







获取指定html标签内容
数据只用作爬虫学习
use Goutte\Client as GoutteClient;
第一个页面(ps:对应上一篇)
1.我们需要获取a标签的href

2.获取下一个页面href列表
$client = new GoutteClient();
$url = 'https://car.autohome.com.cn/price/brand-'.$brandId.'.html#pvareaid=2042362';
$domain = 'https://car.autohome.com.cn';
$crawler = $client->request('GET', $url);
$url_models = $crawler->filter('.list-dl > dd > .list-dl-text > a')->each(function ($node) use ($domain){
return $domain.$node->attr('href');
});
return $url_models;
第二个页面
$client = new GoutteClient();
$crawler = $client->request('GET', $url);
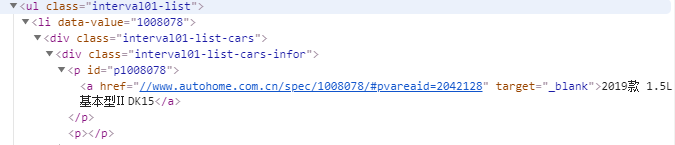
$url_detail = $crawler->filter('.interval01-list > li')->each(function($node){
return 'https://www.autohome.com.cn/spec/'.$node->attr('data-value').'/#pvareaid=2042128';
});
return $url_detail;
第三个页面

$client = new GoutteClient();
$crawler = $client->request('GET', $url);
$field = $crawler->filter('ul.baseinfo-list > li')->each(function($node){
if($node->text() != '更多参数 >'){
return $node->text();
}
});
//车系名称
$carName = $crawler->filter('.athm-sub-nav__car__name > a > h1')->text();
//车型名称
$carModels= $crawler->filter('.information-tit > h2')->text();
//参数
$field = json_encode(array_filter($field),JSON_UNESCAPED_UNICODE);
return ['carName'=>$carName,'carModels'=>$carModels,'field'=>$field] ;
至此,我们已经获取到我们所需数据

本文只作简单爬取数据,并未对分页数据进行爬取















 6157
6157











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









