






之前的slurm集群下面辖三个节点,compute-0,compute-1,compute-2。但后面更名为node1,node2,node3,在master节点配置完/etc/slurm/slurm.conf文件之后,也通过文件同步机制同步到各node上了,各个node的hostname包括/etc/hosts这些文件也都改过了,都没问题
但在master上用slurm提交任务,分发到各节点上还是会去请求老的节点名称,导致屡次报错,以node3为例:

找了一圈,没发现有类似的解决帖
直到lasted一次报错[2024-04-29T16:41:26.777] error: _find_node_record: lookup failure for node "compute-2"导致了slurm崩溃了
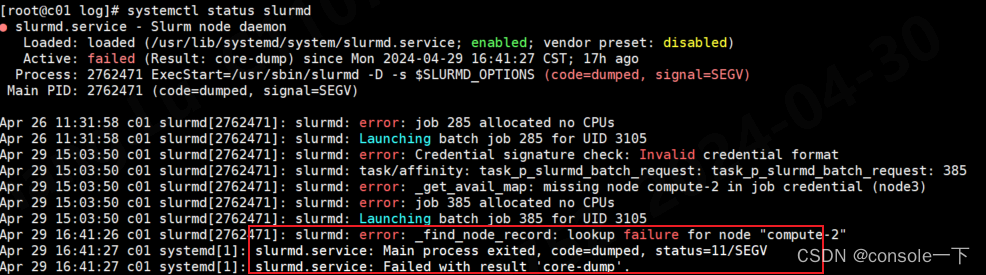
随后重启了node3的slurmd服务
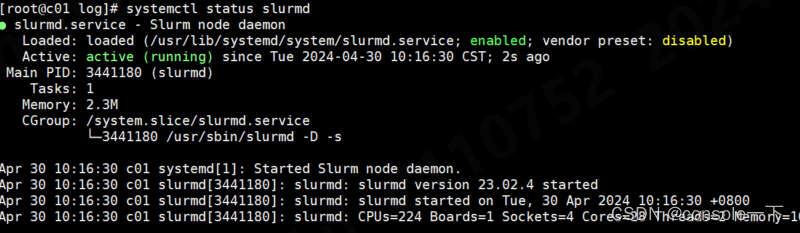
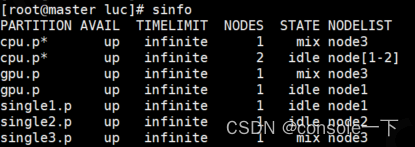
在master查看,确实也恢复idle状态了
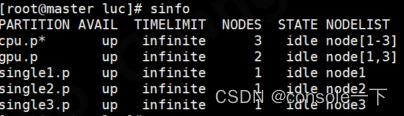
(之前是down)

而后在master提交任务,指定用node3来跑,发现都正常了
======================================================================
所以问题是怎么解决的呢,初步认为是在/etc/slurm/slurm.conf完成nodename变更之后,没有将节点的slurmd服务重新启动,因此可能因为有缓存的原因,还是会去请求旧的节点名称,自然找不到。将服务重新启动之后问题就好了
至于如何导致的服务崩溃,core-dump,是没有深究,欢迎讨论















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









