






线性回归
对于一元线性回归(单变量线性回归)来说,学习算法为 y = ax + b 我们换一种写法: hθ(x) = θ0 + θ1x1
练习1 – 利用Sklearn做线性回归的预测
线性回归实际上要做的事情就是: 选择合适的参数(θ0, θ1),使得hθ(x)方程,很好的拟合训练集
利用sklearn运行代码如下:
"""
使用sklearn实现线性回归
"""
import numpy as np
from sklearn.linear_model import LinearRegression
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
lin_reg = LinearRegression()
# fit方法就是训练模型的方法
lin_reg.fit(X, y)
# intercept 是截距 coef是参数
print(lin_reg.intercept_, lin_reg.coef_)
# 预测
X_new = np.array([[0], [2]])
print(lin_reg.predict(X_new))
运行代码结果如下:
[4.28035282] [[2.86306684]]
[[ 4.28035282]
[10.0064865 ]]
模型
![]()
参数
![]()
损失参数
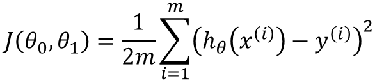
目标
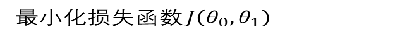

梯度下降算法:重复执行直到收敛:
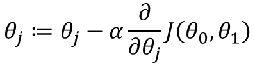
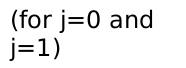
梯度下降代码运行如下:
"""
线性回归实现梯度下降的批处理(batch_gradient_descent )
"""
import numpy as np
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
X_b = np.c_[np.ones((100, 1)), X]
# print(X_b)
learning_rate = 0.1
# 通常在做机器学习的时候,一般不会等到他收敛,因为太浪费时间,所以会设置一个收敛次数
n_iterations = 1000
m = 100
# 1.初始化theta, w0...wn
theta = np.random.randn(2, 1)
count = 0
# 4. 不会设置阈值,之间设置超参数,迭代次数,迭代次数到了,我们就认为收敛了
for iteration in range(n_iterations):
count += 1
# 2. 接着求梯度gradient
gradients = 1/m * X_b.T.dot(X_b.dot(theta)-y)
# 3. 应用公式调整theta值, theta_t + 1 = theta_t - grad * learning_rate
theta = theta - learning_rate * gradients
print(count)
print(theta)线性回归模型
![]()
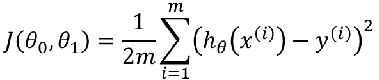
梯度下降算法
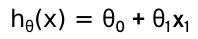 重复执行直到收敛:
重复执行直到收敛:
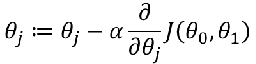
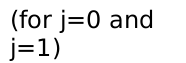
####################################################################################################
“Batch” Gradient Descent 批梯度下降
批梯度下降:指的是每下降一步,使用所有的训练集来计算梯度值
“Stochastic” Gradient Descent 随机梯度下降
随机梯度下降:指的是每下降一步,使用一条训练集来计算梯度值
“Mini-Batch” Gradient Descent “Mini-Batch”梯度下降
“Mini-Batch”梯度下降:指的是每下降一步,使用一部分的训练集来计算梯度值















 52
52











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









