






R语言是一门常用于数据分析、统计建模的计算机语言,它与主流的C/C++、Java、Python等语言相比,支持更多的数据类型,例如向量、矩阵,同时提供了多种统计和数学计算方法。
R语言解释器下载地址: https://www.r-project.org/
Rstudio是R语言集成开发环境,下载地址:https://www.rstudio.com/
四则运算
R语言使用+, -, *, /, ^ 来表示加、减、乘、除和乘方。数值可以写成 123, -123, 123.45, 1.23E-5这样的形式。其中1.23E-5表示 1.23 × 1 0 − 5 1.23 \times 10^{-5} 1.23×10−5 。
字符串
用单引号 ’ 或双引号" 包裹起来的文字内容为字符串,如 ‘hello, world’ 或 ‘123456’。
向量
R 语言中可以通过 c(…) 来声明一个向量,例如 x = ( 1 , 2 , 3 , 4 , 5 ) \boldsymbol{x} = (1, 2, 3, 4, 5) x=(1,2,3,4,5) 可以通过 x <- c(1, 2, 3, 4, 5) 来声明。
对两个长度相等的向量进行四则运算的效果是向量中的每一个元素都与另一个向量中的每一个元素进行四则运算。而一个向量与一个数进行四则运算的效果是该向量中的所有元素都与这个数进行四则运算。(类似numpy的广播机制)如:

矩阵
R 语言中可以通过 matrix() 函数来创建矩阵。matrix() 的原型为 matrix(data=NA, nrow=1, ncol=1, byrow=FALSE, dinames=NULL) 其中:
- data : 矩阵的元素,通常为向量。
- nrow 和 ncol : 设定矩阵的行数和列数,一般只需设定其一,另一个会根据数据长度算出。
- byrow : 设定矩阵的填充方式,值为 TRUE 时按行填充。默认为 FALSE ,即按列填充。
通过 matrix() 创建矩阵的例子如下:


此外还可以使用 dim() 通过向量来创建矩阵,例如:

生成时间序列
通过 ts() 函数可以将一个向量或矩阵转成一个一元或多元的时间序列(ts)对象,ts() 函数的原型为:ts(data = NA, start = 1, end = numeric(0), frequency = 1, deltat = 1, ts.eps = getOption(“ts.eps”), class, names)。其中:
- data 要生成时间序列的向量或矩阵。
- start 第一个观测值的时间。
- end 最后一个观测值的时间。
- frequency 单位时间内观测值的频数。
- deltat 两个观测值之间的时间间隔。
- ts.eps 序列之间的误差限。若序列之间的频率差异小于 ts.eps 则认为这些序列的频率相等。
- class 对象的类型。一元序列默认为 ts,多元序列默认为 c(“mts”, “ts”) 。
- names 给出多元序列中每个一元序列的名称,默认为 Series 1, Series 2, … 。
下面是一个例子:

画图
R 语言中可以直接使用 plot() 函数来绘制图像,例如:


还可以直接绘制时间序列的图像:
plot(ts(x))

为了将多幅图画在一起,可以使用 par() 函数:
-
op <- par(mfrow=c(2, 1), mar=c(5, 4, 2, 2) + .1) # mfrow
指定了图像矩阵为两行一列,即画两幅图,每行一幅;mar 指定了图像的边界,分别是下、左、上、右,可以根据喜好指定 plot(ts(x)) -
acf(x, main = “”) # 计算 acf 函数

统计与时间序列分析基础
平均值

方差和标准差

偏度和峰度
可以通过自己编写函数来计算偏度和峰度:

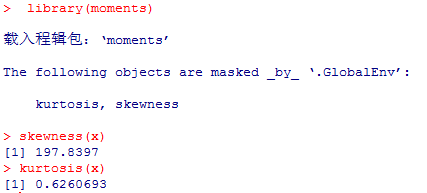
也可以通过 moments 包中的 skewness 和 kurtosis 函数来计算偏度和峰度。
首先通过 > install.packages(moments) 来安装 moments 包,然后通过 > library(moments) 来使用这个包。之后就可以直接通过 skewness() 和 kurtosis() 来计算偏度和峰度。
重要的概率分布
正态分布
通过 rnorm() 函数可以产生服从正态分布的随机数,rnorm() 函数的原型为 rnorm(n, mean=0, sd=1) ,其中 n 为生成数据个数,mean 为生成数据的均值,sd 为生成数据的标准差。例如:


χ 2 \chi^2 χ2 分布
可以通过 rchisq(n, df) 来产生 n 个 服从自由度为 df 的 χ 2 \chi^2 χ2 分布的随机数
若 X 1 , X 2 , … , X n X_1,X_2,\dots,X_n X1,X2,…,Xn为相互独立的、服从标准正态分布 N ( 0 , 1 ) N(0,1) N(0,1)的随机变量,则它们的平方和 Y = ∑ i = 1 n X i 2 Y=\sum_{i=1}^nX_i^2 Y=∑i=1nXi2服从 χ 2 \chi^2 χ2分布,记作 Y ∼ χ 2 ( n ) Y\sim \chi^2(n) Y∼χ2(n), n n n为自由度,它的期望 E Y = n EY=n EY=n,方差 D Y = 2 n DY=2n DY=2n
rchisq(n=1000, df=20)
hist(chi, prob=TRUE, 30)

t t t 分布
若 X ∼ N ( 0 , 1 ) X\sim N(0,1) X∼N(0,1), Y ∼ χ 2 ( n ) Y\sim \chi^2(n) Y∼χ2(n),且相互独立,则 T = X Y / n T=\frac{X}{\sqrt{Y/n} } T=Y/nX 服从 t t t 分布,记作 T ∼ t ( n ) T\sim t(n) T∼t(n), n n n为自由度。
t = rt(n=1000, df=5)
hist(t, prob=TRUE, 30)

F F F 分布
若 X ∼ χ 2 ( n 1 ) , Y ∼ χ 2 ( n 2 ) X\sim \chi^2(n_1),Y\sim \chi^2(n_2) X∼χ2(n1),Y∼χ2(n2),且相互独立,则 F = X / n 1 Y / n 2 F=\frac{X/n_1}{Y/n_2} F=Y/n2X/n1 服从 F F F分布,记作 F ∼ F ( n 1 , n 2 ) F\sim F(n_1,n_2) F∼F(n1,n2), ( n 1 , n 2 ) (n_1,n_2) (n1,n2)称自由度。
f = rf(n=1000, df1=10, df2=50)
hist(f, prob=TRUE, 30)

参考资料
Datawhale 开源文档:https://github.com/datawhalechina/team-learning-data-mining/tree/master/TimeSeries















 4531
4531











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









