







一、进程、线程、协程
- 进程 ,指一个程序在给定数据集合上的一次执行过程,是系统进行资源分配和运行调用的独立单位。可以简单地理解为操作系统中正在执行的程序。也就说,每个应用程序都有一个自己的进程。
- 线程 ,线程是一个基本的CPU执行单元。它必须依托于进程存活。一个线程是一个execution context(执行上下文),即一个CPU执行时所需要的一串指令。
- 协程 , 是一个可以在某个地方挂起的特殊函数,并且可以重新在挂起处继续运行。一个线程也可以包含多个协程,所以说,协程与进程、线程相比,不是一个维度的概念。
- 进程与线程区别
1、线程必须在某个进程中执行。
2、一个进程可包含多个线程,其中有且只有一个主线程。
3、多线程共享同个地址空间、打开的文件以及其他资源。
4、多进程共享物理内存、磁盘、打印机以及其他资源。
每一个进程启动时都会最先产生一个线程,即主线程。然后主线程会再创建其他的子线程。线程一般分为主线程、子线程、守护线程(后台)、前台线程
GIL
-
全局解释器锁 Global Interpreter Lock
计算机程序设计语言解释器用于同步线程的一种机制,它使得任何时刻仅有一个线程在执行,所以即便在多核心处理器中,使用GIL解释器也只允许同一时间执行一个线程
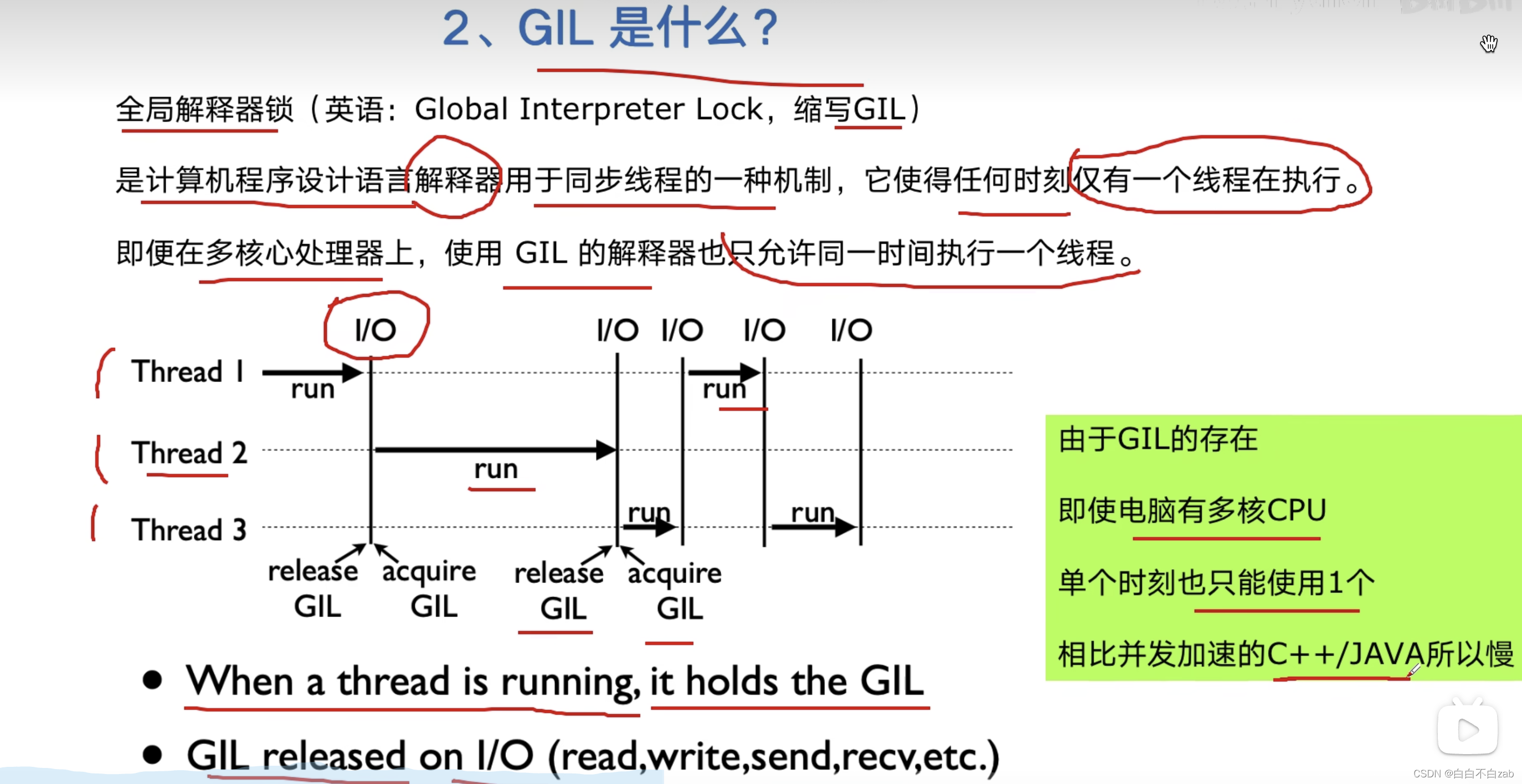
-
python对象管理,是使用引用计数器进行的,引用数为0则释放对象

GIL好处:简化了python对共享资源的管理 -
如何规避GIL带来的限制
1、多线程threading 机制依然是有用的,用于IO密集型计算
因为在I/O(read,write,send,recv,etc.)期间,线程会释放GIL,实现CPU和IO的并行,但是多线程用于CPU密集型计算时,只会更加拖慢速度
2、使用multiprocessing的多进程机制实现并行计算、利用多核CPU优势。
为了应对GIL的问题,Python提供了multiprocessing -
扩展
GIL只在CPython解释器中才有,而在PyPy和Jython中是没有GIL的。
二、多线程使用
1、导入threading,直接使用
import threading
def heart_thread(self):
"""使用列表推导式创建线程池"""
threads = [threading.Thread(target=self.xiaotu_heart, args=(i, i+500)) for i in range(0, 10000, 500)]
[i.start() for i in threads]
[i.join() for i in threads]
2、继承threading.Thread来自定义线程类,重写run方法
import threading
class MyThread(threading.Thread):
def __init__(self, n):
super(MyThread, self).__init__() # 重构run函数必须要写
self.n = n
def run(self):
print("current task:", n)
if __name__ == "__main__":
t1 = MyThread("thread 1")
t2 = MyThread("thread 2")
t1.start()
t2.start()
使用元组方式传参
例子:
(url,)加逗号叫元组
(url)不加逗号叫字符串,string
线程合并
join函数执行顺序是逐个执行每个线程,执行完毕后继续往下执行。主线程结束后,子线程还在运行,join函数使得主线程等到子线程结束时才退出。
def heart_thread(self):
"""小兔-多线程探活"""
threads = [threading.Thread(target=self.xiaotu_heart, args=(i, i+500)) for i in range(0, 10000, 500)]
[i.start() for i in threads]
[i.join() for i in threads]
线程安全问题,线程锁
- 互斥锁
线程之间数据共享的。当多个线程对某一个共享数据进行操作时,就需要考虑到线程安全问题。threading模块中定义了Lock 类,提供了互斥锁的功能来保证多线程情况下数据的正确性。
1、锁定方法acquire可以有一个超时时间的可选参数timeout。如果设定了timeout,则在超时后通过返回值可以判断是否得到了锁,从而可以进行一些其他的处理。
#创建锁
mutex = threading.Lock()
#锁定
mutex.acquire([timeout])
mutex.acquire(1)
#释放
mutex.release()
lock = threading.Lock()
def xiaotu_pipei(self, x, y):
"""小兔匹配"""
with lock:
xiaotu_user = YamlHandler(USER_NUMBER).read_yaml()
cut_user = xiaotu_user[x:y]
for i in range(len(cut_user)):
xiaotu = cut_user[i]['user_id']
self.data['partyType'] = 2
match_res = r().post(url="xxx", headers=AppHeader(xiaotu).get_headers(), data=json.dumps(self.data))
print(f'{threading.current_thread().name}-{xiaotu}-{random_time()}-匹配:{match_res}')
self.yaml['partyType'] = 2
self.yaml['partyID'] = match_res['data']['partyInfo']['partyID']
game_res = r().get(url="xxx", headers=AppHeader(xiaotu).get_headers(), params=self.yaml)
print(f'{threading.current_thread().name}-{xiaotu}-{random_time()}-探活1:{game_res}')
- 递归锁(可重入锁)
为了满足在同一线程中多次请求同一资源的需求,Python提供了可重入锁(RLock)。RLock内部维护着一个Lock和一个counter变量,counter记录了acquire 的次数,从而使得资源可以被多次require。直到一个线程所有的acquire都被release,其他的线程才能获得资源。
#创建 RLock
mutex = threading.RLock()
class MyThread(threading.Thread):
def run(self):
if mutex.acquire(1):
print("thread " + self.name + " get mutex")
time.sleep(1)
mutex.acquire()
mutex.release()
mutex.release()
importtimeimportthreading
A= threading.RLock() #这里设置锁为递归锁
importthreadingclassobj(threading.Thread):def __init__(self):
super().__init__()defrun(self):
self.a()
self.b()def a(self): #递归锁,就是将多个锁的钥匙放到一起,要拿就全拿,要么一个都拿不到
#以实现锁
A.acquire()print('123')print(456)
time.sleep(1)print('qweqwe')
A.release()defb(self):
A.acquire()print('asdfaaa')print('(⊙o⊙)哦(⊙v⊙)嗯')
A.release()for i in range(2):
t=obj()
t.start()
- 死锁
两个或两个以上的线程或进程在执行程序的过程中,因争夺资源而相互等待,程序会出现阻塞现象
importtimeimportthreading
A=threading.Lock()
B=threading.Lock()importthreadingclassobj(threading.Thread):def __init__(self):
super().__init__()defrun(self):
self.a()#如果两个锁同时被多个线程运行,就会出现死锁现象
self.b()defa(self):
A.acquire()print('123')
B.acquire()print(456)
time.sleep(1)
B.release()print('qweqwe')
A.release()defb(self):
B.acquire()print('asdfaaa')
A.acquire()print('(⊙o⊙)哦(⊙v⊙)嗯')
A.release()
B.release()for i in range(2): #循环两次,运行四个线程,第一个线程成功处理完数据,第二个和第三个就会出现死锁
t =obj()
t.start()
-
守护线程
如果希望主线程执行完毕之后,不管子线程是否执行完毕都随着主线程一起结束。我们可以使用setDaemon(bool)函数,它跟join函数是相反的。它的作用是设置子线程是否随主线程一起结束,必须在start() 之前调用,默认为False。 -
定时器
如果需要规定函数在多少秒后执行某个操作,需要用到Timer类。
from threading import Timer
def show():
print("Pyhton")
# 指定一秒钟之后执行 show 函数
t = Timer(1, hello)
t.start()
三、多进程
1、直接使用muiltprocessing库中的Process类
from multiprocessing import Process
def show(name):
print("Process name is " + name)
if __name__ == "__main__":
proc = Process(target=show, args=('subprocess',))
proc.start()
proc.join()
2、继承Process来自定义进程类,重写run方法
from multiprocessing import Process
import time
class MyProcess(Process):
def __init__(self, name):
super(MyProcess, self).__init__()
self.name = name
def run(self):
print('process name :' + str(self.name))
time.sleep(1)
if __name__ == '__main__':
for i in range(3):
p = MyProcess(i)
p.start()
for i in range(3):
p.join()
多进程通信
进程之间不共享数据的。如果进程之间需要进行通信,则要用到Queue模块或者Pipe模块来实现。
- Queue
Queue是多进程安全的队列,可以实现多进程之间的数据传递。它主要有两个函数put和get。
1、put() 用以插入数据到队列中,put还有两个可选参数:blocked 和timeout。如果blocked为 True(默认值),并且timeout为正值,该方法会阻塞timeout指定的时间,直到该队列有剩余的空间。如果超时,会抛出 Queue.Full异常。如果blocked为False,但该Queue已满,会立即抛出Queue.Full异常。
2、get()可以从队列读取并且删除一个元素。同样get有两个可选参数:blocked和timeout。如果blocked为True(默认值),并且 timeout为正值,那么在等待时间内没有取到任何元素,会抛出Queue.Empty异常。如果blocked为False,有两种情况存在,如果Queue有一个值可用,则立即返回该值,否则,如果队列为空,则立即抛出Queue.Empty异常。
from multiprocessing import Process, Queue
def put(queue):
queue.put('Queue 用法')
if __name__ == '__main__':
queue = Queue()
pro = Process(target=put, args=(queue,))
pro.start()
print(queue.get())
pro.join()
- Pipe
Pipe的本质是进程之间的用管道数据传递,而不是数据共享,这和socket有点像。pipe() 返回两个连接对象分别表示管道的两端,每端都有send()和recv()函数。如果两个进程试图在同一时间的同一端进行读取和写入那么,这可能会损坏管道中的数据.
from multiprocessing import Process, Pipe
def show(conn):
conn.send('Pipe 用法')
conn.close()
if __name__ == '__main__':
parent_conn, child_conn = Pipe()
pro = Process(target=show, args=(child_conn,))
pro.start()
print(parent_conn.recv())
pro.join()
- 进程池
使用Pool模块创建多个进程
#coding: utf-8
import multiprocessing
import time
def func(msg):
print("msg:", msg)
time.sleep(3)
print("end")
if __name__ == "__main__":
# 维持执行的进程总数为processes,当一个进程执行完毕后会添加新的进程进去
pool = multiprocessing.Pool(processes = 3)
for i in range(5):
msg = "hello %d" %(i)
# 非阻塞式,子进程不影响主进程的执行,会直接运行到 pool.join()
pool.apply_async(func, (msg, ))
# 阻塞式,先执行完子进程,再执行主进程
# pool.apply(func, (msg, ))
print("Mark~ Mark~ Mark~~~~~~~~~~~~~~~~~~~~~~")
# 调用join之前,先调用close函数,否则会出错。
pool.close()
# 执行完close后不会有新的进程加入到pool,join函数等待所有子进程结束
pool.join()
print("Sub-process(es) done.")
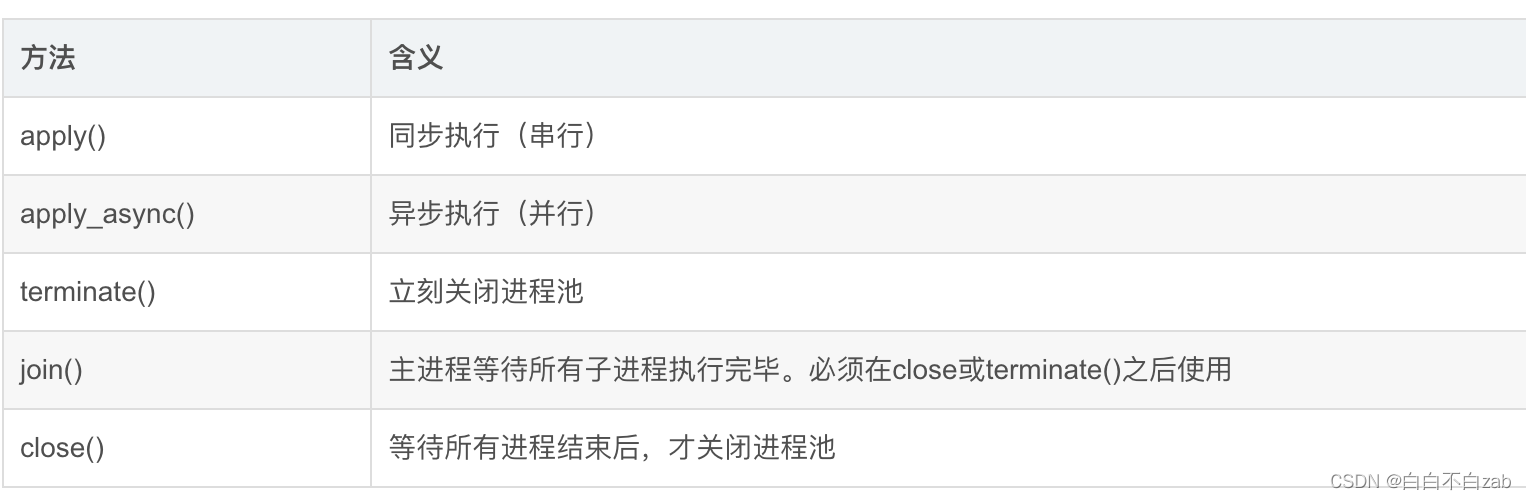
1、如上,进程池Pool被创建出来后,即使实际需要创建的进程数远远大于进程池的最大上限,p.apply_async(test)代码依旧会不停的执行,并不会停下等待;相当于向进程池提交了10个请求,会被放到一个队列中;
2、当执行完p1 = Pool(5)这条代码后,5条进程已经被创建出来了,只是还没有为他们各自分配任务,也就是说,无论有多少任务,实际的进程数只有5条,计算机每次最多5条进程并行。
3、当Pool中有进程任务执行完毕后,这条进程资源会被释放,pool会按先进先出的原则取出一个新的请求给空闲的进程继续执行;
4、当Pool所有的进程任务完成后,会产生5个僵尸进程,如果主线程不结束,系统不会自动回收资源,需要调用join函数去回收。
5、join函数是主进程等待子进程结束回收系统资源的,如果没有join,主程序退出后不管子进程有没有结束都会被强制杀死;
6、创建Pool池时,如果不指定进程最大数量,默认创建的进程数为系统的内核数量.
四、异步
异步处理是一种并发编程模式,通过调度不同任务之间的执行和等待时间,减少处理器的闲置时间来达到减少整个程序的执行时间。
- 与多线程和多进程处理方式的区别
异步处理是在同一个线程之内的任务调度,无法利用多核CPU优势
python异步框架
- asyncio模块
import asyncio
# asyncio模块三个重要概念
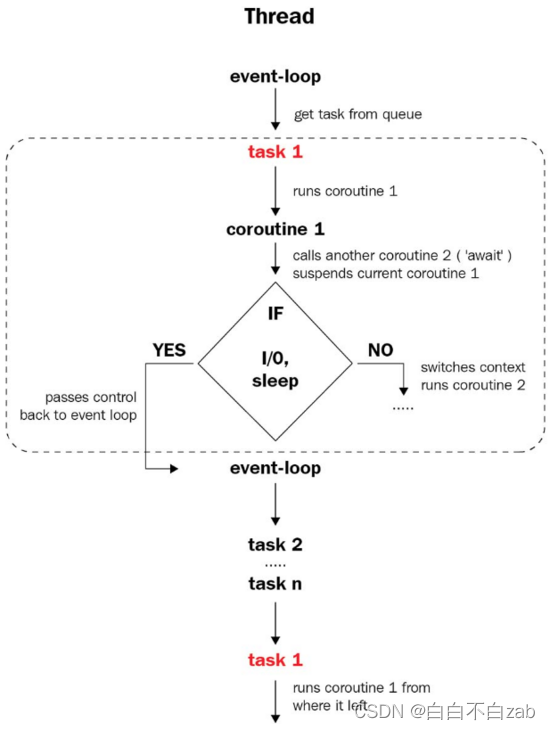
event loops
# 主要负责跟踪和调度所有异步任务,编排具体的某个时间点执行的任务;
coroutines
# 对具体执行任务的封装,是一个可以在执行中暂停并切换到event loops执行流程的特殊类型的函数;其一般还需要创建task才能被event loops调度;
futures
# 负责承载coroutines的执行结果,其随着任务在event loops中的初始化而创建,并随着任务的执行来记录任务的执行状态;
asyncio执行过程
1、首先事件循环启动之后,会从任务队列获取第一个要执行的coroutine,并随之创建对应task和future;
2、随着task的执行,当遇到coroutine内部需要切换任务的地方,task的执行就会暂停并释放执行线程给event loop,event loop接着会获取下一个待执行的coroutine,并进行相关的初始化之后,执行这个task;
3、随着event loop执行完队列中的最后一个coroutine才会切换到第一个coroutine;
4、task的执行结束,event loops会将task清除出队列,对应的执行结果会同步到future中,这个过程会持续到所有的task执行结束;
异步使用
async、await
- async使用在函数的def关键字前边,标记这是一个coroutine函数;
- await用在conroutine里边,用于标记需要暂停释放执行流程给event loops;
- await 后边的表达式需要返回waitable的对象,例如conroutine、task、future等;
- asyncio模块主要提供了操作event loop的方式;
- 我们可以通过async将count_down标记为coroutine,然后使用await和asyncio.sleep来实现异步的暂停,从而将控制权交给event loop;
async def count_down(name, delay, start):
indents = (ord(name) - ord('A')) * '\t'
n = 3
while n:
await asyncio.sleep(delay)
duration = time.perf_counter() - start
print('-' * 40)
print(f'{duration:.4f} \t{indents}{name} = {n}')
n -= 1
# 定义一个异步的main方法,主要完成task的创建和等待任务执行结束
async def main():
start = time.perf_counter()
tasks = [asyncio.create_task(count_down(name,delay,start)) for name, delay in [('A', 1),('B', 0.8),('C', 0.5)]]
await asyncio.wait(tasks)
print('-' * 40)
print('Done')
python中的concurent.futures提供了ThreadPoolExecutor和ProcessPoolExecutor,可以直接在异步编程中使用,从而可以在单独的线程或者进程执行任务
import time
import asyncio
from concurrent.futures import ThreadPoolExecutor
def count_down(name, delay, start):
indents = (ord(name) - ord('A')) * '\t'
n = 3
while n:
time.sleep(delay)
duration = time.perf_counter() - start
print('-'*40)
print(f'{duration:.4f} \t{indents}{name} = {n}')
n -=1
async def main():
start = time.perf_counter()
loop = asyncio.get_running_loop()
executor = ThreadPoolExecutor(max_workers=3)
fs = [
loop.run_in_executor(executor, count_down, *args) for args in [('A', 1, start), ('B', 0.8, start), ('C', 0.5, start)]
]
await asyncio.wait(fs)
print('-'*40)
print('Done.')
asyncio.run(main())
# ----------------------------------------
# 0.5087 C = 3
# ----------------------------------------
# 0.8196 B = 3
# ----------------------------------------
# 1.0073 A = 3
# ----------------------------------------
# 1.0234 C = 2
# ----------------------------------------
# 1.5350 C = 1
# ----------------------------------------
# 1.6303 B = 2
# ----------------------------------------
# 2.0193 A = 2
# ----------------------------------------
# 2.4406 B = 1
# ----------------------------------------
# 3.0210 A = 1
# ----------------------------------------
# Done.
五、进程、线程、协程同时应用
"""10000个请求,开启2个进程,进程中开启3个线程,线程中开启5个协程来处理
"""
import requests, time
from multiprocessing import Queue, Process
import threading
import gevent
def process_work(q, p_name):
"""
创建3个线程
:param q: 队列
:param pname: 进程名
:return:
"""
thread_list = []
for i in range(3):
t_name = "{}--t--{}".format(p_name, i)
t = threading.Thread(target=thread_work, args=(q, t_name))
print('创建线程---{}'.format(t_name))
t.start()
thread_list.append(t)
for thread in thread_list:
thread.join()
def thread_work(q, t_name):
"""
创建5个协程
:param q: 队列名
:param tname: 线程名
:return:
"""
g_list = []
for i in range(5):
g_name = "{}--g--{}".format(t_name, i) # 协程名
print("创建协程----{}".format(g_name))
g = gevent.spawn(gevent_work, q, g_name)
g_list.append(g)
gevent.joinall(g_list)
def gevent_work(q, g_name):
"""
协程做的事:处理任务
:param q: 队列
:param gname: 协程名
:return:
"""
count = 0
while not q.empty():
url = q.get(timeout=0.01)
requests.get(url=url)
gevent.sleep(0.01)
count += 1
print("----协程{}执行了{}个任务".format(g_name, count))
def count_time(old_func):
"""函数计时装饰器"""
def wrapper(*args, **kwargs):
print('开始执行')
st = time.time()
old_func(*args, **kwargs)
et = time.time()
print('结束执行')
print('执行耗时:{}'.format(et - st))
return wrapper
@count_time
def main():
"""
main函数创建2个进程,控制程序的运行
:return:
"""
q = Queue()
# 创建10000个任务在队中
for i in range(10000):
q.put("http://www.baidu.com")
print("11111")
process_list = []
# 将创建的进程都加入进程列表,并启动
for i in range(2):
p_name = 'p--{}'.format(i)
print('创建进程-{}'.format(p_name))
pro = Process(target=process_work, args=(q, p_name)) # 进程不共享全局变量,所有q做参数传进去
process_list.append(pro)
pro.start()
# 主进程等待所有子进程
for pro in process_list:
pro.join()
if __name__ == '__main__':
main()
















 79
79











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









