







1. kafka相关
1.1 利用kafka本身的缓存机制
1.1.1 背景
在压测过程中,当数据量增大之后,有两个topic的生产者均出现发送数据到kafka超时的情况。
1.1.2 解决方案
利用好kafka生产者本身自带的缓存池机制。
- 设置
batch.size//缓存池中批次发送大小阈值,当一批次数据达到这个大小就会触发发送 默认为 16k-即16384. - 设置
linger.ms//缓存池发送时间阈值,当一个批次创建后 linger.ms毫秒后,即使数据量没有达到 batch.size大小也会立即发送,默认为0.
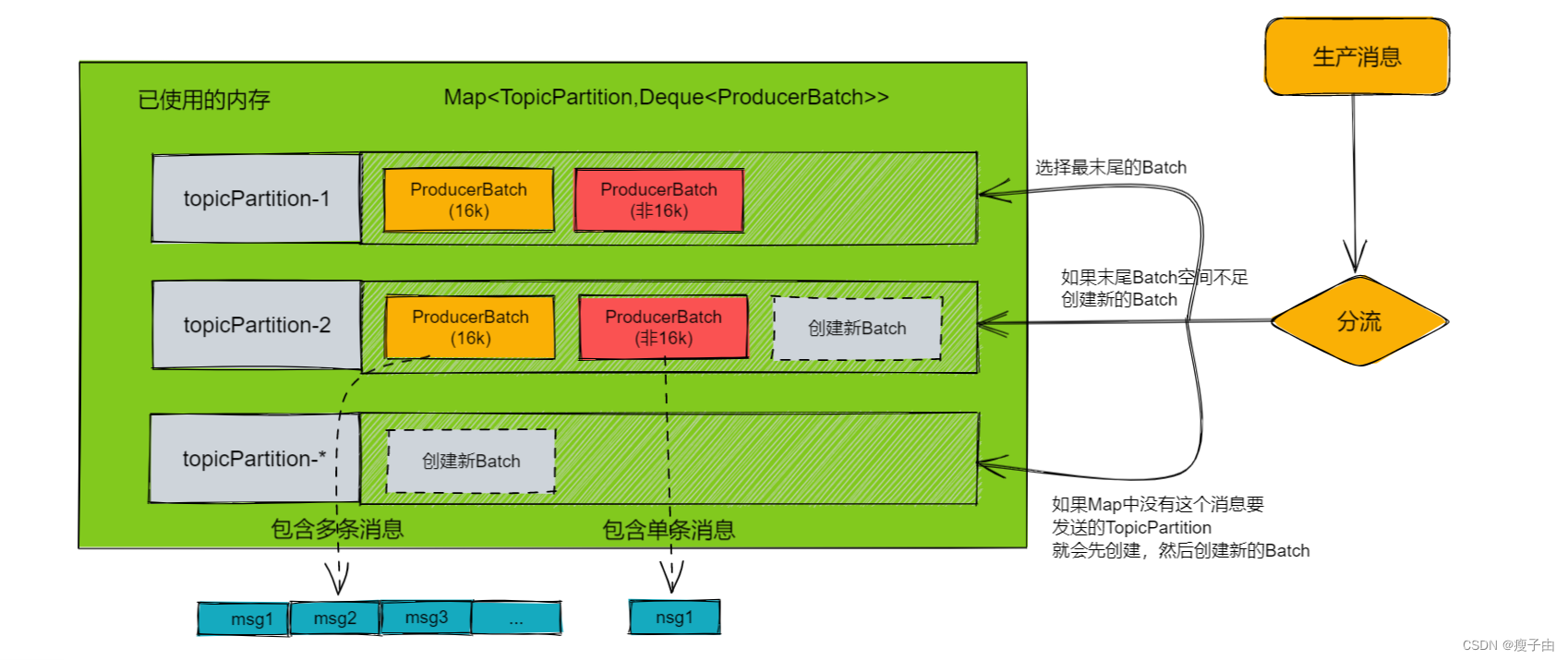
kafka消息缓存模型
本次优化中将batch.size调大到 160k 后碰到1.2问题调整到 1600k,后因每条消息也不能延后太多,所以调整到了480k。
将linger.ms调整到了1000ms,让消息批次每1秒发一次,后因为每条消息不能延后太多,所以调整到了200ms。
1.2 合理的消费速度和生产批次
1.2.1 背景
在根据1.1优化将批次调整到163840之后,继续压测的过程中,依旧偶尔出现发送kafka超时的情况。
1.2.2 原因分析
首先,如果消费速度过快造成后续生产者阻塞,可以调整缓存池大小 buffer.memory 该配置为生产者内存缓冲区的大小,生产者用它缓冲要发送到服务器的消息。如果数据产生速度大于向broker发送的速度,导致生产者空间不足,producer会阻塞或者抛出异常。缺省33554432 (32M)。
但是如果长期处于生产速度小于消费速度的状态下,再大的buffer.memory都是会被塞满的。
经计算,当时配置的生产者批次大小为163840,配置消费者最大拉取条数为30条,每个消费者线程拉回来的最大数据大小为3700 * 30 = 111600,根据1.1的原理,如果消费者一直拉满等于1.1设置的批次无效,每拉一次数据都会重新生成一个批次,造成将buffer内存填满。

1.2.3 解决方案
- 首先,继续调大了1.1所述的
batch.size从 163840 调整到 1638400 - 然后根据压测环境的数据量每秒300条数据,30个消费者线程,配置每批拉取的最大数据量 将
max.poll.records从30降低到20,这样既可以降低拉取数据大小,也可以应对数据陡增场景。
1.3 优化1.1 1.2配置造成的延时不达标,继续优化
1.3.1 背景
优化1.1的时候将批次发送时间linger.ms 配置为了1000,而 1.2将batch.size 调整到了1638400,约442条数据才会触发大小阈值,而压测数据每秒产生300条数据,所以导致这个批次里携带的消息都会在有一秒钟的发送延时。
1.3.2 解决方案
- 首先调整
linger.ms为200,先保证每个数据最多只会有200ms延时。 - 调整
batch.size为 491520,可以应对陡增情况每100多条才会触发一次发送,这条修改收益不大,只是觉得1638400的阈值实在太高了。
1.4 根据不同topic的数据大小调整各自消费者最大拉取数量
1.4.1 背景
数据接入服务在给压测环境造静态数据的过程中,由于产生的图片使用的base64发送到kafka,所以每条数据的大小都很大,一开始配置每批次拉去30条,造成了内存溢出。后来调整到每批次5条,可以稳定运行了,但是后来接入算法入库结果数据的消费者出现了积压。
1.4.2 问题分析
因为算法入库结果的消费者是后来开启的,一开始就有数据在里边了,所以会有一定积压,但是因为数据一边产生一边消费,所以一直消耗不下去。
1.4.3 解决方案
由于算法入库结果的消息一条大小很小,所以将消费每个topic的消费组配置分开配置。
消费数据(数据较长)的最大拉取条数为5,消费结果(数据很短)的最大拉取条数为50 - 100,放到压测环境,一会儿就把积压给消耗了。
2. flink相关
2.1 合理设置窗口时间
2.1.1 背景
布控告警在flink布控规则匹配的节点有一定的延时。
2.1.2 解决方案
- 原来的flink窗口时间为1000ms的阈值,也就是1秒钟之后才会把匹配结果发出,修改为200ms。
- 原来flink窗口的大小是没有设置的,顺带修改为20条的大小,以应对数据量大的情况。
3. 逻辑优化
3.1 http请求重试机制
3.1.1 背景
压测过程中有段时间视图库请求总是有些报错,导致数据的丢失。
3.1.2 解决方案
- 增加重试机制应对偶发异常。不太追求效率更追求不丢失的静态数据录入的改为500以上错误码无限重试,400-500错误码将源数据转存到另一个topic。追求性能的动态数据链设置为5次重试。
- 数据链种使用视图库的采集服务,因为视图库的查询服务端口接到增删改的请求会转发给采集服务做处理,所以追求高性能的数据链将增删改直接使用视图库采集服务,减小视图库压力。
3.2 区分数据链日志错误码(待)
3.2.1 背景
当前数据链日志打印的errorCode,成功了就是0,失败了就是1,无法根据错误码定位问题。
3.2.2 解决方案
待解决
需制定细分策略,尝试是否能将错误码准确对应到和各种异常一一对应,这样只需要撰写错误码说明就可以一目了然的让使用者定位到问题所在。















 398
398











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









