







# 卷积可微分逻辑门网络
Convolutional Differentiable Logic Gate Networks
前言:
今天这篇难度很低啊,简单来说就是使用logic gate 去模拟神经网络的matrix calculation的行为。这样的话我认为是提高了可解释性,当然泛化能力应该是下降的。好处是降低了神经网络的大小,你只需要储存几个特定的计算逻辑门就行了。对比PFSA的话,它是可训练的,所以保留了我觉得神经网络最棒的东西,就是可训练性。PFSA更精简,更有数学之美,但是手写方程然后去手工微调,真是艰难啊。
不过大家建议看论文不要误入歧途,很多方法,但是推荐你还是多了解再深入研究,不然有时候感觉未来会很辛苦。
论文出处:
NeurIPS 2024, 所以预期是篇好论文。https://arxiv.org/pdf/2411.04732
作者之前还有一篇https://proceedings.neurips.cc/paper_files/paper/2022/file/0d3496dd0cec77a999c98d35003203ca-Paper-Conference.pdf
背景
逻辑门网络:逻辑门网络是指使用AND, NAND, or XOR.之类的binary 逻辑门来表示网络,通过调整逻辑门的选择与节点间的连接方式,从而将原本梯度下降的训练问题转化成了一系列的门的组合问题。
但是对于机器学习的问题时,通常使用的组合方法解决问题变得不可行了,因为神经网络通常需要数百万甚至更多的参数来构成数据的计算,因此他们团队之前提出了一种可微分的松弛方法,使得使用梯度下降方法可以在逻辑门网络上使用。、
结构:
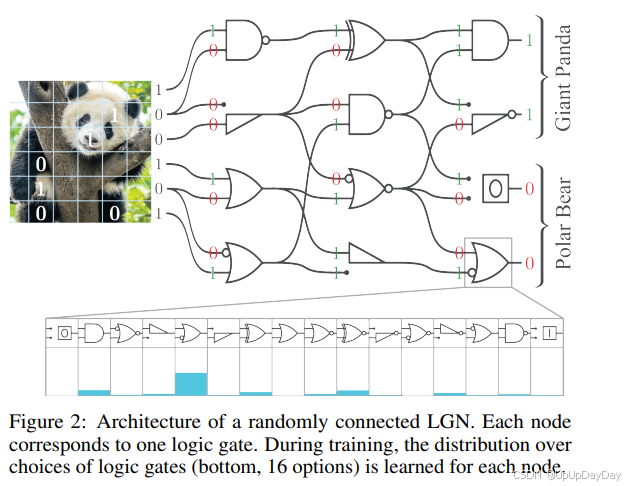
包含了一个逻辑门,这张图可以看到是3层,每层有4个逻辑门。由于逻辑门的本质上是非线性的,因此整个过程不需要任何激活函数(有趣吧)。此外,因为不依赖矩阵计算,它也没有任何的weight或者bais(感觉在拟合上的效率会下降,或者最少降低了全局最优点的上限). 可以看到逻辑门有一个缺陷,他只有两个输出和输入,因此无法做到全连接,这样的结构可能在训练中带来缺陷。
可微分松弛
事实上目前的网络尽管看着提供了一个选择的概率,但是网络仍然是不可以微分的:1.逻辑门对bool输入的计算是离散函数(input和output都是只有0/1),因此是不可微分的;2.逻辑门本身是离散的,它是一个非线性计算嘛,因此也是不可微分的。目前已经有一些研究提出了使用概率逻辑来将逻辑门进行可微分松弛,指的就是他们团队之前自己写的另外一篇2022的neuraIPS。比如,将一个逻辑 (a1^a2)松弛为a1 ⋅ \cdot ⋅ a2,这样的花对于两个独立的伯努利变量(a1,a2)的输出概率,就可以视作一个概率分布,因此就可以使用softmax来进行编码了。
此外,这个可训练参数向量 z ∈ R 1 6 z ∈ R^16 z∈R
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









