







在我们学习Python的第一天和第二天的时候我们已经把Python安装好了,环境配置也处理完毕了,今天我们就来爬数据,用Python总得做点啥是不是,今天我们先爬取网站数据,提高一下我们明天开始学基础的积极性。
废话不多逼逼了,开始上步骤,请确保每一步与笔者一致并执行成功!!!
废话不多逼逼了,开始上步骤,请确保每一步与笔者一致并执行成功!!!
废话不多逼逼了,开始上步骤,请确保每一步与笔者一致并执行成功!!!
准备开始
每一次打算用 Python 搞点什么的时候,你问的第一个问题应该是:“我需要用到什么库”?
第一步,连接并获取一个要爬取的网站内容
今天网页爬取要用到的库(选任意一个就可以):
- Beautiful Soup - - https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
- Requests - - https://2.python-requests.org//zh_CN/latest/user/quickstart.html
- Scrapy - - https://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/tutorial.html
- Selenium - - https://www.seleniumhq.org/
要爬取的网站:
https://www.fasttrack.co.uk/league-tables/tech-track-100/league-table/

爬取数据之前要先分析你将要爬取数据的数据结构,通过鼠标右键你想要查看的内容,选择“检查”,就能看到他的dom结构。
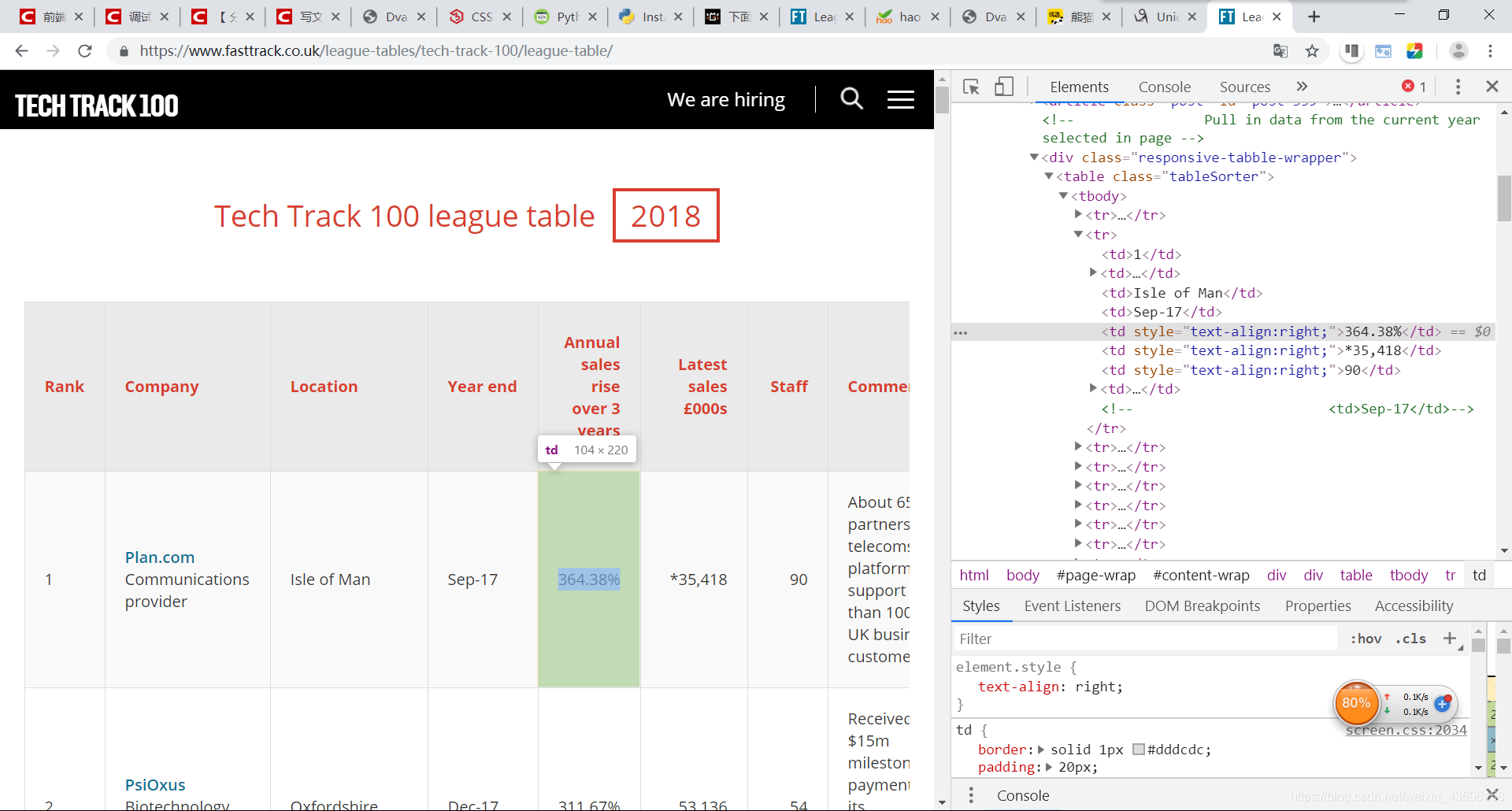
这个例子里,所有的100个结果都包含在同一个页面中,还被 标签分隔成行。但实际抓取过程中,许多数据往往分布在多个不同的页面上,你需要调整每页显示的结果总数,或者遍历所有的页面,才能抓取到完整的数据。
在表格页面上,你可以看到一个包含了所有100条数据的表格,右键点击它,选择“检查”,你就能很容易地看到这个 HTML 表格的结构。包含内容的表格本体是在这样的标签里:

每一行都是在一个 标签里,也就是我们不需要太复杂的代码,只需要一个循环,就能读取到所有的表格数据,并保存到文件里。
附注:你还可以通过检查当前页面是否发送了 HTTP GET 请求,并获取这个请求的返回值,来获取显示在页面上的信息。因为 HTTP GET 请求经常能返回已经结构化的数据,比如 JSON 或者 XML 格式的数据,方便后续处理。你可以在开发者工具里点击 Network 分类(有必要的话可以仅查看其中的 XHR 标签的内容)。这时你可以刷新一下页面,于是所有在页面上载入的请求和返回的内容都会在 Network 中列出。此外,你还可以用某种 REST 客户端(比如 Insomnia)来发起请求,并输出返回值。
将你的编辑器和电脑上安装BeautifulSoup4
windows键加r键开启命令行。
$ pip install BeautifulSoup4
然后再在你的编辑器上进行安装

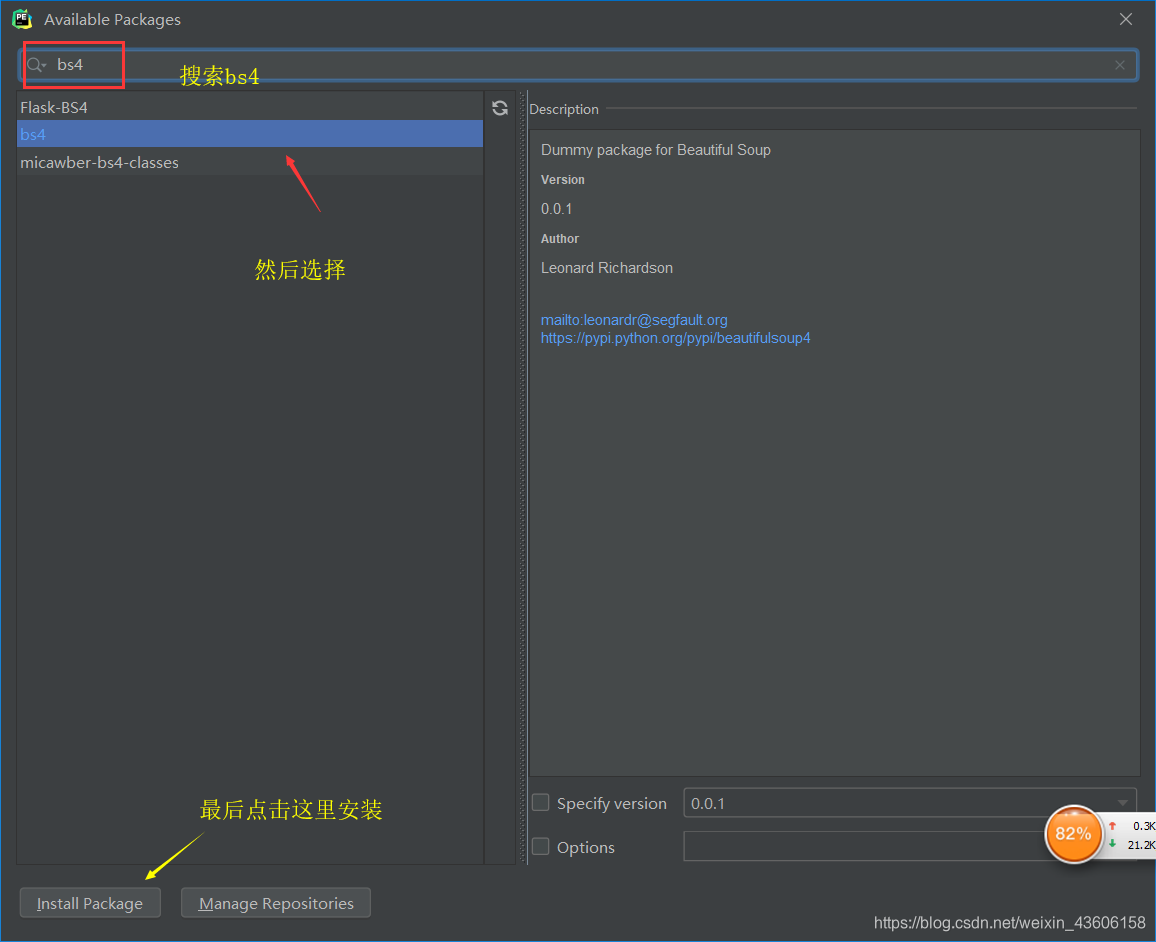
安装完成后在界面下方会提示“Package‘bs4’ install successfully”

现在开始在你第一天print出Hello World的那个文件把那个Print删了开始改成我们今天接下来的代码:
首先要做的是导入代码中需要用到的各种模块。上面我们已经提到过 BeautifulSoup,这个模块可以帮我们处理 HTML 结构。接下来要导入的模块还有 urllib,它负责连接到目标地址,并获取网页内容。最后,我们需要能把数据写入 CSV 文件,保存在本地硬盘上的功能,所以我们要导入 csv 库。当然这不是唯一的选择,如果你想要把数据保存成 json 文件,那相应的就需要导入 json 库。
# 导入需要的模块
from bs4 import BeautifulSoup
import urllib.request
import csv
# 把网站url存在变量里
urlpage = 'https://www.fasttrack.co.uk/league-tables/tech-track-100/league-table/'
# 获取网页内容,把html数据保存在“page变量里”
page = urllib.request.urlopen(urlpage)
# 用beautiful soup 解析 html 数据
soup = BeautifulSoup(page, 'html.parser')
这时候,你可以试着把 soup 变量打印出来,看看里面已经处理过的 html 数据长什么样:
print(soup)
如果变量内容是空的,或者返回了什么错误信息,则说明可能没有正确获取到网页数据。你也许需要用一些错误捕获代码,配合 urllib.error 模块,来发现可能存在的问题。
第二步,用BeautifulSoup处理获得的html数据
查找 HTML 元素
既然所有的内容都在表格里(<table>标签),我们可以在 soup 对象里搜索需要的表格,然后再用 find_all 方法,遍历表格中的每一行数据。
如果你试着打印出所有的行,那应该会有 101 行——100行内容,加上一行表头。
# 在表格中查找数据
table = soup.find('table', attrs={'class': 'tableSorter'})
results = table.find_all('tr')
print('Number of results', len(results))
看看打印出来的内容,如果没问题的话,我们就可以用一个循环来获取所有数据啦。
如果你打印出 soup 对象的前 2 行,你可以看到,每一行的结构是这样的:
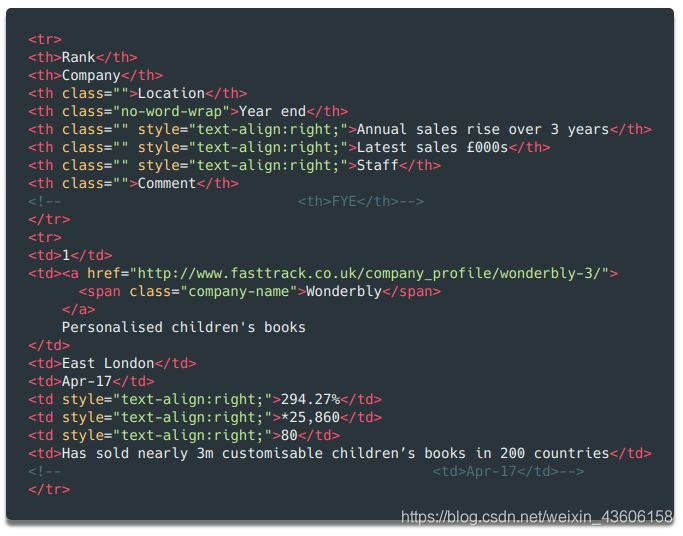
可以看到,表格中总共有 8 列,分别是 Rank(排名)、Company(公司)、Location(地址)、Year End(财年结束)、Annual Sales Rise(年度销售增长)、Latest Sales(本年度销售额)、Staff(员工数)和 Comments(备注)。这些都是我们所需要的数据。
这样的结构在整个网页中都保持一致(不过在其他网站上可能就没这么简单了!),所以我们可以再次使用 find_all 方法,通过搜索 元素,逐行提取出数据,存储在变量中,方便之后写入 csv 或 json 文件。
循环遍历所有的元素并存储在变量中
在 Python 里,如果要处理大量数据,还需要写入文件,那列表对象是很有用的。我们可以先声明一个空列表,填入最初的表头(方便以后CSV文件使用),而之后的数据只需要调用列表对象的 append 方法即可。
rows = []
rows.append(['Rank', 'Company Name',
'Webpage', 'Description',
'Location', 'Year end',
'Annual sales rise over 3 years', 'Sales f000s',
'Staff', 'Comments'
])
print(rows)
这样就将打印出我们刚刚加到列表对象 rows 中的第一行表头。
你可能会注意到,我输入的表头中比网页上的表格多写了几个列名,比如 Webpage(网页)和 Description(描述),请仔细看看上面打印出的 soup 变量数据——第二行第二列的数据里,可不只有公司名字,还有公司的网址和简单描述。所以我们需要这些额外的列来存储这些数据。
第三步,在soup对象里循环搜索需要的html元素
下一步,我们遍历所有100行数据,提取内容,并保存到列表中。
循环读取数据的方法:
# 遍历所有数据
for result in results:
# 找到每一个 td 单元格的内容
data = result.find_all('td')
# 如果该单元格无数据,则跳过
if len(data) == 0:
continue
因为数据的第一行是 html 表格的表头,所以我们可以跳过不用读取它。因为表头用的是 标签,没有用 标签,所以我们只要简单地查询 标签内的数据,并且抛弃空值即可。
接着,我们将 data 的内容读取出来,赋值到变量中:
# 将单元格内容保存到变量中
rank = data[0].getText()
company = data[1].getText()
location = data[2].getText()
yearend = data[3].getText()
salesrise = data[4].getText()
sales = data[5].getText()
staff = data[6].getText()
comments = data[7].getText()
如上面的代码所示,我们按顺序将 8 个列里的内容,存储到 8 个变量中。当然,有些数据的内容还需有额外的清理,去除多余的字符,导出所需的数据。
第四步,进行数据处理(将不要的符号去掉等等操作)
数据清理
如果我们打印出 company 变量的内容,就能发现,它不但包含了公司名称,还包括和描述。如果我们打印出 sales 变量的内容,就能发现它还包括一些备注符号等需要清除的字符。
print('Company is', company)
print('Sales', sales)
我们希望把 company 变量的内容分割成公司名称和描述两部分。这用几行代码就能搞定。再看看对应的 html 代码,你会发现这个单元格里还有一个 元素,这个元素里只有公司名称。另外,还有一个 <a> 链接元素,包含一个指向该公司详情页面的链接。我们一会也会用到它!
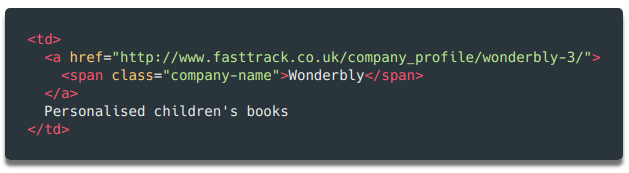
为了区分公司名称和描述两个字段,我们再用 find 方法把 元素里的内容读取出来,然后删掉或替换 company 变量中的对应内容,这样变量里就只会留下描述了。
要删除 sales 变量中的多余字符,我们用一次 strip 方法即可。
# 提取公司名字
companyname = data[1].find('span', attrs={'class': 'company-name'}).getText()
description = company.replace(companyname, '')
# 移除多余的字符
sales = sales.strip('*').strip('+').replace(',', '')
最后我们要保存的是公司网站的链接。就像上面说的,第二列中有一个指向该公司详情页面的链接。每一个公司的详情页都有一个表格,大部分情况下,表格里都有一个公司网站的链接。

检查公司详情页里,表格中的链接
为了抓取每个表格中的网址,并保存到变量里,我们需要执行以下几个步骤:
- 在最初的 fast track 网页上,找到需要访问的公司详情页的链接。
- 发起一个对公司详情页链接的请求
- 用 Beautifulsoup 处理一下获得的 html 数据
- 找到需要的链接元素
正如上面的截图那样,看过几个公司详情页之后,你就会发现,公司的网址基本上就在表格的最后一行。所以我们可以在表格的最后一行里找 <a> 元素。
# 获取链接,并发出访问请求
url = data[1].find('a').get('href')
page = urllib.request.urlopen(url)
# 处理HTML数据
soup = BeautifulSoup(page, 'html.parser')
# 找到表格中的最后一行,尝试获取<a>元素的内容
try:
tableRow = soup.find('table').find_all('tr')[-1]
webpage = tableRow.find('a').get('href')
except:
webpage = None
同样,有可能出现最后一行没有链接的情况。所以我们增加了 try… except 语句,如果没有发现网址,则将变量设置成 None。当我们把所有需要的数据都存在变量中的以后(还在循环体内部),我们可以把所有变量整合成一个列表,再把这个列表 append 到上面我们初始化的 rows 对象的末尾。
# 把变量添加到rows对象里
rows.append([rank, company,
webpage, desciption,
location, yearend,
salesrise, sales,
staff, comments
])
# 注意这里退出了循环体
print(rows)
上面代码的最后,我们在结束循环体之后打印了一下 rows 的内容,这样你可以在把数据写入文件前,再检查一下。
第五步,把数据写入csv文件中
最后,我们把上面获取的数据写入外部文件,方便之后的分析处理。在 Python 里,我们只需要简单的几行代码,就可以把列表对象保存成文件。
# 创建一个 csv 文件,并将 rows 对象写入这个文件中
with open('techtrack100.scv', 'w', newline='') as f_output:
csv_output = csv.writer(f_output)
csv_output.writerows(rows)
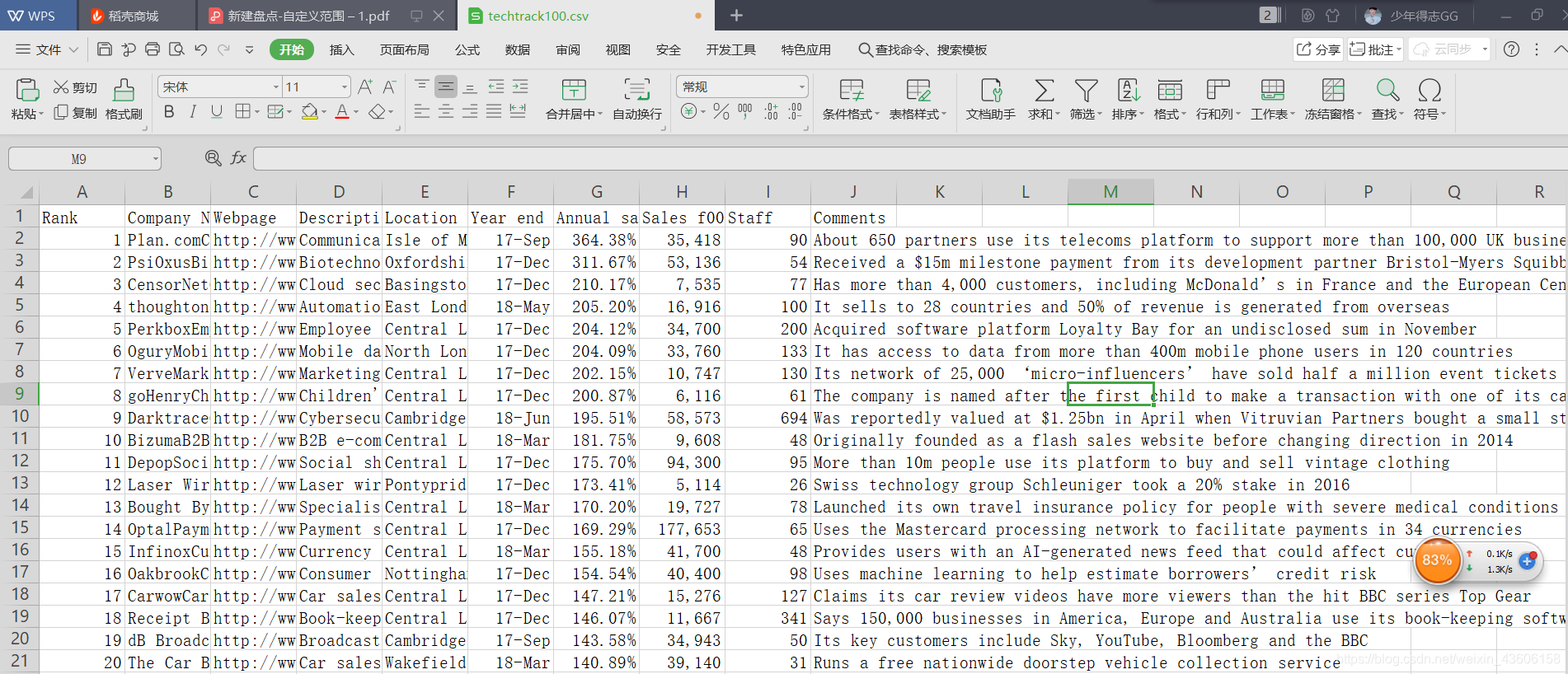
最后我们来运行一下这个 python 代码,如果一切顺利,你就会发现一个包含了 100 行数据的 csv 文件出现在了目录中,你就可以看到如下效果了:
如果你运行时报错:UnicodeEncodeError: ‘gbk’ codec can’t encode character ‘\xa0’
请将最后的代码改成:
with open('techtrack100.csv', 'w', newline='') as f_output:
csv_output = csv.writer(f_output.replace(u'\xa0', u''))
csv_output.writerows(rows)
OK了,如果朋友们还有其他什么问题就在下面留言吧!明天开始学python基础!一起加油!















 5908
5908











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









