







深入解析ASR技术:从基础原理到模型优化
深入解析ASR技术:从基础原理到模型优化

一、ASR技术概述
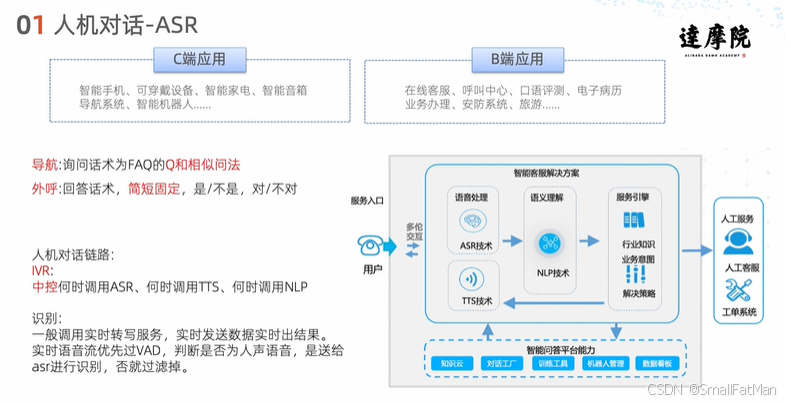
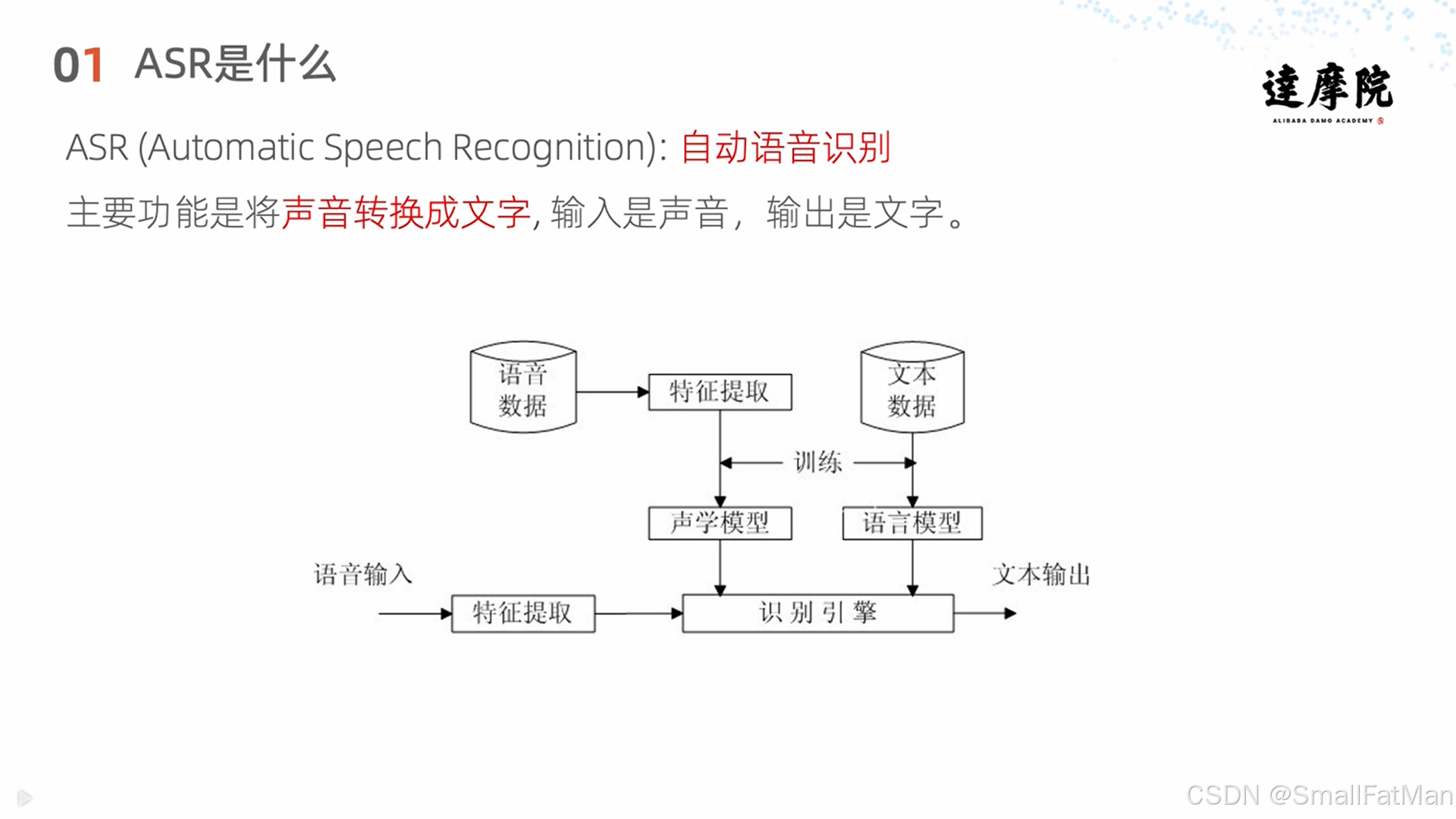

自动语音识别(Automatic Speech Recognition,ASR)是现代人机交互的核心技术之一,它使计算机能够将人类语音转换为可处理的文本数据。ASR技术已广泛应用于多个领域:
C端应用场景
- 智能手机语音助手
- 可穿戴设备语音控制
- 智能家电交互
- 智能音箱
- 导航系统语音输入
- 智能机器人对话
B端应用场景
- 在线客服系统
- 呼叫中心自动化
- 语言学习口语评测
- 电子病历语音录入
- 业务办理语音交互
- 安防系统语音监控
- 旅游行业智能导览
在导航场景中,ASR需要处理FAQ的标准问法和各种相似问法;在外呼场景中,则主要识别简短固定的应答如"是/不是"、"对/不对"等。
二、ASR核心原理
ASR系统由两大核心模型组成:
1. 声学模型(Acoustic Model)
声学模型负责处理声音信号,识别发音内容。它将音频特征映射到音素或子词单元,解决"发的是什么样的音"的问题。
示例:
- 音频输入:“wo shi yi ge xiao xue sheng”
- 声学识别结果:“wo shi yi ge xiao xue sheng”
2. 语言模型(Language Model)
语言模型处理文本的语义通顺度,基于统计规律或神经网络预测词序列的概率,解决"这句话是否通顺可理解"的问题。
示例对比:
- 声学相同输出:“wo shi yi ge xiao xue sheng”
- 可能文本结果:
- 错误:“我试一个晚雪升”
- 正确:“我是一个小学生”
三、ASR评价体系


1. 评价指标
ASR系统使用**字错误率(CER)**作为核心评价指标:
CER = (插入错误 + 替换错误 + 删除错误) / 总字数
字准率 = 100% - CER
错误类型定义:
- 插入错误(ins):识别结果中出现原文本没有的字
- 删除错误(del):原文本中的字在识别结果中缺失
- 替换错误(sub):原文本中的字被识别为其他字
2. 计算示例
标注文本:"我是北京中关村一小的学生"(12字)
识别结果:"*试北京中关村一小的学生啊"
分析:
- “我” → 删除错误(del=1)
- “试"替换"是” → 替换错误(sub=1)
- “啊” → 插入错误(ins=1)
计算:
CER = (1+1+1)/12 = 25%
字准率 = 100% - 25% = 75%
注:英文场景使用WER(词错误率),计算原理相同但以单词为单位。
四、ASR完整流程
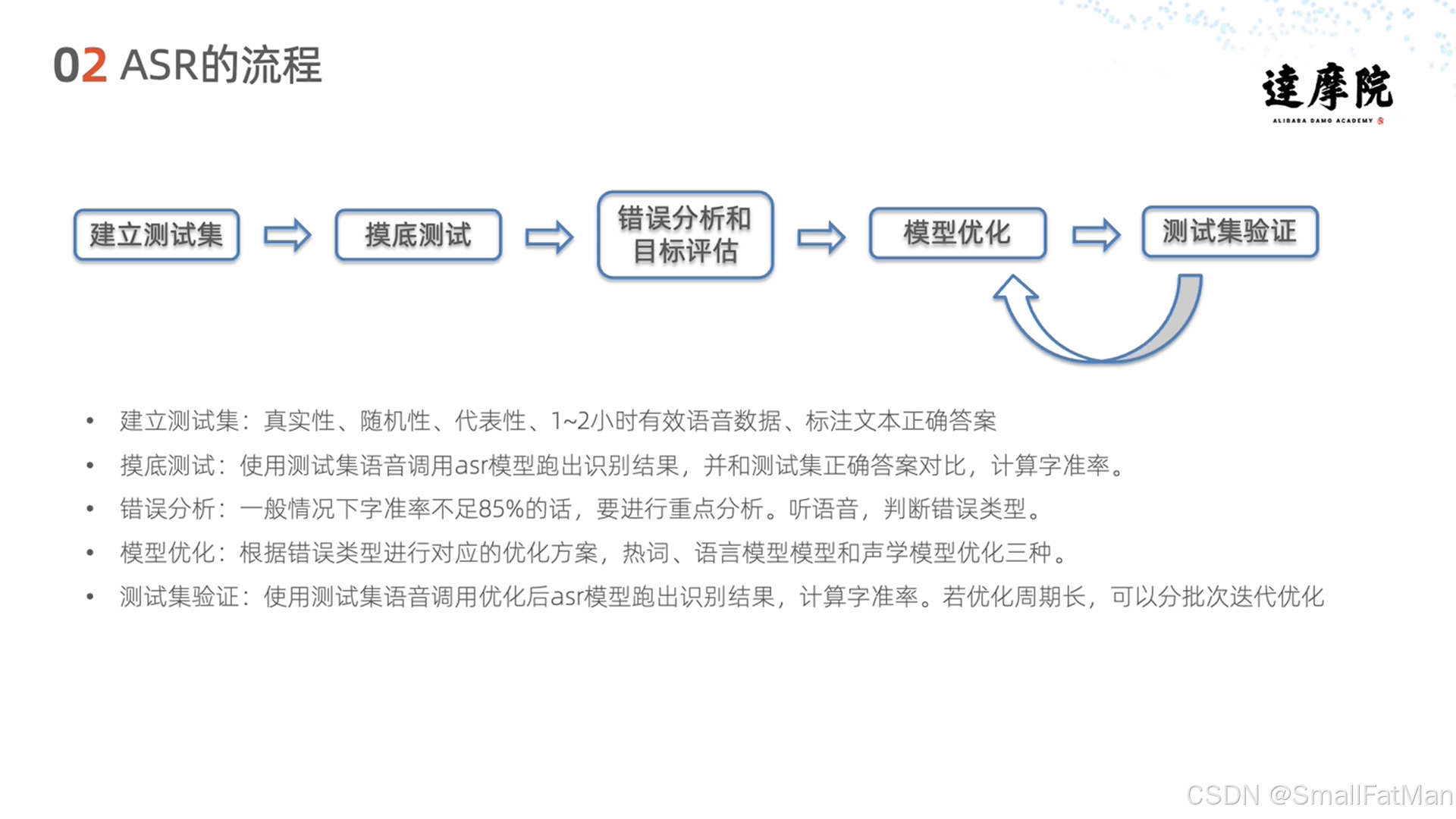
1. 建立测试集
- 采集1-2小时真实业务语音
- 确保数据具有代表性和随机性
- 人工标注准确文本作为标准答案
2. 模底测试
- 使用ASR模型识别测试集语音
- 对比识别结果与标注文本
- 计算初始字准率
3. 错误分析
- 字准率低于85%需重点分析
- 识别错误类型:声学错误或语言错误
- 检查语音质量和标注准确性
4. 模型优化
- 根据错误类型选择优化方案:
- 热词优化
- 语言模型定制
- 声学模型优化
5. 验证测试
- 使用优化后模型重新测试
- 计算优化后字准率
- 迭代优化直至达到目标指标
五、ASR模型优化策略


1. 错误分析三维度
(1) 语音特点分析
- 检查音频格式/采样率是否正确
- 识别噪声、口音、吞音等问题
- 评估音量是否合适
- 排除多人同时说话等无效场景
(2) 标注正确性验证
- 检查专业术语转写准确性
- 确认背景相关词汇的正确标注
- 示例错误:“和目路由"误标为"和睦路由”
(3) 识别错误类型判断
- 言对了字错了:语言模型问题
- 例:“我是一个小学生"→"我试一个喷墨子”
- 优化:加强语言模型
- 言错了:声学模型问题
- 例:“我是一个小学生"→"我这里是新东方”
- 优化:改进声学模型
2. 语言模型定制
| 基础模型输出 | 优化后输出 |
|---|---|
| 办了1个无线流量 | 办了1个无限流量 |
| 巴巴vip优酷会有权益 | 八八vip优酷会有权益 |
| 购物今天跟优惠券没有用上 | 购物津贴跟优惠券没有用上 |
优化方法:
- 收集领域特定语料(话术、制度文档等)
- 基于统计信息优化词关联概率
- 重点提升专有名词识别准确率
3. 声学模型优化
| 基础模型输出 | 优化后输出 |
|---|---|
| 投保人与实际淘宝人 | 投保人与实际投保人 |
| 工业叫狗赛到的 | 公安局交警大队 |
| 提出湘云歌姬恋 | 提出同原告借款 |
优化方法:
- 收集领域特定语音数据
- 针对口音、背景噪声等场景优化
- 特殊发音模式专项训练(数字字母组合等)
六、ASR技术架构
完整的人机对话系统中的ASR模块:
- 服务入口:接收用户语音输入
- 语音处理:
- 实时语音流经VAD(语音活动检测)
- 过滤非人声部分
- 有效语音送ASR识别
- 语义理解:结合NLP技术解析文本
- 服务引擎:基于行业知识生成响应
- ASR技术栈:声学模型+语言模型组合
- 智能问答平台:提供领域知识支持
七、总结与展望
ASR技术作为语音交互的入口,其准确性直接影响用户体验。通过建立科学的评价体系、系统的优化流程和针对性的模型调优,可以显著提升识别率。未来ASR技术将朝着以下方向发展:
- 端到端模型:简化传统流水线,提升整体性能
- 自适应学习:实时适应用户发音特点
- 多模态融合:结合视觉、上下文等信息提升准确率
- 低资源场景:提升小数据量下的模型表现
随着深度学习技术的发展,ASR系统的准确率和鲁棒性将持续提高,为人机交互创造更多可能性。
八、ASR常见问题解答


1. 基础问题
Q: 机器人抢话是怎么回事?
A: 这通常与VAD(语音活动检测)参数设置有关。检查VAD的后置参数(默认为800ms),若设置过小会导致系统过早判定用户说话结束。建议调整VAD参数平衡响应速度和对话体验。
Q: ASR在人机对话中识别什么内容?
A: 不同场景识别重点不同:
- 导航场景:识别FAQ的标准问法及相似问法
- 外呼场景:识别固定应答(是/不是)及相似回答
Q: 语音识别能达到100%准确吗?
A: 不可能。ASR基于概率算法,错误案例必然存在。评价应看整体识别率,而非单个案例。
2. 技术优化问题
Q: 如何提升端到端识别准确率?
A: 需多维度优化:
- 语音层面:
- 优化声学模型处理特殊发音
- 调整VAD阈值过滤非人声噪声
- 数据层面:
- 定期分析无意图语音数据
- 标注识别错误案例针对性优化
- 业务层面:
- 对不影响业务流程的识别错误(如语气词差异)可降低优化优先级
Q: 遇到数据质量问题怎么办?
A: 关键检查点:
- 确保语音数据无丢帧(影响相当于"题目只出一半")
- 检查VR链路数据传输逻辑
- 排除波形异常等质量问题
- 对问题数据分类处理(共性问题优先解决)
Q: 方言识别如何处理?
A: 区分两种情况:
- 重口音:
- 现有普通话模型已覆盖部分重口音
- 可通过额外声学训练加强
- 真正方言:
- 需从底层词典开始构建
- 要求上万小时标注数据
- 开发周期至少1年起
建议优先确认是否属于可理解的重口音范畴
3. 错误分析问题
Q: 错误分析需要哪些材料?
A: 完整分析需要:
- 错误语音原始数据
- ASR识别结果文本
- 错误描述(句子级别)
- 错误背景信息:
- 是否业务流程关键节点
- 是否高频出现
- 对业务影响程度
Q: 如何判断优化优先级?
A: 评估三维度:
- 业务影响:关键流程错误 > 非关键错误
- 出现频率:共性高频问题 > 个别案例
- 优化成本:语言模型优化通常比声学模型优化成本低
九、ASR实施关键要点
-
数据先行原则
- 确保接收完整的语音数据
- 建立1-2小时代表性测试集
- 定期更新测试集保持时效性
-
问题排查流程
-
优化策略选择
- 热词优化:快速解决特定词汇识别问题
- 语言模型定制:提升领域专业术语识别
- 声学模型优化:改善口音、噪声等场景表现
-
认知边界管理
- 接受算法固有瓶颈
- 对无法解决的问题考虑业务流程优化
- 平衡优化成本与收益
十、总结与最佳实践

-
实施建议
- 建立标准化测试评估流程
- 区分关键错误与非关键错误
- 优先解决高频共性问题
- 保持测试集与业务同步更新
-
避坑指南
- 避免过度优化非关键场景
- 不追求100%识别率
- 不依赖单一优化手段
- 不忽视数据质量检查
-
未来方向
- 自适应学习用户发音特征
- 融合上下文语义理解
- 开发轻量级方言解决方案
- 优化端到端模型效率
ASR技术作为智能交互的基础设施,需要持续优化和理性评估。通过系统化的测试方法、科学的错误分析和针对性的模型优化,可以不断提升识别效果,为业务创造更大价值。



















 2962
2962

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











