









Hadoop压缩和存储
一、Hive数据的压缩方式
| 压缩格式 | 算法 | 文件扩展名 | 是否可切分 |
|---|---|---|---|
| Gzip | DEFLATE | .gz | 否 |
| bzip2 | bzip2 | .ba2 | 是 |
| LZO | LZO | .lzo | 是 |
| Snappy | Snappy | .snappu | 否 |
重点是lzo和snappy,这俩之间的最主要区别是否可切片。在生产环境中用的更多是Snappy。
Gzip
优点:
- 压缩解压速度快 , 压缩率高 , hadoop本身支持
- 处理压缩文件时方便 , 和处理文本一样
- 大部分linux 系统自带 Gzip 命令 , 使用方便
缺点:
- 不支持切片
使用场景
- 文件压缩后在130M以内 (一个块大小) , 都可以使用 GZip 压缩(因为Gzip唯一的缺点是不能切片)
总结 : 不需要切片的情况下 可以使用
BZip2
优点:
- 压缩率高(高于Gzip)
- 可以切片
- hadoop自带 使用方便
缺点
- 压缩解压速度超级慢
使用场景
- 不要求压缩速率 ,但是对压缩率有要求的情况下 比如备份历史记录 , 备份文件
- 或者 输出的文件较大 , 处理后的数据需要减少磁盘存储并且以后使用数据的情况较少 (解压 / 压缩的情况较少)
- 对于单个文件 较大 ,又想压缩减少磁盘空间 , 并且兼容之前的应用程序的情况
总结 : 对于压缩解压速度没有要求的情况下
Lzo
优点
- 压缩解压速度比较快 , 压缩率也可以
- 支持切片 是hadoop 比较流行的压缩格式
- 可以在linux 下安装 lzo命令 使用方便
缺点
- 压缩率比Gzip低一些
- hadoop 本身不支持, 需要自己安装
- 使用Lzo 格式的文件时需要做一些特殊处理(为了支持 Split 需要建立索引 , 还需要家将 InputFormat 指定为Lzo 格式 [特殊]
使用场景
- 压缩以后还大于 200M 的文件 , 且文件越大 Lzo 的优势越明显
- (原因很简单 , 四种压缩方式 只有BZip2 , LZO支持切片 , 然后 BZip2 你懂的 , 速度贼慢 ,只能用于特定的场景, 所以 Lzo 是比较经常用的 )
总结 : 压缩后文件还是比较大 需要切片的情况下 推荐使用
Snappy
优点
- 高压缩解压速度 , 压缩率还可以
缺点
- 不能切片
- 压缩率比Gzip小
- hadoop本身不支持 需要安装
使用场景
- 当Mapeduce的Map阶段输出的数据比较大的时候 , 作为Map到Reduce的中间数据的压缩格式
- 作为一个MapReduce作业的输出和另一个MapReduce的输入
总结 : 因为压缩率不怎么样 还不能切片 , 所以在一般的作为输入文件压缩时可以用 GZip 和 Lzo 都比Snappy
总结 :
压缩速率 : Snappy > GZIp > Lzo >BZip2
支持切片 : BZIp2 LZo
压缩率 : BZip2 > GZip > Lzo > Snappy
二、 开启 Map 输出阶段压缩(MR 引擎)
开启 map 输出阶段压缩可以减少 job 中 map 和 Reduce task 间数据传输量。具体配置如下:
(1)开启 hive 中间传输数据压缩功能:
hive (default)>set hive.exec.compress.intermediate=true;
(2)开启 mapreduce 中 map 输出压缩功能
hive (default)>set mapreduce.map.output.compress=true;
(3)设置 mapreduce 中 map 输出数据的压缩方式
hive (default)>set mapreduce.map.output.compress.codec= org.apache.hadoop.io.compress.SnappyCodec;
(4)执行查询语句
hive (default)> select count(ename) name from emp;
三、开启 Reduce 输出阶段压缩
当 Hive 将 输 出 写 入 到 表 中 时 , 输出内容同样可以 进行压缩。属 性 hive.exec.compress.output 控制着这个功能。用户可能需要保持默认设置文件中的默认值 false, 这样默认的输出就是非压缩的纯文本文件了。用户可以通过在查询语句或执行脚本中设置这个值为 true,来开启输出结果压缩功能。
(1)开启 hive 最终输出数据压缩功能
hive (default)>set hive.exec.compress.output=true;
(2)开启 mapreduce 最终输出数据压缩
hive (default)>set mapreduce.output.fileoutputformat.compress=true;
(3)设置 mapreduce 最终数据输出压缩方式
hive (default)> set mapreduce.output.fileoutputformat.compress.codec = org.apache.hadoop.io.compress.SnappyCodec;
(4)设置 mapreduce 最终数据输出压缩为块压缩
hive (default)> set mapreduce.output.fileoutputformat.compress.type=BLOCK;
(5)测试一下输出结果是否是压缩文件
hive (default)> insert overwrite local directory '/opt/module/data/distribute-result' select * from emp distribute by deptno sort by empno desc;
四、Hive数据的存储方式
hive在建表的时候 通过语句 [STORED AS file_format] – 指定数据在文件中的存储格式
Hive支持的存储数据的格式主要有:TEXTFILE 、SEQUENCEFILE、ORC、PARQUET。
列式存储和行式存储的特点
如图所示左边为逻辑表,右边第一个为行式存储,第二个为列式存储。
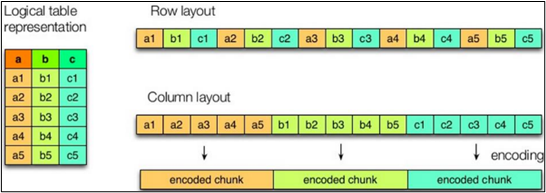
行存储的特点
查询满足条件的一整行数据的时候,列存储则需要去每个聚集的字段找到对应的每个列的值,行存储只需要找到其中一个值,其余的值都在相邻地方,所以此时行存储查询的速度更快。
也就是说找到索引 直接找到这一整行的数据 便于直接查找,但是聚合运算不如列式存储.
列存储的特点
因为每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量;每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的设计压缩算法。
可以很快的进行聚合运算,因为一列的数都是存储在一个区域.
TEXTFILE和SEQUENCEFILE的存储格式都是基于行存储的;
ORC和PARQUET是基于列式存储的。
存储格式的优缺点
TextFile
默认格式,数据不做压缩,磁盘开销大,数据解析开销大。可结合Gzip、Bzip2使用,但使用Gzip这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作。
Orc格式
Orc (Optimized Row Columnar)是Hive 0.11版里引入的新的存储格式。
如下图所示可以看到每个Orc文件由1个或多个stripe组成,每个stripe一般为HDFS的块大小,每一个stripe包含多条记录,这些记录按照列进行独立存储,对应到Parquet中的row group的概念。每个Stripe里有三部分组成,分别是Index Data,Row Data,Stripe Footer:

1)Index Data:一个轻量级的index,默认是每隔1W行做一个索引。这里做的索引应该只是记录某行的各字段在Row Data中的offset。
2)Row Data:存的是具体的数据,先取部分行,然后对这些行按列进行存储。对每个列进行了编码,分成多个Stream来存储。
3)Stripe Footer:存的是各个Stream的类型,长度等信息。
每个文件有一个File Footer,这里面存的是每个Stripe的行数,每个Column的数据类型信息等;每个文件的尾部是一个PostScript,这里面记录了整个文件的压缩类型以及FileFooter的长度信息等。在读取文件时,会seek到文件尾部读PostScript,从里面解析到File Footer长度,再读FileFooter,从里面解析到各个Stripe信息,再读各个Stripe,即从后往前读。
Parquet格式
arquet文件是以二进制方式存储的,所以是不可以直接读取的,文件中包括该文件的数据和元数据,因此Parquet格式文件是自解析的。也是spark读取文件的默认格式.
(1)行组(Row Group):每一个行组包含一定的行数,在一个HDFS文件中至少存储一个行组,类似于orc的stripe的概念。
(2)列块(Column Chunk):在一个行组中每一列保存在一个列块中,行组中的所有列连续的存储在这个行组文件中。一个列块中的值都是相同类型的,不同的列块可能使用不同的算法进行压缩。
(3)页(Page):每一个列块划分为多个页,一个页是最小的编码的单位,在同一个列块的不同页可能使用不同的编码方式。
通常情况下,在存储Parquet数据的时候会按照Block大小设置行组的大小,由于一般情况下每一个Mapper任务处理数据的最小单位是一个Block,这样可以把每一个行组由一个Mapper任务处理,增大任务执行并行度
存储和压缩结合该如何选择?
根据ORC和parquet的要求,一般就有了
1、ORC格式存储,Snappy压缩
create table stu_orc(id int,name string)
stored as orc
tblproperties ('orc.compress'='snappy');
2、Parquet格式存储,Lzo压缩
create table stu_par(id int,name string)
stored as parquet
tblproperties ('parquet.compression'='lzo');
3、Parquet格式存储,Snappy压缩
create table stu_par(id int,name string)
stored as parquet
tblproperties ('parquet.compression'='snappy');
总结:因为Hive 的SQL会转化为MR任务,如果该文件是用ORC存储,Snappy压缩的,因为Snappy不支持文件分割操作,所以压缩文件「只会被一个任务所读取」,如果该压缩文件很大,那么处理该文件的Map需要花费的时间会远多于读取普通文件的Map时间,这就是常说的「Map读取文件的数据倾斜」。
那么为了避免这种情况的发生,就需要在数据压缩的时候采用bzip2和lzo等支持文件分割的压缩算法。但恰恰ORC不支持刚说到的这些压缩方式,所以这也就成为了大家在可能遇到大文件的情况下不选择ORC的原因,避免数据倾斜。
「所以在实际生产中,使用Parquet存储,lzo压缩的方式更为常见,这种情况下可以避免由于读取不可分割大文件引发的数据倾斜。 但是,如果数据量并不大(预测不会有超大文件,若干G以上)的情况下,使用ORC存储,snappy压缩的效率还是非常高的。」
面试题:为什么采用parquet+lzo?
HiveSQL转化成MR任务的时候,如果文件过大,MR的map端读取所花费的时间过长,就会造成数据倾斜的问题。为了避免上面的问题出现,所以建议采用支持切片的压缩方式LZO/BZIP2。而这两种支持切片的压缩方式中,LZO的速度明显高于BZIP2。而在存储上,orc的存储方式是不支持这些压缩方式,所以采用Parquet作为存储。
五、map的各个阶段适合采用什么压缩
MapReduce里面需要采用压缩的地方有三个:
Map端的输入:这个阶段需要满足的条件是要能切片,LZO和BZIP2
Map端的输出:这个阶段要满足的条件是要快,所以适合采用Snappy
Reduce端的输出:这个阶段最主要的是所压缩的文件要够小,因此适合采用GZIP

















 925
925











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











