







推荐系统在技术实现上一般划分为三个阶段:挖掘、召回、排序 。
为什么要融合?
挖掘的工作是对用户和物品做非常深入的结构化分析,各个角度各个层面的特征都被呈现出来,并且建好索引,供召回阶段使用,大部分挖掘工作都是离线进行的。
接下来是召回,为什么是召回呢?因为物品太多了,每一次给一个用户计算推荐结果时,如果对全部物品挨个计算,那将是一场灾难,取而代之的是用一些手段从全量的物品中筛选出一部分比较靠谱的。
最后是排序,针对筛选出的一部分靠谱的做一个人统一的按资排辈,最后这一个统一的排序就是今天要讲的主题:融合。
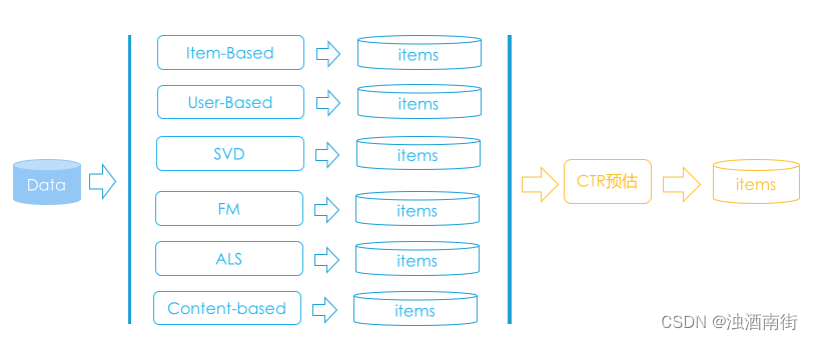
什么要融合呢?这个还需要回到召回阶段,看这个阶段到底发生了什么?
在召回阶段,其实就是很多推荐算法,比如基于内容的推荐,协同过滤或矩阵分解等等,每一种土建算法都会产生一批推荐结果,一般还附带给每个结果产生一个推荐分数。
于是问题来了,这些不同的算法产生的推荐分数,最后要一起排个先后,难道依据各自的分数吗?
这样是不行的,有如下几个原因:
1、有的算法可能只给出结果,不给分数,比如用决策树产生一些推荐结果;
2、每种算法给出结果时如果有分数,分数范围不一定一样,所以不能相互比较;
3、即时强行把所有分数都做归一化,仍然不能相互比较,因为产生机制不同,有的可能普遍偏高,有的可能普遍偏低。
举一个例子,比如江苏的考生江苏卷考进清华,北京的考生北京卷考进清华,河南的考生全国卷考进清华,他们都是学霸,可是我如何从中选择出学霸中的学霸呢?很简单,来一次入学统一考试就可以了。这个入学考试就是模型融合。也就是说,不同的算法只负责推举出候选结果,真正最终是否推荐给用户,由另一个统一的模型说了算,这个就叫做模型的融合。
模型的融合除了统一规范,还有集中提升效果的作用。在机器学习中,有专门为融合而生的集成学习思想。
今天要讲的典型的模型融合方案是:逻辑回归和梯度提升决策树组合,我可以给它取个名字“辑度组合”。
“辑度组合”原理
在推荐系统的模型融合阶段,就要以产品目标为导向。举个简单的例子,信息流推荐,如果以提高CTR为目标,则融合模型就要把预估CTR作为本职工作,可以选用逻辑回归。
逻辑回归
CTR预估就是在推荐一个物品之前,预估一下用户点击它的概率有多大,再根据这个预估的点击对物品排序输出。
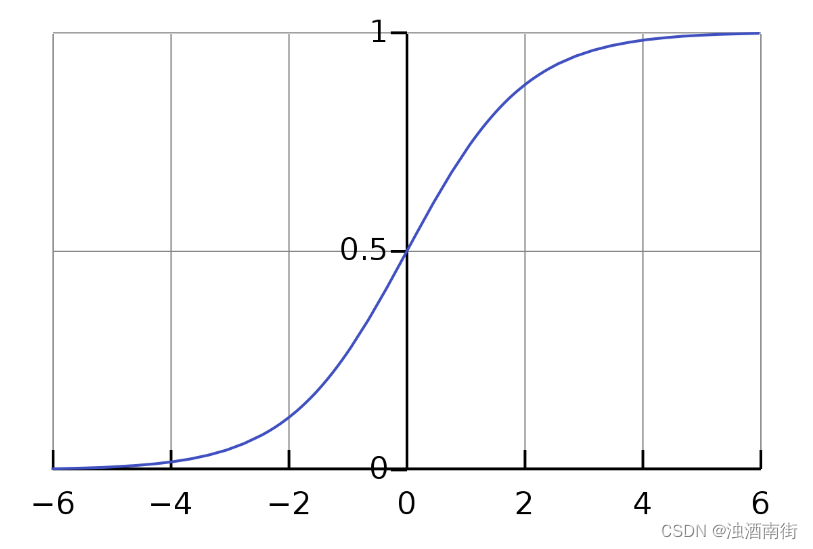
逻辑回归常常被选择来执行这个任务,它的输出范围就是从0到1之间,刚好满足点击预估的输出,这是一个基础。因为逻辑回归是广义线性模型,相比于传统线性模型,在线性模型基础上增加了sigmoid函数。
逻辑回归如何做CTR预估呢?先看一下计算CTR预估时,需要的两个东西:
1.特征; 2.权重
第一个是特征,就是向量化的把一个用户和物品成对组合展示出来;第二个是权重,每一个特征都有一个权重,权重就是特征的话事权,每个特征的权重不一样,对最终计算CTR影响有大有小。
有了特征,它是一个向量,假如把它叫做x,还有特征的权重,也是一个维度和特征一样的向量,假如叫做w。我们通过对x和w做点积计算,就得到一个传统的线性模型的输出,再用一个sigmoid函数对这个值做一个变换,就得到一个0到1之间的值,也就是预估的CTR。
sigmoid 函数:
σ
(
w
,
x
)
=
1
1
+
e
(
−
w
∗
x
)
σ(w,x) =\frac{1}{1+e^{(-w * x)}}
σ(w,x)=1+e(−w∗x)1
要做的就是两件事;搞特征,学权重。前者占据更多时间。特征在很多领域都是布尔取值,比如搜索广告,只有出现和不出现两种。还有一些特征是实数取值,很多场景下可以把他划分成多个区间段,也变成了布尔取值。除此之外,逻辑回归是广义线性回归,所谓广义是因为加了sigmoid函数,很多非线性关系它也无能为力。
特征可以组合,有二阶组合,还有三阶组合,特征组合的难点在于:组合数目非常庞大,而且并不是所有组合都有效,只有少数组合有效。
需要不断从数据中发现新的、有效的特征及特征组合。
特征工程+线性模型,是模型融合、CTR预估等居家旅行必备。
权重的学习主要看两个方面:损失函数的最小化,就是模型的偏差是否足够小;另一个就是模型的正则化,就是看模型的方差是否足够小;
除了要学习出偏差和方差都较小的模型,还需要给工程留有余地,具体来说有两点:一个是希望越多权重为0越好,权重为0称为稀疏,可以减小计算复杂度。
另一个是希望能够在线学习这些权重,后台源源不断地更新权重。要学习逻辑逻辑回归的权重,经典的方法如梯度下降一类,尤其是随机梯度下降,可以实现在实时数据流情形下,更新逻辑回归的权重,每一个样本更新一次。
但随机梯度下降为人诟病的是很难得到稀疏的模型,效果收敛也很慢。后来,google在2013年发表了新的学习算法:FTRL,一种结合了L1正则和L2正则的在线优化算法,现在基本都采用这个算法。
梯度提升决策树GBDT
特征组合又能有效表达出数据中的非线性事实,可以通过树模型提高效率。树模型天然就可以肩负起特征组合的任务,从第一个问题开始,也就是树的根节点,到最后得到答案,也就是叶子节点,这一路径下来就是若干个特征的组合。
树模型最开始的是决策树,简称DT,实践发现,把“多个表现”略好于“随机乱猜”的模型以某种方式集成在一起往往出奇效,所以就是说树模型的集成模型。最常见的就是说随机森林,简称RF,和梯度提升树,简称GBDT。
梯度提升树,可以分为两部分,一个是GB,一个是DT.GB是得到集成模型的方案,沿着残差梯度下降的方向构建新的子模型,而DT就是指构建子模型要用的决策树。
举例:
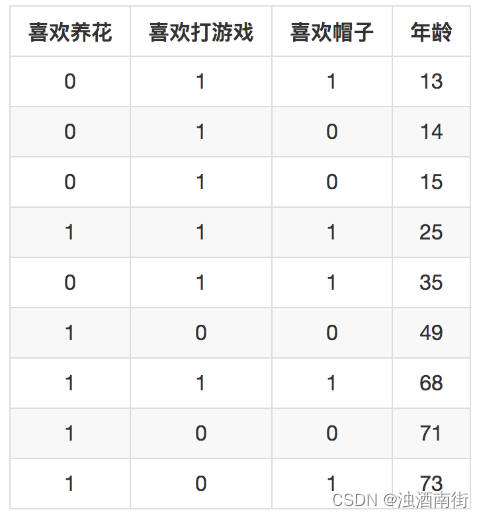
现在有个任务是根据是否喜欢养花,喜欢打游戏,喜欢帽子来预测年龄,模型就是梯度提升决策树GBDT。假设我们设定好每个子树只有一层,那么三个特征各自按照取值都可以构成
两分支的小树枝。
树根节点为:是否喜欢养花,左分支是不喜欢,被划分进去的样本有13,14,15,35;右边是喜欢,被划分进去的样本有25,49,68,71,73。左边的样本均值是19.25,右边样本均值是57.2。
树根节点为:是否喜欢游戏,左分支是不喜欢,被划分进去的样本有49,71,73;右边是喜欢,被划分进去的样本有13,14,15,25,35,68。左边的均值是64,右边的均值是28.3。
树根节点为:是否喜欢帽子,左分支是不喜欢,被划分进去的样本有14,15,49,71;右边是喜欢,被划分进去的样本有13,25,35,68,73。左边的均值是37.25,右边的均值是42.8。
叶子节点上都是被划分进去的样本年龄均值,也就是预测值。这里是看哪个树让残差减小最多,分别拿三个方案取预测每个样本,统计累积的误差平方和,三个分别是1993.55,2602,5007.95,
于是显然第一颗树的预测结果较好,所以GBDT第一颗树胜出。
接下来第二棵树如何生成呢?GBDT用上一棵树取预测所有样本,得到每一个样本的残差,下一棵树不是去拟合样本的目标值,而是去拟合上一颗树的残差。这里,就是去拟合下面这个表格:
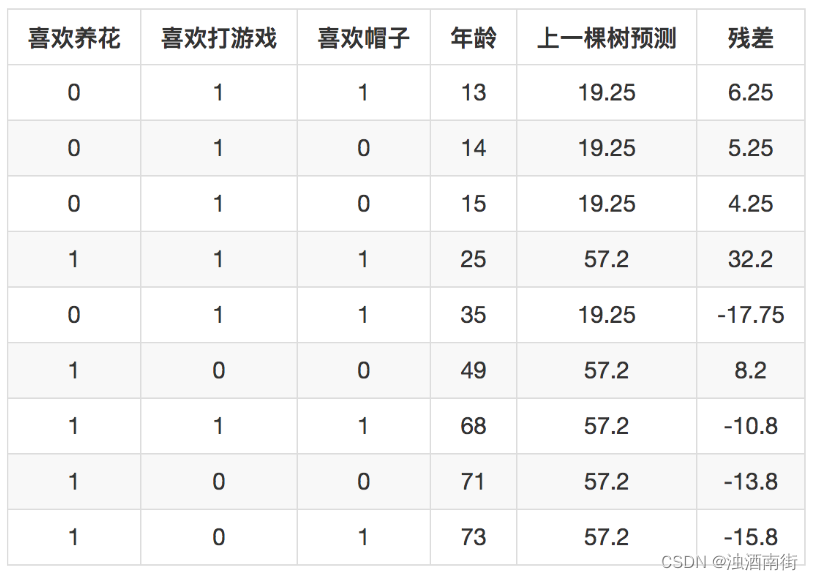
新一轮构建树的过程以最后一列残差为目标。构建过程这里不再赘述,得到第二颗树。如此不断在上一次建树的残差基础上构建新树,直到满足条件后停止。
在得到所有这些树后,真正使用时,是将它们的预测结果相加作为最终输出结果。这就是GBDT的简单举例。
这里有几个问题:
第一个,上面的例子是回归问题,如何将它用来做分类呢?那就是把损失函数从上面的误差平方和换成适合分类的损失函数,比如对数损失函数。更新时按照梯度方向即可,上面的误差平方和的梯度就刚好是
残差。对于CTR预估这样的二分类任务,可以将损失函数定义为:
−
y
l
o
g
p
−
(
1
−
y
)
l
o
g
(
1
−
p
)
-ylog p - (1-y)log(1-p)
−ylogp−(1−y)log(1−p)
第二个,通常还需要考虑防止过拟合,也就是损失函数汇总需要增加正则项,正则化的方法一般是:限制总的树个数,树的深度,以及叶子节点的权重大小。
第三个,构建每一颗树时,如果遇到实数值的特征,还需要将其分裂成若干区间,分裂指标有很多,可以参考xgboost中的计算分裂点收益,也可以参考决策树所用的信息增益。
二者结合
前面介绍了逻辑回归LR,以及梯度提升决策树GBDT的原理。实际上可以将两者结合在一起,用于做模型融合阶段的CTR预估。这是Facebook在其广告系统中使用的方法,其中GBDT的任务就是产生高阶特征组合;
具体做法是:GBDT产生了N棵树,一条样本来了后,在每一颗树上都会从根节点走到叶子节点,到了叶子节点后,就是1或者0.把每棵树的输出结果看成是一个组合特征,取值为0或者1,一共N颗树,每棵树i有Mi个叶子就相当于有M种组合,一棵树对应一个one-hot(独热)编码方式,一共就有 ∑ i = 1 N M i \sum_{i=1}^N{M_i} ∑i=1NMi个维度的新特征,作为输入向量进入LR模型,输出最终的结果。
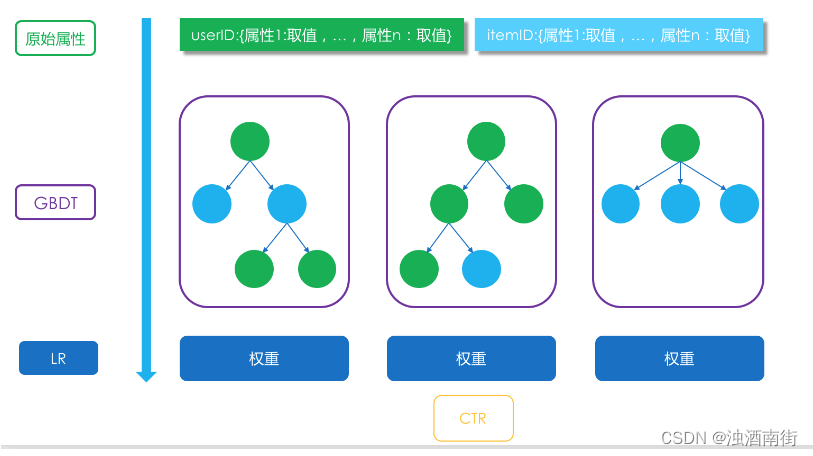
每一条样本,样本内容一般是把用户、物品、场景三类特征拼接在一起,先经过N颗GBDT树各自预测一下,给出0或1的预测结果。接着,这个N个预测结果再作为one-hot编码特征拼接成一个向量送入逻辑回归中,产生最终的融合预测结果。另外,由于两者结合后用来做推荐系统的模型融合,所以也可以考虑在输入特征中加入各个召回模型产生的分数。
以上就是“辑度组合”原理,虽然简单,但在实际应用中非常有效。
总结
今天我们主要讲了简单的逻辑回归和梯度提升决策树,两者都不是太复杂的模型。并且无论是逻辑回归,还是梯度提升决策树,都有非常成熟的开源实现,可以很快落地。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









