









说明:文章中的学习内容和图片取自莫烦python的视频。
1、何为TF-IDF?
TF—词频(Term Frequency):表示词条在文章中出现的次数(频率);
例如下图: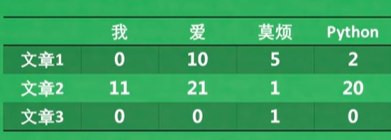
IDF—逆文件频率指数(Inverse Document Frequency):所有的词在这个系统中的区分力的大小,真正突出每一篇文章的重点;
例如下图:如果这个系统中每一篇文章中都有重复出现“我”这个字的时候,那么“我”这个字在任意一篇文档中的区分力就不强。如果搜索的时候关键字用的是“莫烦”,然鹅整个系统中叫莫烦的人又能有多少呢?所以“莫烦”这个词的区分力就很强。
分割
所以,TF是文章信息的局部信息;而IDF表示的是系统的全局信息。
TF-IDF的核心思想为词条的重要性随着该词条在当前文档中出现的次数成正比增加,但同时会随着它在语料库(所有文档)中出现的频率成反比下降。
并且两个各有各自的优势,所以想要结合两者的优势来表达一篇文章,就可以将这两者进行结合----即TF-IDF算法,这个算法常用于是一种用于信息检索(information retrieval)与文本挖掘(text mining)的常用加权技术。
将TF-IDF两者相结合,就是将这两者相乘的意思。
公式:TF-IDF = TF(词频) * IDF(逆文档频率)
这就意味着,所有文章都可以用一串集合所有词的分数来表示。通过分数的高低,可以大概看出这一篇文章的关键内容是什么。

二、TF-IDF的数学表达式
举个例子:
假设我们在搜索引擎中搜索“莫烦python”,机器会利用词表来计算“莫烦python”这个问题的TF-IDF值,然后会计算问句和每篇文章的cosine距离。这个例子中的计算过程,简单来说,就是将文章按照词的维度放到一个四维空间中,(由于画不了四维,就用个三维空间说明一下)然后把问句同样也放到这个空间里,最后看空间中这个问题离哪一个文章的距离最近,越近则相似度越高。通过这样的方式呢,我们就能找到搜索问题的最佳匹配文章了。

注:TF-IDF并不是一种神经网络或者深度学习,而是一种基于统计学的方法。但它有不可动摇的地位,最主要的原因是搜索中,文档量是巨大的, 而深度学习单个处理每篇文档太慢了,在追求搜索速度时,我们不得不依赖于快速的传统方法。


三、TF-IDF应用
(1)搜索引擎;(2)关键词提取;(3)文本相似性;(4)文本摘要
四、代码
1、sk-learn实现
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
docs=[
"it is a good day, I like to stay here",
"I am happy to be here",
"I am bob",
"it is sunny today",
"I have a party today",
"it is a dog and that is a cat",
"there are dog and cat on the tree",
"I study hard this morning",
"today is a good day",
"tomorrow will be a good day",
"I like coffee, I like book and I like apple",
"I do not like it",
"I am kitty, I like bob",
"I do not care who like bob, but I like kitty",
"It is coffee time, bring your cup",
]
## sk-learn
vectorizer = TfidfVectorizer()
tf_idf = vectorizer.fit_transform(docs)
q = "I get a coffee cup"
qtf_idf = vectorizer.transform([q])
res = cosine_similarity(tf_idf, qtf_idf)
# [[0. ]
# [0. ]
# [0. ]
# [0. ]
# [0. ]
# [0. ]
# [0. ]
# [0. ]
# [0. ]
# [0. ]
# [0.21398863]
# [0. ]
# [0. ]
# [0. ]
# [0.56058105]]
res = res.ravel().argsort()[-3:] #元素从小到大排列,提取最后三个其对应的index(索引)
#[13 10 14]
print("top 3 docs for '{}':".format(q))
for i in res:
print(docs[i])
结果入下:
top 3 docs for ‘I get a coffee cup’:
I do not care who like bob, but I like kitty
I like coffee, I like book and I like apple
It is coffee time, bring your cup














 385
385











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









