







解析库PyQuery的学习
声明:本文只作学习研究,禁止用于非法用途,否则后果自负,如有侵权,请告知删除,谢谢!
目标网站:https://movie.douban.com/top250
引言
为了提升自己有关于爬虫的深度,特开始全面的提升自己,与平时大多时间使用lxml的xpath提取不同本次使用的为pyquery解析库
-
pyquery的安装方法
在命令行模式中输入或者在pycharm编辑器的terminal中输入
1.1、pip install pyquery -
pyquery的初始化
PyQuery的初始化的时候也需要传入HTML数据源来初始化一个操作对象,且PyQuery它的初始化方式有多种,比如直接传入字符串,传入URL,传文件名等。
html/字符串初始化:一般html页面与字符串的初始化只在于filename方法的运用使用filename方法的时候就时html页面,直接使用字符串名则不需要使用该方法
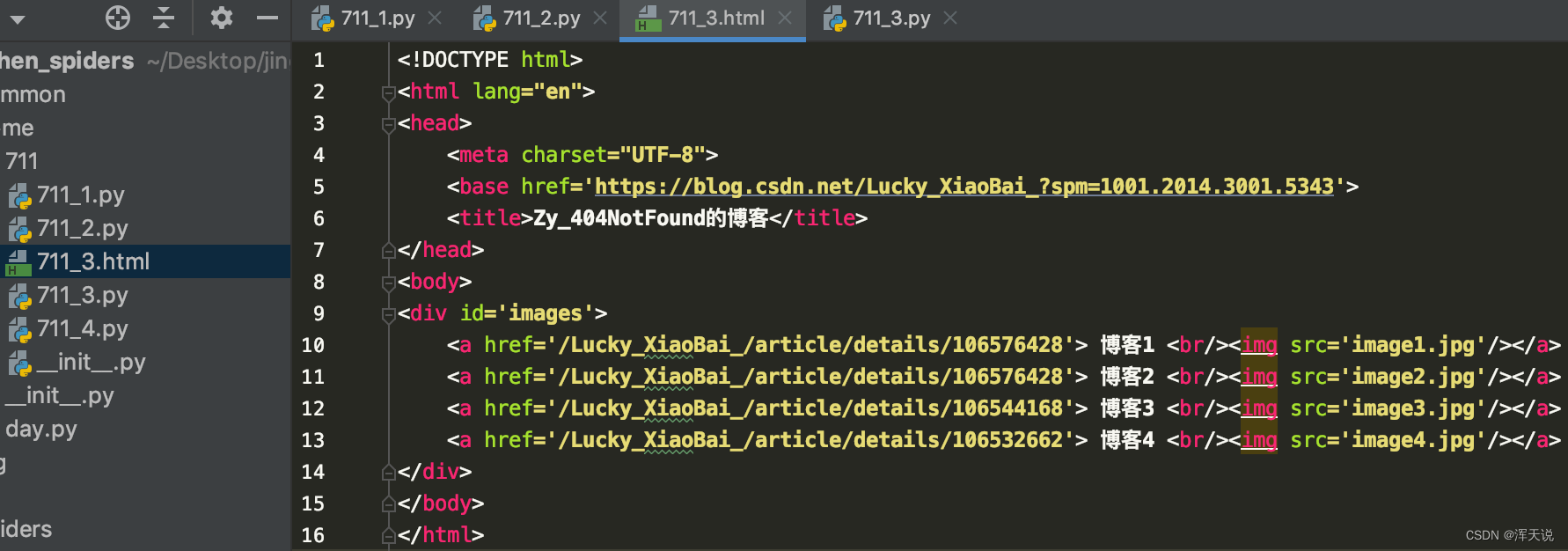
html = '''
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<base href='https://blog.csdn.net/Lucky_XiaoBai_?spm=1001.2014.3001.5343'>
<title>xxx的博客</title>
</head>
<body>
<div id='images'>
<a href='/Lucky_XiaoBai_/article/details/106576428'> 博客1 <br/><img src='image1.jpg'/></a>
<a href='/Lucky_XiaoBai_/article/details/106576428'> 博客2 <br/><img src='image2.jpg'/></a>
<a href='/Lucky_XiaoBai_/article/details/106544168'> 博客3 <br/><img src='image3.jpg'/></a>
<a href='/Lucky_XiaoBai_/article/details/106532662'> 博客4 <br/><img src='image4.jpg'/></a>
</div>
</body>
</html>
'''
from pyquery import PyQuery as pq
response = pq(html)
print(response('a'))
print('*'*100)
print(response('a').text())
response = pq(filename='711_3.html')
print(response('a'))
print('*'*100)
print(response('a').text())

url初始化
from pyquery import PyQuery as pq
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36',
}
response = pq('https://movie.douban.com/top250',headers=headers)
print(response.text())
print(response)
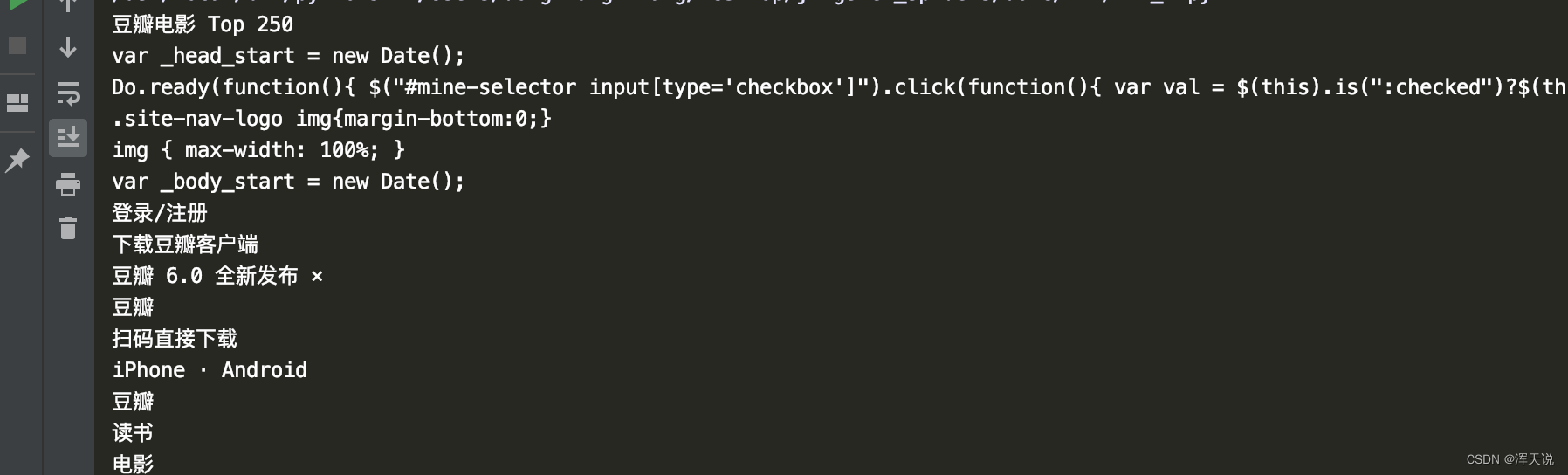
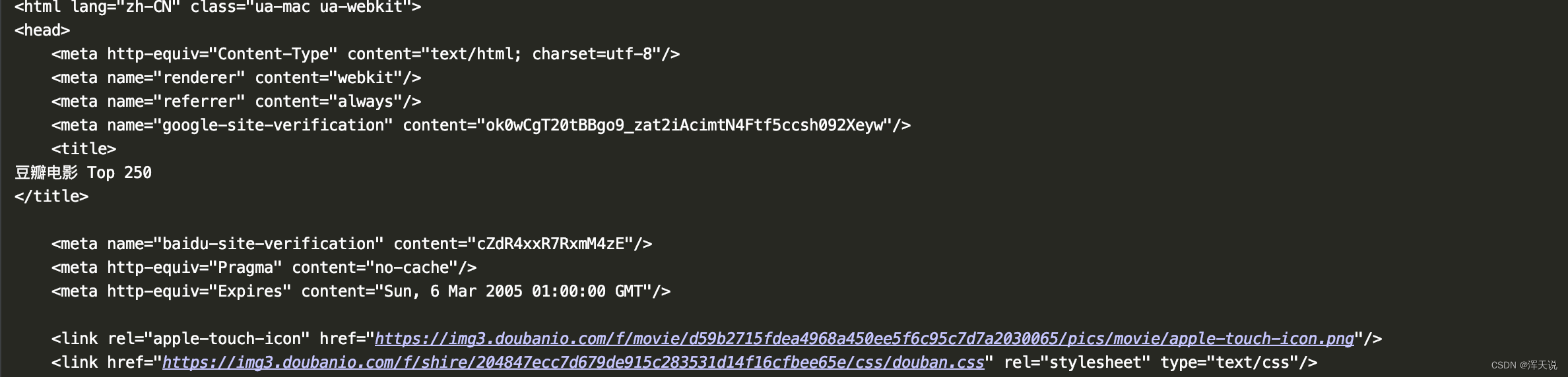
如上两图使用了PyQuery初始化豆瓣的url请求获取到了数据,response响应的数据为豆瓣接口的html返回(打印的数据随着数据的状态显示的也截然不同)
mod = response('title').text()
print(mod)

下面来说说将要使用的PyQuery的选择器
| 选择器 | 例子 |
|---|---|
| # id | #id='XXX’的选择器:选择所有id="XXX"的元素 |
| .class | .class='XXX’的选择器:选择所有class="XXX"的元素 |
| * | 所有元素 |
| element | p/div/ul/li的选择器:选择所有标签p/div/ul/li的元素 |
| element element | 例div p:选择所有div标签下的p元素 |
| items() | 获取到多个标签时,使用items()将pyquery转换为一个生成器 |
| text() | 获取标签 |
| attr | 获取属性 |
例子获取这些值
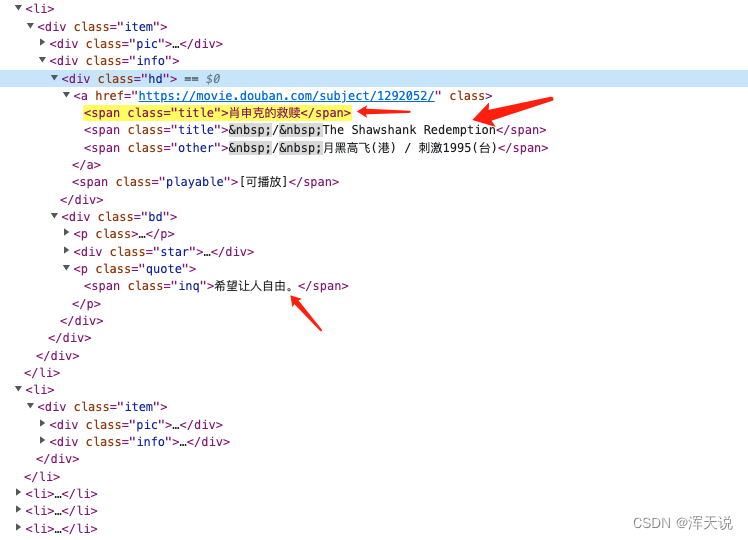
name = response('.hd a span:nth-of-type(1)').text()
print(name)
代码的意识:获取所有class=‘hd’下a标签下的第一个span的值其中nth-of-type(1)是指指获取第一个span的标签,如过是span标签下的则值为(下下图)获取所有span标签的值
下图是结果


3.获取信息获取信息有两种
3.1、是获取文本
如下图
name = response('.hd a span:nth-of-type(1)').text()
en_name = response('.hd a span:nth-of-type(2)').text()
other = response('.hd a span:nth-of-type(3)').text()
note = response('.inq').text()
print(name)
print(en_name)
print(other)
print(note)
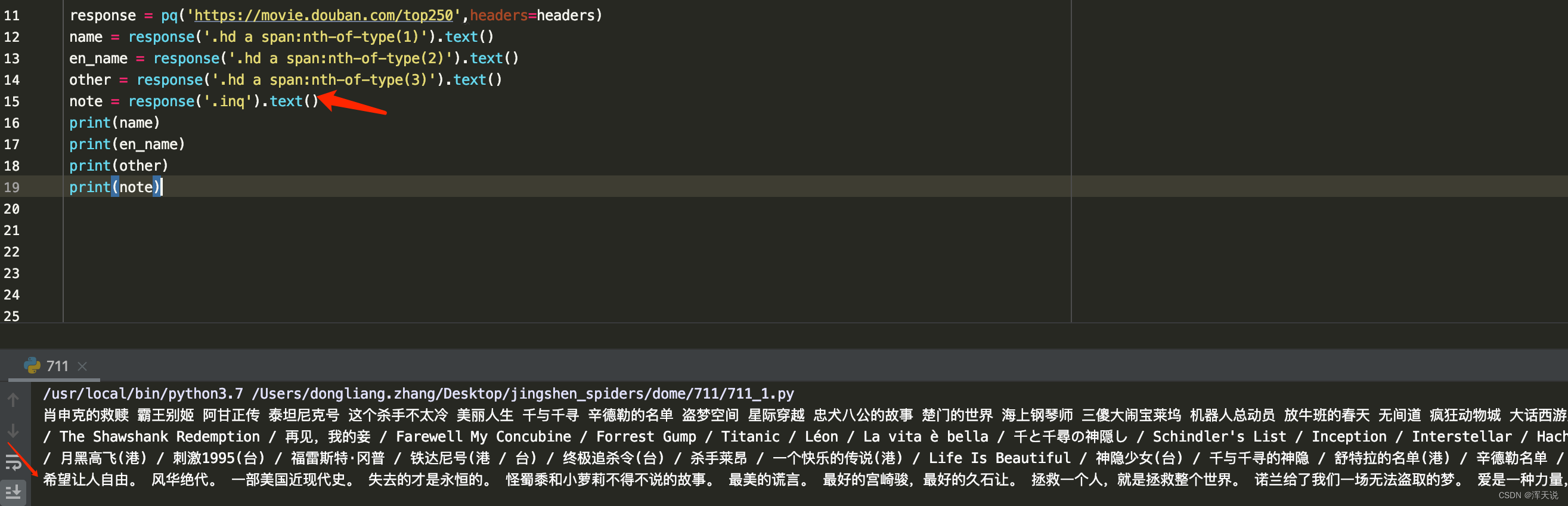
name = ''.join(response('.hd a span:nth-of-type(1)').text()).split()
note = ''.join(response('.inq').text()).split()
print(name)
print(note)
for item in range(len(name)):
print(name[item],note[item])
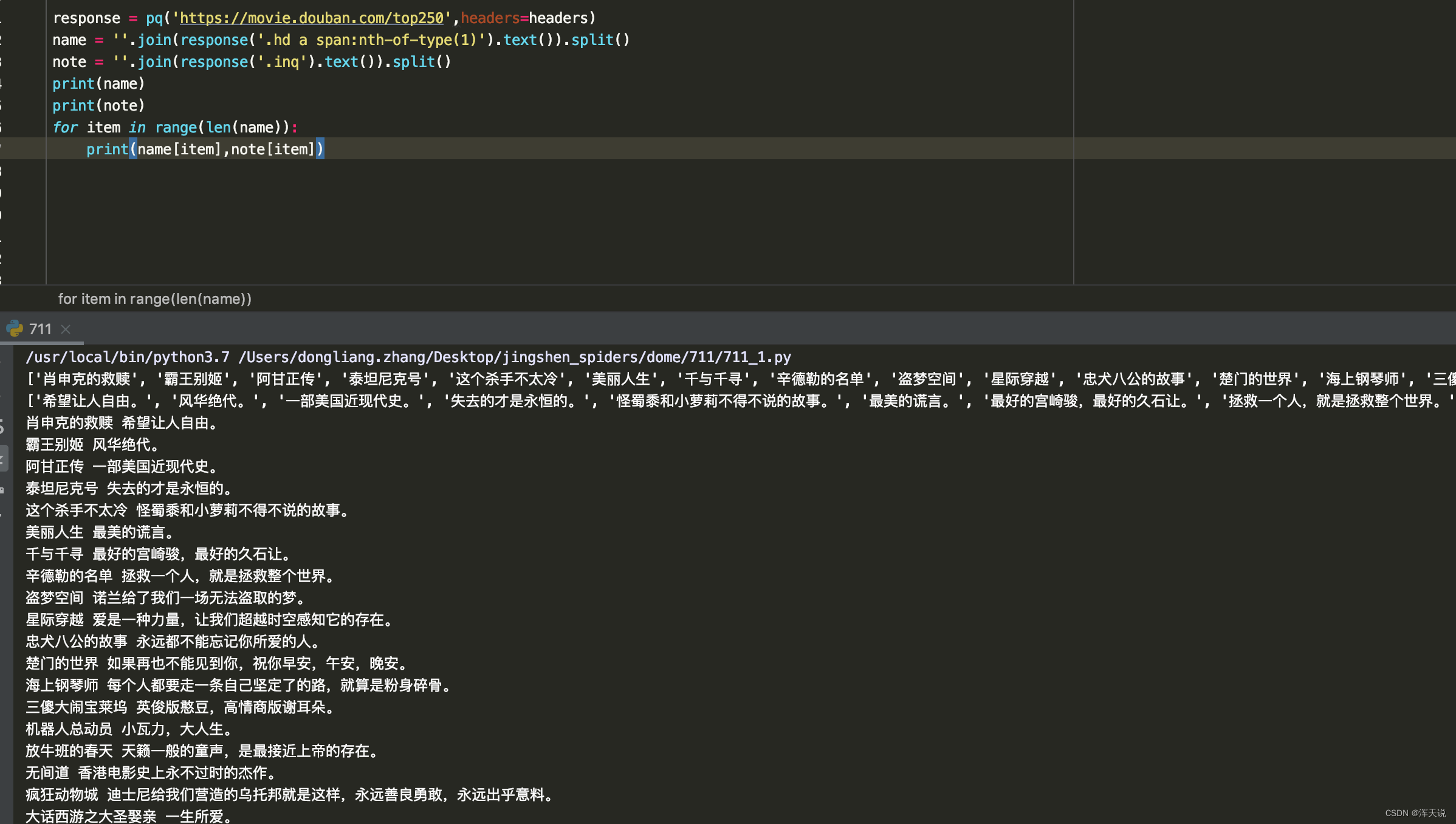
2、获取属性
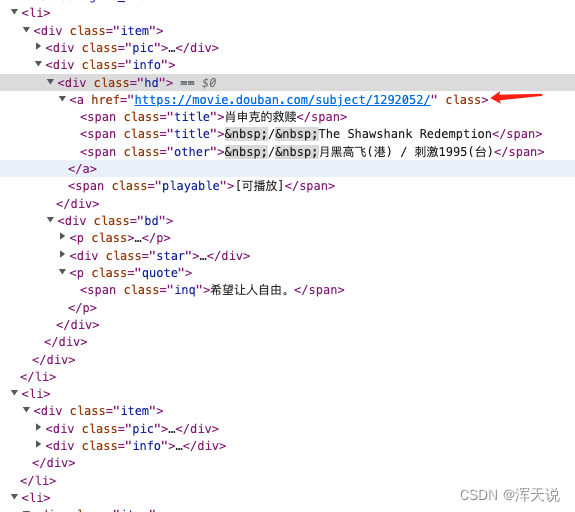
#获取所有的a标签下的href链接
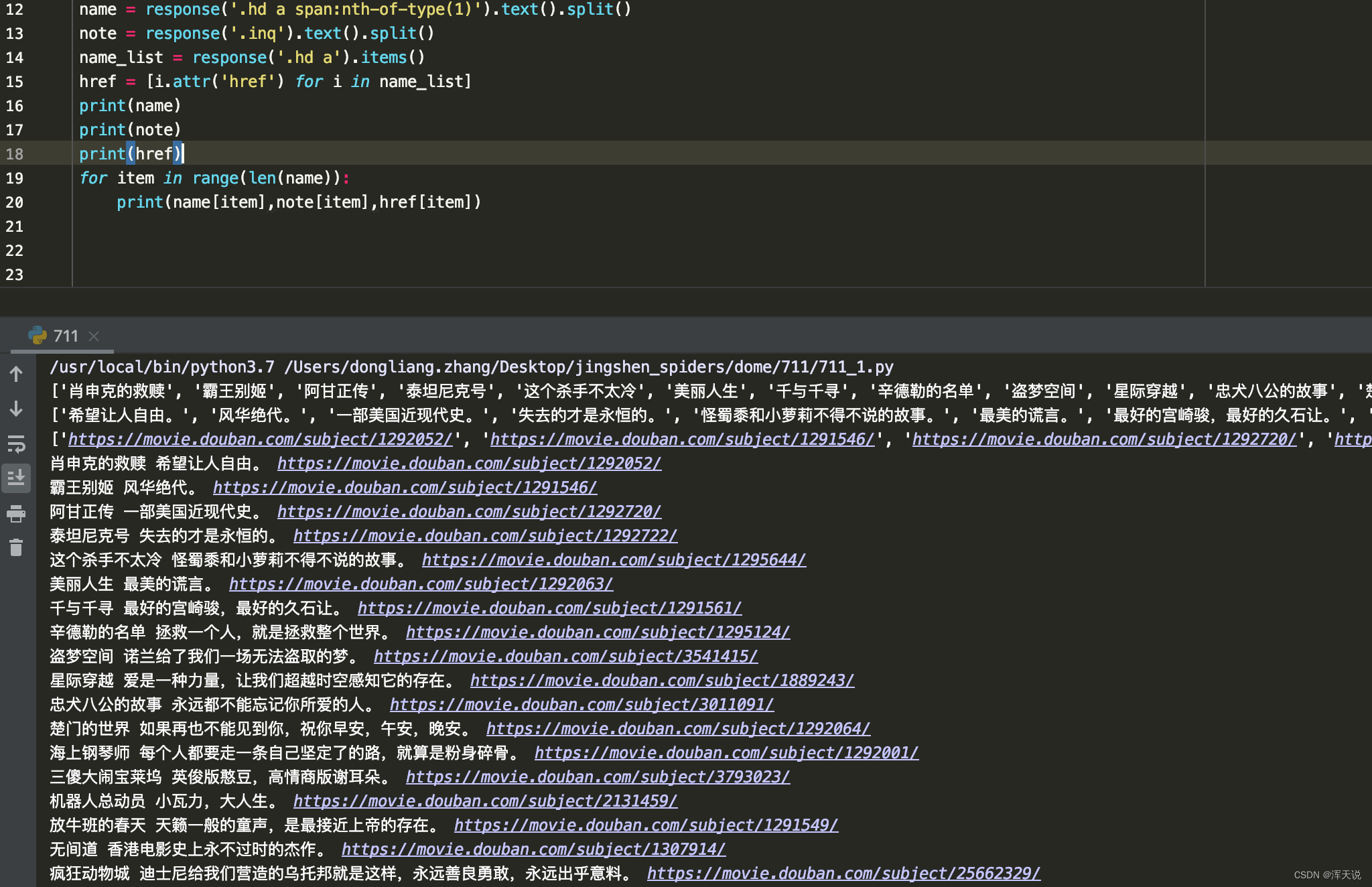
name = response('.hd a span:nth-of-type(1)').text().split()
note = response('.inq').text().split()
name_list = response('.hd a').items()
href = [i.attr('href') for i in name_list]
print(name)
print(note)
print(href)
for item in range(len(name)):
print(name[item],note[item],href[item])
更多CSS选择器可以查看
http://www.w3school.com.cn/css/index.asp
官方文档
http://pyquery.readthedocs.io/
4.总结:
本次的学习就到这了,还有很多的选择器没有分析但对于目前大多数的网站入门应是够了,在使用pyquery的过程中还是比较轻松的,对于所需要的数据只要打开浏览器的开发者模式后,都可以较快的确认并获取自己所需要的数据,其局限性只限于静态页面的数据获取,但着丝毫不影响其强大,可以使人较快快速的上手去解析数据,所有python爬虫的初学者都可以多多的去使用,这对复杂结构的数据解析很有帮助。
更多CSS选择器可以查看
http://www.w3school.com.cn/css/index.asp
官方文档
http://pyquery.readthedocs.io/















 1239
1239











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









