.singletonList(new MultipleSheetNo2ExcelTemplate()));
}
}
3.1.4 EasyExcel用例
- 多个sheet
@Slf4j
@RestController
public class ExcelExampleController {
@PostMapping("/easyexcel/template")
public void template(HttpServletRequest request, HttpServletResponse response) {
String filename = "文件名称";
final AtomicInteger index = new AtomicInteger(0);
String userAgent = request.getHeader("User-Agent");
if (userAgent.contains("MSIE") || userAgent.contains("Trident")) {
// 针对IE或者以IE为内核的浏览器:
filename = java.net.URLEncoder.encode(filename, StandardCharsets.UTF_8);
} else {
// 非IE浏览器的处理:
filename = new String(filename.getBytes(StandardCharsets.UTF_8), StandardCharsets.ISO_8859_1);
}
response.setContentType("application/vnd.ms-excel");
response.setHeader("Content-disposition", String.format("attachment; filename=\"%s\"", filename + ".xlsx"));
response.setHeader("Cache-Control", "no-cache");
response.setHeader("Pragma", "no-cache");
response.setDateHeader("Expires", -1);
response.setCharacterEncoding("UTF-8");
final ExcelWriterBuilder excelWriterBuilder;
try {
excelWriterBuilder = EasyExcel.write(response.getOutputStream());
} catch (IOException e) {
throw new RuntimeException(e);
}
try (
ExcelWriter excelWriter = excelWriterBuilder
.registerWriteHandler(
new SelectDataWorkbookWriteHandler()
)
.build()
) {
WriteSheet writeSheet = EasyExcel
.writerSheet(0, "sheet名称")
.head(MultipleSheetNo1ExcelTemplate.class)
.registerWriteHandler(new SelectDataSheetWriteHandler(index, createSelectionMapping(MultipleSheetNo1ExcelTemplate.class)))
.build();
excelWriter.write(new ArrayList<String>(), writeSheet);
WriteSheet writeSheet2 = EasyExcel
.writerSheet(1, "sheet名称2")
.head(MultipleSheetNo2ExcelTemplate.class)
.registerWriteHandler(new SelectDataSheetWriteHandler(index, createSelectionMapping(MultipleSheetNo2ExcelTemplate.class)))
.build();
excelWriter.write(new ArrayList<String>(), writeSheet2);
excelWriter.finish();
} catch (Exception e) {
log.error("导出Excel文件异常", e);
}
}
@Nullable
private static <T> Map<Integer, ? extends AbstractExcelSelectModel<?>> createSelectionMapping(@Nonnull Class<T> dataClass) {
final Field[] fields = ReflectUtil.getFields(dataClass);
final AtomicInteger fieldIndex = new AtomicInteger(1);
final Map<Integer, ? extends AbstractExcelSelectModel<?>> selectionMapping = Arrays.stream(fields)
.map(field -> {
final ExcelSelect excelSelect = AnnotatedElementUtils.getMergedAnnotation(field, ExcelSelect.class);
if (Objects.isNull(excelSelect)) {
log.debug("No ExcelSelect annotated on {}, skip processing", field.getName());
return null;
}
final ExcelProperty excelProperty = AnnotatedElementUtils.getMergedAnnotation(field, ExcelProperty.class);
AbstractExcelSelectModel<?> excelSelectModel;
if (StrUtil.isNotEmpty(excelSelect.parentColumnName())) {
excelSelectModel = new ExcelCascadeModel(field, excelSelect, excelProperty, fieldIndex.getAndIncrement());
} else {
excelSelectModel = new ExcelSelectModel(field, excelSelect, excelProperty, fieldIndex.getAndIncrement());
}
return excelSelectModel;
})
.filter(Objects::nonNull)
.collect(Collectors.toMap(AbstractExcelSelectModel::getColumnIndex, Function.identity(), (a, b) -> a));
if (MapUtil.isEmpty(selectionMapping)) {
return null;
}
// 设置父列索引
final Map<String, Integer> columnNamedMapping = selectionMapping.values()
.stream()
.collect(Collectors.toMap(AbstractExcelSelectModel::getColumnName, AbstractExcelSelectModel::getColumnIndex));
selectionMapping.forEach((k, v) -> {
if (v.hasParentColumn() && columnNamedMapping.containsKey(v.getParentColumnName())) {
v.setParentColumnIndex(columnNamedMapping.get(v.getParentColumnName()));
}
});
return selectionMapping;
}
}
3.2 效果图
3.2.1 业务sheet
子级通过Indirect关联父级内容
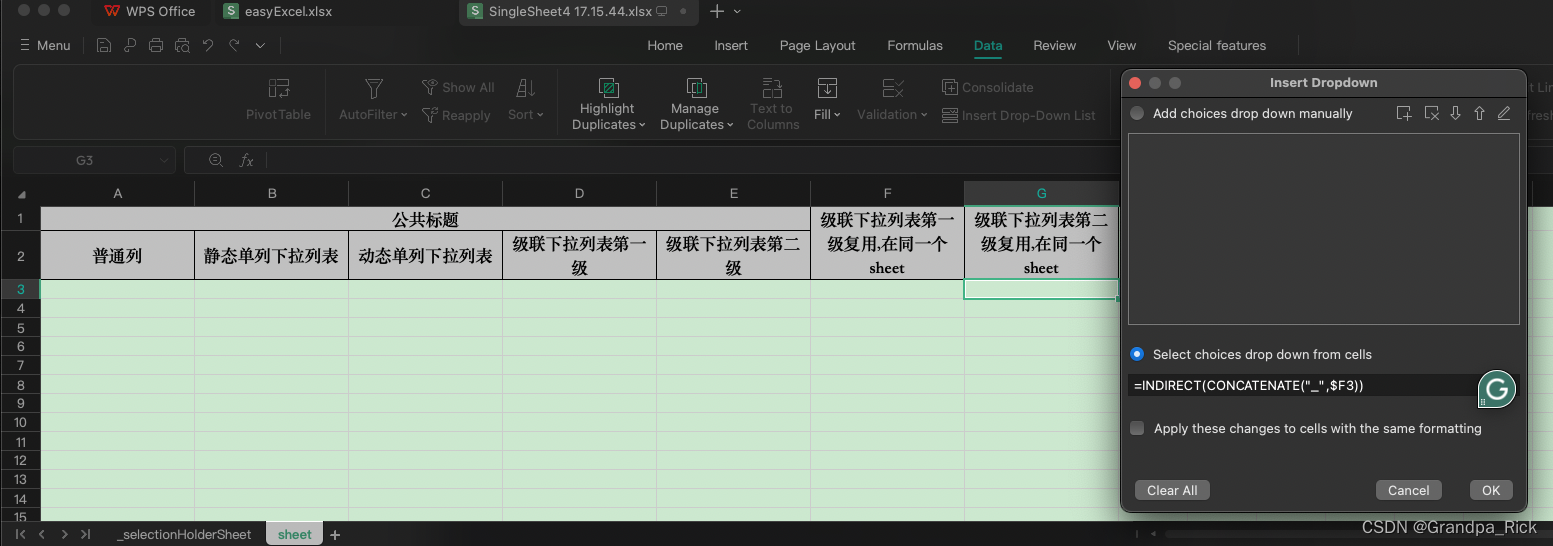
数据校验
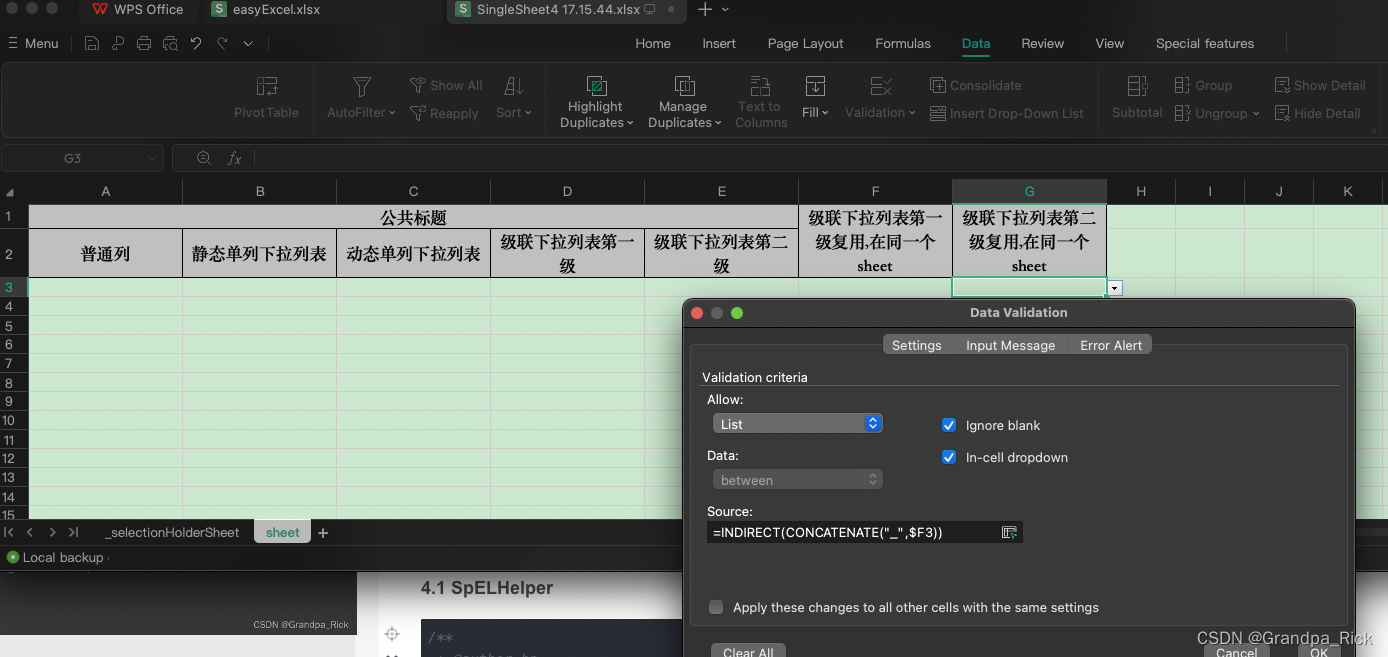
多个sheet场景, 名称管理器的作用域为sheet
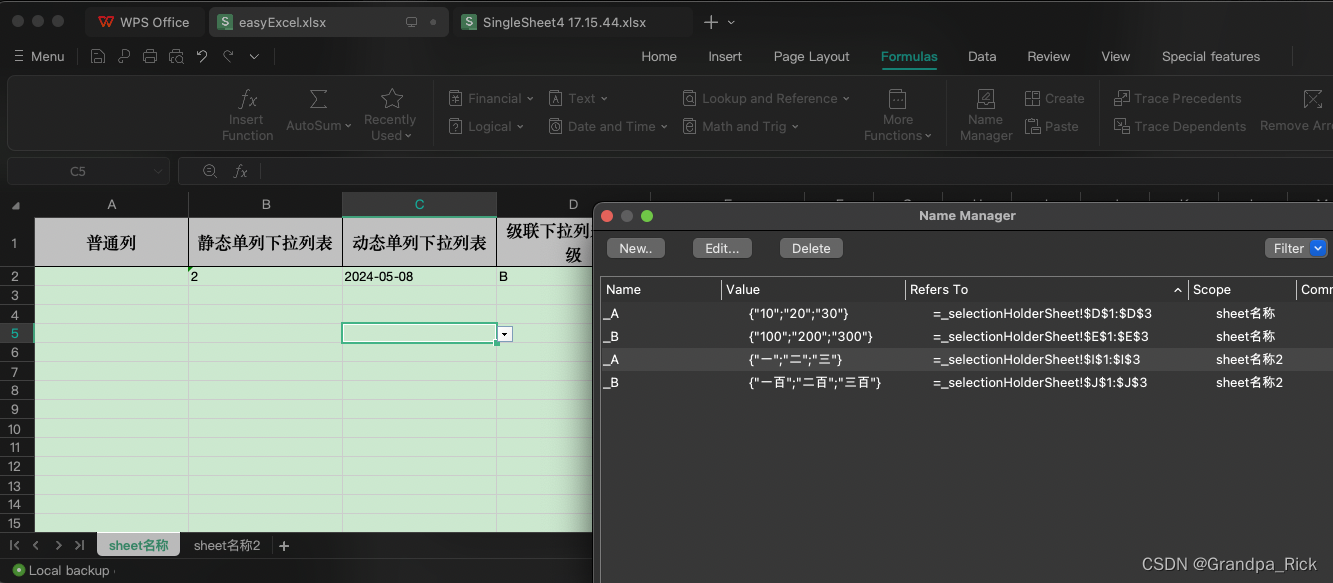
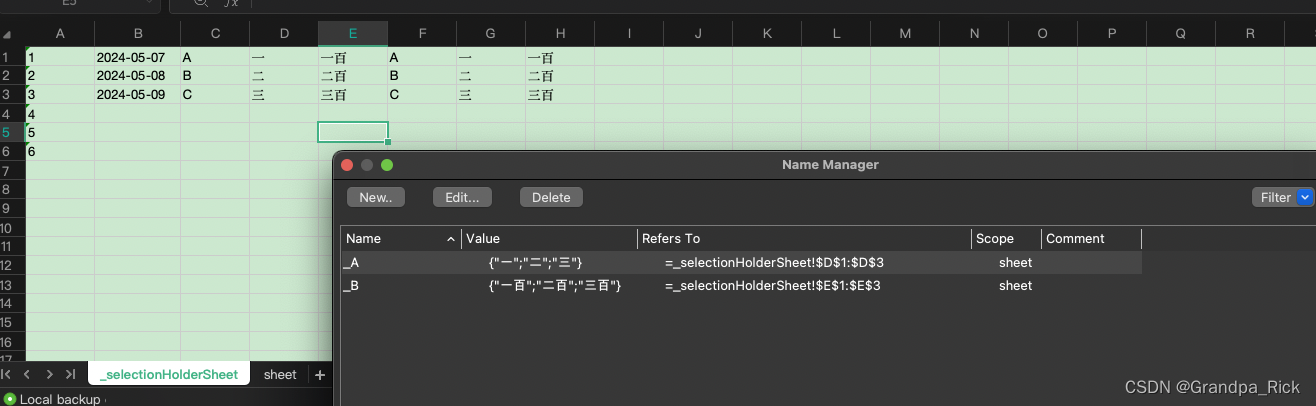
3.2.2 下拉sheet
- 支持Cell.setCellValue()中的最基本的那几种数据类型
- String
- double
- Date
- LocalDate
- LocalDateTime
- Calendar
- RichTextString
四、附录
4.1 SpELHelper
/**
* 很多判断是Groovy语法
* <p>
* Tips:
* <ul>
* <li>字符串单引号. 可以调用方法或访问属性</li>
* <li>属性首字母大小写不敏感</li>
* <li>集合元素: Map用 {@code map['key']} 获取元素, Array/List用 {@code 集合名称[index]} 获取元素</li>
* <li>定义List: {@code {1,2,3,4} 或 {{'a','b'},{'x','y'}} }</li>
* <li>instance of: {@code 'xyz' instanceof T(int)}</li>
* <li>正则: {@code '字符串' matches '正则表达式'}</li>
* <li>逻辑运算符: {@code !非 and与 or或}</li>
* <li>类型: {@code java.lang包下直接用, 其他的要用T(全类名)}</li>
* <li>构造器: {@code new 全类名(构造参数)}</li>
* <li>变量: StandardEvaluationContext当中的变量 {@code #变量名称 }</li>
* <li>#this: 当前解析的对象</li>
* <li>#root: 上下文的根对象</li>
* <li>Spring Bean引用: {@code @beanName} </li>
* <li>三元表达式和Java一样</li>
* <li>Elvis Operator: {@code Names?:'Unknown'} Names为空提供默认值</li>
* <li>防NPE操作符: {@code PlaceOfBirth?.City} 如果为NULL 防止出现NPE</li>
* <li>筛选集合元素: {@code 集合.?[筛选条件]} 如果是Map集合,Map.Entry为当前判断对象</li>
* <li>筛选第一个满足集合元素: {@code 集合.^[筛选条件]}</li>
* <li>筛选最后一个满足集合元素: {@code 集合.$[筛选条件]}</li>
* <li>集合映射,类似StreamAPI的map()再collect(): 使用语法 {@code 集合.![映射规则]}, Map集合类似上述说明</li>
* <li>表达式模版: 默认{@code #{} }, 指定解析模版内部的内容</li>
* </ul>
*
* @author hp
*/
@Slf4j
@Configuration
public class SpELHelper implements ApplicationContextAware {
private BeanResolver beanResolver;
private final ExpressionParser expressionParser = new SpelExpressionParser();
private final ParserContext parserContext = ParserContext.TEMPLATE_EXPRESSION;
@Override
public void setApplicationContext(@NonNull ApplicationContext applicationContext) throws BeansException {
this.beanResolver = new BeanFactoryResolver(applicationContext);
}
public <T, R> StandardSpELGetter<T, R> newGetterInstance(String expression) {
return new StandardSpELGetterImpl<>(expression, new StandardEvaluationContext());
}
public <T, R> StandardSpELGetter<T, R> newGetterInstance(String expression, EvaluationContext evaluationContext) {
return new StandardSpELGetterImpl<>(expression, evaluationContext);
}
public <T, R> StandardSpELSetter<T, Collection<R>> newSetterInstance(Field field) {
return new StandardSpELSetterImpl<>(field);
}
public <T, R> StandardSpELSetter<T, Collection<R>> newSetterInstance(Field field, EvaluationContext evaluationContext) {
return new StandardSpELSetterImpl<>(field, evaluationContext);
}
public interface StandardSpELGetter<T, R> extends Function<T, R> {
R apply(T t, @Nullable Visitor<EvaluationContext> visitor);
static <T> StandardSpELGetter<T, T> identity() {
return new StandardSpELGetter<>() {
@Override
public T apply(T t, @Nullable Visitor<EvaluationContext> visitor) {
return t;
}
@Override
public T apply(T t) {
return t;
}
};
}
}
public interface StandardSpELSetter<T, R> extends BiConsumer<T, R> {
void accept(T target, R result, @Nullable Visitor<EvaluationContext> visitor);
}
public class StandardSpELGetterImpl<T, R> implements StandardSpELGetter<T, R> {
private final Expression expression;
private final EvaluationContext evaluationContext;
private StandardSpELGetterImpl(String expression) {
this(expression, new StandardEvaluationContext());
}
private StandardSpELGetterImpl(String expression, EvaluationContext evaluationContext) {
if (StrUtil.isNotEmpty(expression) && expression.startsWith(parserContext.getExpressionPrefix())) {
this.expression = expressionParser.parseExpression(expression, parserContext);
} else {
this.expression = expressionParser.parseExpression(expression);
}
this.evaluationContext = Objects.requireNonNull(evaluationContext);
if (this.evaluationContext instanceof StandardEvaluationContext standardEvaluationContext) {
standardEvaluationContext.setBeanResolver(beanResolver);
// standardEvaluationContext.setTypeConverter(new StandardTypeConverter());
}
}
@SuppressWarnings("unchecked")
@Override
public R apply(T data, @Nullable Visitor<EvaluationContext> visitor) {
Optional.ofNullable(visitor).ifPresent(v -> v.visit(evaluationContext));
return (R) expression.getValue(evaluationContext, data);
}
@Override
public R apply(T data) {
return apply(data, Visitor.defaultVisitor());
}
}
public class StandardSpELSetterImpl<T, R> implements StandardSpELSetter<T, Collection<R>> {
private final String fieldName;
private final boolean isCollection;
private final Expression expression;
private final EvaluationContext evaluationContext;
private StandardSpELSetterImpl(Field field) {
this(field, new StandardEvaluationContext());
}
private StandardSpELSetterImpl(Field field, EvaluationContext evaluationContext) {
this.fieldName = Objects.requireNonNull(field).getName();
this.expression = expressionParser.parseExpression(fieldName);
this.isCollection = Collection.class.isAssignableFrom(Objects.requireNonNull(field).getType());
this.evaluationContext = evaluationContext;
}
@Override
public void accept(T target, Collection<R> result, @Nullable Visitor<EvaluationContext> visitor) {
Optional.ofNullable(visitor).ifPresent(i -> i.visit(this.evaluationContext));
if (isCollection) {
this.expression.setValue(evaluationContext, target, result);
} else {
if (result.size() == 1) {
this.expression.setValue(evaluationContext, target, result.stream().findFirst().get());
} else {
log.error("write join result to {} error: Too many results, field is {}, data is {}", target, fieldName, result);
}
}
}
@Override
public void accept(T target, Collection<R> result) {
accept(target, result, Visitor.defaultVisitor());
}
}
}
4.2 ExcelHelper
核心逻辑, 可完全复用
- 创建普通下拉列表
- 引用一个表格区域, 区域内的值为下拉列表的值
- 创建数据有效性约束: 当用户输入值不在范围内时报错提示.
- 创建子级下拉列表
- 创建名称管理器: 通过 key 可以找到一个表格区域的引用, 引用的值可以作为下拉菜单的值
- 引用 indirect 函数, 当父列选择值后, 子列动态加载名称管理器中对应key的值列表
- 创建数据有效性约束: 当用户输入值不在范围内时报错提示.
/**
* @author hp
*/
@Slf4j
@UtilityClass
public class ExcelHelper {
public static void addCascadeDropdownToSheet(
Workbook workbook,
Sheet sheet,
Sheet selectionSheet,
AtomicInteger selectionColumnIndex,
ExcelCascadeModel cascadeModel
) {
addCascadeDropdownToSheet(
workbook,
sheet,
selectionSheet,
selectionColumnIndex,
cascadeModel.getOptions(),
cascadeModel.getParentColumnIndex(),
cascadeModel.getColumnIndex(),
cascadeModel.getFirstRow(),
cascadeModel.getLastRow()
);
}
public static void addDropdownToSheet(
Sheet sheet,
Sheet selectionSheet,
AtomicInteger selectionColumnIndex,
ExcelSelectModel selectModel
) {
addDropdownToSheet(
sheet,
selectionSheet,
selectionColumnIndex,
selectModel.getOptions(),
selectModel.getColumnIndex(),
selectModel.getFirstRow(),
selectModel.getLastRow()
);
}
private static void addCascadeDropdownToSheet(
Workbook workbook,
Sheet sheet,
Sheet selectionSheet,
AtomicInteger selectionColumnIndex,
Map<Object, Collection<Object>> options,
int parentColumnIndex,
int columnIndex,
int startRowIndex,
int endRowIndex
) {
final String parentColumnName = calculateColumnName(parentColumnIndex + 1);
final String indirectFormula = createIndirectFormula(parentColumnName, startRowIndex + 1);
createValidation(sheet, indirectFormula, columnIndex, startRowIndex, endRowIndex);
options.forEach((parentOption, childOptions) -> {
if (CollUtil.isEmpty(childOptions)) {
return;
}
final int index = selectionColumnIndex.getAndIncrement();
createDropdownElement(selectionSheet, childOptions, index);
final String actualColumnName = calculateColumnName(index + 1);
final String formulaForNameManger = createFormulaForNameManger(selectionSheet, actualColumnName, childOptions.size());
createNameManager(workbook, sheet, parentOption, formulaForNameManger);
});
}
private static void addDropdownToSheet(
Sheet sheet,
Sheet selectionSheet,
AtomicInteger selectionColumnIndex,
Collection<Object> options,
int columnIndex,
int startRowIndex,
int endRowIndex
) {
final int index = selectionColumnIndex.getAndIncrement();
createDropdownElement(selectionSheet, options, index);
final String actualColumnName = calculateColumnName(index + 1);
final String indirectFormula = createFormulaForDropdown(selectionSheet, actualColumnName, options.size());
createValidation(sheet, indirectFormula, columnIndex, startRowIndex, endRowIndex);
}
public static Sheet createSheet(Workbook workbook, String sheetName, boolean unlimitedWindowSize) {
// 创建Sheet, windowSize控制在内存中一次操作sheet的量, 默认100, 超过后将刷到磁盘, 内存中的对象将被销毁
final Sheet sheet = workbook.createSheet(sheetName);
if (unlimitedWindowSize && sheet instanceof SXSSFSheet sxssfSheet) {
sxssfSheet.setRandomAccessWindowSize(-1);
}
return sheet;
}
private static void createDropdownElement(Sheet sheet, Collection<Object> options, int columnIndex) {
// 垂直方向生成元素, 从索引0行开始
final AtomicInteger rowIndexAtomic = new AtomicInteger(0);
options.forEach(option -> {
final int rowIndex = rowIndexAtomic.getAndIncrement();
final Row row = Optional.ofNullable(sheet.getRow(rowIndex)).orElseGet(() -> sheet.createRow(rowIndex));
final Cell cell = row.getCell(columnIndex, Row.MissingCellPolicy.CREATE_NULL_AS_BLANK);
cell.setCellValue(String.valueOf(option));
});
}
private static void createValidation(Sheet sheet, String validationFormula, int columnIndex, int startRowIndex, int endRowIndex) {
// 创建约束范围
final CellRangeAddressList addressList = new CellRangeAddressList(startRowIndex, endRowIndex, columnIndex, columnIndex);
// 创建约束
final DataValidationHelper validationHelper = sheet.getDataValidationHelper();
final DataValidationConstraint constraint = validationHelper.createFormulaListConstraint(validationFormula);
// 样式, 默认最严格方式, 禁止输入不在选项范围内的值
final DataValidation dataValidation = validationHelper.createValidation(constraint, addressList);
dataValidation.setErrorStyle(DataValidation.ErrorStyle.STOP);
dataValidation.setShowErrorBox(true);
dataValidation.setSuppressDropDownArrow(true);
dataValidation.createErrorBox("提示", "请选择下拉选项中的内容");
sheet.addValidationData(dataValidation);
}
private static String createIndirectFormula(String columnName, int startRow) {
return ExcelConstants.INDIRECT_FORMULA_FORMAT.formatted(columnName, startRow);
}
private static String createFormulaForNameManger(Sheet sheet, String columnName, int size) {
return ExcelConstants.NAME_MANAGER_FORMULA_FORMAT.formatted(sheet.getSheetName(), columnName, "1", columnName, size);
}
private static String createFormulaForDropdown(Sheet sheet, String columnName, int size) {
return ExcelConstants.DROPDOWN_FORMULA_FORMAT.formatted(sheet.getSheetName(), columnName, "1", columnName, size);
}
private static void createNameManager(Workbook workbook, Sheet sheet, Object originalNameName, String formula) {
final String nameName = formatNameManager(originalNameName);
//处理存在名称管理器复用的情况
Name name = workbook.getName(nameName);
if (name != null && Objects.equals(name.getSheetName(), sheet.getSheetName())) {
return;
}
name = workbook.createName();
name.setNameName(nameName);
// 作用域在sheet, 而非workbook
name.setSheetIndex(workbook.getSheetIndex(sheet));
name.setRefersToFormula(formula);
}
public static void hideSheet(Workbook workbook, Sheet sheet) {
// 隐藏Sheet
final int sheetIndex = workbook.getSheetIndex(sheet);
if (sheetIndex > -1) {
workbook.setSheetHidden(sheetIndex, true);
} else {
log.error("Can't hide sheet={}, cause the sheet can't be found on the workbook!", sheet.getSheetName());
}
}
private static String formatNameManager(Object name) {
// 针对Excel不允许某些字符开头的情况, 使用下划线拼接可以实现, 在Indirect函数中再次拼接下划线即可完成数据关联
return "_" + name;
}
private static String calculateColumnName(int columnIndex) {
//获取到实际列名称, 例如 AAA 列
final int minimumExponent = minimumExponent(columnIndex);
final int base = 26, layers = (minimumExponent == 0 ? 1 : minimumExponent);
final List<Character> sequence = Lists.newArrayList();
int remain = columnIndex;
for (int i = 0; i < layers; i++) {
int step = (int) (remain / Math.pow(base, i) % base);
step = step == 0 ? base : step;
buildColumnNameSequence(sequence, step);
remain = remain - step;
}
return sequence.stream()
.map(Object::toString)
.collect(Collectors.joining());
}
private static void buildColumnNameSequence(List<Character> sequence, int columnIndex) {
final int capitalAAsIndex = 64;
sequence.add(0, (char) (capitalAAsIndex + columnIndex));
}
private static int minimumExponent(int number) {
final int base = 26;
int exponent = 0;
while (Math.pow(base, exponent) < number) {
exponent++;
}
return exponent;
}
}
4.3 ExcelConstants
/**
* @author hp
*/
public interface ExcelConstants {
@FieldDesc("request.attribute中持有该变量时,作为自定义文件名称,动态名称")
String FILENAME_ATTRIBUTE_KEY = "__EXCEL_NAME_KEY__";
@FieldDesc("request.attribute中持有该变量时,作为查询下拉列表数据的参数列表")
@Requirement("value=Map<String,Object>")
String DROPDOWN_QUERY_PARAMS_ATTRIBUTE_KEY = "__EXCEL_DROPDOWN_QUERY_PARAM_KEY__";
@FieldDesc("名称管理器的引用格式")
String NAME_MANAGER_FORMULA_FORMAT = "%s!$%s$%s:$%s$%s";
@FieldDesc("下拉列表的引用格式")
String DROPDOWN_FORMULA_FORMAT = "=%s!$%s$%s:$%s$%s";
@FieldDesc("indirect引用函数的格式,下划线用于拼接特殊名称管理名称")
String INDIRECT_FORMULA_FORMAT = "INDIRECT(CONCATENATE(\"_\",$%s%s))";
@FieldDesc("存放下拉数据的sheet名称")
String SELECTION_HOLDER_SHEET_NAME = "_selectionHolderSheet";
// 合并单元格的策略, 目前仅根据内容来, 上下单元格内容相同时合并
enum MergeStrategy {
CONTENT,
}
}
五、日志
- 2024-05-08:
- 改用SpEL.
- 多个sheet多个下拉存在覆盖的问题通过调整设计和实现解决.
- 多sheet场景也仅使用一个sheet存放所有sheet下拉数据.
- 2023-12-28:
- 应同好的提问, 修改了生成存放下拉元素的sheet的逻辑: 单Sheet场景中, 将所有的下拉数据都生成到一个sheet中
- 2023-10-25:
- 由于名称管理器对特殊字符和数字开头的限制, 其允许使用_(下划线)开头, 这里通过在生成名称管理器值的时候拼接下划线, 在使用INDIRECT函数时拼接下划线的方式使得父级下拉值可以以特殊字符或数字开头.
- 2023-08-10:
- 计算下拉列表的列名称逻辑上无数量限制, 实际如WPS中, 一个Sheet最多可使用16384列生成下拉
- 2023-05-30:
- 精简博客内容, 只保留最主要的介绍信息
- 2023-05-16: note:
- 同好 niceGoingGn 提到的下拉数据提示文件损坏的问题, 可能是由于poi的API在实现用一个数组作为dropdown数据时, 底层是拼字符串的方式, 该方式在Excel有字符数量限制. 所以会导致异常, 之前也是我的场景局限性太强, 目前已经调整为所有的dropdown都通过引用的方式加载, 1000+ elements都没问题.
- 同好 小宇哥JJ 提到的对存在一个多级表头时处理注解的优化(能拉, 但只能拉一点点), 以及级联复用时, 名称管理器重复创建会报错的情况, 目前已经调整. 复用时不再出现异常, 同时对多个级联存在时优化了生成sheet的逻辑.
- optimizations: 纵向生成数据, 支持676+26列带下拉, 优化存在多级表头的问题, 优化生成的隐藏sheet数量.
- 历史省略
以下历史内容
校验部分, 在新版本已经调整到@ExcelSelect中了.
六、导入
因为我在项目中使用的涉及到存在合并行的情况, 所以这里自定义处理导入;
最终处理为Map<合并行第一行的行号, Collection<合并行>>
1. EasyExcel方式
@PostMapping("/import")
public AjaxResult import(MultipartFile file) {
Map<Integer, List<ImportDTO>> map = new HashMap<>(16);
EasyExcel.read(file.getInputStream(), ImportDTO.class, new EasyExcelUtil.ImportEventListener<>(map))
.extraRead(CellExtraTypeEnum.MERGE)
.excelType(ExcelTypeEnum.XLSX)
.headRowNumber(1)
.sheet(0)
.doRead();
xxxxService.validateImport(map);
return xxxxService.import(map);
}
2. 插件方式
@PostMapping("/import")
public AjaxResult importProjectV2(
@RequestExcel(
listener = MergeRowAnalysisEventListener.class,
enhancement = {MergeRowReaderEnhance.class}
)
Map<Integer, List<xxxImportDTO>> map
) {
xxxtService.validateImport(map);
return xxxService.import(map);
}
2.自定义导入监听器
MergeRowAnalysisEventListener 或 EasyExcelUtil.ImportEventListener 作用都一样
非必要 或者清空extra方法,在这个监听器里做校验就行了
以下代码不难看出, 其实可以在EasyExcel处理数据的时候就校验数据, 并合理使用其抛异常方法抛出异常, 但是debug之后发现处理合并行方法 extra 在最后执行, 没利用到组件的 onException 方法, 所以推迟到组件处理完数据后再统一校验
public static class ImportEventListener<T> extends AnalysisEventListener<T> {
private final Map<Integer, List<T>> map;
private Integer headRowNumber = 1;
public ImportEventListener(Map<Integer, List<T>> map) {
this.map = map;
}
// 这个是每行的数据(每一行都会执行这个)
@Override
public void invoke(T data, AnalysisContext context) {
final List<T> list = new ArrayList<>();
list.add(data);
map.put(map.keySet().size(), list);
}
//所有数据处理之后
@Override
public void doAfterAllAnalysed(AnalysisContext context) {
}
//可以考虑有一条错就抛, 还是所有数据处理完,其中有异常,全部抛
@Override
public void onException(Exception exception, AnalysisContext context) throws Exception {
throw exception;
}
// 这个是读取单元格和并时的信息
@SneakyThrows
@Override
public void extra(CellExtra extra, AnalysisContext context) {
if (headRowNumber == null) {
headRowNumber = context.readSheetHolder().getHeadRowNumber();
}
// 获取合并后的第一个索引
Integer index = extra.getFirstRowIndex() - headRowNumber;
final List<T> first = map.get(index);
// 获取合并后的最后一个索引
Integer lastRowIndex = extra.getLastRowIndex() - headRowNumber;
for (int i = index + 1; i <= lastRowIndex; i++) {
final List<T> c = map.get(i);
if (CollUtil.isNotEmpty(c)) {
first.addAll(c);
map.remove(i);
}
}
}
}
3. 校验数据
基于javax.validation, org.hibernate.validator, 点进去看看就差不多清楚了
3.1 自定义校验注解
使用到自定义校验器, 和一个获取动态数据的处理器
@Target({ElementType.METHOD, ElementType.FIELD, ElementType.ANNOTATION_TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@Constraint(validatedBy = DynamicSelectDataValidator.class) // 校验器
public @interface DynamicSelectData {
String message() default "请填写规定范围的值";
Class<?>[] groups() default {};
Class<? extends Payload>[] payload() default {};
String parameter() default "";
Class<? extends ColumnDynamicSelectDataHandler> handler() default DefaultColumnDynamicSelectDataHandler.class;
}
3.2 自定义校验器
在校验时, 这个校验器会校验对应注解, 获取到注解的信息, 初始化动态数据处理器, 调用校验方法时查询数据并完成校验, 校验为false时, 会根据提示信息保存在ConstraintViolation对象中, 最后形成一个集合
@Slf4j
public class DynamicSelectDataValidator implements ConstraintValidator<DynamicSelectData, String> {
private String arg = null;
private ColumnDynamicSelectDataHandler handler = null;
@Override
public void initialize(DynamicSelectData data) {
this.arg = data.parameter();
final Class<? extends ColumnDynamicSelectDataHandler> sourceHandlerClass = data.handler();
this.handler = SpringUtil.getBean(sourceHandlerClass);
}
@Override
public boolean isValid(String value, ConstraintValidatorContext constraintValidatorContext) {
if (StrUtil.isEmpty(value) || Objects.isNull(handler)) {
return true;
}
try {
final List<String> constrainSource = (List<String>) handler.source().apply(arg);
return constrainSource.contains(value);
} catch (Exception e) {
return false;
}
}
}
3.3 动态获取数据处理器
只是获取合法数据集, 随便怎么写都行, 优化后这里的处理器和模版导出时的相同
3.4 校验数据方法
每一行校验一次, 每行所有列的问题返回一个map集合, 实际怎么封装校验结果可以自己修改
这里也能发现一个明显问题, 获取数据的方法每行都会被调用, 我的场景里数据量不是很大, 但是如果比较大的话, 还是需要准备一个上下文之类的存一下会一直重复的数据集, 避免每次都查询
public static <T> Optional<Map<String, Object>> validateData(T data) {
//这里的默认validator可以改成静态成员变量, 避免每次行记录都调
final Validator validator = Validation.buildDefaultValidatorFactory().getValidator();
//校验数据后的结果
Set<ConstraintViolation<T>> set = validator.validate(data, Default.class);
if (CollUtil.isEmpty(set)) {
return Optional.empty();
}
List<String> columnExceptions = new ArrayList<>();
for (ConstraintViolation<T> cv : set) {
columnExceptions.add(cv.getMessage());
}
if (CollUtil.isEmpty(columnExceptions)) {
return Optional.empty();
}
final Map<String, Object> rowExceptionMap = new HashMap<>(16);
rowExceptionMap.put("exceptions", columnExceptions);
return Optional.of(rowExceptionMap);
}
3.5 使用注解
这里只展示跟上述内容相关的注解, 其他例如NotEmpty, Digits, Email之类的注解有自己对应的校验器
如果写死的列表用正则就行了, 动态的数据配置处理器查询
@Data
public class TestImportDTO{
@ExcelProperty(value = "普通列")
private String common;
@Pattern(regexp = "^(A|B|C|D)$", message = "校验信息")
@ExcelSelect(staticData = "[\"A\", \"B\", \"C\", \"D\", \"E\"]")
@ExcelProperty(value = "单列select")
private String singleSelect;
@DynamicSelectData(message = "动态单列select请填写给定的选项", handler = {DynamicDataConstrainSourceHandler.class}, parameter = "自定义参简单参数")
@ExcelSelect(handler = ExcelTestSourceHandler.class)
@ExcelProperty(value = "动态单列select")
private String dynamicSingleSelect;
//parent字段定义父列名称
@DynamicSelectData(message = "级联子列请填写给定的选项", handler = {ChildConstrainSourceHandler.class})
@ExcelSelect(parentColumn = "父列", handler = ExcelChildSourceHandler.class)
@ExcelProperty(value = "级联子列")
private String child;
@DynamicSelectData(message = "父列请填写给定的选项", handler = {ChildConstrainSourceHandler.class})
@ExcelSelect(handler = ExcelParentSourceHandler.class)
@ExcelProperty(value = "父列")
private String parent;
}
3.6 校验结果
{
"msg": "导入数据异常",
"code": 500,
"data": [
{
"row": "第1条记录异常",
"exceptions": [
"xxx不能为空"
]
},
{
"row": "第1条记录的第2条子记录记录异常",
"exceptions": [
"子记录xxx请填写纯数字(整数位不超过10位,小数位不超过两位)"
]
},
{
"row": "第2条记录异常",
"exceptions": [
"xxx不能为空"
]
},
{
"row": "第3条记录异常",
"exceptions": [
"xxxx请填写纯数字(整数位不超过10位,小数位不超过两位)"
]
},
{
"row": "第3条记录的第3条子记录异常",
"exceptions": [
"子记录xxx请填写纯数字(整数位不超过10位,小数位不超过两位)"
]
}
]
}

















 5273
5273

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









