







DPP介绍
Spark3.0 支持动态分区裁剪 Dynamic Partition Pruning,简称 DPP,核心思路就是先将join 一侧作为子查询计算出来,再将其所有分区用到 join 另一侧作为表过滤条件,从而实现对分区的动态修剪。如下图所示
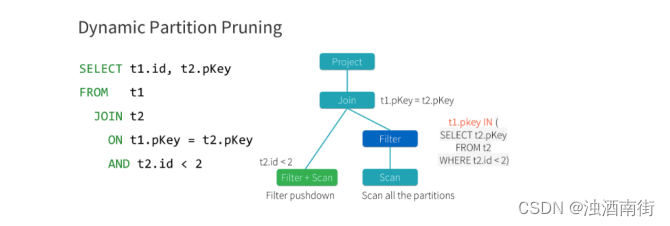
将 select t1.id,t2.pkey from t1 join t2 on t1.pkey =t2.pkey and t2.id<2 优化成了 select t1.id,t2.pkey from t1 join t2 on t1.pkey=t2.pkey and t1.pkey in(select t2.pkey from t2 where t2.id<2)
触发条件:
(1)待裁剪的表 join 的时候,join 条件里必须有分区字段
(2)如果是需要修剪左表,那么 join 必须是 inner join ,left semi join 或 right join,反之亦然。但如果是 left out join,无论右边有没有这个分区,左边的值都存在,就不需要被裁剪
(3)另一张表需要存在至少一个过滤条件,比如 a join b on a.key=b.key and a.id<2参数spark.sql.optimizer.dynamicPartitionPruning.enabled 默认开启。
spark-submit --master yarn --deploy-mode client --driver-memory 1g --num executors 3 --executor-cores 4 --executor-memory 2g --class com.atguigu.sparktuning.dpp.DPPTest spark-tuning-1.0-SNAPSHOT-jar-with dependencies.jar
具体代码
package com.atguigu.sparktuning.dpp
import com.atguigu.sparktuning.utils.InitUtil
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
object DPPTest {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("DPPTest")
.set("spark.sql.optimizer.dynamicPartitionPruning.enabled", "true")
// .setMaster("local[*]")
val sparkSession: SparkSession = InitUtil.initSparkSession(sparkConf)
val result=sparkSession.sql(
"""
|select a.id,a.name,a.age,b.name
|from sparktuning.test_student a
|inner join sparktuning.test_school b
|on a.partition=b.partition and b.id<1000
""".stripMargin)
// .explain(mode="extended")
result.foreach(item=>println(item.get(1)))
}
}















 677
677











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









