







1.DOS命令创建项目
1.1 scarpy startproject qsbk(项目名称)
1.2 进入项目目录 cd qsbk
1.3 scrapy genspider qsbk_spiderqiushibaike.com
(爬虫名称,爬虫名称不能与项目名称同名)
1.4 可以在pycharm或其他编译器上试运行,博主用pycharm,用pycharm打开qsbk项目,然后在页面下方找到Terminal, 输入
scrapy crawl qsbk_spider
无错误就说明创建项目成功
2. 项目目录
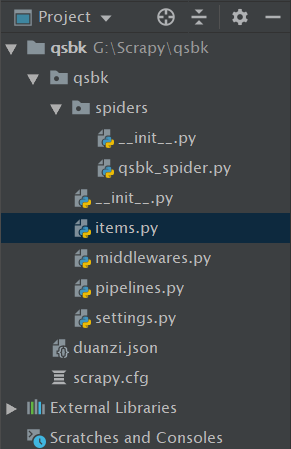
其中, duanzi.json是最后爬取成功生成的。
3.项目设置settings.py文件
3.1 ROBOTSTXT_OBEY = False项目默认为True。默认为True,就是要遵守robots.txt 的规则,通俗来说, robots.txt 是遵循 Robot协议 的一个文件,它保存在网站的服务器中,它的作用是,告诉搜索引擎爬虫,本网站哪些目录下的网页不希望你进行爬取收录。在Scrapy启动后,会在第一时间访问网站的 robots.txt 文件,然后决定该网站的爬取范围。
当然,我们并不是在做搜索引擎,而且在某些情况下我们想要获取的内容恰恰是被 robots.txt 所禁止访问的。所以,某些时候,我们就要将此配置项设置为 False ,拒绝遵守 Robot协议 !
3.2
DEFAULT_REQUEST_HEADERS = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'Accept-Language': 'en', User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36 }
那现在想一下为什么要设置User-Agent???

有一些网站不喜欢被爬虫程序访问,所以会检测连接对象,如果是爬虫程序,也就是非人点击访问,它就会不让你继续访问,所以为了要让程序可以正常运行,需要隐藏自己的爬虫程序的身份。此时,我们就可以通过设置User Agent的来达到隐藏身份的目的,User Agent的中文名为用户代理,简称UA。
User Agent存放于Headers中,服务器就是通过查看Headers中的User Agent来判断是谁在访问。在Python中,如果不设置User Agent,程序将使用默认的参数,那么这个User Agent就会有Python的字样,如果服务器检查User Agent,那么没有设置User Agent的Python程序将无法正常访问网站。
Python允许我们修改这个User Agent来模拟浏览器访问,它的强大毋庸置疑。
4. 编写爬虫
项目创建成功并经初步设置之后,就可以编写爬虫了。
4.1 项目目的
首先作为一个入门级项目,就简单的爬取糗事百科的段子,爬取内容只含有段子内容和作者。
现在项目目录下的items.py文件中定义需要抓取的数据,代码如下:
import scrapy
class QsbkItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
author = scrapy.Field()
text = scrapy.Field()
4.2 爬虫qsbk_spider.py
# -*- coding: utf-8 -*-
import scrapy
from qsbk.items import QsbkItem
class QsbkSpiderSpider(scrapy.Spider):
name = 'qsbk_spider' # 爬虫名称
allowed_domains = ['qiushibaike.com'] # 允许域名
start_urls = ['https://www.qiushibaike.com/text/'] # 开始爬取链接
base_url = 'https://www.qiushibaike.com'
def parse(self, response):
duanzidivs = response.xpath("//div[@id='content-left']/div")
for duanzidiv in duanzidivs:
author = duanzidiv.xpath(".//h2/text()").get().strip()
text = duanzidiv.xpath(".//div[@class='content']//text()").getall()
text = "".join(text).strip()
item = QsbkItem(author=author, text=text)
# yield是将这个函数包装成一个迭代器,每次调用都返回这个item
yield item
next_url = response.xpath("//ul[@class='pagination']//li[last()]/a/@href").get()
# 糗事百科段子页面共13页,所以13页之后不存在下一页了, 此处加一个if判断
if not next_url:
return
else:
yield scrapy.Request(self.base_url+next_url, callback=self.parse)
4.3 编写管道文件piplines.py,将爬取结果保存到json格式的文件中
from scrapy.exporters import JsonLinesItemExporter
class QsbkPipeline(object):
def __init__(self):
self.fp = open('duanzi.json', 'wb')
self.exporter = JsonLinesItemExporter(self.fp, ensure_ascii=False, encoding='utf-8')
def open_spider(self, spider):
print('爬虫开始...')
def process_item(self, item, spider):
self.exporter.export_item(item)
return item
def close_spider(self):
self.fp.close()
print('爬虫结束...')
此处补充一个知识点:
from scrapy.exporters import JsonItemExporter, JsonLinesItemExporter
大致概括下:
(要用二进制的方式来写)
首先我们从名字里大致可以看出来了,两者区别 Lines 也就是行的意思,也就是说 前者是一起写进json文件里,后者是我们每次parse函数yield的item,经过处理就直接写入json里面。
那么我们可以想一下,前者,既然是一起写入,假如我们爬取的的数据有上万条,那就很吃内存了。
后者是一条一条的存,对内存很友好,但是他每次写入的是一个 dict,可能读取的时候,没有 前者友好。
4.4 启用一个Item Pipeline组件
为了启用Item Pipeline组件,必须将它的类添加到 settings.py文件ITEM_PIPELINES 配置
ITEM_PIPELINES = {
'qsbk.pipelines.QsbkPipeline': 300,
}
后面的数字为设置优先级,数字越小,优先级越高。
5. 爬取部分结果展示

糗事百科每个页面25条段子,共13页。所以25*13=325。
结果是以每个字典的形式一条条列出来的,当然也可以用一个列表包含字典的形式也可,在此就不做探究了。
6. 项目笔记总结
由于这是个入门小项目,所以要编写的东西也不多,后续会有更新…
















 6086
6086











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









