







线程
进程与线程
进程
概念: 一个正在进行的程序
一个程序在准备运行时,系统会为其开辟一片内存空间(运行内存)
线程
概念:程序的一条执行路径(一个程序可以有多条)
注意:
1,一个进程自带一个线程,该线程被称为主线程(main)
2,一个进程可以有多个线程,一个进程中如果有多个线程则称为多线程.
多线程
概念:一个进程中有多个线程
注意:
如果一个进程中有多个线程在运行,从宏观角度上来看
多个线程同时执行,从微观上考虑多个线程交替执行
线程的组成
CPU时间片
一个线程抢夺到CPU执行权后可以执行的时间
运行数据
一个线程拥有一个独立的栈
多个进程共享一个堆内存
代码逻辑
代码执行的顺序
线程的使用
创建
方案1:创建Thread的子类对象,并重写run方法
方式1:子类继承于Thread,并重写run方法,然后在使用的地方创建子类对象
情况1:
步骤
1,创建个类
public class MyThread{}
2,让该类继承与Thread
public class MyThread extends Thread{}
3,重写 run() 方法(run中的代码就是该线程执行的代码)
public class Mythread extends Thread{
public void run(){}
}
4,创建该类对象
public class Test{
public static void main(String[] args){
MyThread myThread = new MyThread();
}
}
情况2:
使用匿名内部类创建Thread的子类对象,并重写run方法
匿名内部类语法格式:
类名/接口名 对象名 = new 类名/接口名(){
要重写的方法
}
Thread thread = new Thread(){
public void run(){
}
}
方案2:将线程任务(Runnable)与线程(Thread)分开创建,在创建Thread对象时将Runnable对象当作参数传入Thread对象中
情况1:
步骤
1:创建线程任务对象
1.1:创建一个类
public class MyRunnable{
}
1.2:让该类实现Runnable接口
public class MyRunnable implements Runnable{
}
1.3:重写run方法
public class MyRunnable implements Runnable{
public void run(){
}
}
1.4:创建该类对象
public class Test{
public static void main(String[] args){
MyRunnable myRunnable = new MyRunnable();
}
}
2:创建线程对象,注意创建线程对象时传入线程任务对象
public class Test{
public static void main(String[] args){
MyRunnable myRunnable = new MyRunnable();
Thread thread = new Thread(myRunnable);
}
}
情况2:
步骤
1:创建线程任务对象,使用匿名内部类的形式创建
public class Test{
public static void main(String[] args){
Runnable runnbale = new Runnable(){
public void run(){
}
};
}
}
2:创建线程对象,注意创建线程对象时传入线程任务对象
public class Test{
public static void main(String[] args){
Runnable runnbale = new Runnable(){
public void run(){
}
};
Thread thread = new Thread(runnable);
}
}
注意:
1,Thread类与Runnable接口由JDK提供
启动
语法:
线程对象.start();
注意:一个线程只能启动一次
关闭
注意:
1,线程一旦被启动,无法控制
2,线程执行完run方法中的代码后,将进入到等待销毁状态
获取线程名称
给线程设置名字或获取线程名称
注意:一个线程有默认名,主线程的默认名为main,子线程默认名为Thread-xx
语法:
设置:
方式1,创建线程对象时设置
new Thread(线程名称);
new Thread(线程任务,线程名称);
方式2,使用线程对象调用setName方法
语法:
线程对象.setName(线程名称);
注意:
在线程启动前设置
获取
语法:
String 变量名 = 线程对象.getName();
如何获取当前线程对象
Thread thread = Thread.currentThread();
优先级
概念:增大或减小线程抢占CPU的优先级
语法:
线程对象.setPriority(优先级);
注意:
优先级取值范围:1~10
优先级默认为5
礼让
概念:在抢夺到CPU执行权后,释放CPU执行权,重新抢夺
语法:
线程对象.yield();
休眠
概念:让线程休眠,该线程在休眠期间不在抢夺CPU执行权
语法:
Thread.sleep(休眠时间);
或
线程对象.sleep(休眠时间);
注意:
1,单位是毫秒
2,该方法为静态方法,可用类名调用,且该方法中声明了异常,因此在使用时需要处理异常
合并
语法:
线程对象.join();
注意:
在线程A的run方法中使用线程对象B调用该方法,表示将B对应的线程中的run方法中没有执行完的代码合并到线程A中
守护线程与前台线程
前台线程:
线程创建时默认就是前台线程
如果一个进程中有前台线程存活,那么该进程将不会被系统所回收
守护线程:
别名:后台线程
如果一个进程中所有的前台线程都被销毁了,进程也将被销毁.此时如果进程中还有守护线程未执行完,那么该守护线程依旧会被销毁
如何设置一个线程为守护线程:
语法:
线程对象.setDaemon(true);
注意:
必须在线程启动前设置守护线程,否则一旦线程启动则不能对该线程设置守护线程
判断该线程是否为守护线程:
语法:
线程对象.isDaemon()
返回类型为boolean类型,true则是守护线程,否则不是
*线程的状态

创建:使用new关键字创建线程后,调用start之前
就绪:调用start之后,还未抢占到cpu执行权时
运行:抢占到cpu执行权后
休眠:调用sleep或wait之后
销毁:run方法执行完毕后
线程安全
原因
多个线程同时操作一个数据时,会导致数据不安全
如数据重复,错乱等问题
名词介绍
同步:同时只能备一条线程执行(线程安全)
异步:同时可被多条线程执行(线程不安全)
实现线程安全的方法
思路:保证同时只能有一条线程在操作数据(即实现同步),并且锁对象是同一个
为什么要使用同步?
因为多个线程操作同一个数据,会导致数据不安全,出现错乱的数据(如重复数据或负数)
方案1:同步代码块
语法:
synchronized (锁对象) {
要同步的代码
}
注意:
锁对象:任何一个类的对象都可以作为锁对象,因此此处的锁对象可以由我们自由指定;但是为了保证同时只能有一个线程操作,所以要保证多个线程的锁对象为同一个对象
方案2:同步方法
语法:
访问权限修饰符 synchronized 返回值类型 方法名(形参列表){
方法体
return 返回值;
}
注意:
锁对象:谁调用同步方法,谁就是锁对象
方案3:同步静态方法
语法:
访问权限修饰符 static synchronized 返回值类型 方法名(形参列表){
方法体
return 返回值;
}
注意:
锁对象:该类的类对象(类对象的获取 类名.class 和 对象名.getClass())
死锁
死锁的产生
多个线程互相持有对方所需的锁资源
死锁的表现
程序无法继续向下执行,也没有关闭,而且多个线程还在抢夺CPU执行权,但是抢到执行权后仍无法执行剩余的代码。
如何避免死锁
尽量不要再同步中使用同步
如:
尽量不要再同步代码块中使用同步方法或同步代码块
尽量不要再同步方法中使用同步方法或同步代码块
使用同步要注意什么?
1,分析需要加同步的地方
2,保证锁对象是同一个对象
3,避免死锁
线程的休眠和唤醒(sleep和wait)
休眠
有限期休眠:sleep,wait
无限期休眠:wait
sleep与wait的区别
相同点:
都可以让线程进行休眠
不同点:
sleep
使用sleep进行休眠,不会释放锁资源
sleep方法属于Thread类提供的静态方法
sleep可以在任何一处使用
只能使用Thread类名或Thread对象调用
wait
使用wait进行休眠,会释放锁对象
wait方法属于Object类提供的方法
wait方法在只能在同步方法或同步代码块中使用
只能使用该同步方法或该同步代码块的锁对象调用
wait方法后没有参数,表示无限期休眠
唤醒
方法:
notify
notifyAll
notify合notifyAll的区别:
相同点:
两个方法都是Object类提供的普通方法,可以使用任何一个类的对象进行调用
只能在同步中使用,并且调用该方法的对象必须是该同步锁对象
不同点:
notify一次只能随机唤醒一个使用调用该方法的对象作为锁对象的线程
notifyAll一次唤醒所有使用调用该方法的对象作为锁对象的线程
生产者与消费者模式
原理:
在一个系统中,存在生产者和消费者两种角色,他们通过内存缓冲区进行通信,生产者生产消费者需要的资料,消费者把资料做成产品。
生活中出现的情况:
情况1,生产的商品过多,导致库房无法存储,此时应该停止生产,等待消费
情况2,消费太快,导致库房中没有商品,此时应该停止消费,等待生产
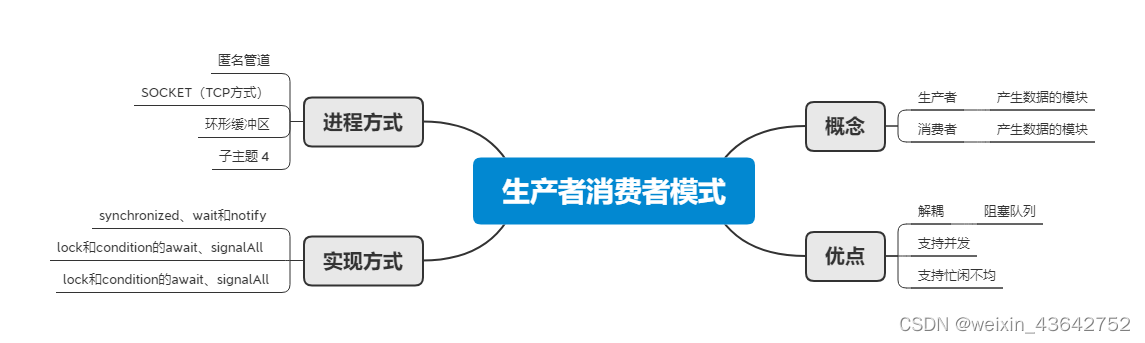
图片来源自设计模式——生产者消费者模式
该文对消费者、生产者模式将的较为全面,建议看看
线程优化
优化的原因
一个线程在存活时大约占1mb的运行内存
线程在使用完成后,需要等待GC回收
此时因为大量的没有被回收的线程占据着内存
这些未被回收的线程将会导致程序运行效率降低,甚至出现内存溢出的情况
线程优化的思路
1,控制创建线程的数量
2,尽量使用空闲的线程,去执行新的任务(线程的复用)
3,当线程处于空闲状态,如果可以被回收,那么就回收
jdk提供了这个思路的工具
这个工具就是线程池
线程池:Executor
简述
一个用以管理线程的容器,包含线程的创建,复用与回收
优点
1,使用线程池以后不用在考虑线程的创建,复用,回收等问题.只需关注线程任务即可
2,节省运行内存,提高代码的执行效率
3,无需频繁的创建与销毁线程
体系
Executor(接口)
子接口:
ExecutorService(接口)
方法:
shutdown() :关闭线程池
submit():提交线程任务给线程池
子类:
ThreadPoolExecutor
...
子接口:
ScheduledExecutorService:调度线程池
注意:
因为Executor和ExecutorService都是接口无法直接创建对象
而ThreadPoolExecutor创建对象的过程较为复杂
所以JDK提供了一个工具类,便于我们创建线程池对象
这个工具类就是Executors
线程池获取的工具类:Executors
优点
更为简单便捷的获取线程池对象
获取线程池
固定线程池
作用:获取一个线程数量恒定的线程池
方法:
public static ExecutorService newFixedThreadPool(线程数量)
可变线程池
作用:获取线程数量不固定的线程池,其中线程的数量根据任务的数量决定
方法:
public static ExecutorService newCachedThreadPool()
单例线程池
作用:获取一个调度线程池
方法:
public static ScheduleExecutorService
newSingleThreadExecutor(int corePoolSize)
调度线程池
作用:获取一个调度线程池
方法:
public static ScheduledExecutorService newScheduledThreadPool()
单例调度线程池
作用:获取一个只有一个线程的调度线程池,如果该线程池中有多个任务则任务按照先后顺序执行
方法:
public static ScheduleExecutorService newSingleThreadScheduleExecutor()
抢占线程池
作用:获取一个抢占线程池
方法:
public static ExecytorService newWorkSteaLingPool()
特点:
1,jdk1.8出现
2,该线程池中有一个算法,叫做窃取算法.该算法的优点将任务平分下去,当该线程中一个线程执行完自己的任务后,会帮助还没有完成任务的线程.从而提高线程任务的执行效率
3,该线程池的线程都是守护线程,所以当进程中所有前台都被销毁后,不论该线程池中的线程是否执行完毕,该线程池中的所有线程都会被销毁,该线程池也会被销毁
4,该线程池如果被关闭,也需等待其中任务执行完毕后才会关闭线程池.前提时在该线程执行线程任务时,有别的前台线程存活
调度线程池的特点及其特有方法
调度线程池:ScheduledExecutorService
特点:
1,属于ExecutorService的子接口
2,拥有特有方法,这些方法主要用以调度线程
3,可延迟,重复执行线程任务
特有方法:
schedule:延迟多长时间后在执行任务
scheduleAtFixedRate:延迟多长时间后在执行任务,间隔多长后重复执行
间隔时间:前一次任务开始时间至本次任务开始时间
注意:
如果代码执行时间超过间隔时间,那么下次任务执行将会在上一次任务执行完毕后,直接执行
scheduleWithFixedDelay:延迟多长时间后在执行任务,间隔多长后重复执行
间隔时间:前一次任务结束时间至本次任务开始时间
线程池: ThreadPoolExecutor类
概念:可变线程池,固定线程,单例线程池获取到的线程池对象,本质就是获取ThreadPoolExecutor的对象
因为在阿里白皮书中说过,为了深入理解线程池,建议所有开发人员使用ThreadPoolExecutor创建线程池对象
构造函数:
ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
1参corePoolSize:核心线程数量,线程池中最小线程数量
2参maximumPoolSize:线程池中最大线程数量
3参keepAliveTime:当非核心线程闲置多长时间后会被系统回收
4参unit:时间单位
5参workQueue:存储线程池执行的任务的集合
6参threadFactory:线程工厂,在线程池中创建线程
7参handler:当线程池中线程任务多余线程时的策略
线程任务优化
原因
因为Runnable 在执完线程任务后,无法返回数据,所以需要对其优化
Callable
callable与Thread结合使用
步骤:
1,创建Callable接口的子类对象
2,创建FutureTask对象,并传入Callable的子类对象
3,创建线程对象,并传入FutureTask对象
4,启动线程
5,使用FutureTask对象调用get方法,获取Callable中call方法的返回值
注意:
get方法会阻塞程序的运行
阻塞到call方法执行完毕,拿到返回值才可以
Callable与线程池结合使用
步骤:
1,创建线程池对象
2,提交线程任务给线程池,并获取其返回值
3,关闭线程池
4,注意步骤2的返回值调用get()方法,获取call方法的返回值
注意:
如果步骤2中传入的线程任务是Runnable对象,那么没有步骤4
如果步骤2中传入的线程任务是Callable对象,那么就可以选择使用步骤4
锁的优化
原因
因为在使用synchronized时,发现不是很方使用
所以对其进行优化
Lock
体系
Lock(接口)
方法:
lock:关闭锁
unlock:释放锁
子类:
ReentrantLock:重入锁
重入锁也叫做递归锁,指的是同一线程 外层函数获得锁之后 ,内层递归函数仍然有获取该锁的代码,但不受影响。
ReentrantReadWriteLock:
方法:
readLock:提供一个Lock对象(读的锁对象)
writeLock:提供一个Lock对象(写的锁对象)
读的锁对象与读的锁对象互不干扰
写的锁对象与写的锁对象互斥
读的锁对象与写的锁对象互斥
读锁使用共享模式;写锁使用独占模式;读锁可以在没有写锁的时候被多个线程同时持有,写锁是独占的。当有读锁时,写锁就不能获得;而当有写锁时,除了获得写锁的这个线程可以获得读锁外,其他线程不能获得读锁















 615
615











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









