







一、完整的监控系统
大数据系统通常运行着众多的指标计算程序,想第一时间发现程序异常,需要一套完备的监控系统,能对运行现状进行可视化展示,并及时探查到运行异常并精准告警
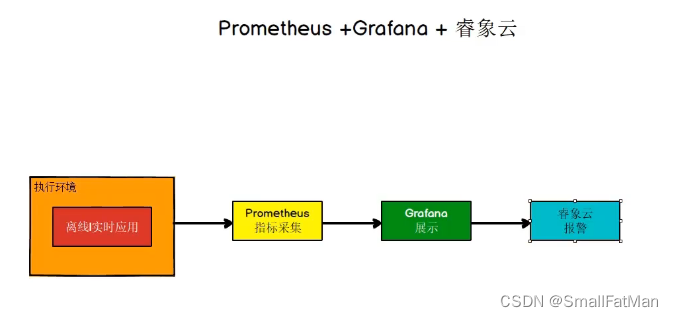
二、Prometheus属于存储计算层
一套完整的监控系统分为采集层>存储计算层>应用层
时间序列数据库TSDB
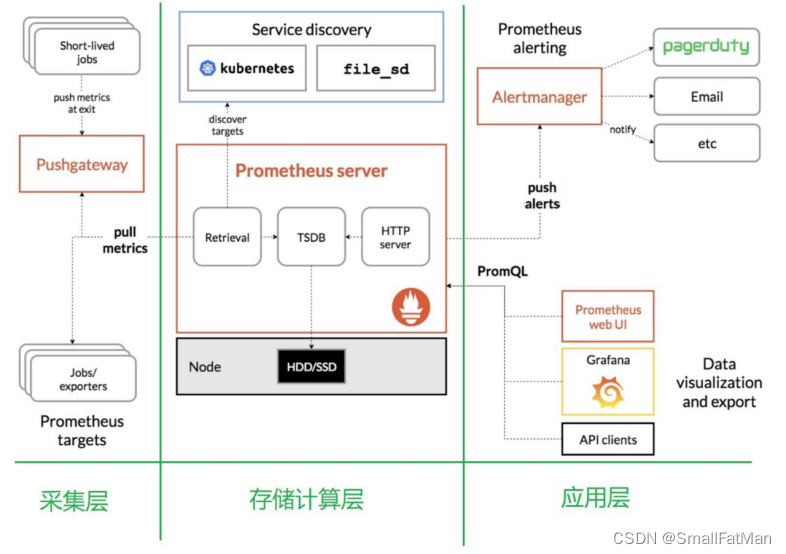
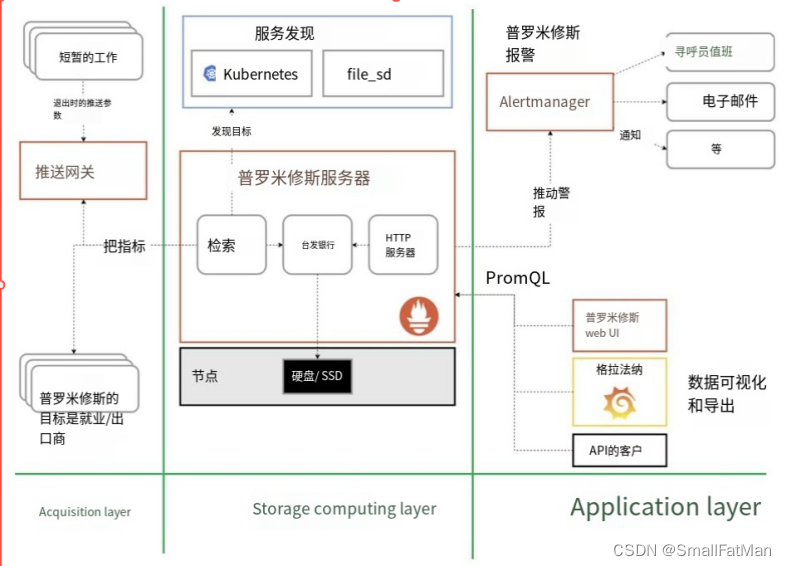
prometheus 负责从 pushgateway 和 job 中采集数据, 存储到后端 Storatge 中,可以通过PromQL 进行查询, 推送 alerts 信息到 AlertManager。 AlertManager 根据不同的路由规则进行报警通知

- Prometheus Server:主服务器,负责收集和存储时间序列数据,负责实现对监控数据的获取,存储以及查询。
- client libraies:应用程序代码插桩,将监控指标嵌入到被监控应用程序中
- Pushgateway:推送网关,为支持short-lived 作业提供一个推送网关。
- Pushgateway:由于 Prometheus 数据采集采用 pull 方式进行设置的, 内置必须保证 prometheus server 和对应的 exporter 必须通信;当网络情况无法直接满足时,可以使用 pushgateway来进行中转,可以通过pushgateway 将内部网络数据主动pus到gateway 里面去,而 prometheus采用pull方式拉取 pushgateway 中数据。
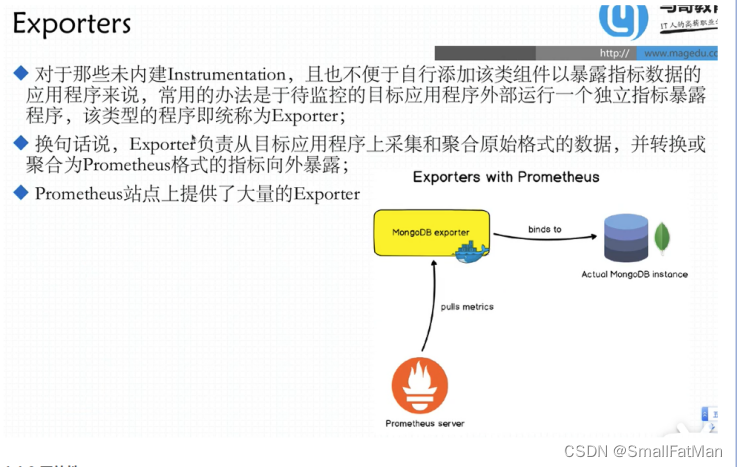
- exporter:专门为一些应用开发的数据摄取组件—exporter,例如:HAProxy、StatsD、Graphite 等等。
- exporter 简单说是采集端,通过 http 服务的形式保留一个 url 地址,prometheus server 通过访问该exporter 提供的 endpoint 端点,即可获取到需要采集的监控数据。
- AlertManager:在 prometheus 中,支持基于 PromQL创建告警规则,如果满足定义的规则,则会产生一条告警信息,进入 AlertManager 进行处理。可以集成邮件,微信或者通过webhook 自定义报警。可对接pagerduty(付费)
- HTTP Server:对外提供HTTP服务
进入到安装好的prometheus里
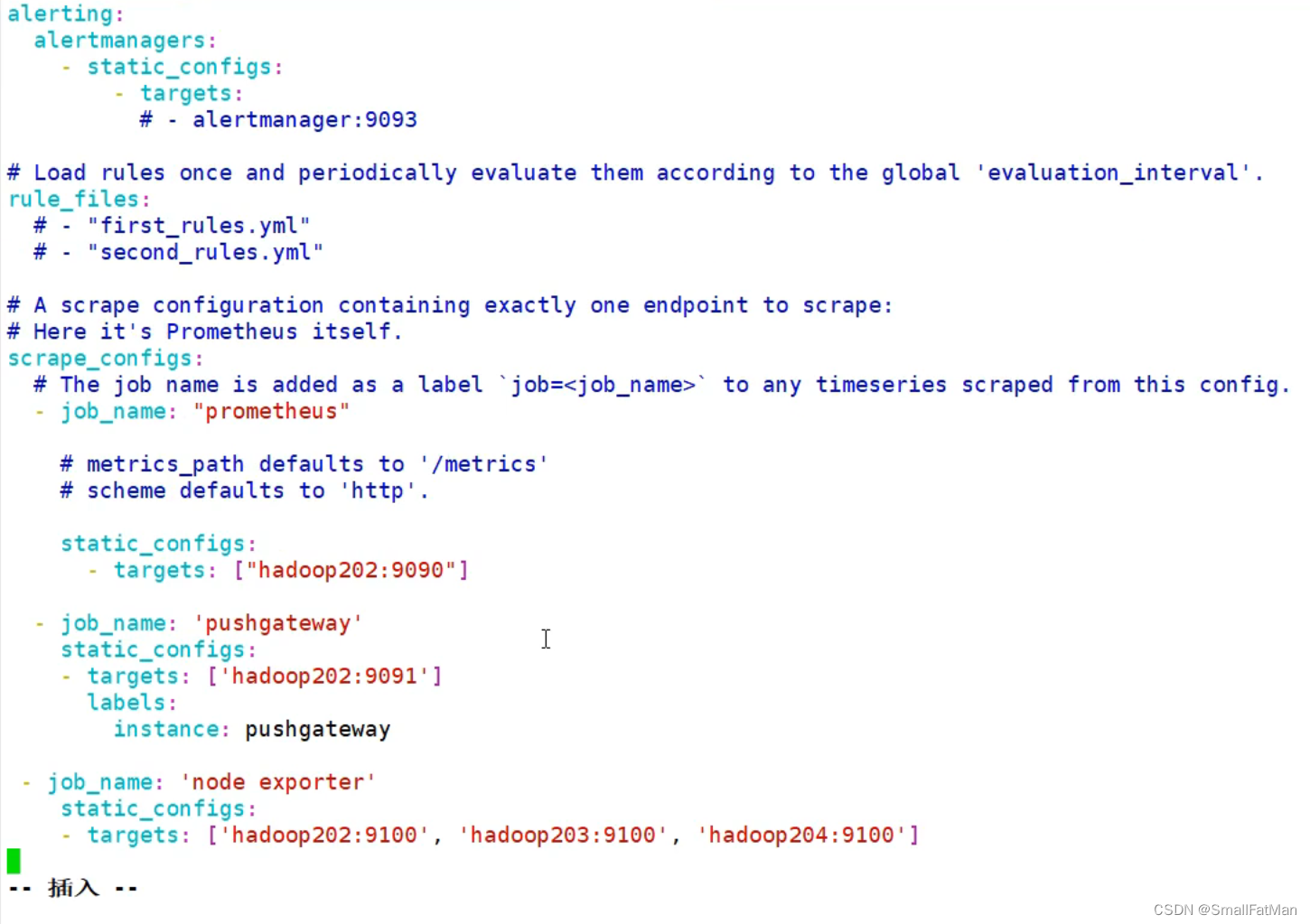
在prometheus配置文件.yml里添加你的探针服务器
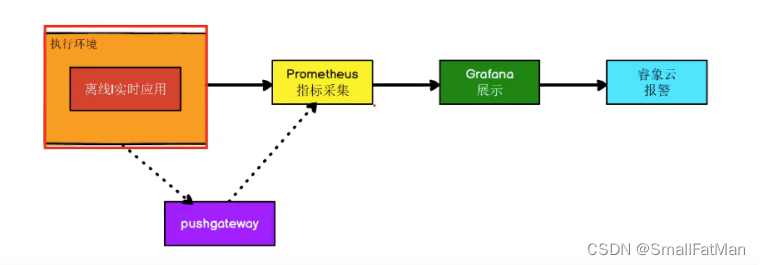
三、Prometheus监控流程
1、给被监控端打上exporter
2、安装配置prometheus服务器,并在配置文件添加上exporter的信息及ip:端口号,不同exporter端口号不同
3、安装配置Granfana服务器,并在其先添加好数据源DataSource
4、去Granfana仪表盘共享网站获取对应exporter的仪表盘,目的是代替PromQL去查询Prometheus数据,将获取到的仪表盘json文件导入Granfana选择添加好的数据源及完成
- Flink > pushgetway; 长期监控服务器 > exporter;
四、PromQL
Prometheus 通过指标名称(metrics name)以及对应的一组标签(labelset)唯一定义一条时间序列。指标名称反映了监控样本的基本标识,而 label 则在这个基本特征上为采集到的数据提供了多种特征维度。用户可以基于这些特征维度过滤,聚合,统计从而产生新的计算后的一条时间序列。PromQL 是 Prometheus 内置的数据查询语言,其提供对时间序列数据丰富的查询,聚合以及逻辑运算能力的支持。并且被广泛应用在 Prometheus的日常应用当中,包括对数据查询、可视化、告警处理当中。可以这么说,PromQL 是Prometheus 所有应用场景的基础,理解和掌握 PromQL 是 Prometheus 入门的第一课。
4.1、基本用法
4.1.1、查询时间序列
当 Prometheus 通过 Exporter 采集到相应的监控指标样本数据后,我们就可以通过
PromQL 对监控样本数据进行查询。
当我们直接使用监控指标名称查询时,可以查询该指标下的所有时间序列。如:
prometheus_http_requests_total
等同于:
prometheus_http_requests_total{}
该表达式会返回指标名称为 prometheus_http_requests_total 的所有时间序列:
prometheus_http_requests_total{code="200",handler="alerts",instance="localhost:9090",job="prometheus",method="get"}= (20889@1518096812.326)
prometheus_http_requests_total{code="200",handler="graph",instance="localhost:9090",job="prometheus",method="get"}= (21287@1518096812.326)
PromQL 还支持用户根据时间序列的标签匹配模式来对时间序列进行过滤,目前主要支持两种匹配模式:完全匹配和正则匹配。
4.1.2、PromQL 支持使用 = 和 != 两种完全匹配模式:
- 通过使用 label=value 可以选择那些标签满足表达式定义的时间序列;
- 反之使用 label!=value 则可以根据标签匹配排除时间序列;
例如,如果我们只需要查询所有 prometheus_http_requests_total 时间序列中满足标签 instance 为 localhost:9090 的时间 序列,则可以使用如下表达式:
prometheus_http_requests_total{instance="localhost:9090"}
反之使用 instance!=“localhost:9090” 则可以排除这些时间序列:
prometheus_http_requests_total{instance!="localhost:9090"}
4.1.3、PromQL还可以支持使用正则表达式作为匹配条件,多个表达式之间使用 | 进行分离:
- 使用
label=~regx表示选择那些标签符合正则表达式定义的时间序列; - 反之使用
label!~regx进行排除;
例如,如果想查询多个环节下的时间序列序列可以使用如下表达式:
prometheus_http_requests_total{environment=~"staging|testing|development",method!="GET"}
排除用法
prometheus_http_requests_total{environment!~"staging|testing|development",method!="GET"}
4.1.4、范围查询
直接通过类似于 PromQL 表达式 httprequeststotal 查询时间序列时,返回值中只会包含该时间序列中的最新的一个样本值,这样的返回结果我们称之为瞬时向量。而相应的这样的表达式称之为__瞬时向量表达式。
而如果我们想过去一段时间范围内的样本数据时,我们则需要使用区间向量表达式。区间向量表达式和瞬时向量表达式之间的差异在于在区间向量表达式中我们需要定义时间选择的范围,时间范围通过时间范围选择器 [] 进行定义。 例如,通过以下表达式可以选择最近 5 分钟内的所有样本数据:
prometheus_http_requests_total{}[5m]
该表达式将会返回查询到的时间序列中最近 5 分钟的所有样本数据:
prometheus_http_requests_total{code="200",handler="alerts",instance="localhost:9090",job="prometheus",method="get"}=[
1@1518096812.326
1@1518096817.326
1@1518096822.326
1@1518096827.326
1@1518096832.326
1@1518096837.325
]
prometheus_http_requests_total{code="200",handler="graph",instance="localhost:9090",job="prometheus",method="get"}=[
4@1518096812.326
4@1518096817.326
4@1518096822.326
4@1518096827.326
4@1518096832.326
4@1518096837.325
]
通过区间向量表达式查询到的结果我们称为区间向量。 除了使用 m 表示分钟以外,PromQL 的时间范围选择器支持其它时间单位:
- s - 秒
- m - 分钟
- h - 小时
- d - 天
- w - 周
- y - 年
4.1.5、时间位移操作
在瞬时向量表达式或者区间向量表达式中,都是以当前时间为基准:
prometheus_http_requests_total{} # 瞬时向量表达式,选择当前最新的数据
prometheus_http_requests_total{}[5m] # 区间向量表达式,选择以当前时间为基准,5 分钟内的数据
而如果我们想查询,5 分钟前的瞬时样本数据,或昨天一天的区间内的样本数据呢? 这个时候我们就可以使用位移操作,位移操作的关键字为 offset。 可以使用 offset 时间位移
操作:
prometheus_http_requests_total{} offset 5m
prometheus_http_requests_total{}[1d] offset 1d
4.1.6、使用聚合操作
一般来说,如果描述样本特征的标签(label)在并非唯一的情况下,通过 PromQL 查询数据,会返回多条满足这些特征维度的时间序列。而 PromQL 提供的聚合操作可以用来对这些时间序列进行处理,形成一条新的时间序列:
# 查询系统所有 http 请求的总量
sum(prometheus_http_requests_total)
# 按照 mode 计算主机 CPU 的平均使用时间
avg(node_cpu_seconds_total) by (mode)
# 按照主机查询各个主机的 CPU 使用率
sum(sum(irate(node_cpu_seconds_total{mode!='idle'}[5m])) /sum(irate(node_cpu_seconds_total [5m]))) by (instance)
4.1.7、标量和字符串
除了使用瞬时向量表达式和区间向量表达式以外,PromQL 还直接支持用户使用标量(Scalar)和字符串(String)
- 标量(Scalar):一个浮点型的数字值标量只有一个数字,没有时序。 例如:
10
需要注意的是,当使用表达式 count(prometheus_http_requests_total),返回的数据类型,依然是瞬时向量。用户可以通过内置函数 scalar()将单个瞬时向量转换为标量。
- 字符串(String):一个简单的字符串值
直接使用字符串,作为 PromQL 表达式,则会直接返回字符串。
"this is a string"
'these are unescaped: \n \\ \t'
`these are not unescaped: \n ' " \t`
4.1.8、合法的 PromQL 表达式
所有的 PromQL 表达式都必须至少包含一个指标名称(例如 http_request_total),或者一个不会匹配到空字符串的标签过滤器(例如{code=”200”})。
因此以下两种方式,均为合法的表达式:
prometheus_http_requests_total # 合法
prometheus_http_requests_total{} # 合法
{method="get"} # 合法
而如下表达式,则不合法:
{job=~".*"} # 不合法
同时,除了使用 {label=value} 的形式以外,我们还可以使用内置的 name 标签来指定监控指标名称:
{__name__=~"prometheus_http_requests_total"} # 合法
{__name__=~"node_disk_bytes_read|node_disk_bytes_written"} # 合法
4.1.9、 PromQL 操作符
使用 PromQL 除了能够方便的按照查询和过滤时间序列以外,PromQL 还支持丰富的操作符,用户可以使用这些操作符对进一步的对事件序列进行二次加工。
这些操作符包括:
数学运算符,逻辑运算符,布尔运算符等等。
1、数学运算
PromQL 支持的所有数学运算符如下所示:
+(加法)-(减法)*(乘法)/(除法)%(求余)^(幂运算)
2、布尔运算
Prometheus 支持以下布尔运算符如下:
==(相等)!=(不相等)>(大于)<(小于)>=(大于等于)<=(小于等于)
3、使用 bool 修饰符改变布尔运算符的行为
布尔运算符的默认行为是对时序数据进行过滤。而在其它的情况下我们可能需要的是真正的布尔结果。例如,只需要 知道当前模块的 HTTP 请求量是否>=1000,如果大于等于1000 则返回 1(true)否则返回 0(false)。这时可以使 用 bool 修饰符改变布尔运算的默认行为。 例如:
prometheus_http_requests_total > bool 1000
使用 bool 修改符后,布尔运算不会对时间序列进行过滤,而是直接依次瞬时向量中的各个样本数据与标量的比较结果 0 或者 1。从而形成一条新的时间序列。
prometheus_http_requests_total{code="200",handler="query",instance="localhost:9090",job="prometheus",method="get"} 1
prometheus_http_requests_total{code="200",handler="query_range",instance="localhost:9090",job="prometheus",method="get"} 0
同时需要注意的是,如果是在两个标量之间使用布尔运算,则必须使用 bool 修饰符
2 == bool 2 # 结果为 1
4.1.10、 使用集合运算符
使用瞬时向量表达式能够获取到一个包含多个时间序列的集合,我们称为瞬时向量。通过集合运算,可以在两个瞬时向量与瞬时向量之间进行相应的集合操作。
目前,Prometheus 支持以下集合运算符:
and(并且)or(或者)unless(排除)
vector1 and vector2 会产生一个由 vector1 的元素组成的新的向量。该向量包含
vector1 中完全匹配 vector2 中的元素组成。
vector1 or vector2 会产生一个新的向量,该向量包含 vector1 中所有的样本数据,
以及 vector2 中没有与 vector1 匹配到的样本数据。
vector1 unless vector2 会产生一个新的向量,新向量中的元素由 vector1 中没有与
vector2 匹配的元素组成。
4.1.11、 操作符优先级
对于复杂类型的表达式,需要了解运算操作的运行优先级。例如,查询主机的 CPU 使用率,可以使用表达式:
100 * (1 - avg (irate(node_cpu_seconds_total{mode='idle'}[5m])) by(job) )
其中irate是PromQL中的内置函数,用于计算区间向量中时间序列每秒的即时增长率。
在 PromQL 操作符中优先级由高到低依次为:
^*, /, %+, -==, !=, <=, =, >and, unlessor
4.1.12、 PromQL 聚合操作
Prometheus 还提供了下列内置的聚合操作符,这些操作符作用域瞬时向量。可以将瞬时表达式返回的样本数据进行 聚合,形成一个新的时间序列。
sum(求和)min(最小值)max(最大值)avg(平均值)stddev(标准差)stdvar(标准差异)count(计数)count_values(对 value 进行计数)bottomk(后 n 条时序)topk(前 n 条时序)quantile(分布统计)
使用聚合操作的语法如下:
<aggr-op>([parameter,] <vector expression>) [without|by (<label list>)]
其中只有 count_values , quantile , topk , bottomk 支持参数(parameter)。
without 用于从计算结果中移除列举的标签,而保留其它标签。by 则正好相反,结果向量中只保留列出的标签,其余标签则移除。通过 without 和 by 可以按照样本的问题对数据进行聚合。
例如:
sum(prometheus_http_requests_total) without (instance)
等价于
sum(prometheus_http_requests_total) by (code,handler,job,method)
如果只需要计算整个应用的 HTTP 请求总量,可以直接使用表达式:
sum(prometheus_http_requests_total)
count_values 用于时间序列中每一个样本值出现的次数。count_values 会为每一个唯一的样本值输出一个时间序列,并且每一个时间序列包含一个额外的标签。 例如:
count_values("count", prometheus_http_requests_total)
topk 和 bottomk 则用于对样本值进行排序,返回当前样本值前 n 位,或者后 n 位的时间序列。
获取 HTTP 请求数前 5 位的时序样本数据,可以使用表达式:
topk(5, prometheus_http_requests_total)
quantile 用于计算当前样本数据值的分布情况 quantile(φ, express)其中 0 ≤ φ ≤ 1。
例如,当 φ 为 0.5 时,即表示找到当前样本数据中的中位数:
quantile(0.5, prometheus_http_requests_total)
五、CA、CT和CPT
CA、CT和CPT是与告警平台相关的三个常见术语,它们代表以下含义:
-
CA(Correlation Analysis):决策分析。CA是告警平台中的一种分析方法,用于对收集到的告警数据进行相关性分析和决策判断。它通过对告警事件进行关联分析,找出事件之间的因果关系和共同特征,以帮助运维人员定位和解决问题。
-
CT(Correlation Technique):相关技术。CT是告警平台中的一种技术手段,主要用于将多个相关的告警事件进行关联和合并,以减少重复告警和降低运维人员的工作量。CT可以基于设定的规则或机器学习算法来实现告警的自动关联和聚合。
-
CPT(Critical Path Analysis):关键路径分析。CPT是告警平台中的一种分析方法,主要用于识别系统或业务中的关键路径,并分析其潜在的风险和影响。通过CPT,运维人员可以更好地了解系统的脆弱环节,及时采取措施以应对潜在的故障或异常情况。
这些术语在告警平台中具有不同的功能和用途,主要目的是提高告警处理的效率和准确性,帮助运维人员迅速定位和解决问题。
grafana比较局限,而且在使用模板的情况下是不允许进行Alert预警的,所以最后我直接采用了Prometheus下的alertmanager报警,放弃了grafana。
















 4609
4609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











