








部署Kubernetes V1.24 集群
环境配置
基础环境配置
| IP地址 | 主机名 | 配置 |
|---|---|---|
192.168.117.251 | server1 | 4C4G |
192.168.117.252 | server2 | 4C4G |
192.168.117.253 | server3 | 4C4G |
系统信息
| 名称 | 版本 |
|---|---|
| 操作系统 | Ubuntu 20.04.4 LTS |
| 内核 | 5.4.0-110-generic |
集群部署环境准备
Kubernetes Documentation | Kubernetes
Kubernets官方文档
Kubernets官方安装文档
根据官网文档,在安装开始之前需要的是:
-
一台兼容的 Linux 主机。Kubernetes 项目为基于 Debian 和 Red Hat 的 Linux 发行版以及一些不提供包管理器的发行版提供通用的指令
-
每台机器 2 GB 或更多的 RAM (如果少于这个数字将会影响你应用的运行内存)
-
2 核CPU或更多
-
节点之中不可以有重复的主机名、MAC 地址或 product_uuid
-
-
禁用交换分区为了保证 kubelet 正常工作,你 必须 禁用交换分区
-
集群中的所有机器的网络彼此均能相互连接(公网和内网都可以)
-
查看主机名、MAC地址和product_uuid
- 你可以使用命令
ip link或ifconfig -a来获取网络接口的 MAC 地址 - 可以使用
sudo cat /sys/class/dmi/id/product_uuid命令对 product_uuid 校验
一般来讲,硬件设备会拥有唯一的地址,但是有些虚拟机的地址可能会重复。 Kubernetes 使用这些值来唯一确定集群中的节点。 如果这些值在每个节点上不唯一,可能会导致安装 失败。
"主机server1" root@server1:~# ip link 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000 link/ether 00:0c:29:92:2a:c6 brd ff:ff:ff:ff:ff:ff root@server1:~# cat /sys/class/dmi/id/product_uuid 780d4d56-d661-17cb-8aa5-dca7d7922ac6"主机server2" root@server2:~# ip link 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000 link/ether 00:0c:29:ca:f7:b2 brd ff:ff:ff:ff:ff:ff root@server2:~# cat /sys/class/dmi/id/product_uuid 3ff54d56-e1b0-b8dc-54fa-99333acaf7b2"主机Server3" root@server3:~# ip link 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000 link/ether 00:0c:29:4e:3f:d4 brd ff:ff:ff:ff:ff:ff root@server3:~# cat /sys/class/dmi/id/product_uuid 9d324d56-f4c9-83cf-7030-eb64ce4e3fd4 - 你可以使用命令
-
放行端口
"所有主机" systemctl stop ufw.service && systemctl disable ufw.service #采用关闭防火墙 放行所有 -
禁用交换分区
"所有主机" echo "vm.swappiness=0" >> /etc/sysctl.conf sysctl -p #表示禁止使用swap分区,只有当内存或硬盘不够用的时候才会使用这个分区,否则不会去使用。 #将swap开机自动挂载禁用 vim /etc/fstab # /swap.img none swap sw 0 0、 #临时关闭 查看swap分区大小 swapoff -a free -m total used free shared buff/cache available Mem: 3901 312 2917 1 671 3339 Swap: 0 0 0 -
hosts文件 域名通信
"所有主机" vim /etc/hosts 192.168.117.251 server1 192.168.117.252 server2 192.168.117.253 server3 #添加对应IP
转发IPv4并让iptabel转发桥接流量
通过运行lsmod | grep br_netfilter来验证是否加载br_netfilter 模块
要加载它需要执行sudo modprobe br_netfilter
为了使Linux节点的iptables能够正确查看桥接流量,请在配置中验证是否将其设置为1。
"all server"
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
overlay
br_netfilter
EOF
sudo modprobe overlay
sudo modprobe br_netfilter
# 验证模块是否加载
lsmod | grep br_netfilter
lsmod | grep overlay
# 安装程序需要sysctl参数,参数在重新启动期间保持不变
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF
# 无需重新启动即可应用sysctl参数
sudo sysctl --system
在kunbernetes官网中有这么一段话:
注意:Docker引擎没有实现CRI,这是容器运行时与Kubernetes一起工作所必需的。因此,必须安装额外的服务cri dockerd。cri Docker是一个基于遗留内置Docker引擎支持的项目,该支持在版本1.24中从kubelet中删除。
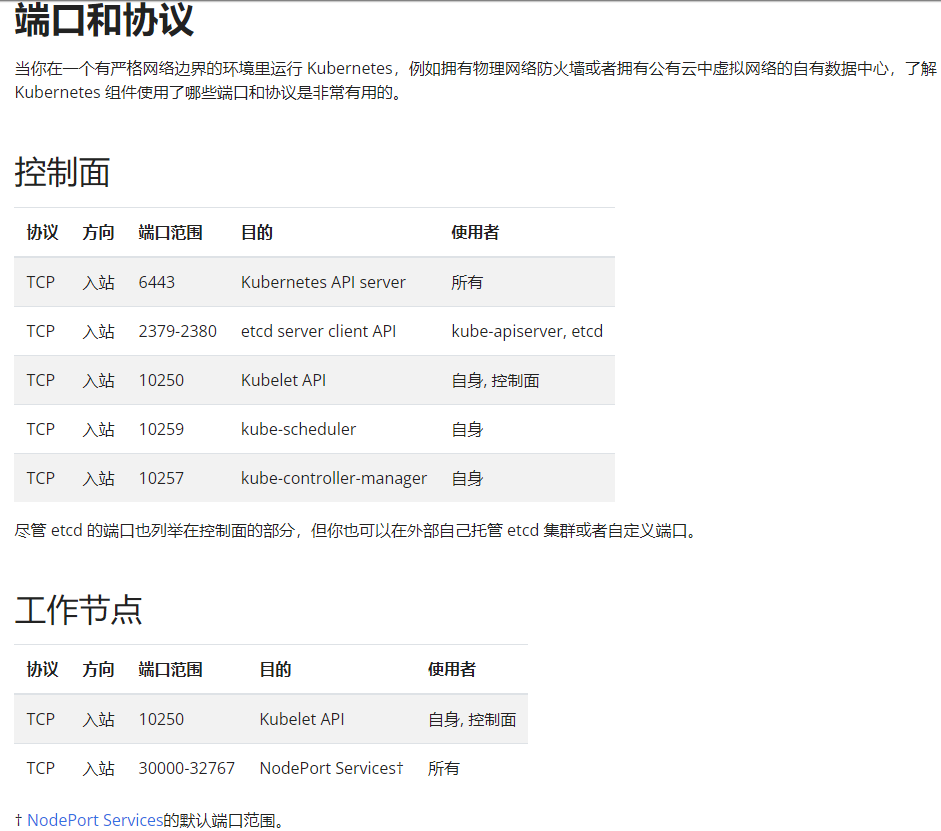
早期的kunbernetes在使用docker调用容器运行时的时候,docker并不能原生的支持kunbernetes,因此在kunbernetes需要维护一个docker shim的服务对docker的api进行调用。为了支持更多的容器运行时的工具kunbernetes在1.24版本将其移除。
早期kunbernetes调用docker流程:
- 用户通过kube-apiserver,调用命令创建/删除容器
- kubelet通过CRI(Container Runtime Interface/容器运行时接口)无法直接调用docker的容器运行的环境。只能通过访问docker shim这个桥接服务与docker API进行通讯创建/删除容器
docker shim: kubernetes通过CRI与容器进行时通信,而Docker不支持CRI,因此需要在CRI与Docker之间添加一个桥接服务docker-shim进行转换,实现CRI与docker API的通信。
容器运行时:容器运行时就是容器运行的环境
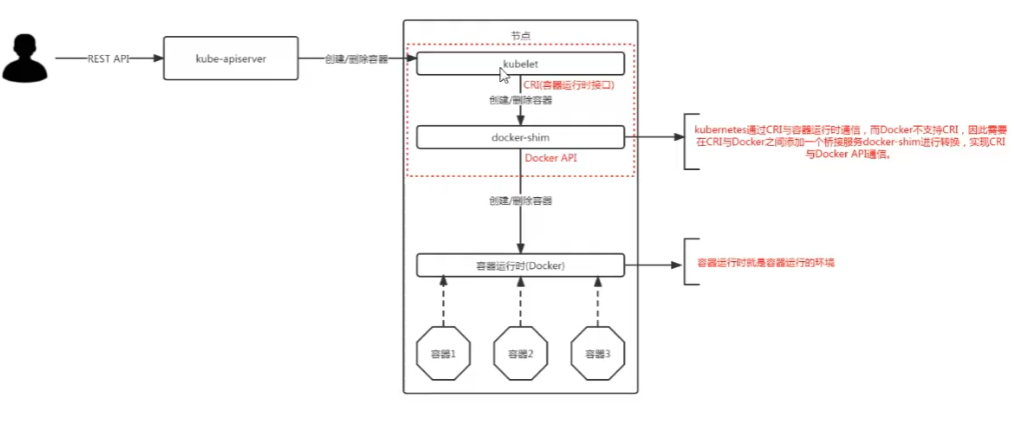
因为早期kunbernetes团队将docker shim集成到kunbernetes中,并对其进行维护。但现在由于有了更多的容器进行时后。不可能单独为dockershim进行维护,所以将其移除为了ci-dockerd。现在我们需要调用docker作为容器的话,必须要额外部署ci-dockerd这个服务。
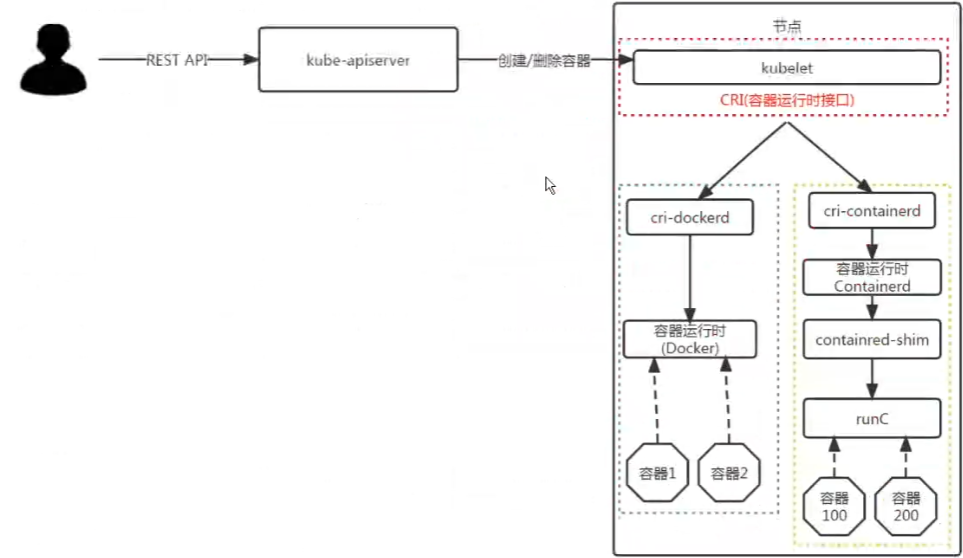
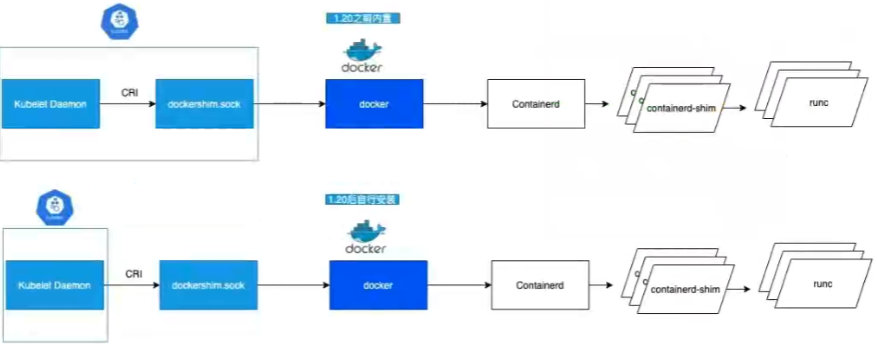
安装容器运行时
为了在 Pod 中运行容器,Kubernetes 使用容器运行时(负责运行容器的软件)。
默认情况下,Kubernetes 使用容器运行时接口(CRI 用于容器运行时与kubelet集成的API) 与所选容器运行时交互。
如果未指定运行时,kubeadm 会自动尝试通过扫描已知端点列表来检测已安装的容器运行时。
如果检测到多个容器运行时或未检测到容器运行时,kubeadm 将引发错误,并要求您指定要使用的容器运行时。
有关详细信息请参阅容器运行时。
**注意:**Docker 引擎不实现 CRI,CRI 是容器运行时与 Kubernetes 配合使用的要求。因此,必须安装一个附加的服务 cri-dockerd。cri-dockerd 是一个基于旧版内置 Docker 引擎支持的项目该支持在 1.24 版中从 kubelet 中删除。
下表包括支持的操作系统的已知容器运行时端点:
Linux:
Runtime Path to Unix domain socket(Unix套接字路径) containerdunix:///var/run/containerd/containerd.sockCRI-Ounix:///var/run/crio/crio.sockDocker Engine (using cri-dockerd)unix:///var/run/cri-dockerd.sock
containerd/getting-started.md at main · containerd/containerd (github.com)
Install Docker Engine on Debian | Docker Documentation
这里一直跳,真的很烦人诶。最终竟然跳到了docker engine的安装文档。其实就是配置docker的镜像源,然后安装containerd.io软件包
我把跳转的网址也都写下来,可以帮助理解
这里直接使用阿里云的docker-ce镜像即可😄
docker-ce镜像-docker-ce下载地址-docker-ce安装教程-阿里巴巴开源镜像站 (aliyun.com)
安装containerd容器进行时
-
安装一些必要的系统工具
"all server" sudo apt-get update sudo apt-get -y install apt-transport-https ca-certificates curl software-properties-common' -
安装GPG证书
"all server" curl -fsSL https://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo apt-key add - -
写入软件源信息
"all server" sudo add-apt-repository "deb [arch=amd64] https://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable" -
安装containerd.io
"all server" sudo apt-get install containerd.io -
安装指定版本的containerd.io(可选)
"all server" sudo apt-cache madison containerd.io #查看版本列表 containerd.io | 1.6.4-1 | https://mirrors.aliyun.com/docker-ce/linux/ubuntu focal/stable amd64 Packages containerd.io | 1.5.11-1 | https://mirrors.aliyun.com/docker-ce/linux/ubuntu focal/stable amd64 Packages containerd.io | 1.5.10-1 | https://mirrors.aliyun.com/docker-ce/linux/ubuntu focal/stable amd64 Packages"all server" #使用第二列中的版本字符串安装特定版本 sudo apt-get install containerd.io=<VERSION_STRING> -
查看uninx套接字路径
"all server" ls /run/containerd/containerd.sock /run/containerd/containerd.sock
安装ipset及ipvsadm
Kubernetes在V1.10,V1.11版本支持基于ipvs的kube-proxy的代理模式,这种代理模式比iptabels的代理模式要更加优秀
- ipvs使用的ipset是一种ip集合的一种方式来处理流量
- ipvs支持调度算法
什么是 IPVS ?
IPVS (IP Virtual Server)是在 Netfilter 上层构建的,并作为 Linux 内核的一部分,实现传输层负载均衡。
IPVS 集成在 LVS(Linux Virtual Server,Linux 虚拟服务器)中,它在主机上运行,并在物理服务器集群前作为负载均衡器。IPVS 可以将基于 TCP 和 UDP 服务的请求定向到真实服务器,并使真实服务器的服务在单个IP地址上显示为虚拟服务。 因此,IPVS 自然支持 Kubernetes 服务
为什么为 Kubernetes 选择 IPVS ?
Kube-proxy 是服务路由的构建块,它依赖于经过强化攻击的 iptables 来实现支持核心的服务类型,如 ClusterIP 和 NodePort。 但是,iptables 难以扩展到成千上万的服务,因为它纯粹是为防火墙而设计的,并且基于内核规则列表。
一个例子是,在5000节点集群中使用 NodePort 服务,如果我们有2000个服务并且每个服务有10个 pod,这将在每个工作节点上至少产生20000个 iptable 记录,这可能使内核非常繁忙。
使用基于 IPVS 的集群内服务负载均衡可以为这种情况提供很多帮助。 IPVS 专门用于负载均衡,并使用更高效的数据结构(哈希表),允许几乎无限的规模扩张。
"all server"
apt install ipset ipvsadm -y
#安装ipset和ipvsadm
#ipvsadm可以实现:
#1. 使用命令添加基于TCP一些的集群服务
#2. 在集群中添加若干台后端真实服务器
#3. 实现同一客户端访问,调度器分配固定服务器
#4. 会使用ipvsadm实现规则的增、删、改
#5. 保存ipvsadm规则
#ipset是iptables的扩展
#允许你创建匹配整个地址sets(地址集合)的规则。而不像普通的iptables链是线性的存储和过滤
#ip集合存储在带索引的数据结构中,这种集合比较大也可以进行高效的查找。
"all server"
# 临时生效
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
# 永久生效
mkdir -p /etc/sysconfig/modules
cat > /etc/sysconfig/modules/ipvs.modules <<EOF
modprobe -- ip_vs
modprobe -- ip_vs_rr #rr轮询,依次分配。当一台主机获得最高优先级后,就会变为最低优先级
modprobe -- ip_vs_wrr #wrr轮询,设置权重值,在分配过程中优先配置权重值高的
modprobe -- ip_vs_sh #指定的hash 访问指定节点
modprobe -- nf_conntrack #网络跟踪 最多见的使用场景是 iptables 的 nat nat 根据转发规则修改IP包的源/目标地址,靠nf_conntrack的记录才能让返回的包能路由到发请求的机器。
EOF
#modprobe -- nf_conntrack_ipv4
chmod 755 /etc/sysconfig/modules/ipvs.modules
bash /etc/sysconfig/modules/ipvs.modules #执行加载内核模块
lsmod | grep -e ip_vs -e nf_conntrack #查看加载的ipvs和nf_conntrack模块
ERROR
配置ipvs时发生错误modprobe: FATAL: Module nf_conntrack_ipv4 not found.
是因为使用了高内核
在高版本内核已经把
modprobe -- nf_conntrack_ipv4替换为
modprobe -- nf_conntrack了
将containerd用作 CRI 运行时
containerd运行的步骤
生成containerd的配置文件
容器/获取主 started.md ·集装箱/集装箱式 (github.com)
containerd配置文件介绍
containerd/containerd-config.toml.5.md at main · containerd/containerd (github.com)
- 由于国内环境原因我们需要将
sandbox_image镜像源设置为阿里云google_containers镜像源
"all server"
#生成默认配置
containerd config default > /etc/containerd/config.toml
vim /etc/containerd/config.toml
45 [plugins."io.containerd.grpc.v1.cri"]
61 sandbox_image = "registry.aliyuncs.com/google_containers/pause:3.6"
#或者
sed -i "s#k8s.gcr.io/pause#registry.aliyuncs.com/google_containers/pause#g" /etc/containerd/config.toml
- 配置镜像加速地址
"all server"
#配置containerd镜像加速地址
[plugins."io.containerd.tracing.processor.v1.otlp"]
endpoint = "https://a8x1qfbv.mirror.aliyuncs.com"
insecure = false
protocol = ""
#使用的是镜像加速器服务,阿里云镜像站开通
[容器镜像服务 (aliyun.com)](https://cr.console.aliyun.com/cn- hangzhou/instances/mirrors)
containerd/docs at main · containerd/containerd (github.com)
containerd从v1.6.0开始支持OpenTelemetry跟踪。目前仅针对gRPC调用。看不懂,但是改到这里了
-
配置 cgroup 驱动程序
systemd🔗虽然 containerd 和 Kubernetes 默认使用旧版驱动程序来管理 cgroups,但建议在基于 systemd 的主机上使用该驱动程序,以符合 cgroup 的“单编写器”规则
"all server" vim /etc/containerd/config.toml [plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options] SystemdCgroup = true #或者 sed -i 's#SystemdCgroup = false#SystemdCgroup = true#g' /etc/containerd/config.toml -
应用所有更改后,重新启动containerd
"all server" systemctl restart containerd && systemctl enable containerd netstat -anput | grep containerd tcp 0 0 127.0.0.1:44607 0.0.0.0:* LISTEN 25280/containerd
现在只是安装了containerd,并未安装ctr命令行.所以无法与containerd命令行界面进行交互
可以选择现在进行单独安装
apt install ctr,也可以在安装完kublet后使用由kublet集成的ctr
安装 kubeadm、kubelet 和 kubectl
您将在所有计算机上安装以下软件包:
kubeadm:用于引导群集的命令。kubelet:在集群中的所有计算机上运行并执行启动 pod 和容器等操作的组件。kubectl:用于与集群通信的命令行实用程序。
kubeadm 不会为您安装或管理,因此您需要确保它们与您希望 kubeadm 为您安装的 Kubernetes 控制平面的版本相匹配。如果不这样做,则存在发生版本偏差的风险,这可能导致意外的错误行为。但是,支持 kubelet 和控制平面之间的一个次要版本偏差,但 kubelet 版本可能永远不会超过 API 服务器版本。例如,运行 1.7.0 的 kubelet 应该与 1.8.0 API 服务器完全兼容,但反之亦然。有关安装的信息,请参阅安装和设置 kubectl
使用阿里镜像站进行安装Kubernets
kubernetes镜像-kubernetes下载地址-kubernetes安装教程-阿里巴巴开源镜像站 (aliyun.com)
- 安装Kunbernets组件
"all server"
apt-get update && apt-get install -y apt-transport-https
curl https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | apt-key add -
cat <<EOF >/etc/apt/sources.list.d/kubernetes.list
deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main
EOF
apt-get update
apt-get install -y kubelet kubeadm kubectl
"all server"
sudo apt-cache madison [kubelet|kubeadm|kubectl] #查看版本列表
sudo apt-get install [kubelet|kubeadm|kubectl]= <VERSION_STRING>
- 配置命令补全
Linux 系统中的 bash 自动补全功能
[Linux 系统中的 bash 自动补全功能 kublet| Kubernetes] (https://kubernetes.io/zh/docs/tasks/tools/included/optional-kubectl-configs-bash-linux/)
[Kubernetes kubadm命令补全] (https://kubernetes.io/zh/docs/reference/setup-tools/kubeadm/generated/kubeadm_completion/)
"all server"
#临时生效
source <(kubectl completion bash)
source <(kubeadm completion bash)
source <(crictl completion bash)
#永久生效
echo 'source <(kubectl completion bash)' >>~/.bashrc
echo 'source <(kubeadm completion bash)' >>~/.bashrc
echo 'source <(crictl completion bash)' >>~/.bashrc
source /usr/share/bash-completion/bash_completion
source ~/.bashrc
- 配置crictl默认的containerd unix端点
root@server1:~# crictl image
WARN[0000] image connect using default endpoints: [unix:///var/run/dockershim.sock unix:///run/containerd/containerd.sock unix:///run/crio/crio.sock unix:///var/run/cri-dockerd.sock]. As the default settings are now deprecated, you should set the endpoint instead.
ERRO[0002] connect endpoint 'unix:///var/run/dockershim.sock', make sure you are running as root and the endpoint has been started: context deadline exceeded
IMAGE TAG IMAGE ID SIZE
[使用 crictl | 调试 Kubernetes 节点Kubernetes] (https://kubernetes.io/docs/tasks/debug/debug-cluster/crictl/#general-usage)
ERROR
这个错误需要指定
unix://套接字程序位置直接编写配置文件
/etc/crictl.yaml#写入 runtime-endpoint: unix:///run/containerd/containerd.sock image-endpoint: unix:///run/containerd/containerd.sock timeout: 10 debug: truecrictl images DEBU[0000] get image connection DEBU[0000] connect using endpoint 'unix:///run/containerd/containerd.sock' with '10s' timeout DEBU[0000] connected successfully using endpoint: unix:///run/containerd/containerd.sock DEBU[0000] ListImagesRequest: &ListImagesRequest{Filter:&ImageFilter{Image:&ImageSpec{Image:,Annotations:map[string]string{},},},} DEBU[0000] ListImagesResponse: &ListImagesResponse{Images:[]*Image{},}再次查看会输出DEBU,是连接超时。之后又会成功,这里不知道为什么,有的文章说镜像源的问题,我改了一下也没有结果。将超时时间延长也没用。这里不想看到的话就将
debug: true改为debug: fales
配置Kubernets集群
使用 kubeadm | 创建集群Kubernetes #更多信息
跳转顺序
- 初始化集群
"server1"
#打印用于kubeadm init的默认初始化配置为文件
kubeadm config print init-defaults > init.yaml
"server1"
#修改配置文件
12 advertiseAddress: 192.168.117.251 #修改为第一台主机的IP地址
17 name: server1 #主机的名称
30 imageRepository: registry.aliyuncs.com/google_containers
32 kubernetesVersion: 1.24.0 #安装的版本
35 serviceSubnet: 10.10.0.0/16 #分配的地址
kubeadm init --config=init.yaml
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
#执行安装完成后提示的命令
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
export KUBECONFIG=/etc/kubernetes/admin.conf
-
安装Kunbernets网络插件
You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/这里我们使用calico网络,不使用flannel网络,因为flannel网络没有隔离性,安全性不高。
Calico支持网络策略,根据网络策略进行路由的选择。
Calico是一家网络和网络策略提供商。Calico支持一组灵活的网络选项,因此您可以根据自己的情况选择最有效的选项,包括无覆盖网络和覆盖网络,无论有无BGP。Calico使用相同的引擎在服务网格层为主机、POD和(如果使用Istio和Envoy)应用程序实施网络策略。
Self-managed on-premises (tigera.io)
Install Calico networking and network policy for on-premises deployments (tigera.io)
跳转顺序
根据您的数据存储和节点数量,选择下面的链接以安装 Calico。
注意:Kubernetes API 数据存储选项超过 50 个节点,使用 Typha 守护程序提供扩展。etcd 不包含 Typha,因为 etcd 已经可以处理许多客户端,所以使用 Typha 是多余的,不建议这样做。
"server1" #下载 Kubernetes API 数据存储的 Calico 网络 curl https://projectcalico.docs.tigera.io/manifests/calico.yaml -O"server1" vim calico.yaml #修改 calico.yaml文件- name: CALICO_IPV4POOL_CIDR value: "10.10.0.0/16" #将其取消注释并修改为init.yaml 中定义的网段地址"server1" kubectl apply -f calico.yaml -
Node加入集群
Then you can join any number of worker nodes by running the following on each as root: kubeadm join 192.168.117.251:6443 --token abcdef.0123456789abcdef \ --discovery-token-ca-cert-hash sha256:f76fdb1684898e7d091d12e10fa59b5fb16bfd01ac5a386c58b29993b707b633"server2&server3" kubeadm join 192.168.117.251:6443 --token abcdef.0123456789abcdef \ --discovery-token-ca-cert-hash sha256:f76fdb1684898e7d091d12e10fa59b5fb16bfd01ac5a386c58b29993b707b633 --cri-socket=unix:///run/containerd/containerd.sock #这里需要指定容器运行时的socket路径 默认的话还是回去寻找dockershimkubectl get nodes NAME STATUS ROLES AGE VERSION server1 Ready control-plane 44m v1.24.0 server2 NotReady <none> 63s v1.24.0 server3 NotReady <none> 71s v1.24.0 #查看节点信息的话为NotReady 因为从节点需要下载calico镜像构建服务 kubectl get pod --all-namespaces NAMESPACE NAME READY STATUS RESTARTS AGE kube-system calico-kube-controllers-56cdb7c587-wr2v9 0/1 ContainerCreating 0 17m kube-system calico-node-drb2g 0/1 Init:1/2 0 2m10s kube-system calico-node-pf259 1/1 Running 0 17m kube-system calico-node-xtg75 0/1 PodInitializing 0 2m18s kube-system coredns-74586cf9b6-ct67s 1/1 Running 0 45m kube-system coredns-74586cf9b6-jwsvz 1/1 Running 0 45m kube-system etcd-server1 1/1 Running 0 45m kube-system kube-apiserver-server1 1/1 Running 0 45m kube-system kube-controller-manager-server1 1/1 Running 0 45m kube-system kube-proxy-8j4xs 1/1 Running 0 45m kube-system kube-proxy-kzm6c 1/1 Running 0 2m10s kube-system kube-proxy-vfp4k 1/1 Running 0 2m18s kube-system kube-scheduler-server1 1/1 Running 0 45m#加入集群成功 kubectl get nodes NAME STATUS ROLES AGE VERSION server1 Ready control-plane 46m v1.24.0 server2 Ready <none> 3m20s v1.24.0 server3 Ready <none> 3m28s v1.24.0














 468
468











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









