









1.1 SAM的特点
SAM的特点、厉害之处在于:SAM可以进行零样本泛化和prompt分割

1.2 SAM的设计出发点
- 什么任务可以实现零样本泛化?
- 文章认为,首先需要定义一个可提示的分割任务,该任务足够通用,以提供强大的预训练目标并支持广泛的下游应用程序。
- 对应的模型架构是什么样的?
- 文章指出,需要一个支持灵活提示的模型(point、box、文字、mask),并且可以在提示时实时输出分割掩码,以供交互使用。

- 哪些数据可以为这项任务和模型提供支持
- 文章提出,训练模型需要多样化、大规模的数据源(使用了1100w张图像,十亿的mask ),为解决这一问题,可以构建一个数据引擎,即在使用高效模型来协助数据收集和使用新收集的数据来改进模型之间进行迭代。
1.3 模型结构

-
将prompt改成向量序列
- promptencoder:prompt总共有point,box,mask,text四种,会将其分为三类。
- point和box可以作为一类使用position encodings(位置向量)
- text可以使用CLIP作为encoder
- mask是一种密集型的prompt,可以使用卷积作为encoder
-
对图像进行特征提取的Image Encoder
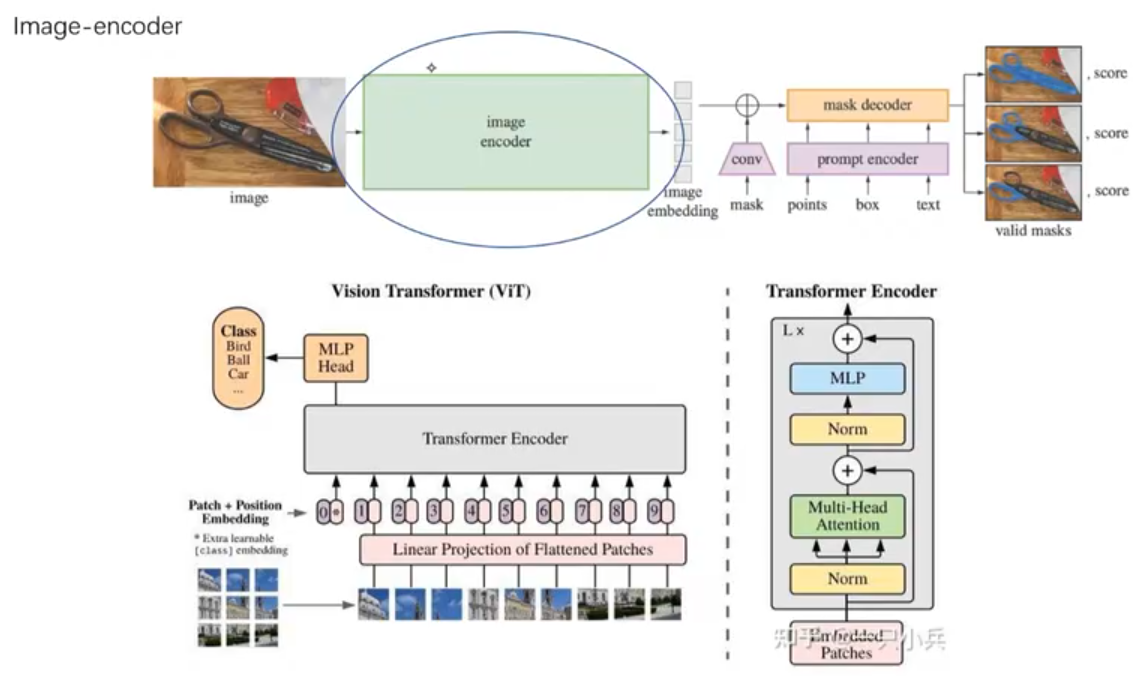
-
为什么这里使用transformer?因为使用transformer的类型,可以实现通用性,进行特征融合和多模态
-
mask decoder结构
- image embedding是图像特征
- output tokens是目标特征,假设我的点点在人物的衣服上,但此时model很难辨别你要分割的是一个人还是一件衣服,因此需要多个目标特征,一般是三个。
- prompt tokens是提示特征
- image to token atten:image作为query,token作为key和value
- token to image atten:token作为query,image作为key和value
- conv. trans.是恢复成图像尺寸,最终得到的masks的每一个像素点代表该像素是该类别的分数
- IOU Scores:分割出来的物体和目标物体的交集
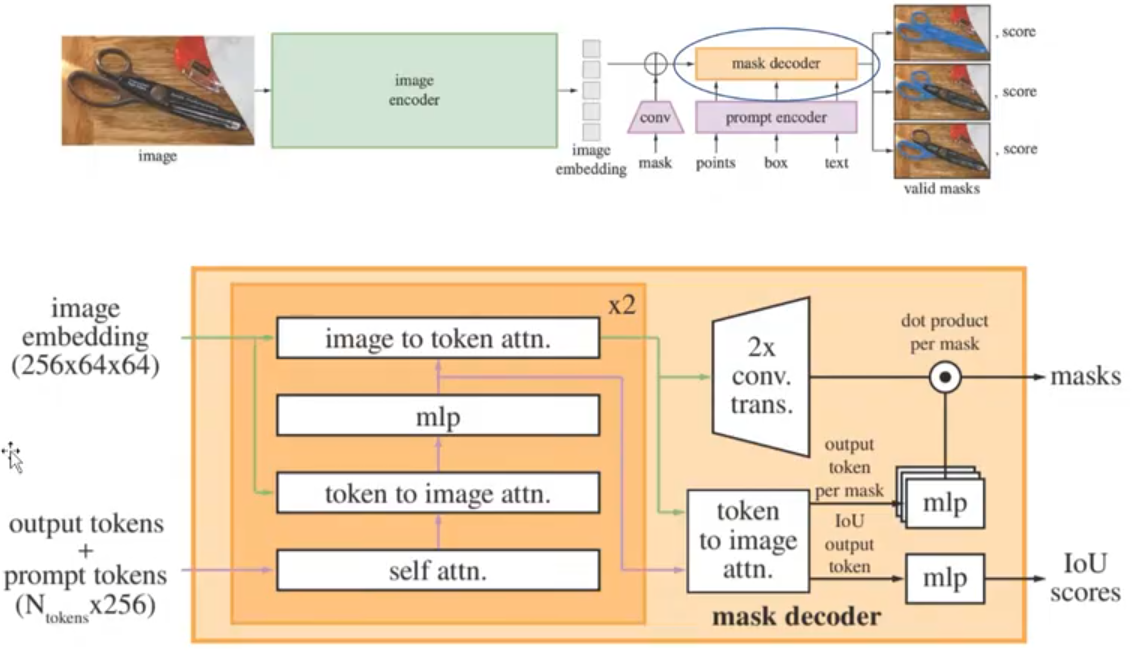
1、一个prompt,模型会输出3个mask,基本能满足大多数情况,主要解决物体之间相互覆盖 人穿衣服)
2、使用I0U的方式,排序mask。在反向传播时,参与计算的只有loss最小的mask相关的参数,只训练结果最好的,太差的直接忽略
3、loss和训练细节:主要使用的是focalloss。每一个mask,会随机产生11种prompt与之配对。
focal loss:
以例图中的分割剪刀为例,剪刀像素占全部像素的比例大致为20%,,这里得到的mask是类别极度不均衡的场景。这里使用传统的二分类损失函数会很难收敛。
focal loss是专门解决类别不均衡的分类:y=0是传统分类;y越大越看重难分的类别

1.4 数据引擎
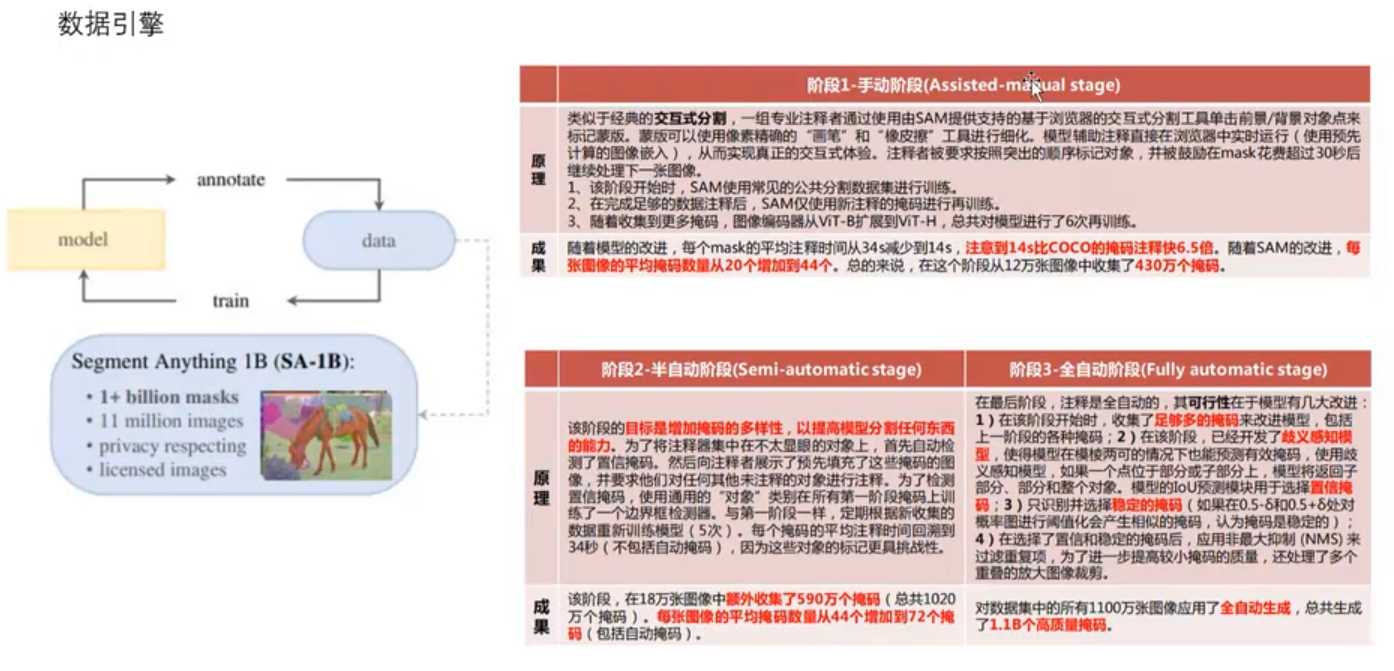
- 手动阶段
- 拿现有的小数据集训练一个粗糙版的SAM
- 粗糙版的SAM分割新数据,人工修正后重新训练模型
- 上两步反复迭代,此时model越来越好,数据越来越多
- 半自动阶段
- 用训练好的sam模型分割数据,把分割不出来的留给人来标。即默认sam能分出来的数据基本上是准确的。
- 自动阶段
- SAM模型在图像上分割,对得分较高,准确率较高,符合设定规则的结果进行保留。
1.5 SAM模型的问题
- 有时会产生幻觉,或者不会清晰地产生边界
- SAM是为通用性和使用广度设计的,而不是为高IoU交互式分割而设计的;
- SAM可以实时处理提示,但在使用重型图像编码器时,SAM的整体性能并不是实时的;
- 对text-to-mask任务的尝试是探索性的,并不完全可靠,需要更多努力使其改进
- SAM可以执行许多任务,但尚不清楚如何设计实现语义和全景分割的简单提示
- 在特定领域,其他工具的表现可能优于SAM。
1.6 应用领域
- 医学图像分割
- 抠图
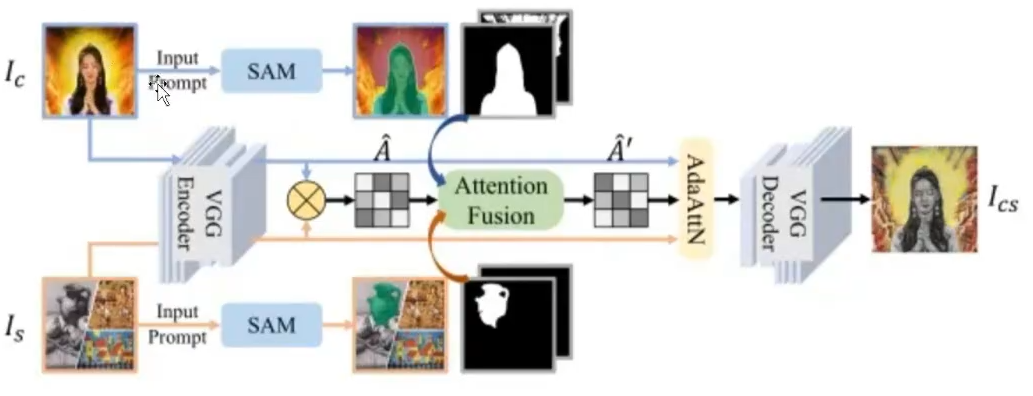
- 风格转换
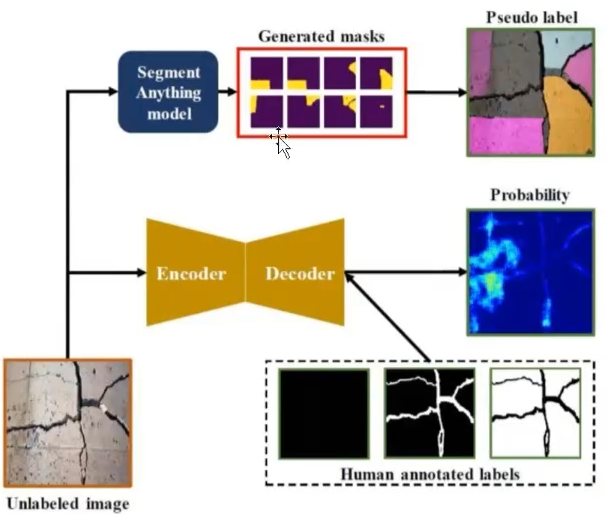
- 裂缝检测等…



















 348
348

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









