







你是否曾经遇到过这样的场景:服务器突然宕机,业务中断,运维团队手忙脚乱地排查问题…在数字化时代,企业的IT系统已经成为业务运转的核心。无论是服务器、网络设备,还是应用程序和数据库,任何一环出现问题,都可能导致业务中断,甚至造成巨大的经济损失。
当业务中断,损失成既定事实,传统的“救火式”运维模式已经无法满足现代企业的需求。如果有一个监控系统能够提前预警,这样的问题完全可以避免。
一、什么是IT运维监控?
IT运维监控是指通过技术手段对IT基础设施、应用程序和业务系统进行实时监控,收集性能数据、日志信息等,并通过分析和告警机制,帮助运维团队及时发现和解决问题。
- 监控的核心目标包括:
保障系统稳定性:实时掌握系统运行状态,预防故障发生。
提升运维效率:通过自动化工具减少人工干预,快速定位问题。
优化性能:通过数据分析,发现性能瓶颈并进行优化。 - 监控的对象通常包括:
服务器(CPU、内存、磁盘、网络等)。
网络设备(路由器、交换机、防火墙等)。
应用程序(响应时间、错误率、吞吐量等)。
数据库(连接数、查询性能、锁等待等)。
云资源(虚拟机、容器、存储等)。
二、IT运维监控的核心价值
- 故障预防
通过实时监控,运维团队可以提前发现潜在问题。例如,当磁盘使用率超过95%时,系统会自动发出告警,提醒运维人员及时清理磁盘,避免因磁盘写满导致服务中断。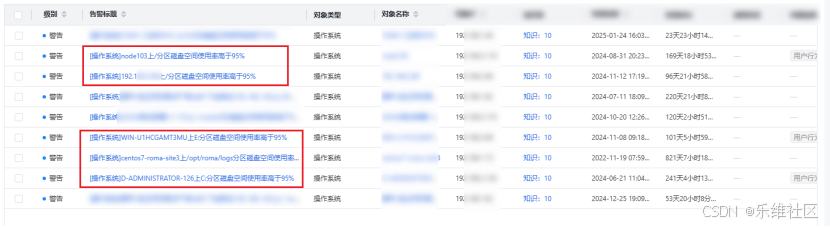
- 快速定位问题
当系统出现故障时,监控工具可以帮助运维团队快速定位问题根源。例如,通过分析日志和性能数据,可以确定是网络延迟、数据库瓶颈还是应用程序错误导致的故障。 - 性能优化
监控工具可以记录历史性能数据,帮助运维团队分析系统瓶颈。例如,通过分析CPU使用率的变化趋势,可以判断是否需要升级硬件或优化代码。 - 成本控制
通过自动化监控和告警,企业可以减少对运维人力的依赖,降低人力成本。同时,避免因故障导致的业务损失,进一步控制成本。
三、IT运维监控的基本流程 - 数据采集
监控工具通过Agent、SNMP、API等方式,从服务器、网络设备、应用程序等目标中收集数据。例如,乐维监控通过Agent采集服务器的CPU、内存、磁盘等指标。 - 数据存储
采集到的数据需要存储在数据库中,以便后续分析和查询。常见的存储方式包括时序数据库(如Prometheus的TSDB)和关系型数据库(如MySQL)。 - 数据分析
监控工具会对采集到的数据进行分析,生成性能报告、趋势图等。例如,通过分析历史数据,可以预测未来可能出现的性能瓶颈。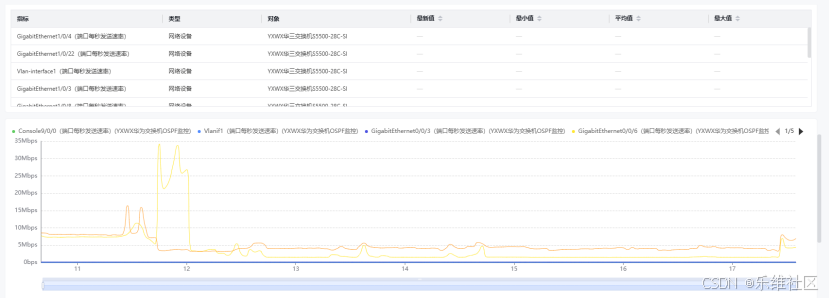
- 告警机制
当监控数据超出预设阈值时,系统会自动发出告警。告警方式包括邮件、短信、微信、钉钉等。合理的告警策略可以避免“告警疲劳”。 - 可视化展示
监控工具通常提供仪表盘功能,将监控数据以图表的形式展示出来。例如,Grafana可以将Prometheus的数据可视化,帮助运维团队直观地了解系统状态。
四、常见的IT运维监控工具 - 开源工具
Zabbix:功能强大,支持多种监控方式,适合中大型企业。
Prometheus:专注于时序数据,适合云原生环境。
Nagios:老牌监控工具,插件丰富,适合小型企业。 - 商业工具
Datadog:云原生监控工具,支持容器、微服务等。
New Relic:专注于应用程序性能监控(APM)。
乐维监控:功能全面,采集能力强,监控覆盖面广,指标体系丰富,提供本地化、定制化的监控解决方案。 - 云原生监控工具
AWS CloudWatch:亚马逊云服务的原生监控工具。
Azure Monitor:微软Azure的监控解决方案。
Google Cloud Operations Suite:谷歌云的监控和分析工具。
五、如何搭建IT运维监控体系? - 明确监控目标
根据业务需求和技术需求,确定需要监控的对象和指标。例如,电商网站可能需要重点关注应用程序的响应时间和数据库的查询性能。 - 选择监控工具
根据企业规模、预算和技术栈选择合适的监控工具。例如,小型企业可以选择Zabbix,大中企业与系统集成环境可以选择乐维监控,云原生环境可以选择Prometheus。 - 部署监控系统
安装和配置监控工具,集成现有的IT基础设施。例如,在服务器上安装Zabbix Agent,配置Prometheus的抓取规则。 - 设置监控指标和告警规则
根据业务场景设置合理的监控指标和告警阈值。例如,设置CPU使用率超过80%时发出告警。 - 持续优化
根据业务变化和技术发展,不断调整监控策略。例如,随着业务增长,可能需要增加对容器和微服务的监控。
六、IT运维监控的进阶技巧 - 自动化运维
将监控与自动化工具(如Ansible、Jenkins)结合,实现故障自动修复。例如,当磁盘空间不足时,自动清理日志文件。 - 根因分析
通过监控数据和日志分析,快速定位问题根源。例如,通过分析应用程序的调用链,确定是哪个服务导致了性能下降。 - 趋势预测
利用历史数据预测未来可能出现的性能瓶颈。例如,通过分析磁盘使用率的增长趋势,预测何时需要扩容。 - AIOps
人工智能在IT运维监控中的应用,例如智能告警、自动化根因分析等。
IT运维监控已经从简单的故障检测,发展到涵盖性能优化、自动化运维、智能分析的综合性体系。随着云原生、可观测性和AIOps的普及,IT运维监控将变得更加智能和高效。


















 387
387

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









