







VScode突然就进不去了,然而昨天晚上还用的好好的。可能是今天安装的某些软件起了冲突,或者是病毒?不管了,先尝试解决问题。
打开报错信息如下
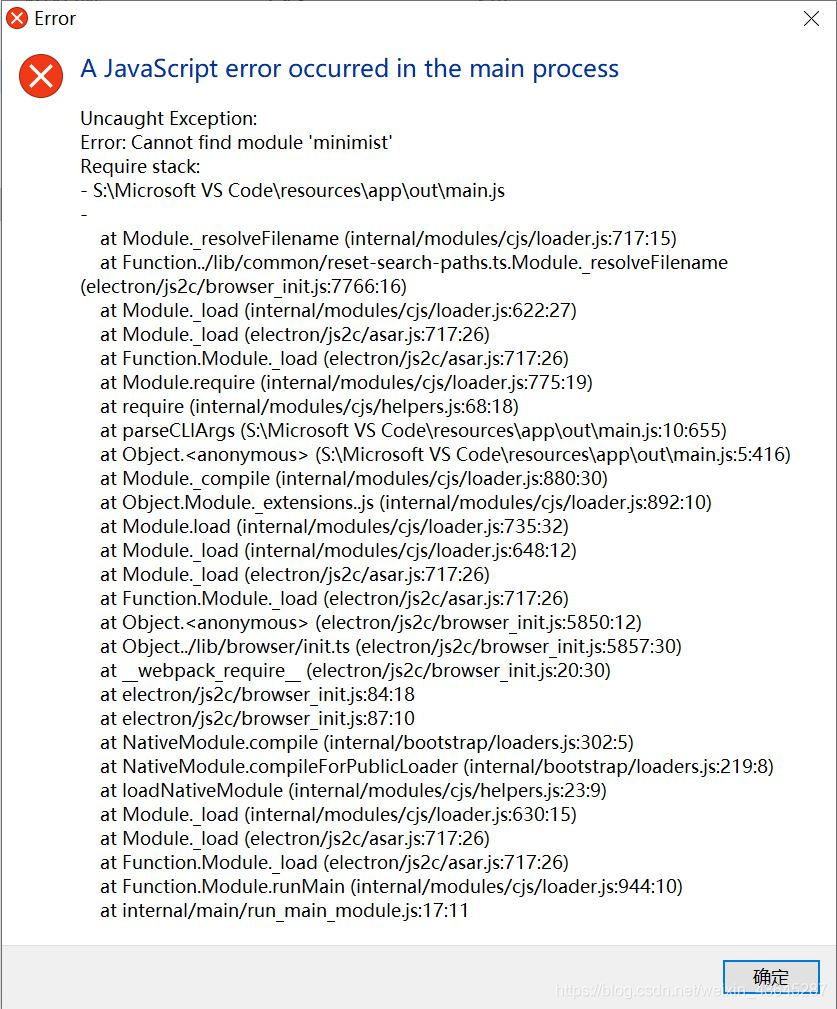
百度还没有直接的解决方法,但是VScode毕竟是很牛逼的工具不会无故出现这个情况。
解决方案
- 知乎搜索了说是部分文件问题
删除C:\Users\CuiQinPro\AppData\Roaming\Code目录,并未解决 - 不过一想也是,我这个明显是缺少了某module,我也不知道这软件的源码module安装位置。最保险的方式是覆盖安装:在官网下一个新的安装在原来的位置。
- 如果覆盖安装时无法安装,检查一下任务管理器是不是出现了下图情况
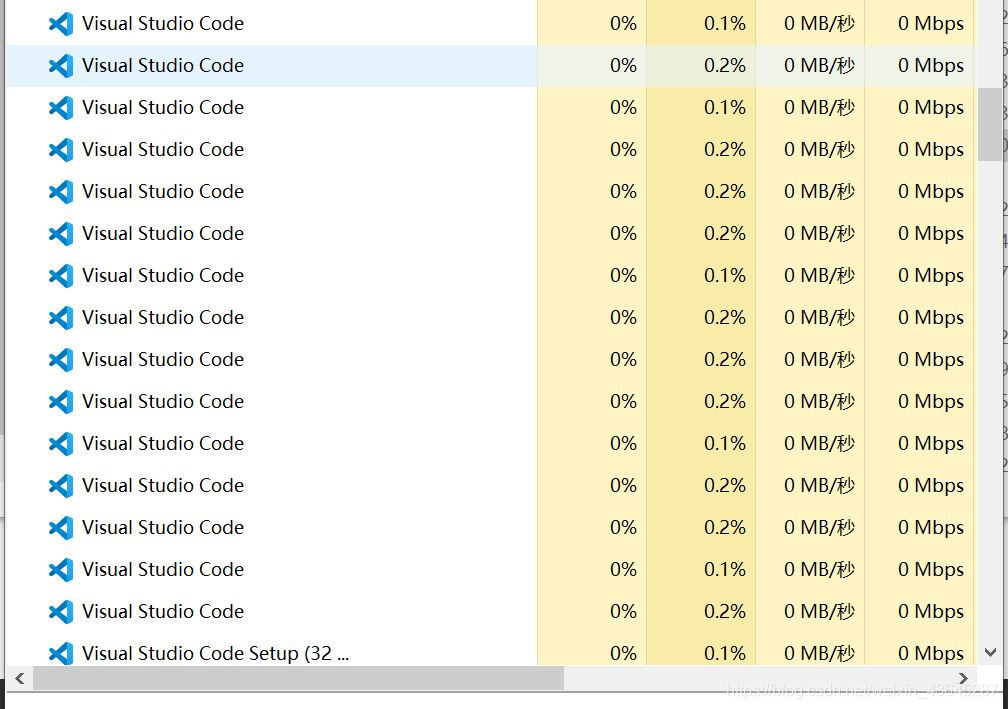
- 无语了,从下到上依次关闭进程后可继续安装,覆盖安装以后成功解决无法打开的上述问题,最重要的是原来的插件并不会被删除。

















 6437
6437

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









