







题目
Interactive Path Reasoning on Graph for Conversational Recommendation
简介
这是一篇KDD 2020的文章,本文提出了会话路径推理,把Conversational Recommendation这个任务建模成一个在Graph中的路径推理任务。它按照用户反馈遍历属性顶点,以明确的方式利用用户偏好的属性,从而更有可能找到用户喜欢的items进行相关的推荐
引入了图结构,从而可以利用更多的信息。并且在这套框架中,推荐系统和对话系统是相互促进的。一方面,路径推理为对话系统提供了更自然的DST,使得对话选择从逻辑上更加完善;另一方面,可以直接从用户反馈中获得属性,使得搜索空间大大减小
why
传统的推荐系统根据过去的交互历史来估计用户对项目的偏好,因此受到获取细粒度和动态用户偏好的限制;对话式推荐系统(CRS)通过使系统能够直接询问用户他们对物品的偏好属性,解决了这些限制;然而,现有的CRS方法没有充分利用这种优势——它们只以相当隐含的方式使用属性反馈,只将用户反馈的attributes映射到latent space,没有发挥出最大的作用,要想让对话推荐系统更精确和可解释,需要更清楚明晰地利用attributes
因此,作者引入了图结构(进行更好地表示和可解释性),将对话推荐视为在user-item-attribute graph中交互地找到一条符合当前用户会话的path。这样不仅效果提升,还拥有更好的可解释性
what
- MULTI-ROUND CONVERSATIONAL RECOMMENDATION SCENARIO
对话推荐系统一般采用多轮的机制,即用户和系统进行交互的过程中,系统每向用户推荐一次items,即算一轮,推荐失败则进行下一轮,推荐成功则结束。此外,当系统询问的arribute用户喜欢/不喜欢时,增/删该用户的attribute集合;当系统推荐的item用户拒绝时,将该item从candidate items中删除

但是上述MCR情景做出了两个假设:
(1)假设用户通过指定属性明确表达自己的偏好,没有任何保留,数据集中包含首选属性的项目足够多。给定这个假设,CRS会将用户接受的属性作为一个强有力的指标。例如,它只考虑包含他接受的所有属性的所有项目(算法1中的第2行和第8行)。这是因为包含所有首选属性的项目比不包含的项目具有更高的优先级
(2)假设CRS不处理强烈的负面反馈。这意味着,如果用户拒绝被询问的属性,CRS不会区分用户是不关心它还是讨厌它。这是因为这种负反馈在目前的数据中很难获得,使得在实验环境中很难模拟。因此,CRS一致把所有被拒绝的属性当作并不关心,只从候选集中移除属性,而不移除包含被拒绝属性的所有项目
how
在MCR中,系统将属性视为偏好反馈,并在属性顶点上游走(即推理)。假设当前活动路径为P = p0,p1,p2,…,pt。系统停留在某点P,将寻找下一个要行走的属性顶点。这个过程可以分解为三个步骤:推理、协商和过渡
-
Reasoning
这一步骤可以解决这两个问题:
(1)推荐哪些项目?(2)问哪个属性?这一步CPR对项目和属性进行评分,采用了一种异步方式交替的去更新item score和attribute score,把打分问题给定义成信息在Graph中的传递问题
首先本文来计算candidate items的分数。文章将与一个path直接相连的items作为candidate items V,对于V中的每一个item v,可以计算它的分数,其中P代表一个用户在对话中偏爱的属性集合
然后,将和一个path直接相连的attributes减去user不喜欢的attributes得到candidate attributes集合P,对于P中的每一个candidate attribute p,本文可以(抽象地)计算它的分数:
这种相邻属性约束带来了两个好处:在推荐方面,显著减少了选择问哪个属性的搜索空间。像之前最先进的会话推荐系统将整个属性集P视为候选空间,增加了学习决策函数的难度
在会话方面,约束相邻属性使对话更加连贯。在语言学中,任何两个相邻话语中的两个实体越接近,对话就越连贯
-
Consultation
这一步骤可以解决以下问题:
什么时候问属性,什么时候做推荐?定义:
当Reasoning完成后,CPR进入到consultation step。这一步的目的是决定“当前是该问属性还是该推荐商品”,其目标是在最短的轮次达成一个成功的推荐,本文把这个选择问题定义成一个reinforcement learning proble方法:
使用一个policy function π,s代表全局对话状态,可以是任何对推荐有用的信息,比如对话历史,候选商品的信息等。policy function的输出空间只有两个:
ask:如果选择此action,从P中选择score最高的属性去问
rec:如果选择此action,从V中选择top-k的items去推荐
这个方法和之前的方法的区别是,之前的方法的policy function是决定“问哪个属性?”,这里是”问还是推荐?“,这样可以把action space降得很小,便于强化学习的训练 -
Transition
当询问的属性p被用户接受时,transition step就会触发。这一步要做的事情是把路径延伸,更新用户选择的属性集P,且更新候选属性集P和候选item集V 。如果属性被用户拒绝,只需将其从候选属性集中移除,而无需顶点转换
SCPR Model
为了实现CPR框架,一般需要指定函数f (v,u,Pu),g(u,p,Vcand)和π(s)。本文提供了一个简单的实现SCPR,在EAR的基础上更新了一些设计(更少的搜索空间和决策空间)
-
Reasoning - Item Scoring
在推理阶段,f (v,u,Pu)通过传播来自user-preferred attributes的信息来对itemv进行评分,使用两个顶点Embedding之间的内积作为消息:
-
Reasoning - Attribute Scoring
推理阶段的另一个问题,是根据当前系统状态决定哪个属性值得询问,一个理想的解决方案是找到一个很好地消除项目不确定性的策略。由于信息熵已被证明是一种有效的不确定性估计方法,所以将g(u,p,Vcand)函数设定为信息熵,但将其调整为加权方式:
其中,σ是sigmoid函数,Vcand表示candidate items,而Vp表示包含属性p的items。与原始的标准熵(平等对待每个项目)不同,本文在此使用加权熵为属性评分中的重要项目分配了更高的权重。如果没有消息传播到attribute,本文将其熵定义为0(notes:本文为了简单,没有考虑useru来计算g,虽然公式中有u,这并不意味着在决定属性时不重视u的重要性,未来可以基于此进行探索) -
Consultation - RL Policy
使用两层前馈神经网络作为本文的策略网络。为了加快收敛速度,本文使用标准的Deep Q-learning进行优化policy network的输入是全局状态s,输出是一个值 Q(s,a),其中a是 a(rec)或a(ask),表明是对action(rec或ask)的estimated reward,系统总是会选择具有较高估计回报的action
状态向量s是两个向量的串联:
输入s:
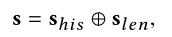
其中s(his)编码对话历史,s(len)代表候选item set的大小reward定义:
r(rec_suc):推荐成功
r(rec_faill):推荐失败
r(ask_suc):用户接受了询问的属性
r(ask’_faill): 用户拒绝了询问的属性
r(quit):session达到了最大轮次
Experiments


Conclusion
本文首次引入图来解决多轮会话推荐问题,并提出了会话路径推理框架。CPR将会话与基于图的路径推理同步,使得属性的利用更加明确,从而大大提高了会话推荐的可解释性















 353
353











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









