







一、真值与机器数
主要讨论数值型数据在计算机内部的机器级表示。计算机内部处理的所有数据都必须经过数字化编码,转换为二进制形式的编码表示。
真值是指数据在现实世界的表示,机器数是指数据在计算机内部的二进制编码表示。
1.整数在计算机内部的编码

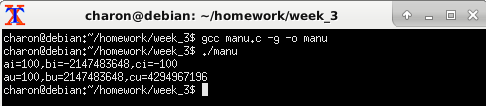
为什么带符号整数bi的输出结果是负数呢?一个无符号整数变量cu,赋值一个负的数据后,输出结果为什么是这个值呢?cu在计算机中实际存储的内容是什么呢?
使用objdump命令反汇编该程序,打开txt并找到main函数所在位置
objdump -S manu > manu.txt

在这段代码中ai、bi、ci都是非静态局部变量,执行程序时被存放在栈帧中。这里的三个数据,100,-100,可以看做是这个程序的常数,把常数赋值给整型变量并且放在栈帧中时,编译程序就把这些常数直接编码在了机器指令中,
左边红框中的数据分别对应100,2147483648和-100,右边红框中的数据为汇编指令的数据。
编译程序是如何对这些常数进行编码的呢?

从真值的角度看,一个数据可以是十进制、二进制、十六进制,对100这个常数来说,它在计算机内部的编码就是采用了它的二进制编码。因为是int类型,所以这里用了32位数据,即4个字节。第二个数也是整数,所以机器数仍然采用了它的二进制编码。对于第三个负数,计算机对其编码采用的是补码的表示方法。
编译时已经将常数直接编码在指令中,执行指令时,就把这些数据直接复制给这些变量。
gdb manu #进入gdb调试
break main #设置断点
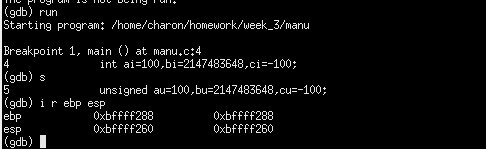
按c语句执行命令,查看当前栈帧的ebp值和esp值
使用eip查看当前断点

可以看到当前断点在11e0这个位置,即上面两条c语句已经执行过了,现在可以查看这些变量在存储器中保存的内容。前面提到过这些变量是非静态局部变量,所以他们被保存在栈帧中,栈帧的地址即上面ebp的值-esp的值。
显示栈帧的内容使用显示存储内容的命令x,显示的范围为ebp-esp+4的值,即88-60=28H=40D,40+4=44,由于这些变量是int型,占4个字节,所以适合使用按4个字节的存储单位显示,所以把44 / 4 = 11按十六进制显示,每个存储单元显示4个字节,显示的起始地址就是esp指向的存储空间。
x/11xw $esp

ebp—>esp指向的范围是260到280,这里刚好是260开始,而右边的红框就显示了当前栈帧288的内容。程序中的变量存储的地址是多少呢?

由图可知,ai的地址是-0xc(%ebp)=0xbffff288-0xc=0xbffff276,所以ai的地址末两位是76。所以ai、bi、ci存储在机器内部的机器数分别如图所示:

同样,au、bu、cu的机器数如图所示:

为什么bi会输出负数呢?
因为bi为int型数据,它的机器数是十六进制的0x80000000,程序中要求将bi输出为带符号整数时,处理程序将机器数当做补码转换为真值,由于最高符号位为1,所以转换后的真值为-2147483648。
cu为一个无符号整数,它的机器数是十六进制的0xfffff9c,程序中要求将cu输出为无符号整数时,处理程序将机器数中的每一位都当作数值位来转换,所以cu为4294967196。
这里的ai和ci从真值上看只差了一个符号位,但其在计算机内部的机器数差异巨大,ai的机器数是0x00000064,ci的机器数是0xfffff9c,这是因为补码对正数和负数的编码值的差异。

对于无符号数au和cu,从c语言的角度讲,一个赋值100,一个赋值-100,100是将64000000赋值给au,所以au的机器数是0x00000064,而cu是-100的编码(补码),即9cffffff,所以cu的机器数是0xffffff9c,所以au输出的真值是100,而cu输出的真值是那个编码的二进制值。
编译程序根据c语言程序中的数据类型,把c语句转换成了不同的机器指令。对带符号整数采用补码的编码方式,它有符号位和数值位的含义;对无符号整数采用二进制的直接编码表示,没有符号的概念,编码中的每一位都是数值位。
2.浮点数在计算机内部的编码


可以看到,系统对int和float类型数据处理后的语句是不一样的。
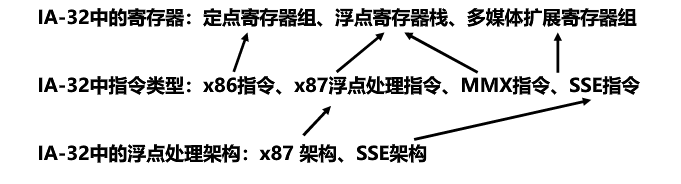
IA-32中对定点整数处理采用的是x86指令,使用的是定点寄存器组,IA-32中的浮点处理器架构有x87和SSE架构,x87架构采用的是x87浮点处理指令,使用的是浮点寄存器栈,SSE架构采用的是SSE指令,使用的是多媒体扩展寄存器组。
本次实验采用的计算机对float类型数据的处理方式:x87浮点处理指令,使用的是浮点寄存器栈。
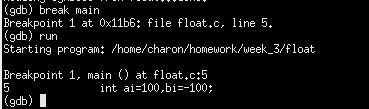
使用gdb调试,设置断点,运行程序

查看当前运行到的位置,11b6H
继续执行
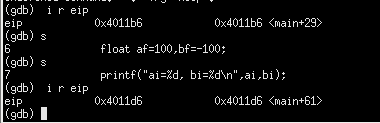
可以看到当前运行到的程序断点为11d6H。
ai、bi、af、bf在机器内存储的机器数是什么呢?
由于他们都是非静态局部变量,所以在当前栈帧中就可以找到这些变量的机器数了。

先查看当前栈帧指针的值,288-270=18H=24D,24+4=28,所以当前栈帧的字节数是28。

由于int型和float型都是4字节大小,所以用x/7xw $esp显示当前栈帧的内容。
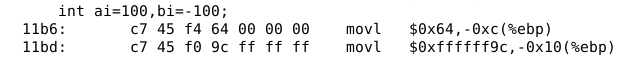
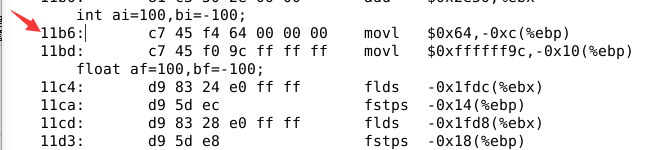
这是ai的赋值语句,100的整数编码被直接编译在指令中,即十六进制的64,对应的机器级指令是mov指令,将64H存入到ai的单元,也就是0x00000064。同理将-100编译到指令中,将-100的编码值传递给bi,也就是0xffffff9c,即bi的机器数。

af是浮点数据类型,上面两条浮点指令对应了af的赋值语句。第一条是取数指令:将存在-0x1fdc(%ebc)地址单元的100编码值传送到浮点寄存器栈。第二条是存数指令:将浮点寄存器栈中的数据送到-0x14(%ebp)地址单元,即af。同理bf的赋值语句也对应着两条机器指令。

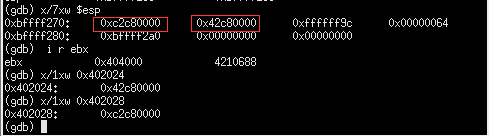
-0x1fdc(%ebx)=0x404000-0x1fdc=0x402024
-0x1fd8(%ebx)=0x404000-0x1fd8=0x402028

编译程序将100保存在了所图所示的地址单元,赋值语句将0x42c80000(100的编码)送到了af所在的地址,即-0x14(%ebp)。af的机器数是0x428000
同理,同理bf=-100这条赋值语句将-100的编码(0xc2c80000)通过浮点寄存器栈送到了-0x18(%ebp),也就是0xc2c80000。
ai、bi、af、bf对应的编码分别是:0x00000064、0xffffff9c、0x42c80000、0xc280000。
可以看到ai和af的数据类型不一样,对应其在计算机中的编码也不一样,int采用的是补码的编码。float采用的是浮点数的编码。
ai和bi的值互为int型的相反数,他们的机器数的01序列满足“按位取反、末位加1”的特点,这是由补码的编码规则决定的
af和bf的真值互为浮点类型的相反数,他们的机器数的01序列中,正数的符号位为0,负数的符号位为1,阶码和尾数部分一样。

对于C语言来说,数值数据的类型主要是带符号整数,无符号整数和浮点数,其对应的机器级编码是不一样的。int类型有一位符号位和若干数值位,unsigned类型在编码中没有符号位,所以所有的01序列都是表示的数值位,float类型数据是32位编码,采用了一位符号位,8位阶码和23位尾数的格式。
机器数其实就是01序列的编码,根据C语言程序中的数据类型,把不同数据类型的语句转化为不同的指令,指令执行过程中,按照一定的编码方式去处理这些机器数。
二、数据存储的宽度与排列方式

1.a、b、c三个变量的真值都是100,但都属于不同的数据类型,它们在存储器中是否占用相同的存储空间呢?
2.一个变量有多个字节时,多个字节在存储器中是按什么顺序排列存放的?
3.变量a、b、c是否可以存放在存储器中任意开始的地址?
即本小节的三个问题:

1.数据存储的宽度

设置断点,启动程序运行,执行三条s命令
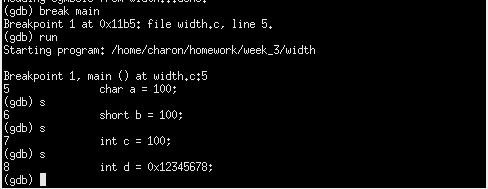
显示当前esp和ebp的内容,进一步查看当前栈帧的内容
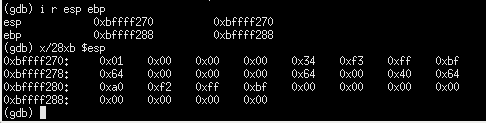
-0x9(%ebp)=0xbffff288-0x9=0xbffff27f
-0xc(%ebp)=0xbffff288-oxc=0xbffff27c
-0x10(%ebp)=0xbffff288-0x10=0xbffff278

27f和27c相差3个字节,27c和278相差4个字节,所以a占了1个字节,b占了2个字节,c占了4个字节。所以0x64是变量a的机器数,0x64和0x00是变量b的机器数,第一个红框中的四个字节是变量c的机器数。其中0x40是无意义数据。
虽然变量a、b、c的真值都是100,但因数据类型的不同而占用了不同字节数的存储单元。
通常情况下,不同数据类型占用的存储宽度不一样。

变量b占用2个字节,应该是0x0064,c占用4个字节,应该是0x00000064,但为什么控制台不是这样显示的呢?
这就涉及到了数据存储的排列方式。
2.数据存储的排列方式
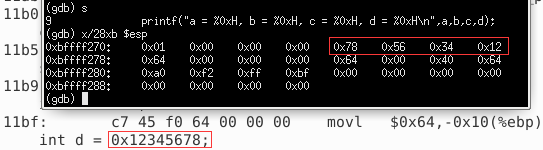
继续执行c语句,查看当前栈帧内容,可以看到这是变量d的机器数,d的值是16进制的12345678,而控制台中看到的是78563412。
计算机是按字节编址,每个地址单元只存储一个字节的宽度,当一个数据有多个字节时,就要占用多个连续的存储单元。

例如变量d有4个字节,它就要存放在连续的4个地址单元中,一个数据的4个字节按什么顺序排列存放呢?
有两种存放方式,一种称为大段方式,一种称为小端方式。在大端方式中,最高有效字节12H,它要存放在连续的4个地址的低地址单元中,所以把这4个字节按照12345678的方式存放。小端方式同理。
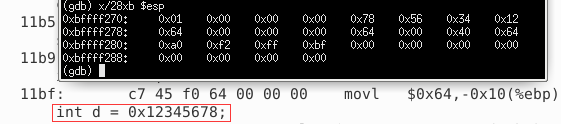
从上图可以看到该计算机采用的是小端方式。这条语句将一个常数赋值给了一个整型变量d,由于d是非静态局部变量,所以就把这个常数编码在机器指令中。这条指令的低4个字节对应着常数十六进制的12 34 56 78。指令中数据的多个字节也存在着排列顺序问题,即大端和小端方式,这里采用的是小端方式,所以指令的低4字节为78H 56H 34H 12H。
如果将该语句赋值的初始值更改为十六进制的0x22334455,编译后的指令会有什么变化呢?

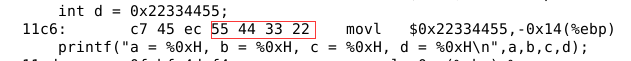
反汇编后可以看到,在这条指令中后4个字节就是d的初始值,以小端方式存放。
3.数据存储的对齐方式

这些变量在存储器中分配存储单元时,会不会分配在连续的地址单元?

反汇编调试程序,设置断点
显示当前esp和ebp寄存器的内容

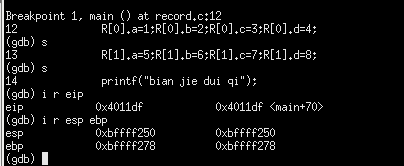
R[0].a: -0x20(%ebp)=0xbffff278-0x20=0xbffff258
R[0].b: -0x1c(%ebp)=0xbffff278-0x1c=0xbffff25c
R[0].c: -0x18(%ebp)=0xbffff278-0x18=0xbffff260
R[0].d: -0x16(%ebp)=0xbffff278-0x16=0xbffff262
查看当前栈帧内容,第一个红框中是R[0].a,第二个红框中是R[0].b,可以看到b并没有挨着R[0].a后面存放,中间空着三个字节。
对于底层机器级代码来说,数据放在任意地址的存储单元,计算机都能正确存储数据,那存储单元中数据间为什么不连续存放,要空着一些单元呢?
在IA-32中,存储机制限制每次访存最多只能读写64位,即8个字节。存储器按字节编址,地址末尾为0到7的地址单元可以同时读写,地址末尾为8到15的8个地址单元可以同时读写,如果把数据存放在地址末位为5678的4个地址单元中,则读写该数据需要访问储存器2次,即涉及到了第一排的末三位和第二排的首位。也就是说,如果把R[0].b挨着R[0].a后面存放,则R[0].b的数据访问有可能花费两个存储周期的时间。如果把R[0].b与R[0].a之间空着三个字节,则读写R[0].b可能就只需要1个存储周期,正如上图所示。
这就是空间与时间的代价问题,编译器通常按照对齐方式给数据分配存储空间、转换代码。linux中采用的基本数据存储对齐策略是:
char型数据只有一个字节,可以放在任意地址单元,short型数据有2个字节,放在地址是2的倍数上,int型数据有4个字节,放在地址是4的倍数上。
R[1].a: -0x14(%ebp)=0xbffff278-0x14=0xbffff264
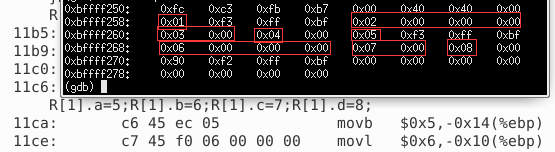
所以上图中空的字节数实际上是按照对齐策略分配存储单元的。R[1].a是个char型数据,按照char型数据对齐的原则,它可以放在任意地址单元,但并没有挨着R[0].d存放,而是放在地址为4的倍数上,这是为什么呢?
数组R的每一个元素都是一个结构体,编译器给结构体数据分配存储空间时,遵循地址是4的倍数的对齐原则。

这个图示意了在对齐方式下,数组R中每个数据的存储情况。在不考虑对齐的方式下, R的每个数组元素占用的存储空间为(1+4+2+1)× 2 = 16(字节)。

在对齐方式下,每个数组元素占用的存储空间为(1+3+4+2+1+1)×2 = 24(字节)。
相对于不对齐方式,每个数组元素多占用4个字节。数据的对齐方式增加了存储空间,减少了数据读取时间。如何对这个结构体的定义优化呢?
a是结构体的首个char成员变量,放在地址是4的倍数上,d是char型变量可以挨着a存放,c是short型变量可以挨着d存放,其地址正好是2的倍数,b是int型变量可以挨着c存放,地址正好是4的倍数,也避免了存储空间的浪费。现在每个数组元素只占用(1+1+2+4)= 8个字节,数组R只需占用16个字符。
对于机器级代码来说,是否数据对齐,访问存储器数据的功能都能正确实现,只是在对齐方式下程序的执行效率更高。

三、整数之间的数据类型转换

1.整数之间的数据类型转换

si是16位的带符号整数,usi是16位的无符号整数,i是32位带符号整数。
计算机中的数据都是以机器数的形式存在,所以c语言中整数的赋值不是发生在真值上的复制,而是在机器数上的赋值。

以赋值语句b=a为例,有如下三种情况:
情况一:相同宽度的两个整型数据之间的赋值。例如将一个n位的整数a赋值给另一个n位的整数b,赋值发生在机器数上,所以这种情况下a和b的机器数相同,但真值不一定相同,取决于a和b的数据类型。
情况二:将一个短的数据类型赋值给一个长的数据类型。例如将一个n位的整数a赋值给另一个m位的数据b,这里n<m,这时候把a的n位01序列复制在b的低n位上,而b的高m-n位由a的数据类型决定。如果a的数据类型是无符号整数,不管b是什么数据类型都需要采用零扩展策略,即将b的高m-n位置为0;如果a的数据类型是带符号整数,不管b是什么数据类型都采用符号扩展策略,即将b的高m-n位置为a的符号位。
情况三:将一个长的数据类型赋值给一个短的数据类型。例如将一个n位的整数a赋值给另一个m位的整数b,这里n大于m,此时采用截断的策略,即将a的低m位的01序列赋值给b,丢弃a的高位部分。
显示当前esp、ebp寄存器的内容,并显示当前栈帧内容。

si:-0xa(%ebp) = 0xbffff288 - 0xa = 638D = 0xbffff27e
-100的16位补码是十六进制的ff9c,这里采用小端方式表示。所以红框中为si的机器数。
当把ui赋值给usi时,si和usi都是16位的整数,所以赋值时是把si的机器数完整地复制给usi,所以红框中前两个字节就是usi的机器数。si和usi的机器数相同,但由于数据类型的不同,所以si和usi的真值不一样,可以看到si的真值是-100,usi的真值是65436。

输出si时,把0xff9c当做补码的编码,输出usi时,把0xff9c当做二进制值编码。

当把usi赋值给带符号整数 i 和无符号整数ui时,usi是16位的无符号整数,i 和ui都是32位,所以赋值时需要进行零扩展。可以看到这里的指令都是零扩展的传送指令,编译是根据源操作数的类型来确定使用的指令,278H是i的机器数,275H是ui的机器数。i 和ui的机器数是一样的,它们的低16位都是usi的01序列,高16位都是0。

当把si赋值给带符号整数i1和无符号整数ui1时,si是16位带符号整数,i1和ui1都是32位,所以赋值时需要进行符号扩展,可以看到这里的指令编译转换后都是符号扩展的传送指令。270H是i1的机器数,26c是ui1的机器数。i1和ui1的机器数是一样的,它们的低16位都是si的01序列,高16位都是si的符号位。

当把i2赋值为十六进制的12348765,把i2赋值给带符号整数si2和无符号整数usi2时,i2是32位带符号整数,si2和usi2是16位整数,所以赋值时需要进行截断操作。可以看到这里的指令编译转换后都是一样的。267H是si2的机器数,265H是usi2的机器数,si2和usi2的机器数是一样的,都是i2的低16位,i2的高16位被丢弃。
由于数据类型的宽度不同,在机器数上赋值的过程中,有可能出现扩展和截断的操作,所以计算机上的赋值运算不同于数学上的等于操作。

比如这里的将i2赋值给si2,si2赋值给i3,i2和i3的机器数就不一样。原因是i2赋值给si2的时候做了截断操作,失去了i2中的高16位,si2赋值给i3的时候又做了符号扩展,扩展出来的16位是si2的符号位0,所以i2的高16位和i3的高16位不一样。

这里是将一个常数赋值给一个32位带符号整数,但这个常数超过了32位带符号整数的表示范围,编译时对该常数做了截断操作。
2.整数和浮点数之间的转换
整数与浮点数之间转换的时候,是在编码格式上的转换。对带符号整数来说采用的是补码的编码方法,

比如int类型有32位编码,其中一位是符号位,另外31位是数值位。浮点数采用IEEE754标准,有两种基本格式:float和double。float格式采用32位编码,其中1位符号位8位阶码,23位尾数。

反汇编后进入调试模式
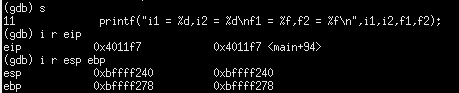
i1: -0xc(%ebp) = 0xbffff278 - 0xc = 620D = 0xbffff26c
ftemp: -0x14(%ebp) = 0xbffff278 - 0x14 = 612D = 0xbffff264

26cH是i1的机器数,264H是ftemp的机器数,260H是i2的机器数。显然i1和i2的机器数不同。

从输出结果可以看出i1和i2的真值差异很大,这是为什么呢?

在整数和浮点数之间转换的时候,要进行数据编码格式上的转换,而不是机器数上的直接复制。i1的机器数0x7fffffff为了转换成float类型的浮点数,需要把i1写成尾数和阶码的格式。尾数的有效数字有31位,而float格式的浮点数的有效数字只有24位,所以需要对尾数进行舍入操作,这里黄色部分就是需要进行舍入的位。根据IEEE754的舍入原则,这里执行入的操作,所以在有效数字的最低位+1,尾数就变成了10B,因此最后的阶码为31,
因此i1转换为float格式时,符号位为0,阶码为31+127,尾数为23个0。要把这个浮点数赋值给i2,又要进行浮点格式和补码的转换。i2的机器数和i1的机器数不一样,原因就是在i1转化为浮点数时做过+1的近似处理。从机器数的编码上看,i2的编码比i1的编码大1,但是将i2的机器数还原为真值后,i2的真值是一个负数,与i1的真值差异就大了。
f1:-0x19(%ebp) = 0xbffff278 - 0x10 = 616D = 0xbffff268
itemp:-0x1c(%ebp) = 0xbffff278 - 0x1c = 604D = 0xbffff25c
f2: -0x20(%ebp) = 0xbffff278 - 0x20 = 602D = 0xbffff25a

25a为f2的机器数,25c为itemp的机器数,268为f1的机器数,显然f1和f2的机器数也不一样。为什么f1的机器数是十六进制的51187654H呢?

初始值是十六进制的987654321H,用二进制编码有36个二进制位,超过了浮点的24位精度,所以需要进行舍操作,f1的浮点数的编码是:符号位为0,阶码为35+127,尾数是23位二进制,所以0x51187654就是f1的机器数。
f1转换为int型itemp时需要做编码格式上的转换,f1的机器数对初始数据做过舍操作,相对于初始值,f1的二进制依旧有36位,但是其低12位全为0。int型数据只有32位,f1有36位二进制,所以超过了int型数据的表示范围。
f1转换为int型数据后,它的机器数是多少呢?itemp的机器数最高位为1,后面有31个0,将其赋值给f2时,又要进行编码格式上的转换,将这个补码转换为真值。由于符号位为1,所以itemp是一个负数,数值为采取按位取反,末位加一的策略,真值用尾数和阶码的形式表达为-1.0×2的31次方。
f2的float编码就是符号位为1,阶码为31+127,尾数为23个0。所以f2的机器数是十六进制的0xcf000000H。
f1和f2的机器数不一样,根本原因在于f1超过了int型数据的表示范围,转换为int型数据时,系统赋值为最高位为1,其余位为0这样一个机器数。

由于编译优化,执行i2=(int)(float)i1,i1和i2的值可能会相等。
3.C语言中的自动类型转换


这两条指令用于实现 i<=n-1 的比较,执行cmp比较指令时,edx和eax寄存器中分别存放着n-1和i的内容。jae是一条无符号整数比较的转移指令,这两条指令执行的作用就是按无符号整数判断,如果edx的内容大于等于eax的内容,则转移到11c0的指令处执行,否则继续执行下一条指令。也就是n-1和 i 按无符号整数比较,如果n-1大于等于 i 就执行循环体,否则退出循环体。
i是带符号整数,n是无符号整数,带符号整数和无符号整数比较时,系统采用的是无符号整数的比较指令,也就是 i 被自动转换为无符号整数后与n-1比较。当n为0时,n-1的内容是多少?
调试执行程序,多次运行si命令,显示edx和eax寄存器的内容

n-1的内容是十六进制的8个f,它是32位无符号整数的最大值,0x0是eax寄存器的内容,也就是 i 的内容,其在程序执行过程中从0开始逐渐加1,但无论 i 的值 是多少,n-1大于等于 i 永远成立。

因此这条转移指令永远转移到11c0的指令处执行,不会退出循环体,程序从而陷入了死循环。
如何修改这个程序呢?不能让系统采用无符号整数比较的转移指令,而要采用带符号整数比较的转移指令,所以n必须设置为带符号整数。
修改n的定义为带符号整数,反汇编并调试程序。
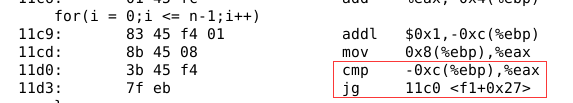
这里采用了带符号整数的转移指令,将n-1的内容保存在了eax寄存器中,-0xc(%ebp)保存的是 i 的内容。

显示当前eax寄存器的内容,当n为0时,n-1的内容依旧是十六进制的8个f,对带符号的整数来说这是负数-1,i 为0时,显然 i 小于等于n-1不成立,所以推出循环体,得到sum的值为1。
这个案例告诉我们程序中少用无符号整数,在带符号整数和无符号整数一起运算的时候,系统会自动类型转换为无符号整数处理,并且无符号整数0-1时得到了能表示无符号整数的最大值0xffffffff。
















 289
289











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









