







聊聊阻塞与非阻塞、同步和异步
在讲IO模型之前,我们先来聊聊什么是阻塞和非阻塞,同步和异步。
因为我发现这两个概念非常容易混起来,好像阻塞就是同步,非阻塞就是异步。
但是请注意:
我们说的同步和异步描述的是顺序关系,而阻塞和非阻塞描述的是一种是否等待的行为,不能划上等于号
举个例子:
我们去食堂吃饭的时候,经常会有两种,一种是需要自己排队打饭,另一种是商家叫号拿饭的。
这里面包含两个步骤:
- 等待:排队买饭/等待叫号
- 获取信息:排队轮到你了/叫到你了
在这个例子中,你是代表一个线程,而商家是属于另一个线程。
阻塞和非阻塞之间的区别是,你是否等待了,在这个期间能做其他事情,是基于同一个线程中的。对于阻塞,就是自己等饭期间,只能去排队,不能做其他事情;而非阻塞,就是在这个期间,能去干别的事情,如买汽水。
同步和异步的区别在于,发起获取消息的过程是否是你这个线程发起的,是基于多线程的。对于同步,多线程之间是有联系的,就是自己主动去找商家,知道自己的饭好了;而异步,就是多线程之间自己运行自己的,对映到例子中,我点了菜之后,我就不管了,商家会叫号,通知你,你的饭好了。
所以我们组合一下:
同步阻塞:就是排队买饭,等这轮到自己。
同步非阻塞:不用排队买饭,但是商家没有叫号的操作,可以去买可乐,然后要时不时的自己去问商家好了没有。
异步非阻塞:不用排队买饭,商家有叫号操作,在此期间,我不用管饭是否好了,我可以去买可乐,等叫到我了,再处理;对应的在程序中,就是有一个回调函数。
IO模型
在之前零拷贝的讲述中,我们知道了,用户空间需要从硬件中获取数据时,是先调用的系统调用接口,通过系统调用调内核函数,从硬件中获取数据,内核IO将数据写入内核空间后,CPU再将内核空间中的数据拷贝到用户空间中去。
整个过程大概是两个步骤:
- 获取硬件中的数据到内核态中
- 将内核态的数据拷贝到用户态
实验
我们先来看个实验:
public class BioServer {
private static final int CORE_POOL_SIZE = 5;
private static final int MAX_POOL_SIZE = 10;
private static final int QUEUE_CAPACITY = 100;
private static final long KEEP_ALIVE_TIME = 1L;
public static void main(String[] args) throws IOException {
//创建一个线程池,如果有客户端来连接,就创建一个线程,与之通信
ThreadPoolExecutor executor = new ThreadPoolExecutor(CORE_POOL_SIZE,
MAX_POOL_SIZE,
KEEP_ALIVE_TIME,
TimeUnit.SECONDS,
new ArrayBlockingQueue<Runnable>(QUEUE_CAPACITY),
new ThreadPoolExecutor.CallerRunsPolicy());
//创建ServerSocket
ServerSocket serverSocket = new ServerSocket(666);
System.out.println("服务启动了...");
while(true){
//监听,等待客户端连接
final Socket socket = serverSocket.accept();
System.out.println("连接到了一个客户端....");
//创建一个线程,与之通信
executor.execute(new Runnable() {
@Override
public void run() {
handle(socket);
}
});
}
}
/**
* 编写一个handle方法,和客户端通信
* @param socket
*/
public static void handle(Socket socket){
try {
System.out.println("当前线程为: " + Thread.currentThread().getName());
byte[] bytes = new byte[1024];
//通过socket,获取输入流
InputStream input = socket.getInputStream();
//循环读取客户端发送的数据
while(true){
int read = input.read(bytes);
if(read != -1){
System.out.println(new String(bytes,0,read));
}else {
break;
}
}
}catch (Exception e){
e.printStackTrace();
}finally {
System.out.println("关闭和client的连接");
try {
socket.close();
}catch (Exception e){
e.printStackTrace();
}
}
}
}
从上面代码中我们可以看到,现在已经先建了一个线程池,当每来一个连接的时候,就会拿一个线程去维护这个连接。
我们来看一下情况,连接两个客户端:
服务启动了...
连接到了一个客户端....
当前线程为: pool-1-thread-1
hhhh
连接到了一个客户端....
当前线程为: pool-1-thread-2
wwwwwww
此时,如果我将核心线程数改成1个会出现什么样的情况呢?
服务启动了...
连接到了一个客户端....
当前线程为: pool-1-thread-1
yyyy
连接到了一个客户端....
会发现,被阻塞了。
如果有成千上万个连接的话,那就意味着有成千上万个线程,这样机器能撑的住吗?
OK,接下来,我们开始今天的内容。
BIO
概述
BIO全称为Blocking IO,同步阻塞IO。
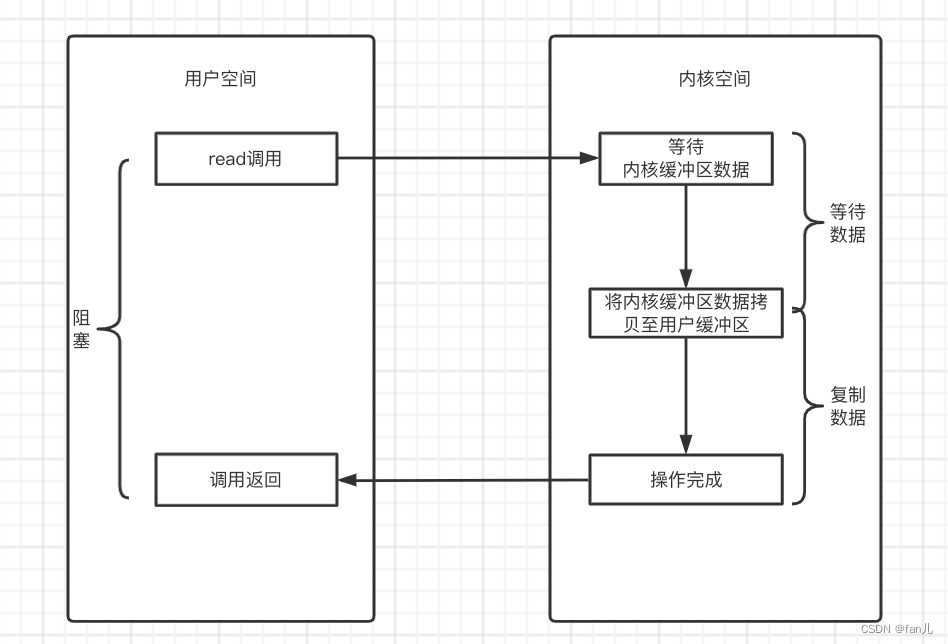
我们来看一下流程,比如说发起一个socket的read()的系统调用:
- 首先是read()系统调用,用户线程等待资源,开始阻塞
- 然后从用户态转换到内核态,调用内核函数,从硬件中读取数据
- 待将数据都读取到内核缓冲区后,将数据拷贝至用户缓冲区
- 内核返回结果(比如返回结果为复制到用户缓冲区的字节数),此时用户线程阻塞被解除,重新运行起来
特点
优点
- 在阻塞数据等待期间,用户线程被挂起,几乎不会占用CPU资源
缺点
- 正常情况下,会为每个连接分配一个线程,每个线程维护一个IO操作;如果并发量大的话,就意味着需要大量地线程来维护网络连接的IO操作,会导致内存、线程切换的消耗很大,性能低。
NIO
概述
NIO全称为Non-Blocking IO ,同步非阻塞IO。
注意:JAVA编程中的NIO不是指的这个NIO,指的是New IO,也就是待会会讲的IO多路复用模型。
在这个模型中,会出现两种情况:
- 第一种是内核缓冲区里面没有数据,此时系统调用会马上返回一个错误码。
- 第二种是内核缓冲区里面有数据了,在将内核缓冲区的数据拷贝到用户缓冲区里面的时候,此时发起系统调用用户线程会被阻塞的,直到这个过程完成。然后系统调用成功返回,用户线程可以处理用户空间的缓冲区的数据。
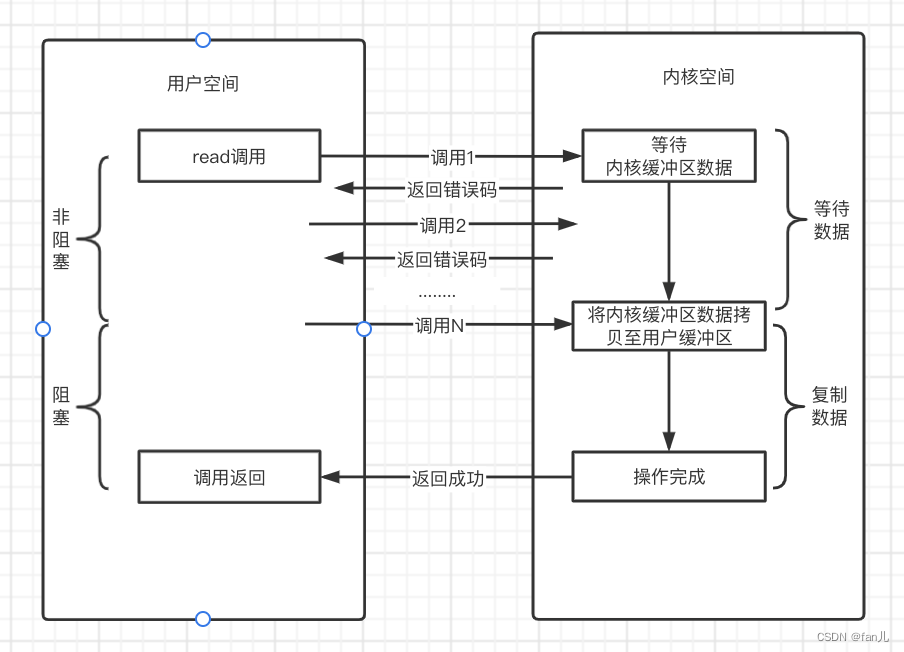
我们来看一下流程:
- 用户线程发起read()系统调用,此时内核缓冲区数据还未准备好,会立即返回EWOULDBLOCK错误码
- 然后用户线程继续发起系统调用,此时内核缓冲区数据依然还未准备好,继续返回EWOULDBLOCK错误码
- 用户线程继续发起系统调用,此时内核缓冲区的数据准备好了,用户线程被阻塞
- 将内核缓冲区的数据拷贝至用户缓冲区,操作完成后,用户线程阻塞被解除
特点
同步非阻塞IO虽然每次发起系统调用的时候都可以马上返回,但是需要不断的进行IO系统调用,会消耗大量的CPU资源,这会导致在并发量高的时候性能低下。但是这个模型有他的参考价值,为其他IO模型的实现打下了基础。
IO多路复用
那么,按照上文所讲,NIO模型会不断地进行IO系统调用,该如何进行优化呢?
我们可以比较容易地想到,等内核缓冲区的数据准备好,通知用户线程不就好了嘛。所以针对上面的NIO模型,又提出了一种以NIO模型为基础的IO多路复用模型。
备注:fd(文件描述符),在Linux中,一切皆文件,所以每个连接就是一个fd。
select
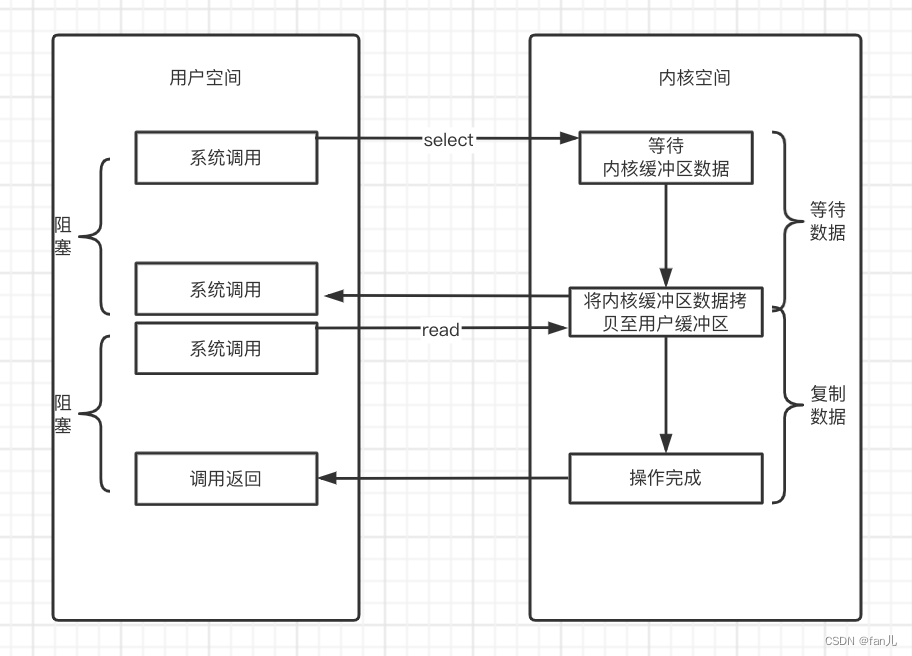
看到下面这个模型的时候,可能会想,这个跟BIO不是几乎一致吗?而且同样都是用户线程阻塞的情况下,还多了一次的系统调用呢。
我们先来看一下它的过程:
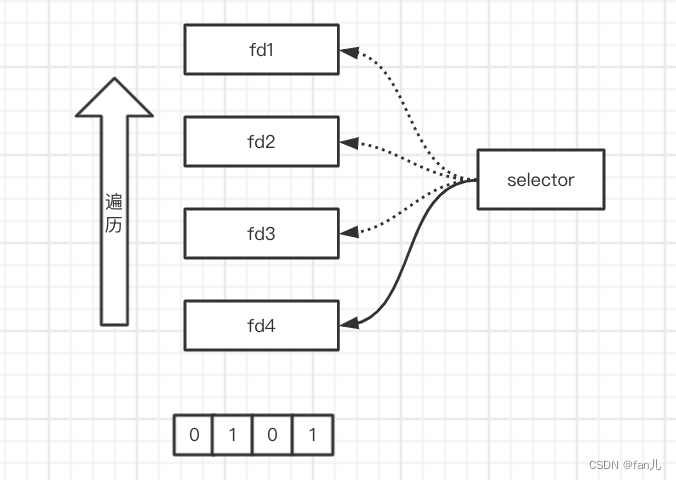
- 首先,已连接的socket放到一个fd集合中
- 使用select系统调用时,需要将这些fd拷贝至内核缓冲区中,然后通过select的查询方法,会去遍历这些fd的IO就绪状态,然后会把这些fd通过一个bitmap(位图)来标记哪些是可读的;如上图中,如果fd2和fd4处于就绪状态了,就会在bitmap中相应的位置置为1
- 用户线程又会去遍历这些bitmap找到其中可读的fd,针对这些fd发起read系统调用,操作完成后进行之后的处理
相比于上面的NIO模型来说,select只需进行一次的系统调用即可获取到哪些fd已经将硬件的数据加载到内核态了。
但是,这种方式的话,不仅需要将数据从用户态拷贝到内核态,相应的待内核态检测完成后,还需要将数据从内核态拷贝到用户套、态,还对这些fd集合进行了两次遍历,时间复杂度O(n);并且还会受到单个进程能打开的fd文件数量的限制,默认数量为1024个。
后来又出现了poll,poll和select的工作原理差不多,同样需要将fd集合从用户态拷贝至内核态,也同样需要去遍历两次fd集合;与select不同的地方在于它的fd的数量不会有限制了,是通过一个双链表来进行存储的。
缺点:
- 进行了两次的fd集合数据拷贝
- 对fd集合进行了两次遍历
epoll

epoll是select和poll的增强。epoll模型主要涉及到了三个系统调用,分别是:
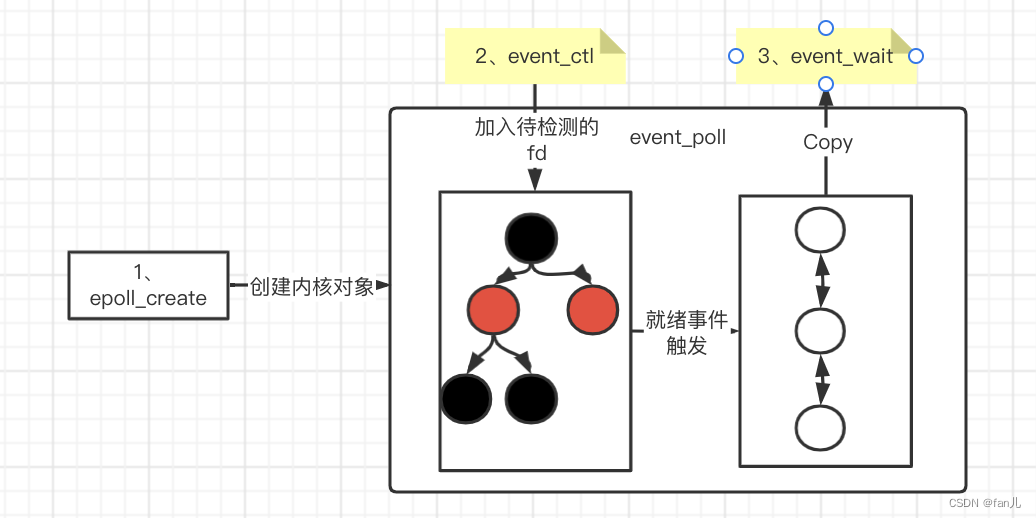
- epoll_create:内核创建一个eventpoll对象,这个对象中,主要维护了两个东西:
- 一个红黑树,在这个红黑树中管理各个fd,即socket连接;用红黑树的原因是红黑树在删除、插入和查找的综合效率比较高。
- 就绪的fd链表,这样通过遍历fd链表,就能知道所有已就绪的fd,而不用去遍历整个树
- epoll_ctl:往红黑树中加入待检测的fd
- epoll_wait:返回IO就绪的fd的个数
过程:
- 首先通过epoll_create系统调用,会创建一个eventpoll对象
- 然后通过event_ctl调用,会创建一个epitem对象,这个对象会放到红黑树中
struct epitem{
struct rb_node rbn;//红黑树节点
struct list_head rdllink;//双向链表节点
struct epoll_filefd ffd; //事件句柄信息
struct eventpoll *ep; //指向其所属的eventpoll对象
struct epoll_event event; //期待发生的事件类型
}
- 当红黑树中的节点有事件发生时,就会将该节点加入到相对应的就绪链表中去
- 当调用epoll_wait的时候,就会去检查就绪的fd链表中是否有epitem对象,如果有就返回个数,并且将该链表从内核态复制到用户态
边缘触发和水平触发
边缘触发和水平触发指的都是epoll_wait()通知用户程序去缓冲区读取数据,但是什么时候读取数据,读取多少两种方式不同。
边缘触发:
边缘触发,关注的是缓冲区的状态的变化。缓冲区只要有新数据来了就会通知去读一次,但是如果一次读不完的话(比如读写缓冲区比较小),就会留在缓冲区,等待下一次触发(即有新数据来)通知用户程序读取。
边缘触发一般搭配非阻塞IO使用,否则如果没有数据可读的时候,就会一直阻塞在读写函数中;使用非阻塞则会在没有数据可读的时候,返回错误码。
水平触发:
水平触发是指,关注的是缓冲区的状态。缓冲区只要处于可读状态,即有数据可读,就会一直触发,通知用户进程读取。
select/poll只有水平触发;epoll默认使用水平触发,可以设置为边缘触发。
优点:
-
无需再将fd集合从用户态拷贝到内核态,只需将要检测的fd节点即可;
-
无需再进行对fd集合进行遍历,只需对epoll_wait系统调用时返回的链表进行遍历即可,并且这些链表里面的节点都是数据已准备好了的fd
AIO
概述
AIO全称为Asynchronous IO ,异步IO。

在AIO模型中,线程发起系统调用后就可以去做其他事情了,剩下的事情全部都交给内核去做,等将内核缓冲区里的数据拷贝到用户缓冲区后,再通知用户线程去处理这些数据。
但是当前JDK对异步IO的支持并不完善,因此异步IO在性能上没有明显的优势;并且AIO的实现是比较复杂的。
总结
本文主要讲解了四种IO模型,BIO、NIO、IO多路复用和AIO。
从BIO入手,讲解IO模型的发展;其中IO多路复用是当前多种高性能中间件的IO模型(如nignx、Redis、netty),著名的reactor模式就是以IO多路复用模型为基础的;而异步IO由于JDK当前对它的支持并不完善导致性能并没有明显的优势,并且编程较为复杂。















 276
276











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









