










前段时间参加了 2022中国高校计算机大赛 微信大数据挑战赛,比赛链接:https://algo.weixin.qq.com/。
由于时间原因精力有限,我们队伍的方案做的比较简陋:
【初赛:rank-18,复赛:rank-40(全国二等奖)】
🚀 我们已开源了我们队的初赛方案代码,可参见如下github链接,欢迎各位star一下,给个⭐,谢谢:
https://github.com/XFR1998/WBDC2022-Multimodal-Short-Video-Classification
简陋方案如下:
1、双流架构。roberta提取文本特征(title, asr, ocr)。swin-tiny和convnext-tiny分别提取视频特征,然后用concatDenseSE层融合。最后用3层cross-attention融合文本和视频特征。

2、其他一些常用比赛tricks:amp混合精度训练,EMA,FGM,SWA。
3、初赛用了单双流模型融合,复赛限制了QPS,所以没来得及弄模型加速。
4、预训练:复赛没时间搞哈哈哈。
5、模型加速优化,没弄,所以没法模型融合哈哈哈。
和前排的分数差距,主要在于:
1、没预训练,复赛翻车哈哈哈,要是用上了预训练的话,能有1-2个百分点提升。
2、没用CLIP-VIT(huggingface有现成可以用),这个可以涨2-3个百分点,所以我们队没用这个巨亏哈哈哈。
3、没搞模型加速优化,也就导致没法模型融合,看前排都融了好几个,融了的话,应该最多能提1个百分点吧。
4、如何合理进行伪标签制作,做好应该能涨几k。
下面对进入决赛的队伍方案做个总结,向大佬学习!!!
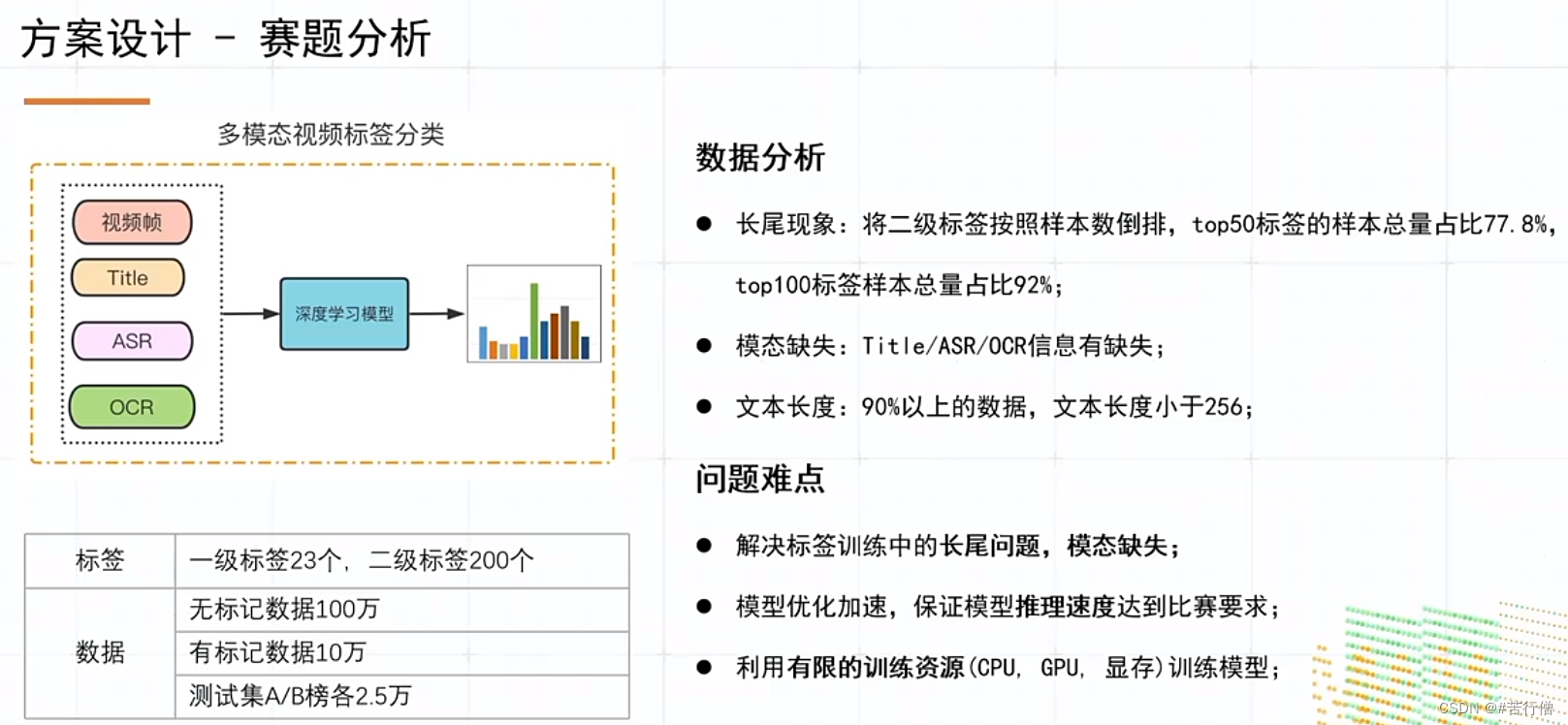
赛题任务-微信小视频分类(多模态任务):


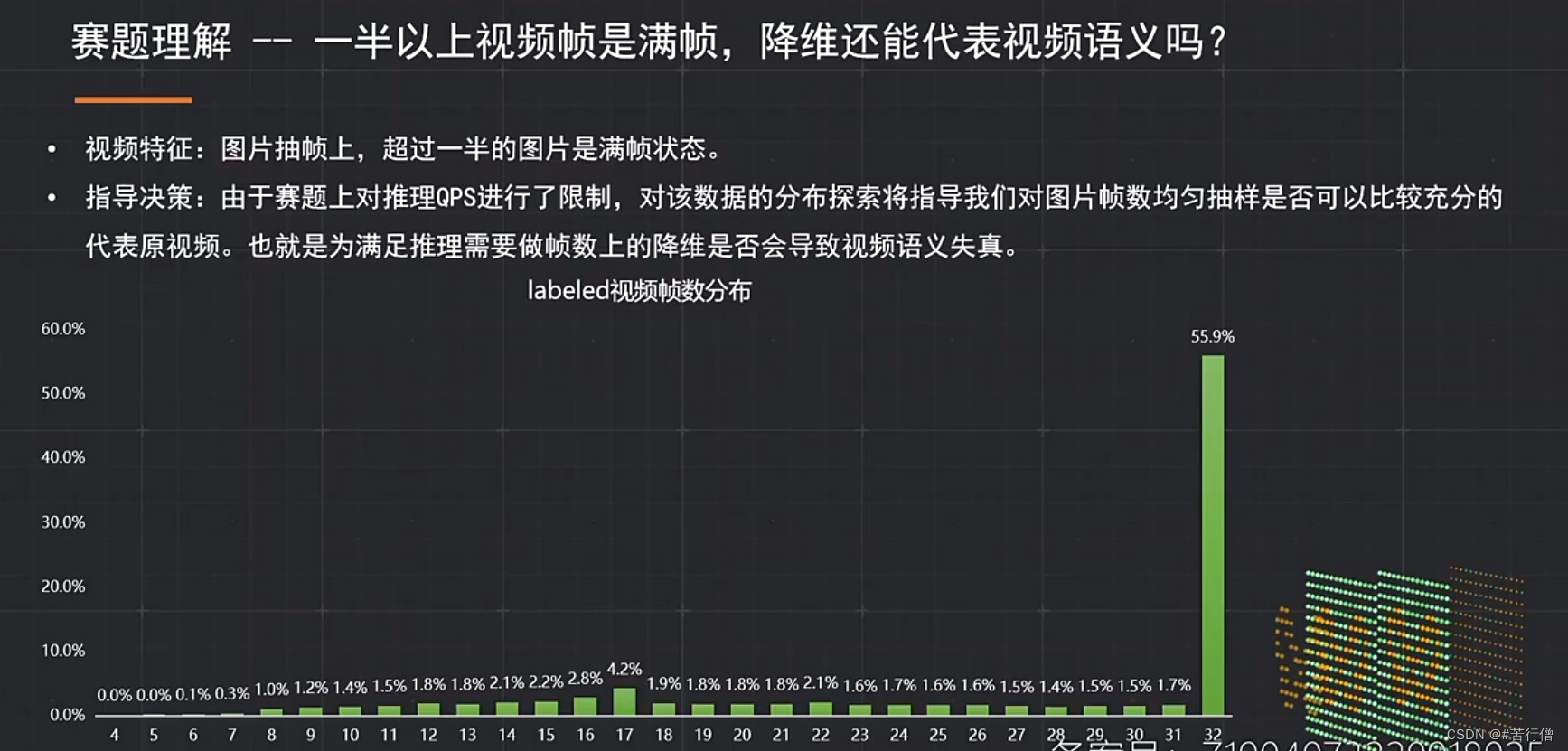
复赛QPS要求:


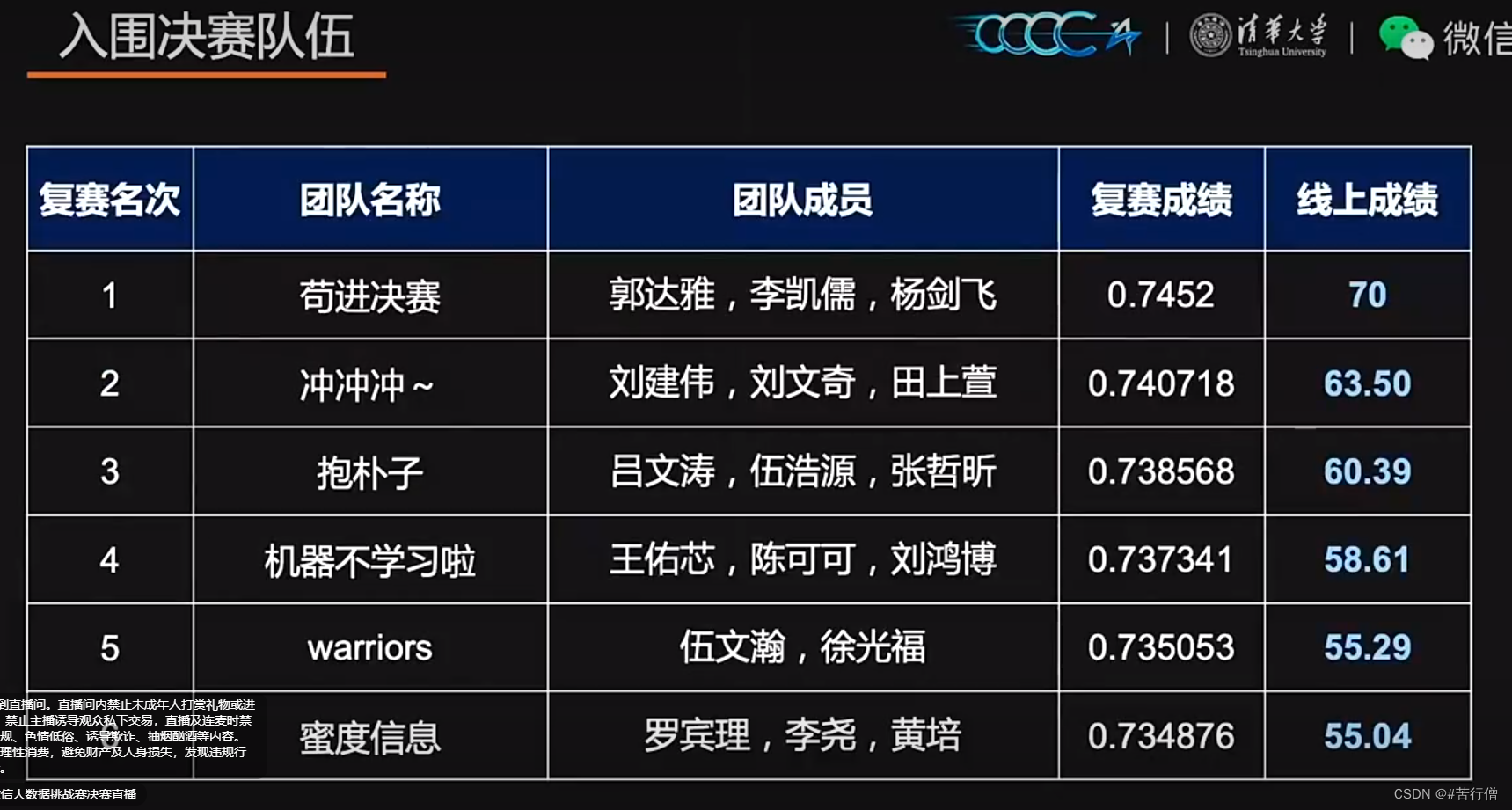
🚀Top 1-6 方案列表:
| 序号 | 队伍 |
|---|---|
| TOP1 | 苟进决赛 |
| TOP2 | 冲冲冲~ |
| TOP3 | 抱朴子 |
| TOP4 | 机器不学习啦 |
| TOP5 | warriors |
| TOP6 | 蜜度信息 |
TOP1-苟进决赛:
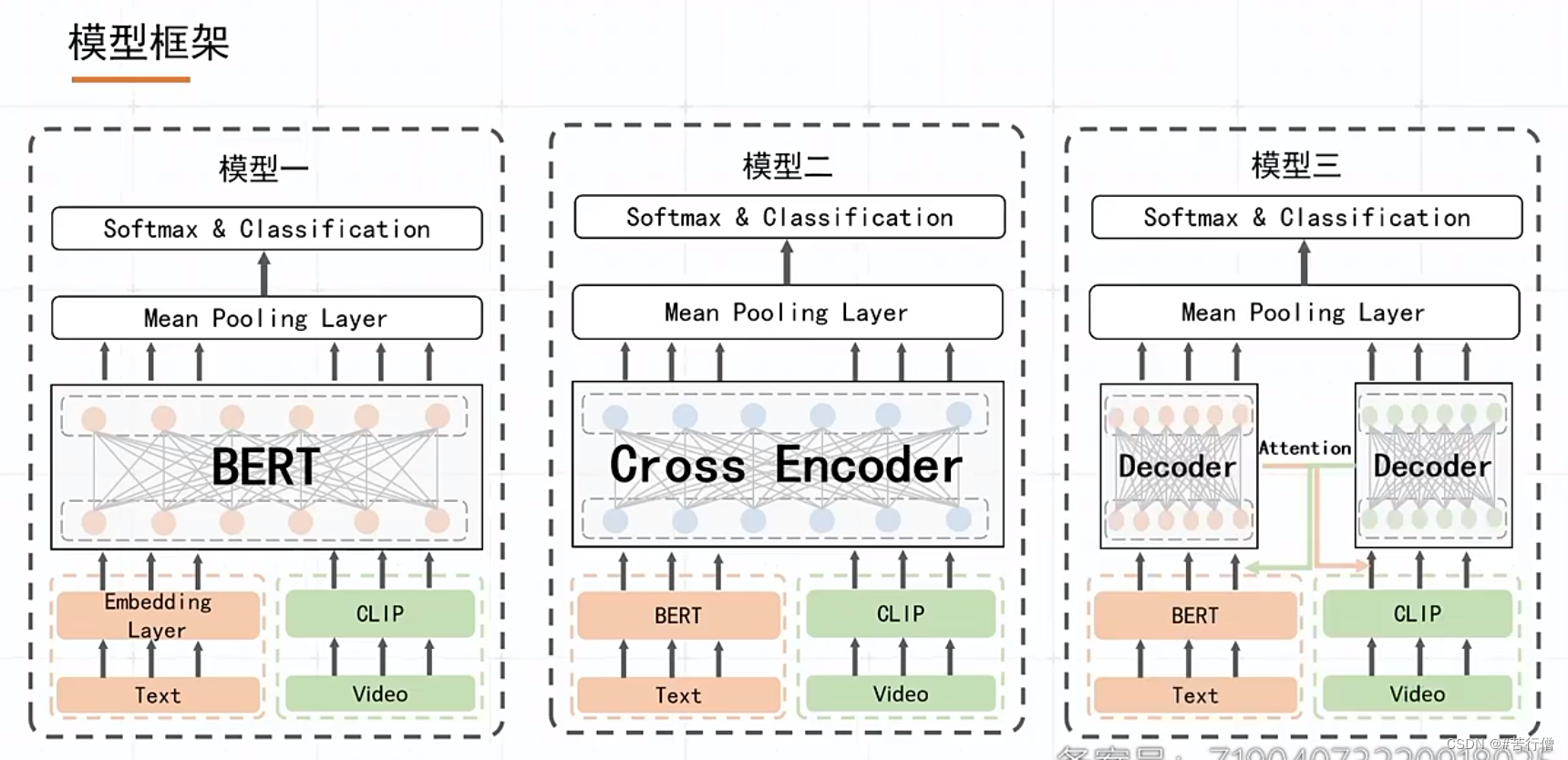
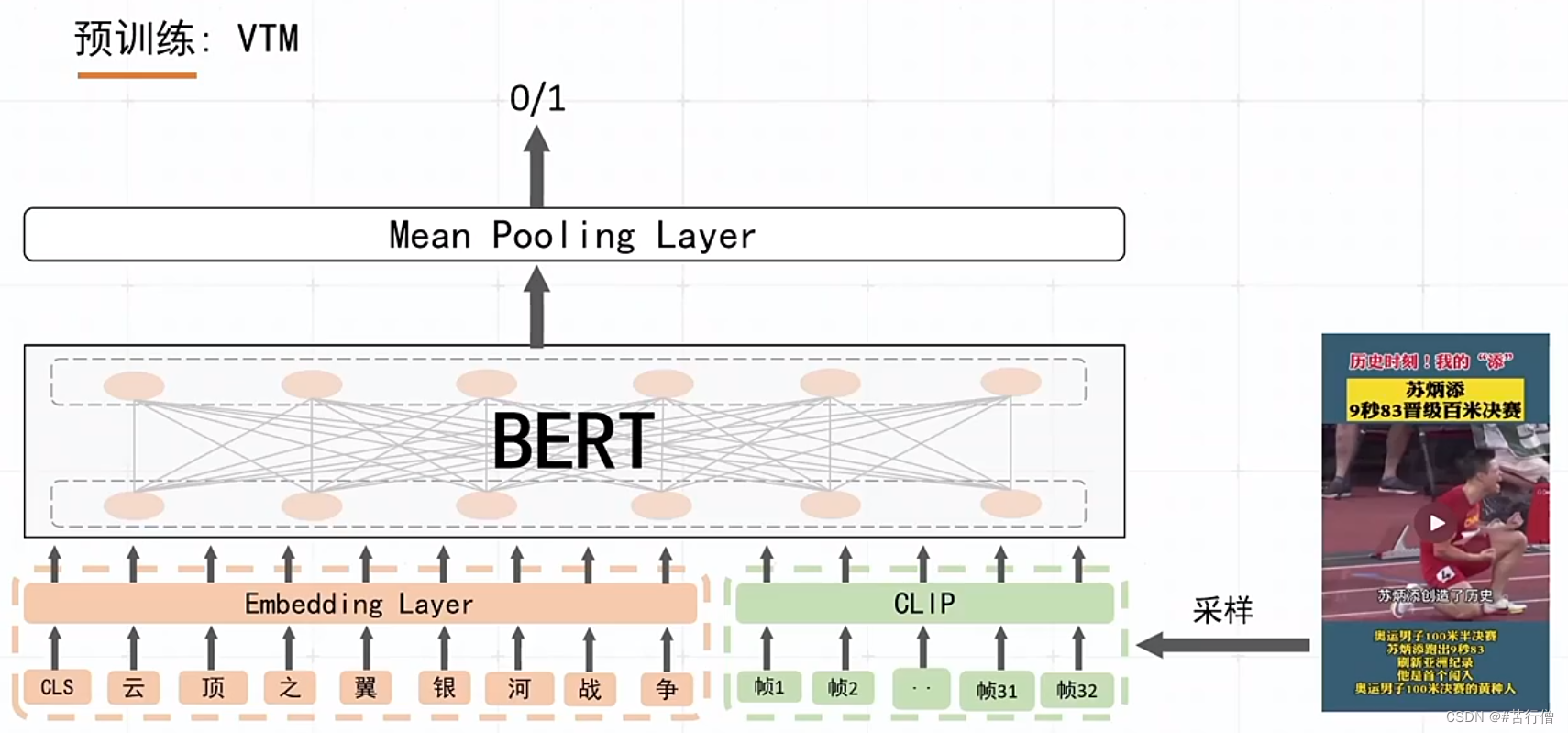
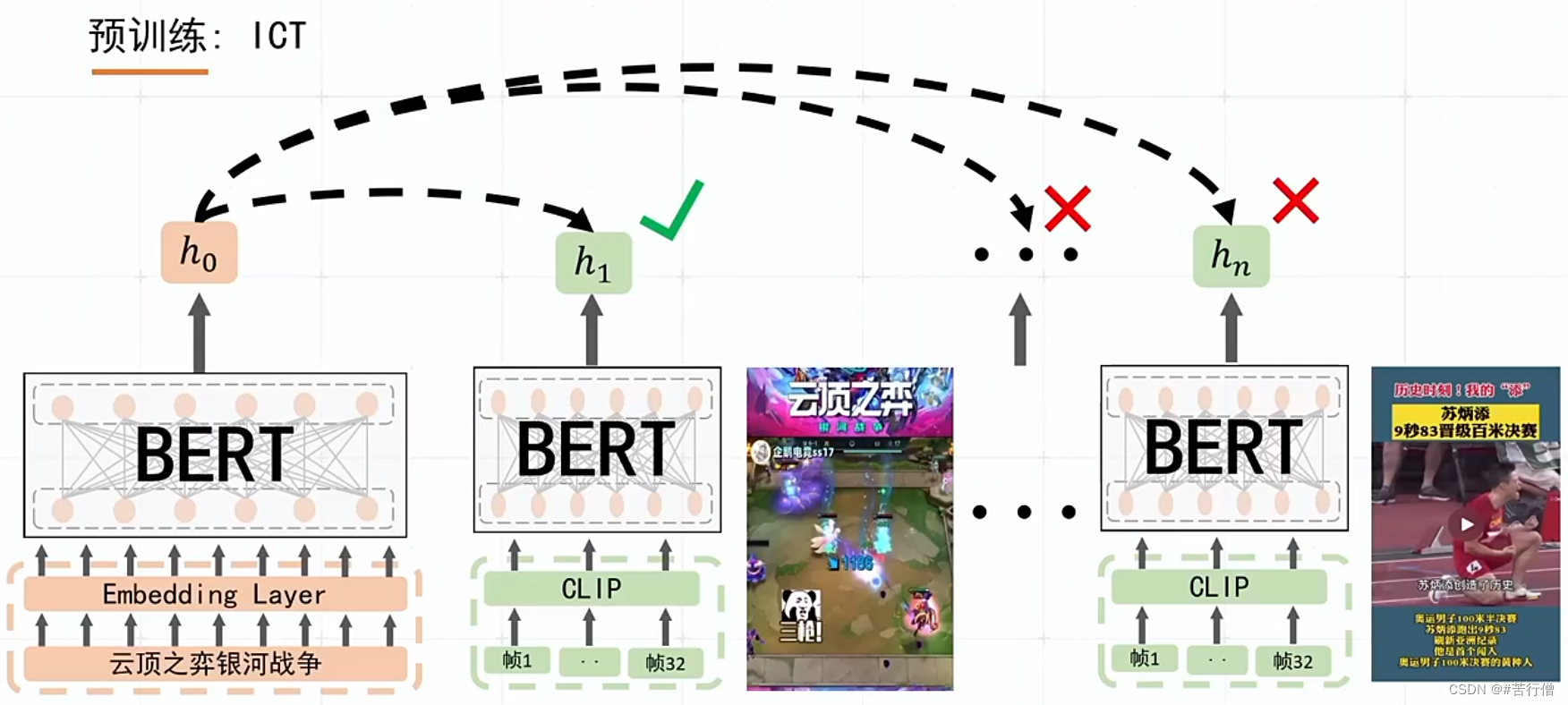
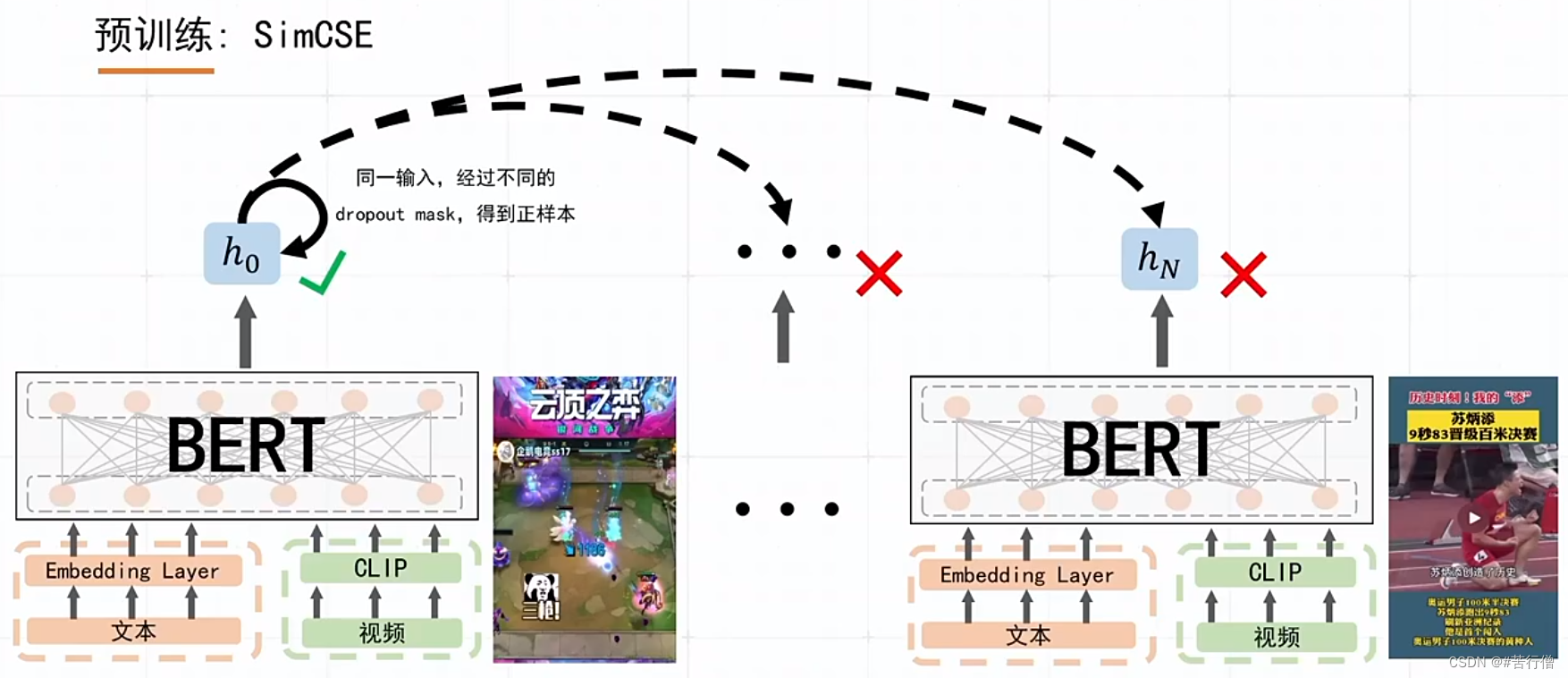
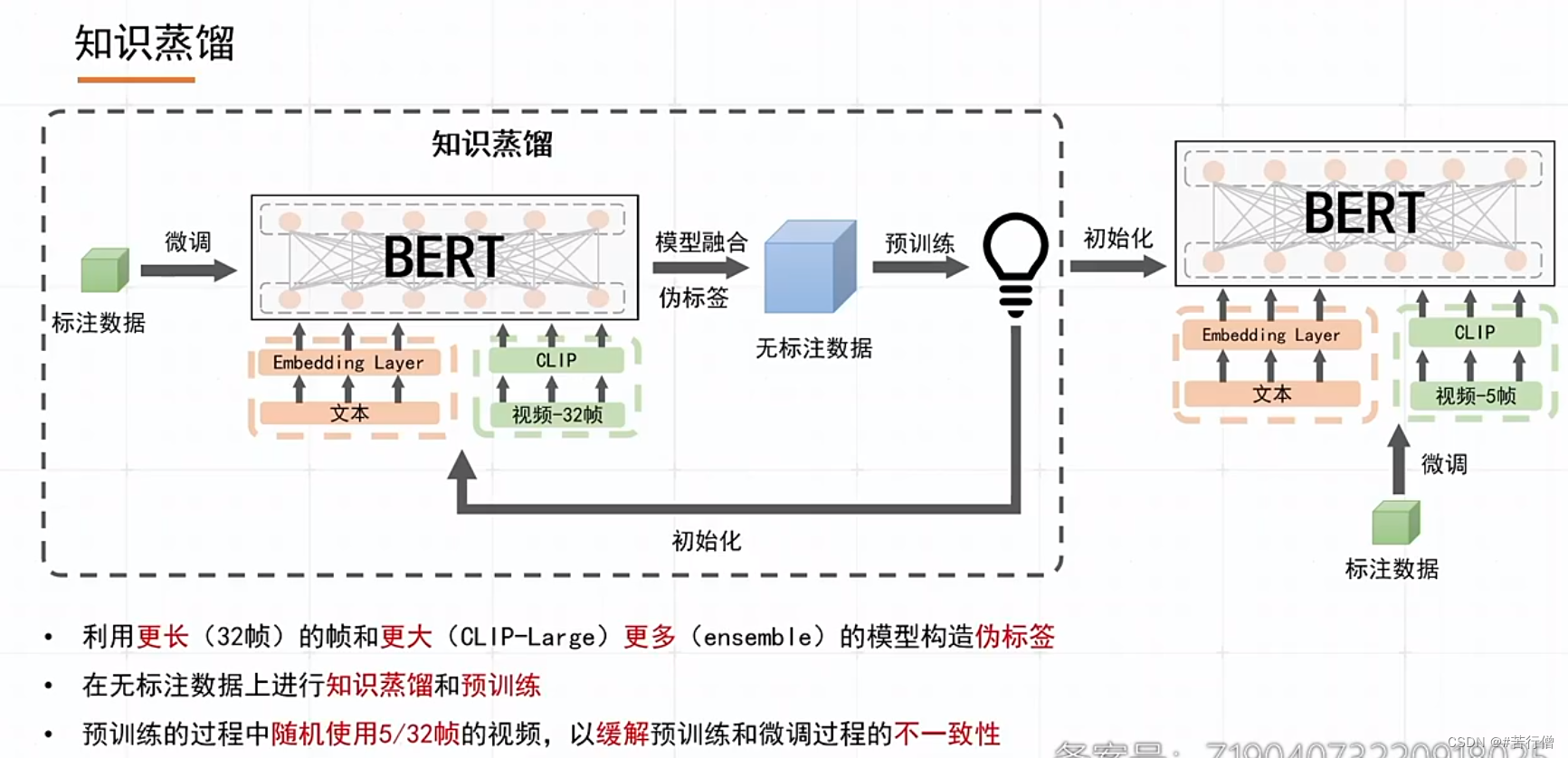
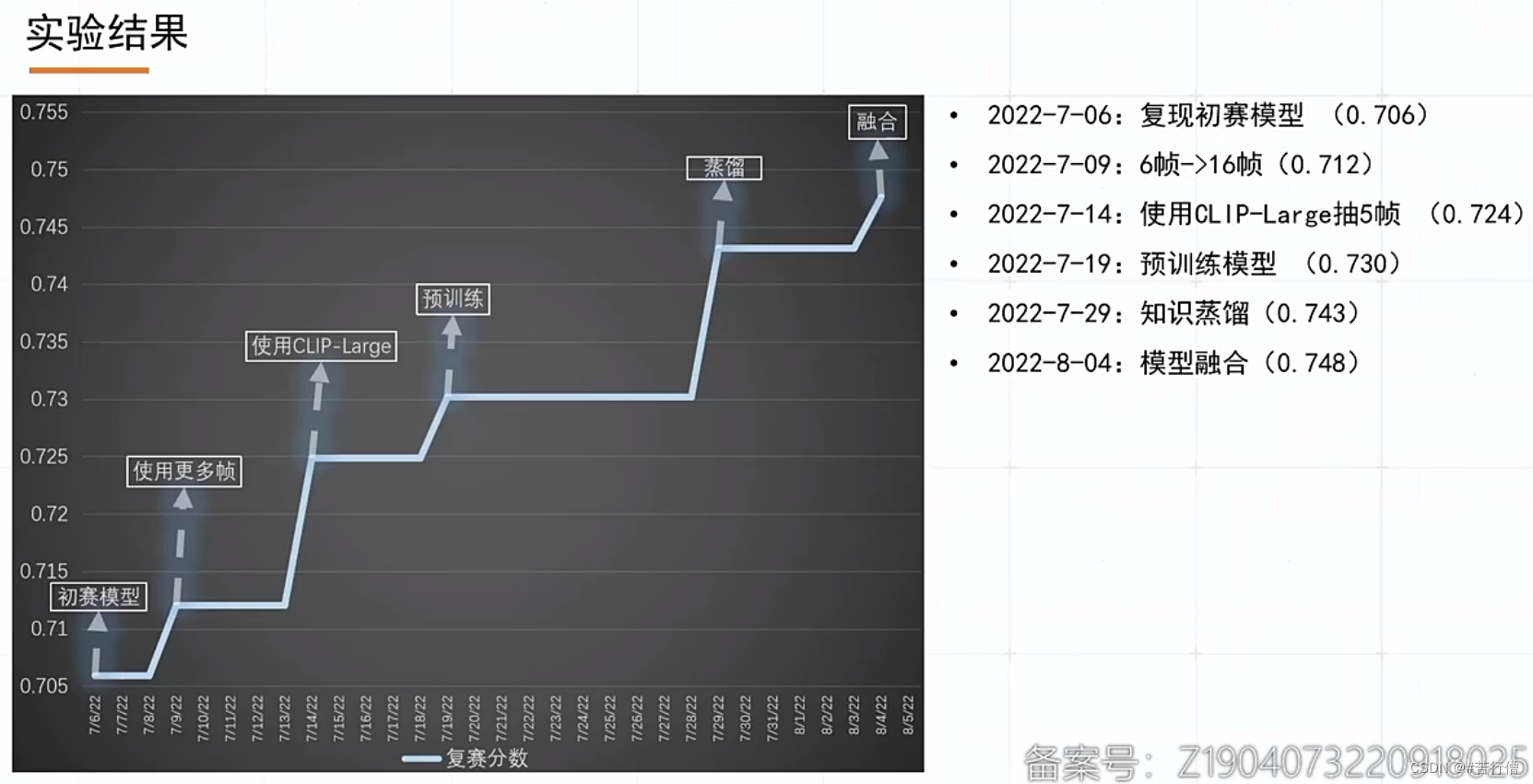

提问环节总结:
1、3种模型,本质上是在顶层的交互模块的区别,不管哪个模型牛,最后融合后,各模型的差异性可能对预测结果均有贡献。
2、知识蒸馏打出的伪标更好,前提是使用了更强更大的模型来打伪标。
3、除了知识蒸馏,也有考虑类别不平衡问题,只是ppt没展示,数量较少的类别重采样,提升较少所以没放在ppt讲。
4、模型融合,直接相加平均。
5、伪标过程(知识蒸馏过程中),数据是:有监督数据+伪标数据(会重用)。
6、为啥基本都用clip-vit,为啥在微信这个任务效果比swin-transformer好?
7、郭大说前排如果用了知识蒸馏的话,可能就打不过了哈哈哈。
TOP2-冲冲冲~:
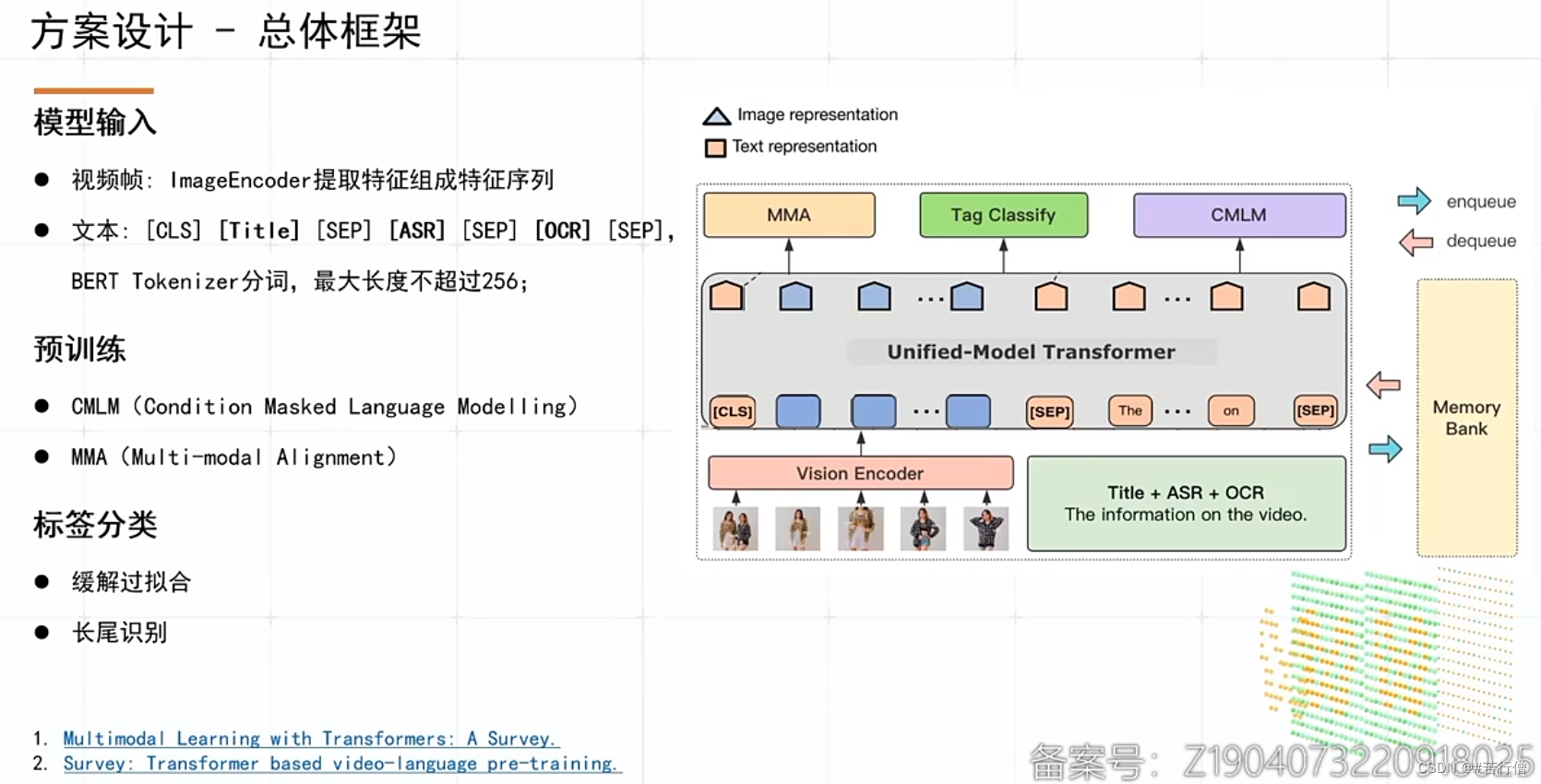

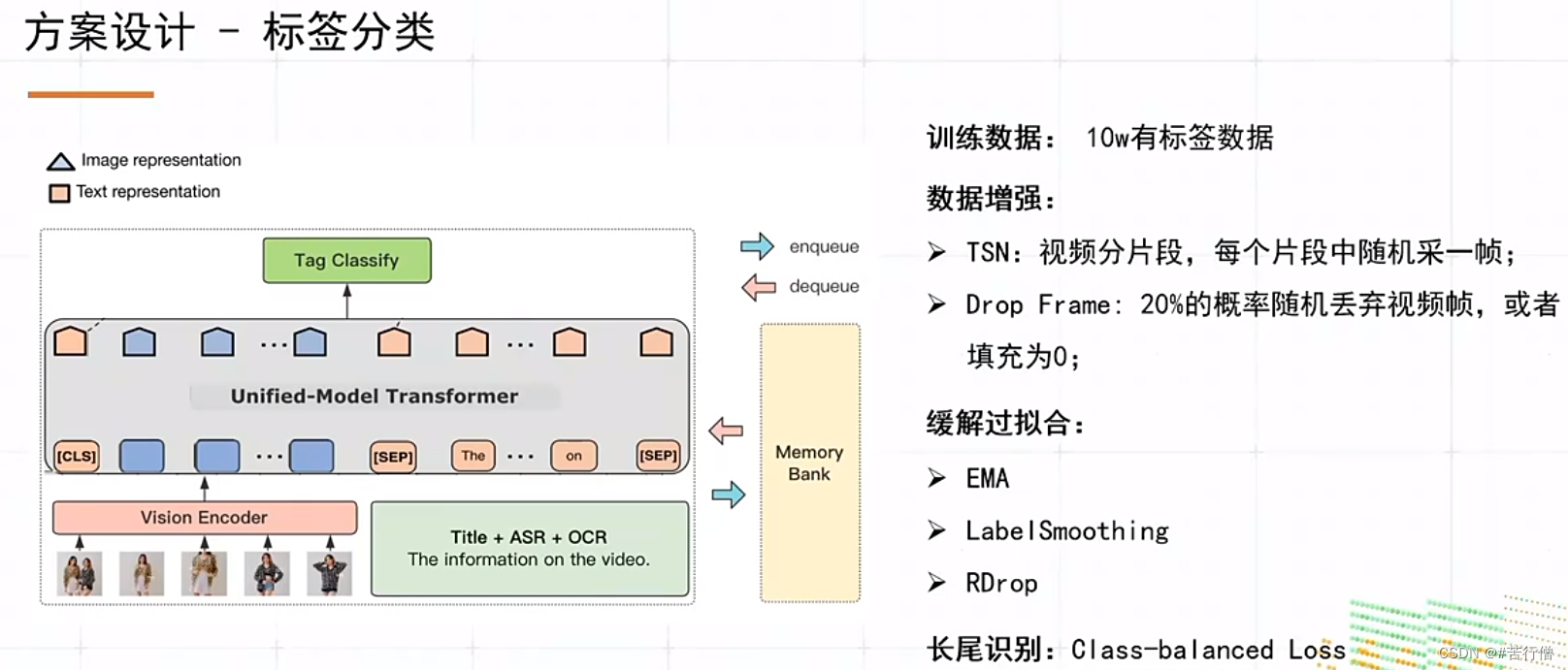
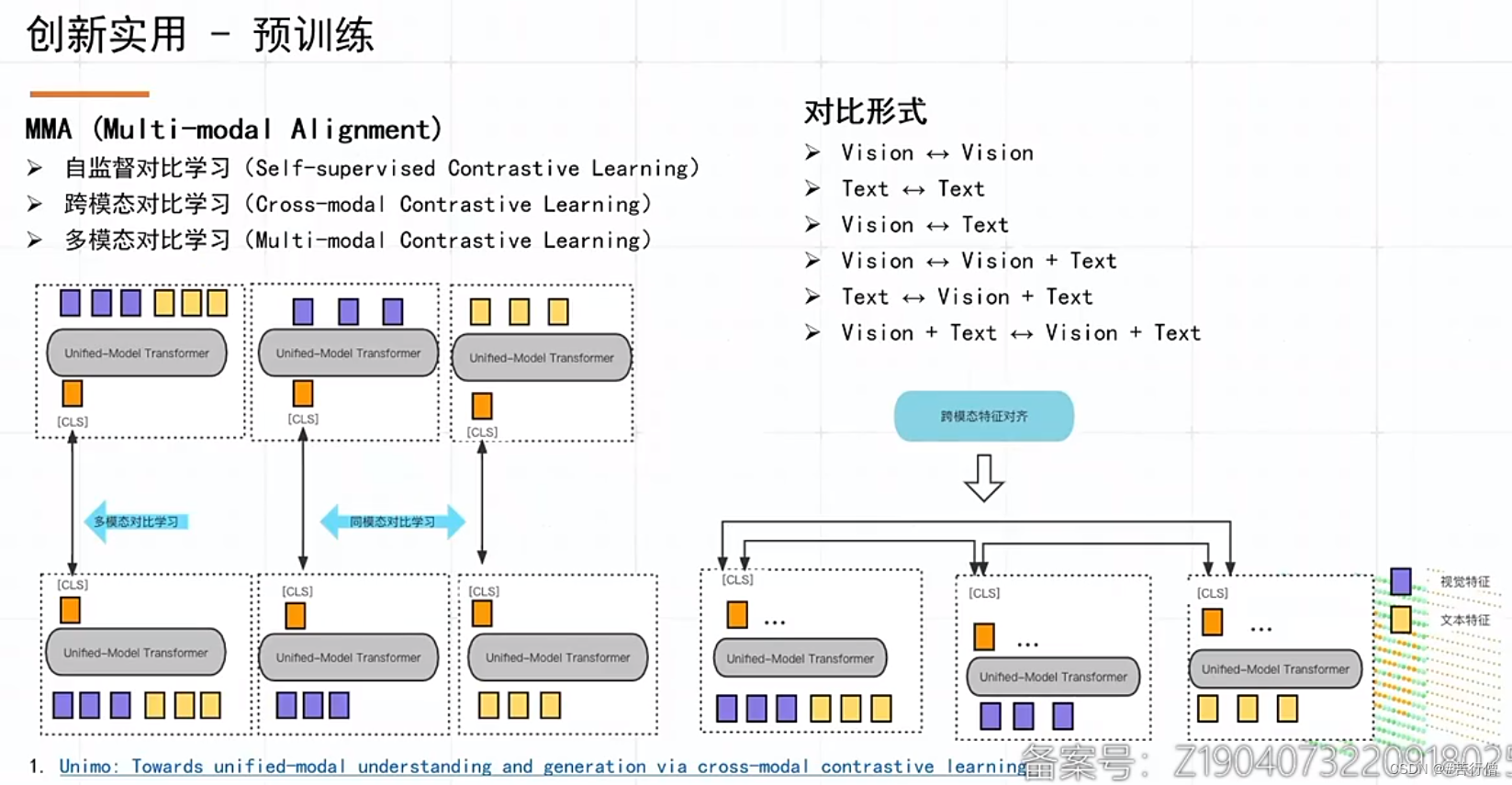
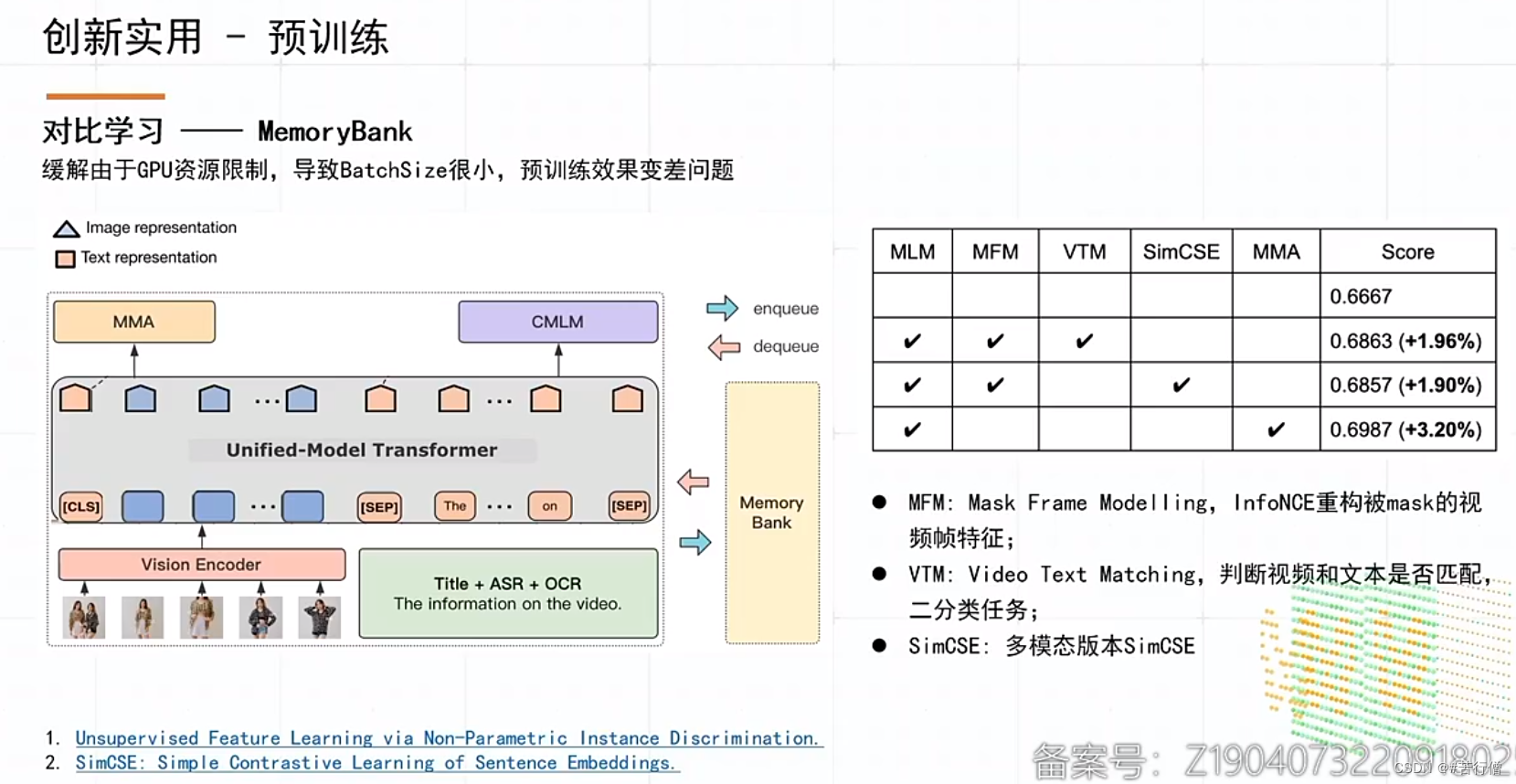
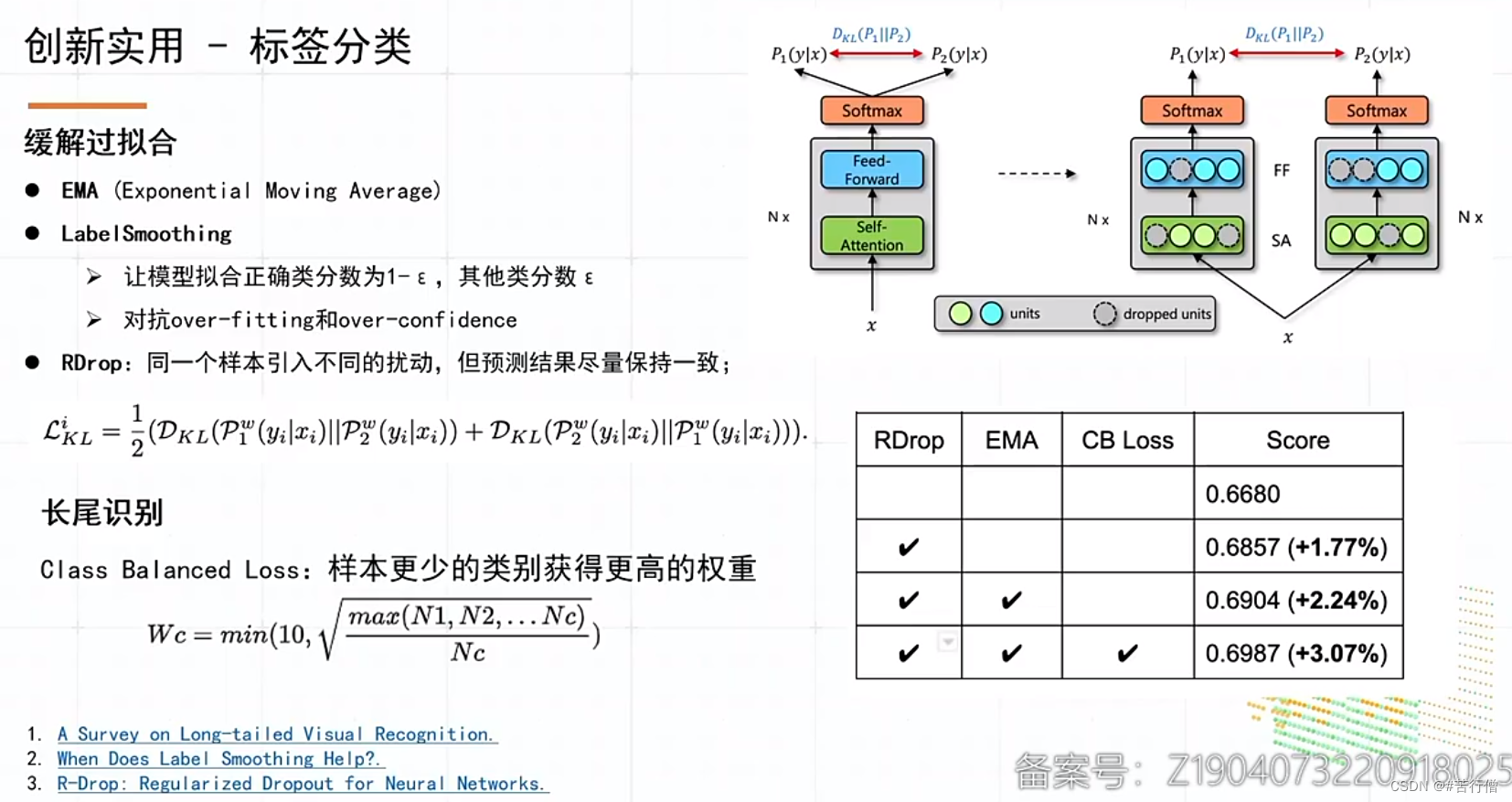
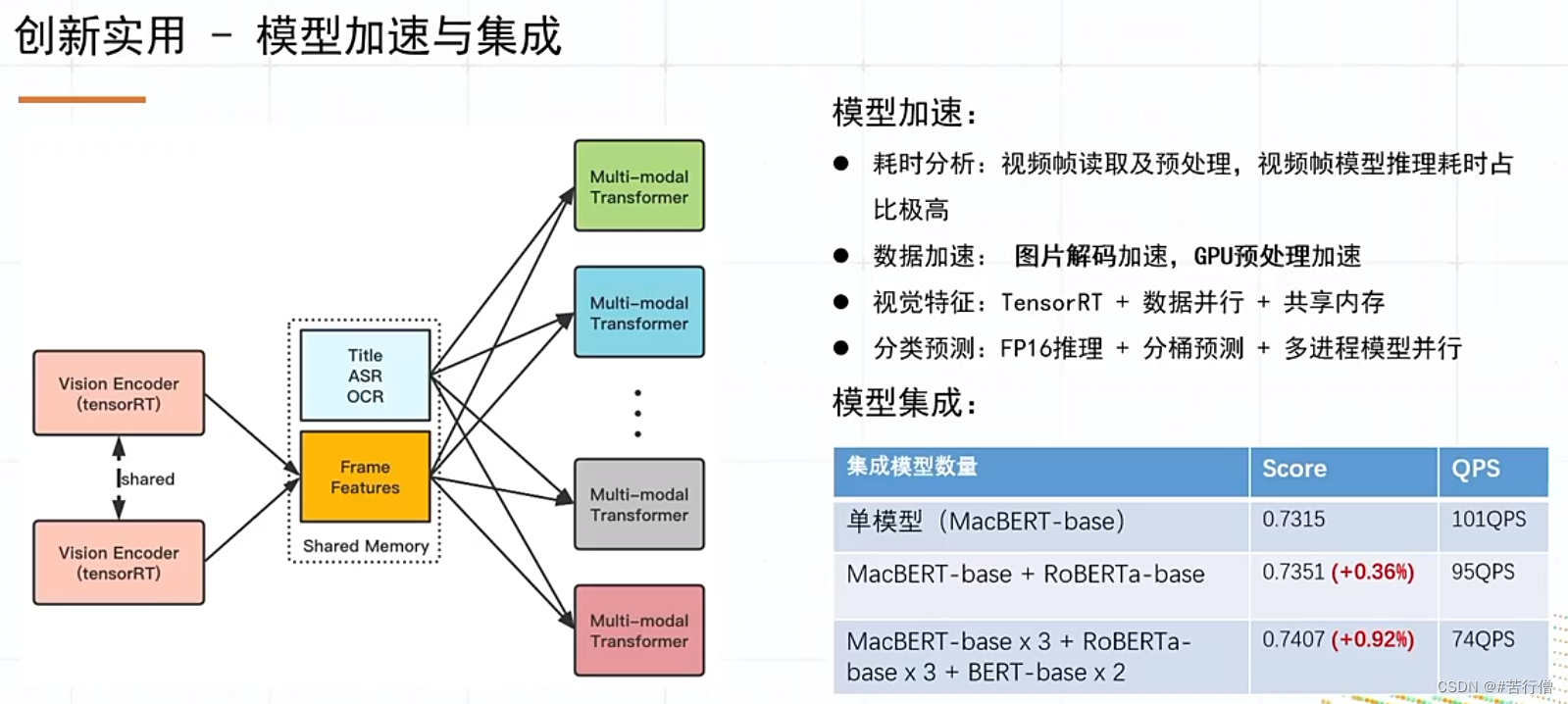


提问环节总结:
1、对比学习中,有3种对比学习方式,复杂度和常规对比学习差不多。
2、直接用分类模型打伪标效果提升不明显。DML结构和分类模型结构一样。
3、和其他队伍的显著特别之处就是:MMA预训练。
TOP3-抱朴子:
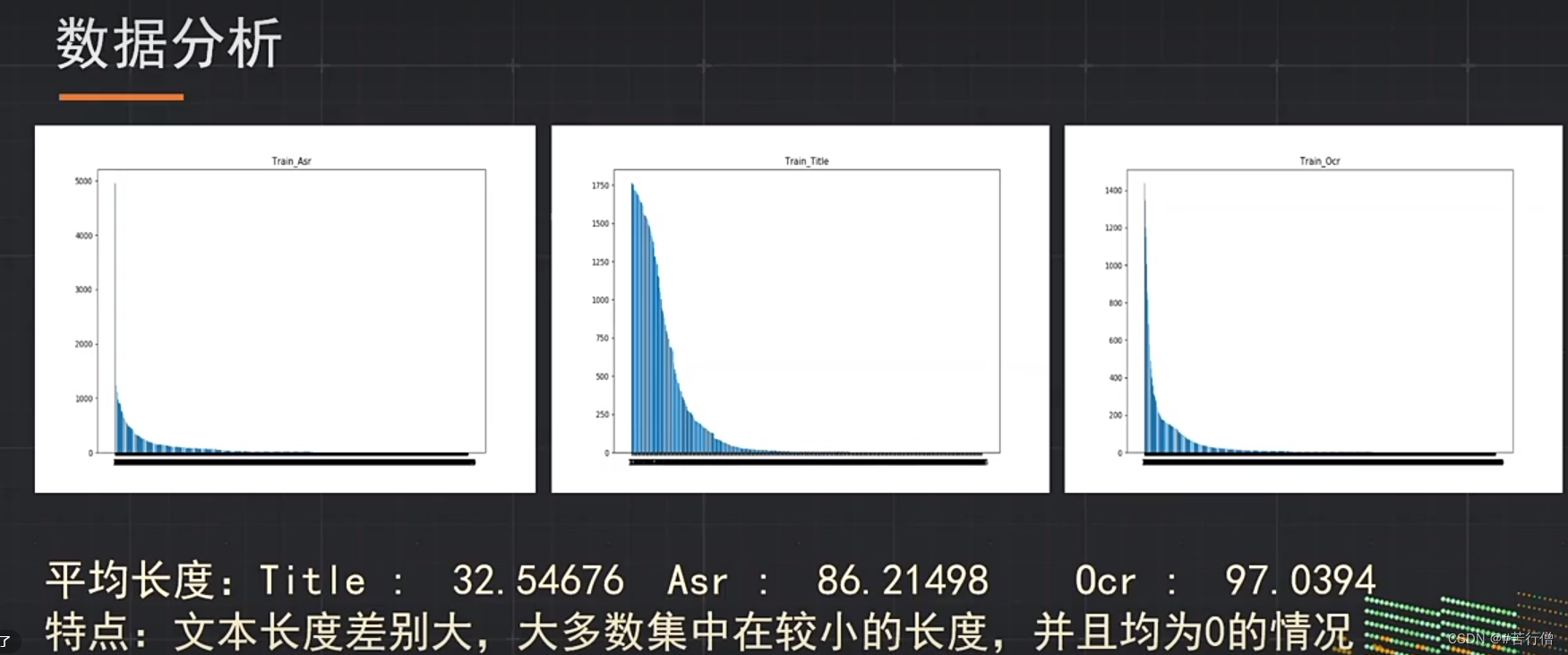
单双流结构模型融合(平均),5种模型。
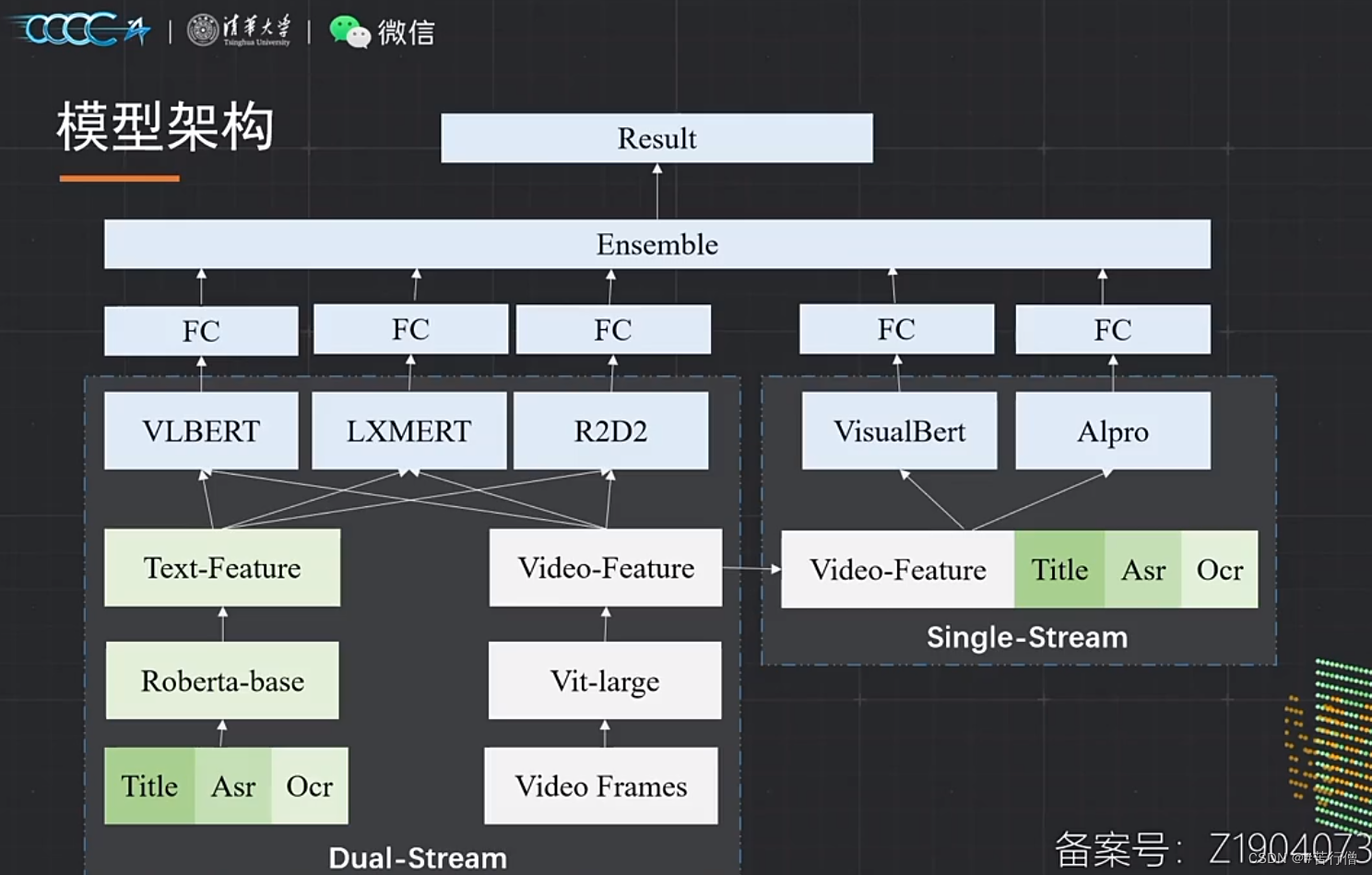
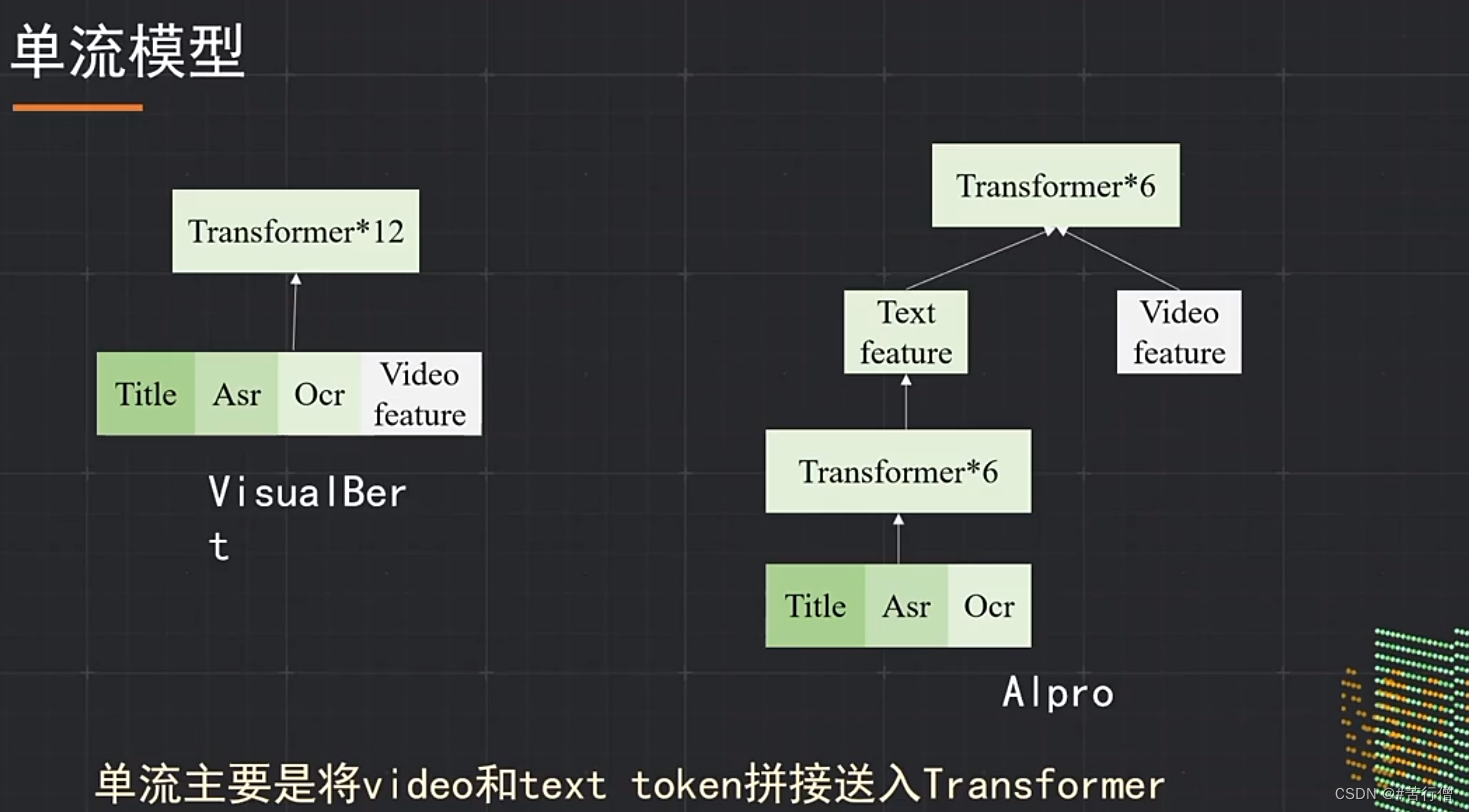
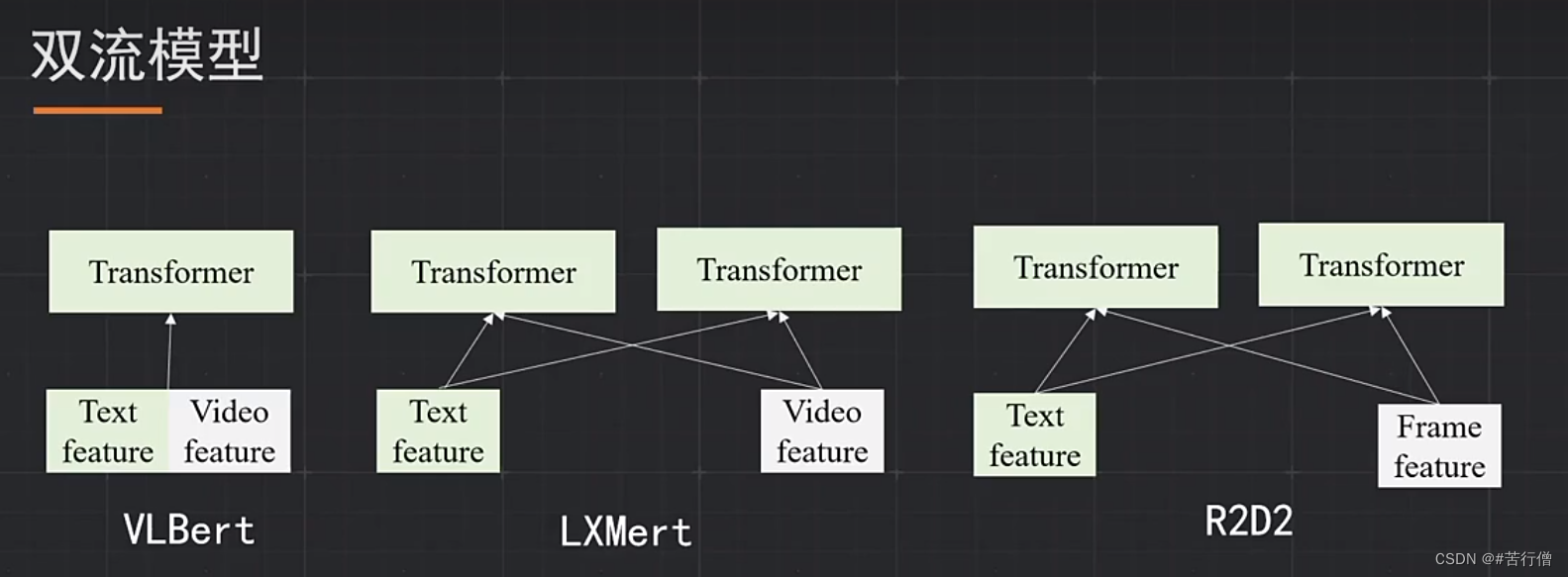
常规预训练任务:MLM, MFM, ITM。






提问环节总结:
1、没用对比学习预训练、只用了图文0/1匹配,实验发现对比学习预训练线上效果不佳。
2、没有对类别不平衡问题做处理。
3、主要集中于编码器的选取,如R2D2。
TOP4-机器不学习啦:

双流模型结构:
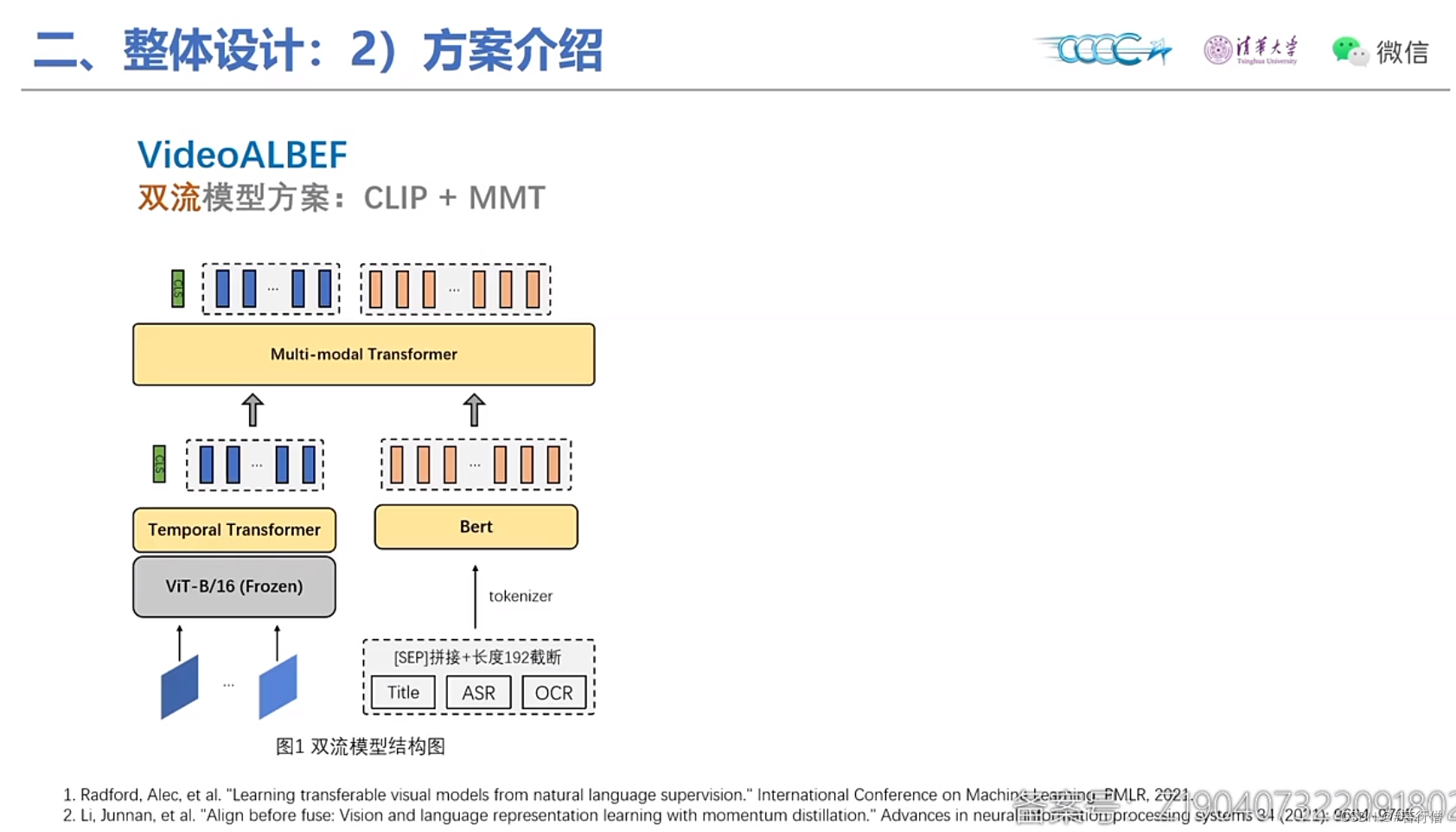
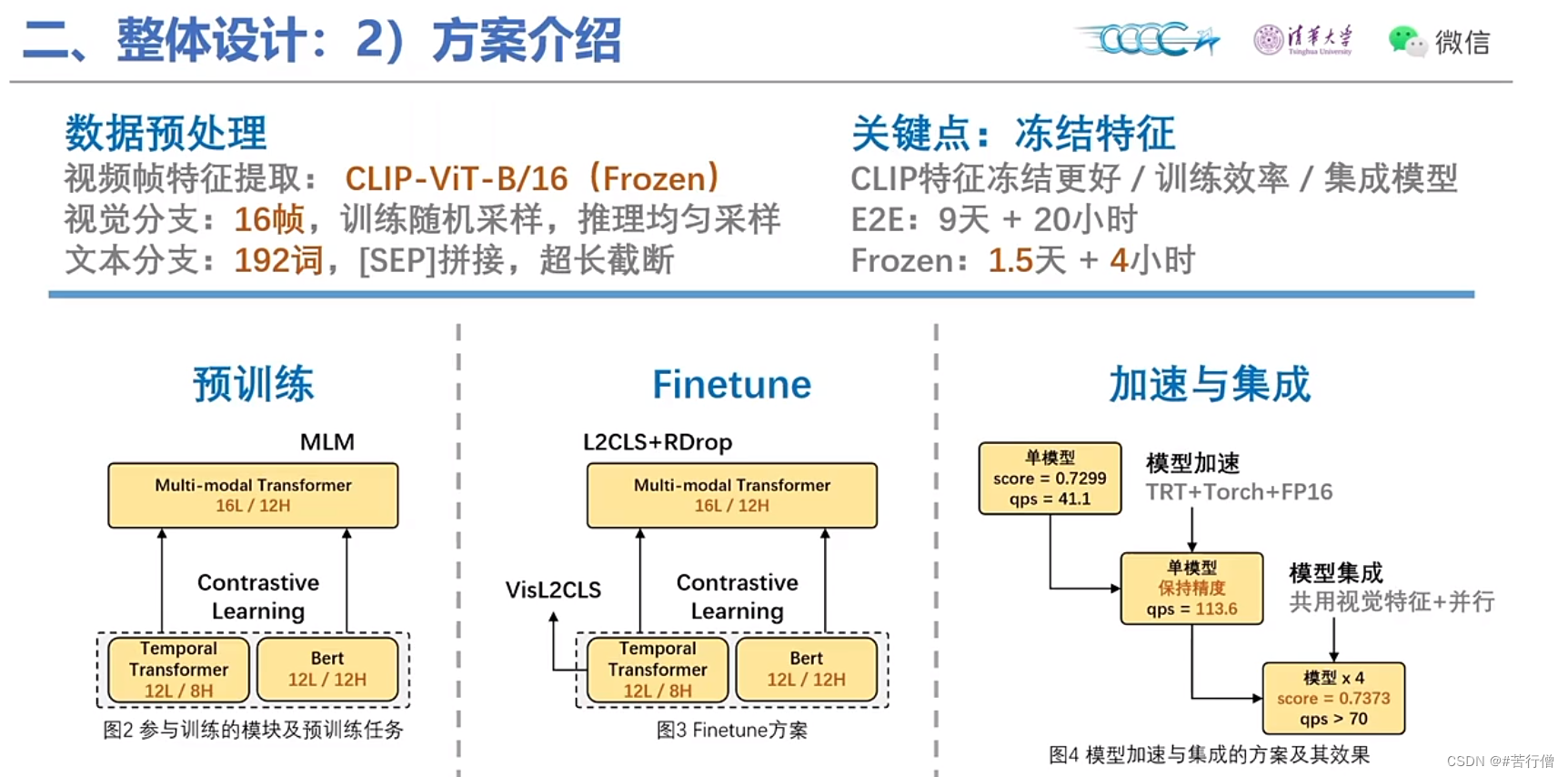
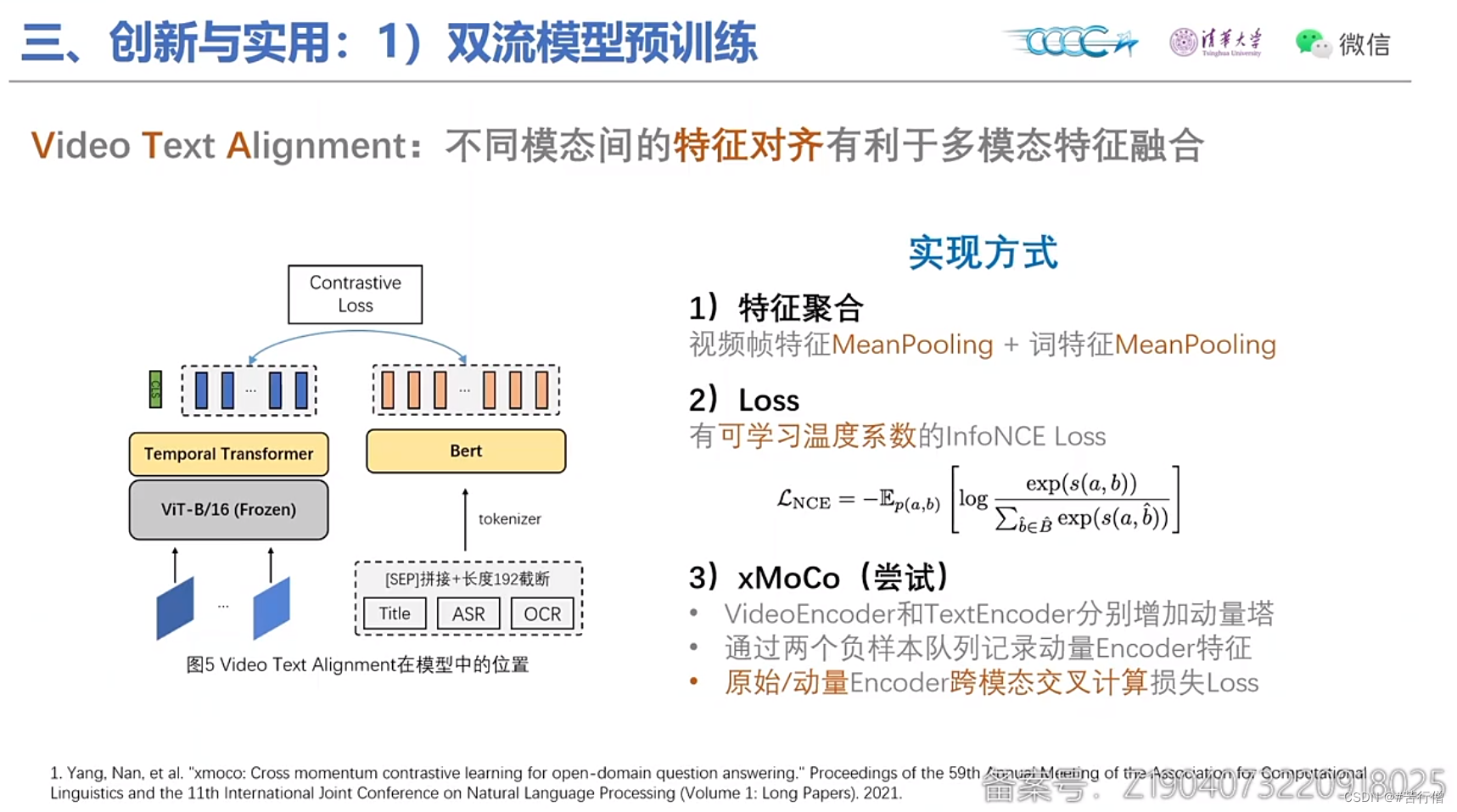
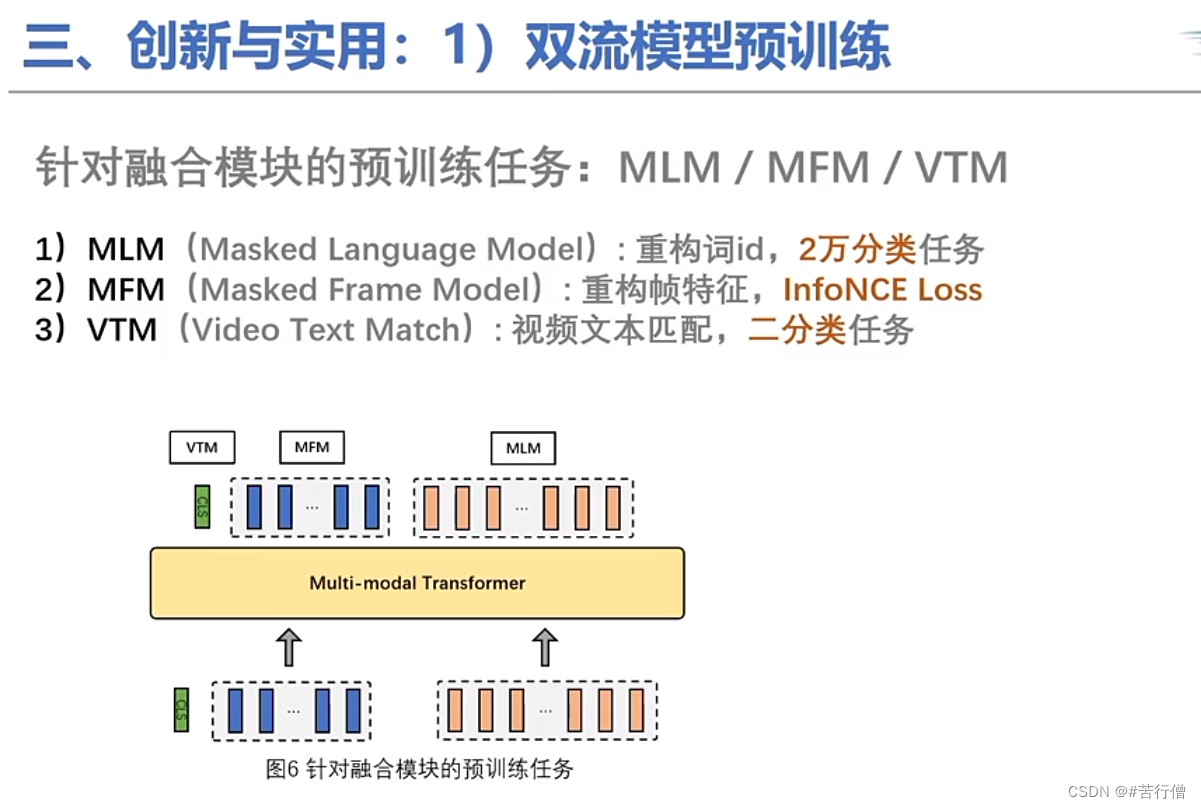
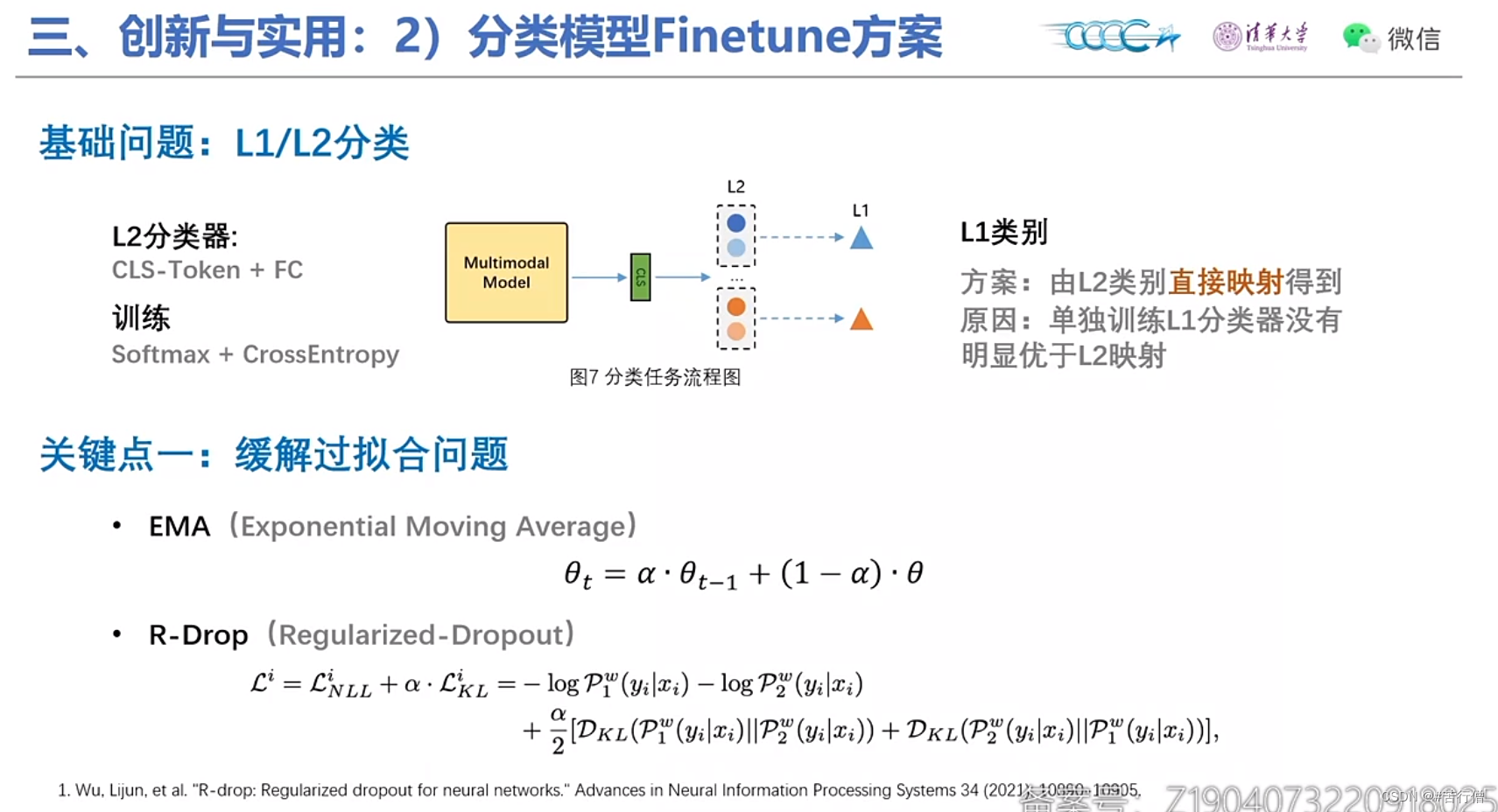

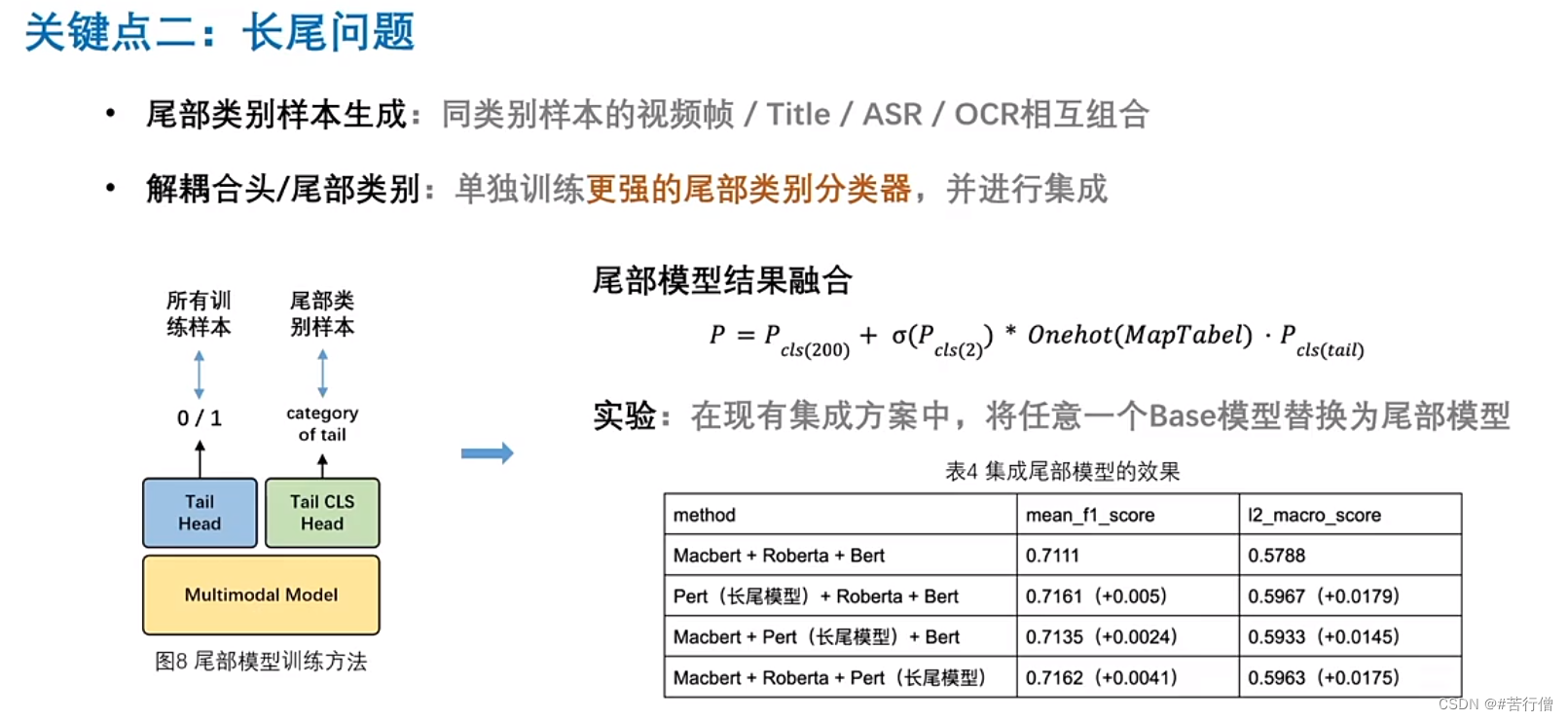


提问环节总结:
1、loss部分有4部分,权重通过做很多对比实验试出来的。
2、层级标签体系之间可能有冲突,L1层面标签可能很清晰,但L2层面不一定。
3、matching任务时,构建pair是随机的,未来可考虑从负样例中合理采样更有价值的负例。
4、至于为什么finetune阶段加了VTA特征对齐任务,说是特征对齐对下游任务可以有一定约束、泛化性有提升。
TOP5-warriors:
maxlen用的也是256。

VL-BERT的结构:
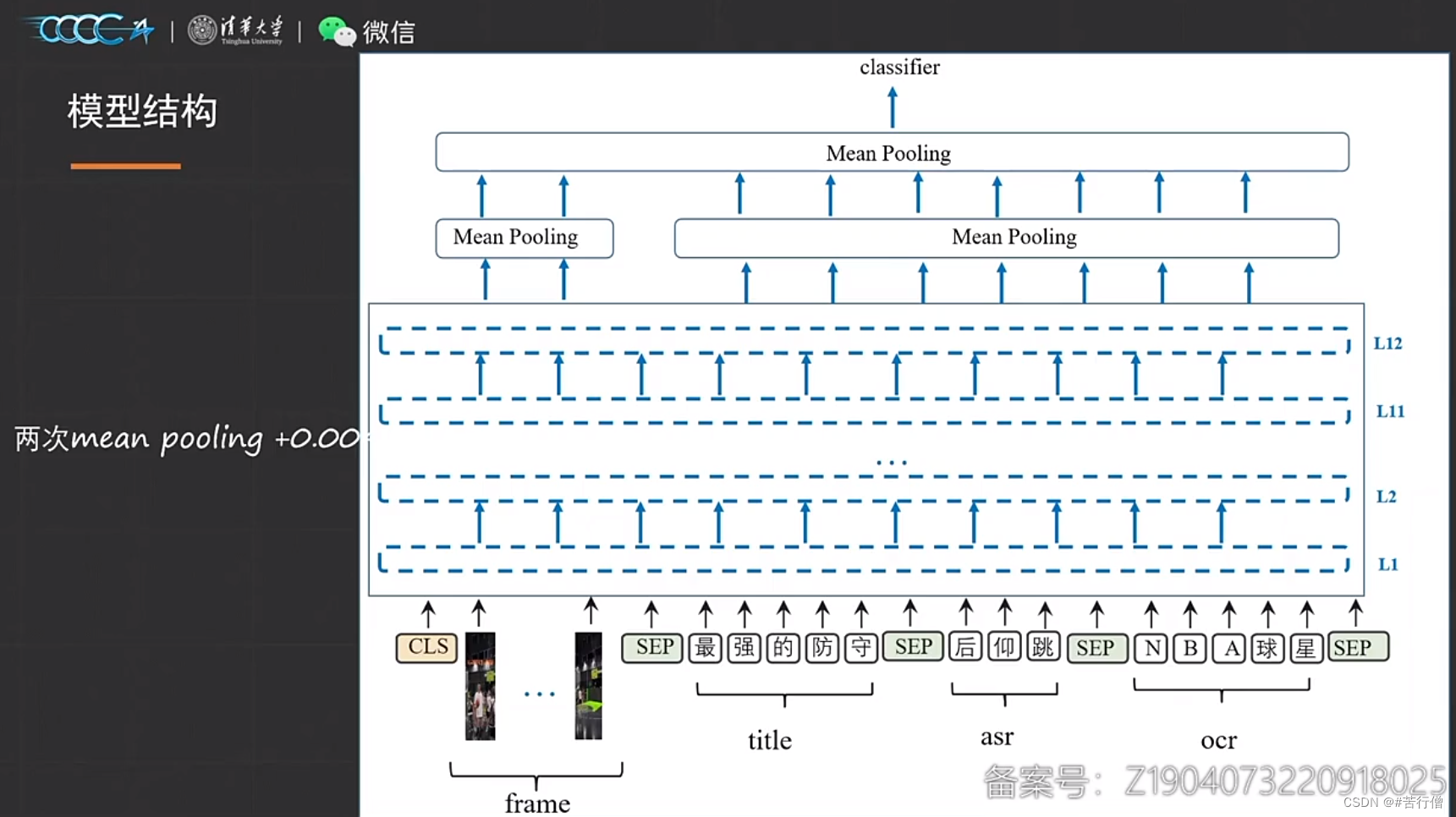

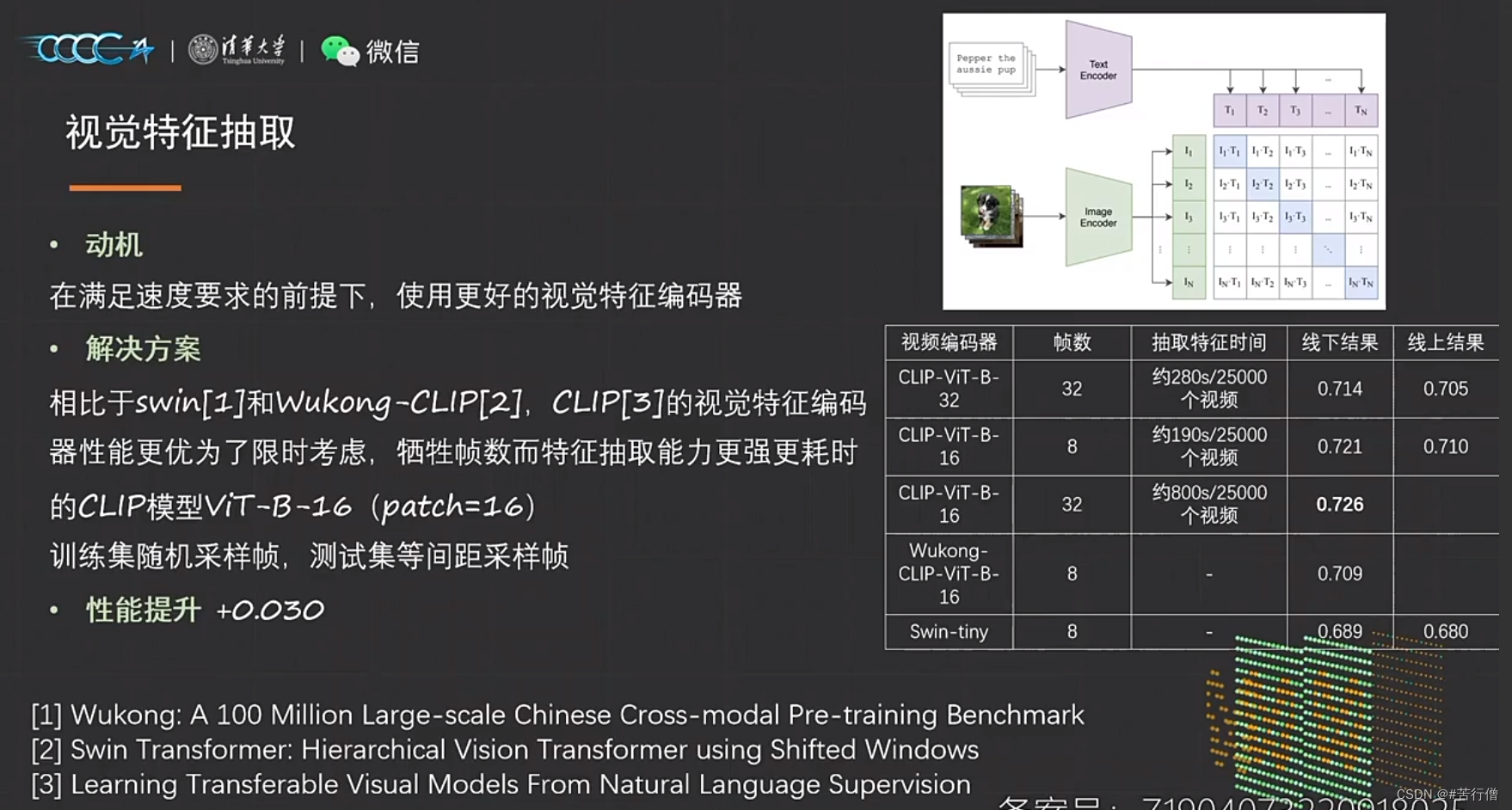
额,又是用clip-vit模型提取视频特征的,基本都用这个(可惜我没用)
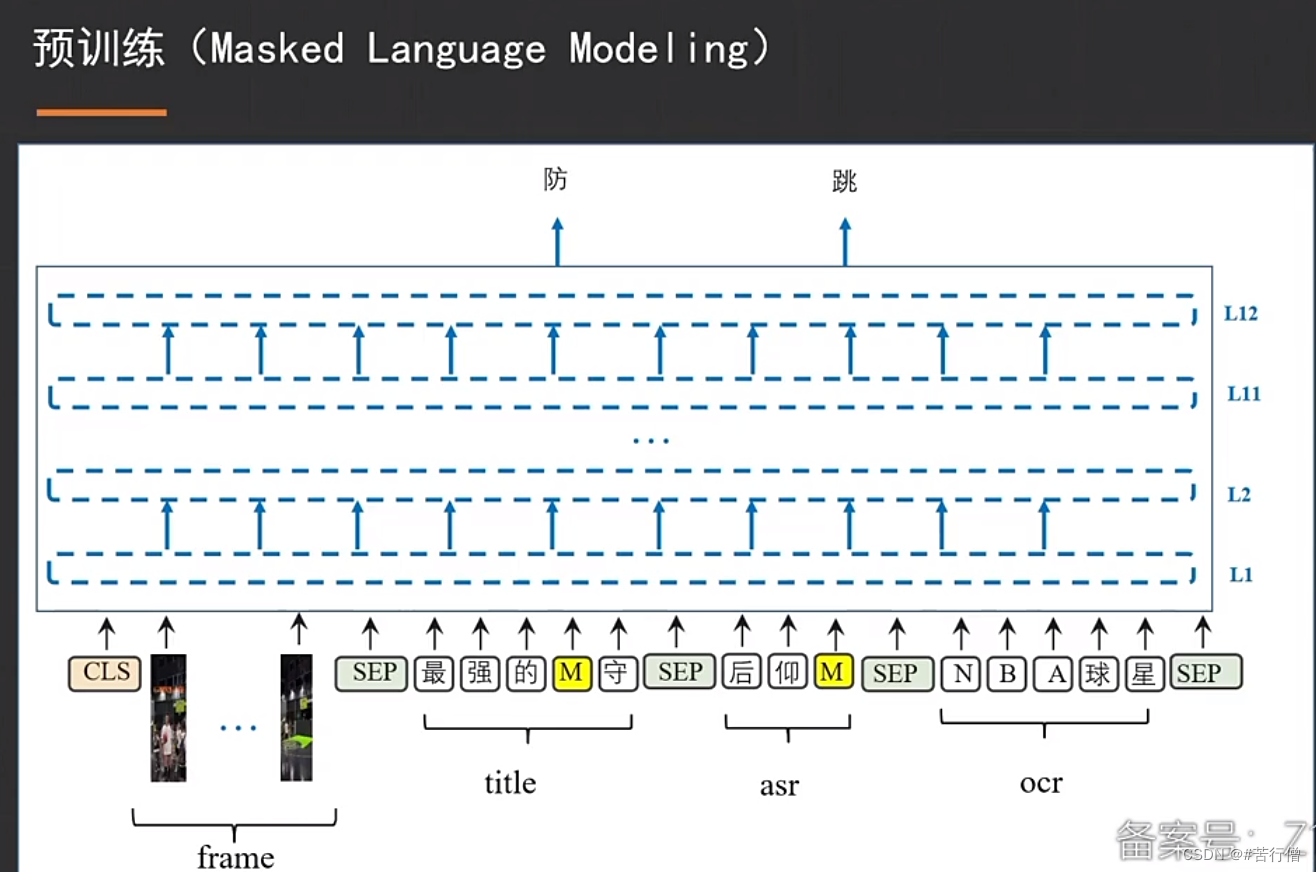
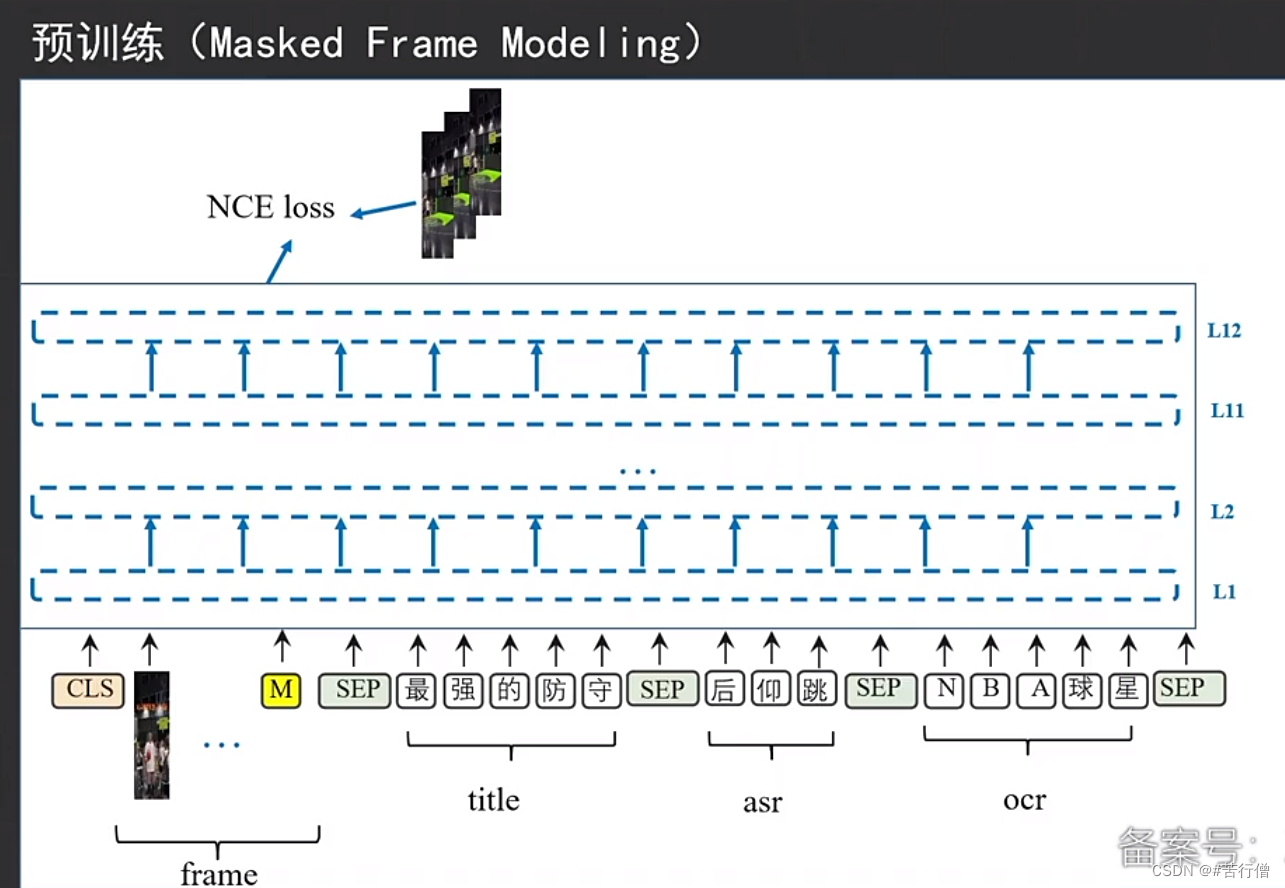
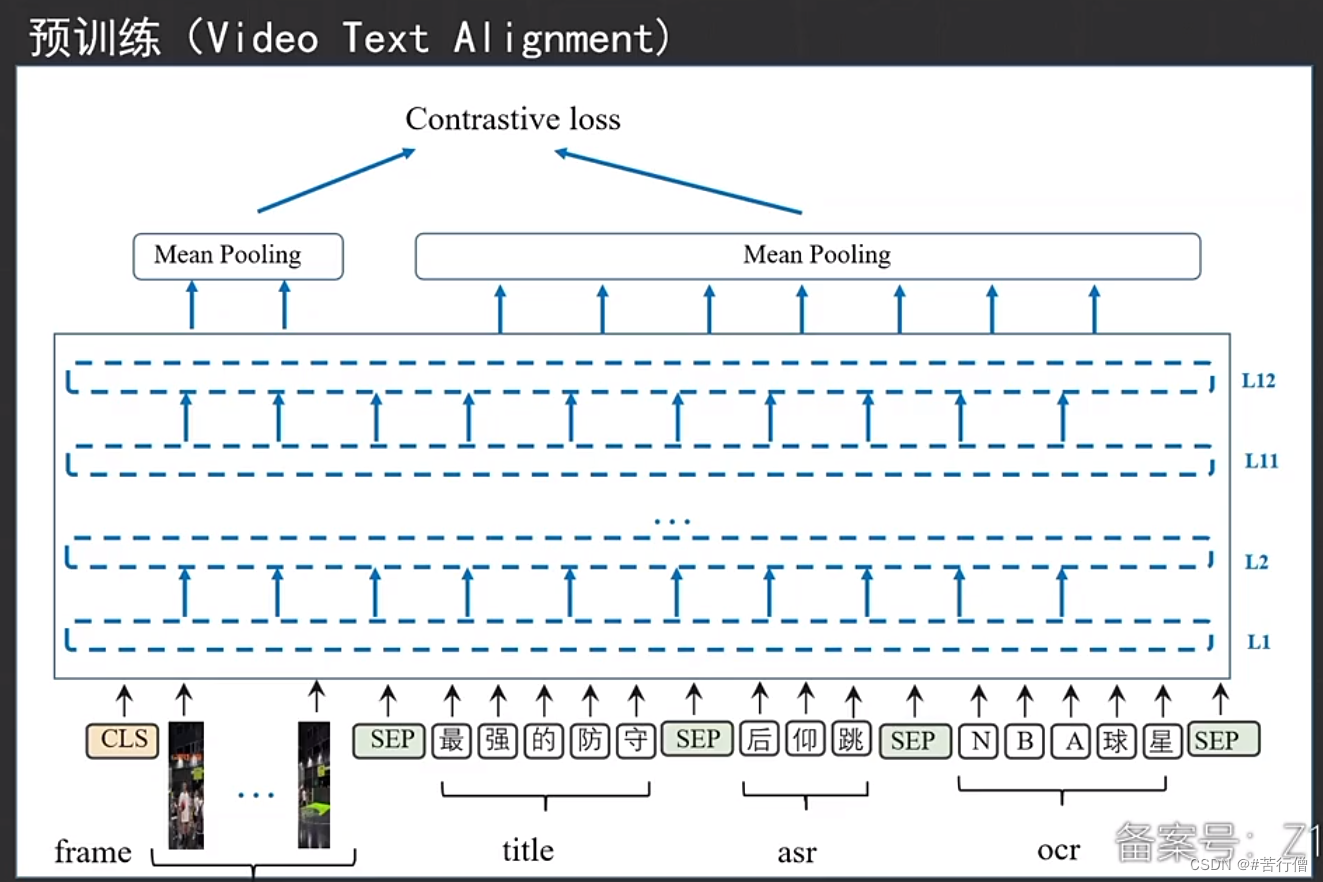
还有个text-video matching预训练任务,没截到图哈哈哈:




提问环节总结:
1、预训练时,MLM预训练基于词粒度做。
2、title、asr、ocr。分别传入3个网络分别提特征,应该没有拼接3个传入网络交互好。测试一下不同模态对分类任务的贡献。
3、采样方面的问题。视频的时序信息是否有用?
4、预训练任务,文本视频2种模态实际是冲突的,那matching任务时是否会影响。
5、创新之处,结合字、词特征。
6、对asr,ocr预处理,去除啊啊啊、哦哦哦等噪音,性能也降了哈哈哈哈。(我也不理解为啥会这样)。
7、没用tensorrt(时间不够时间去试),用了fp16。
8、如果能用large,减少帧数,性能应该会提升。
TOP6-蜜度信息:


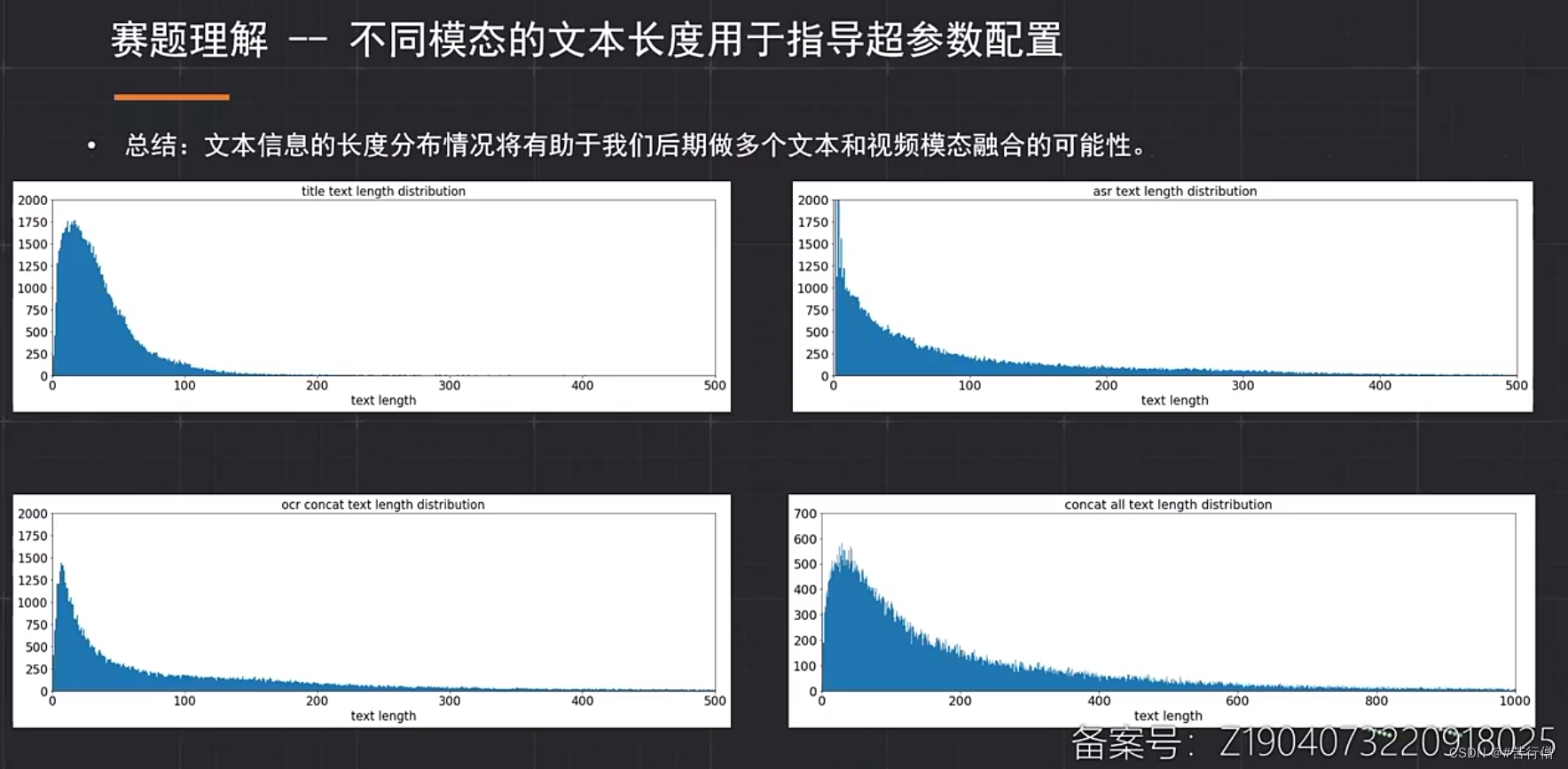
最后选择256长度截断(实验测试经过qps与精度衡量):

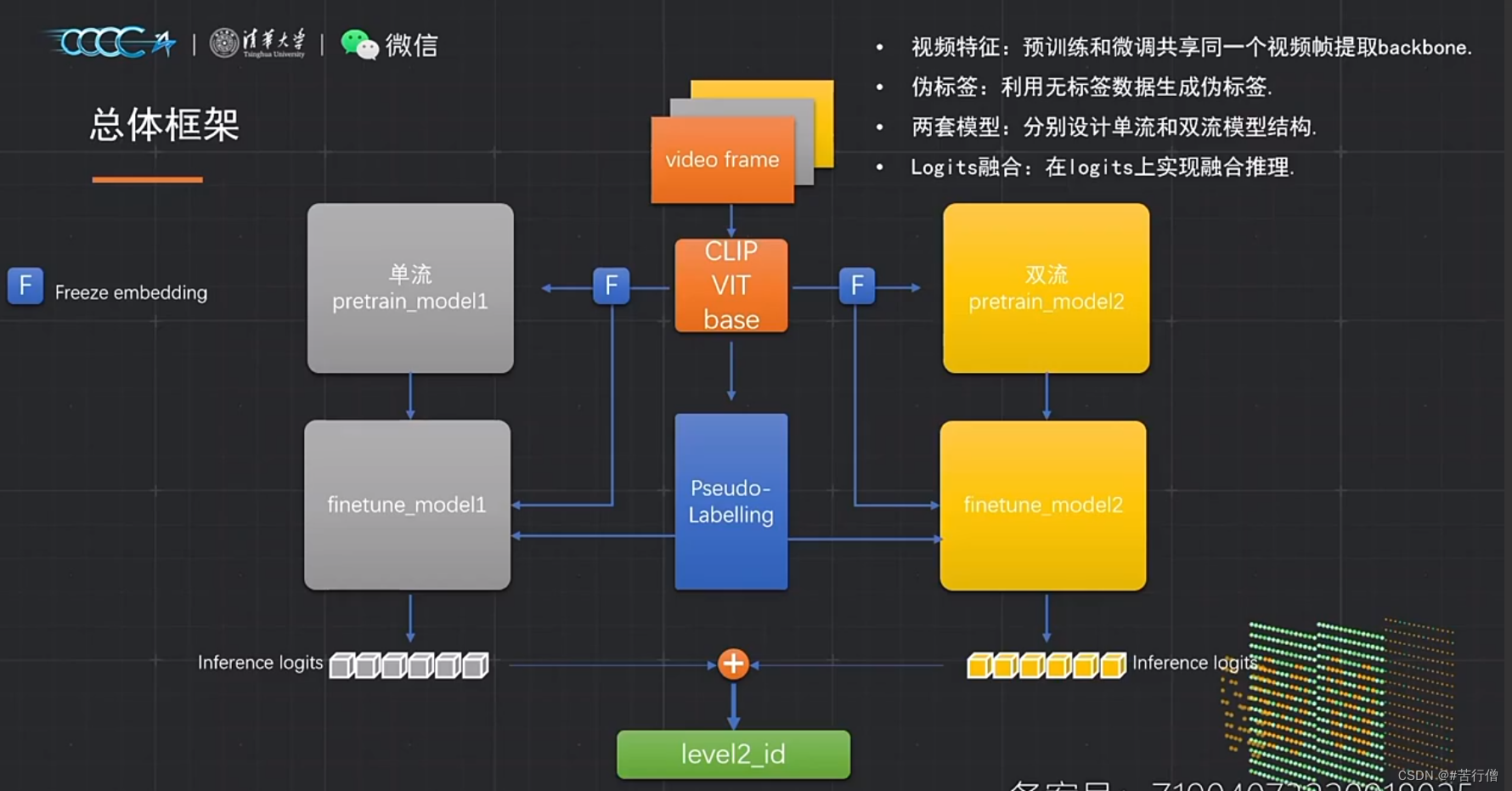
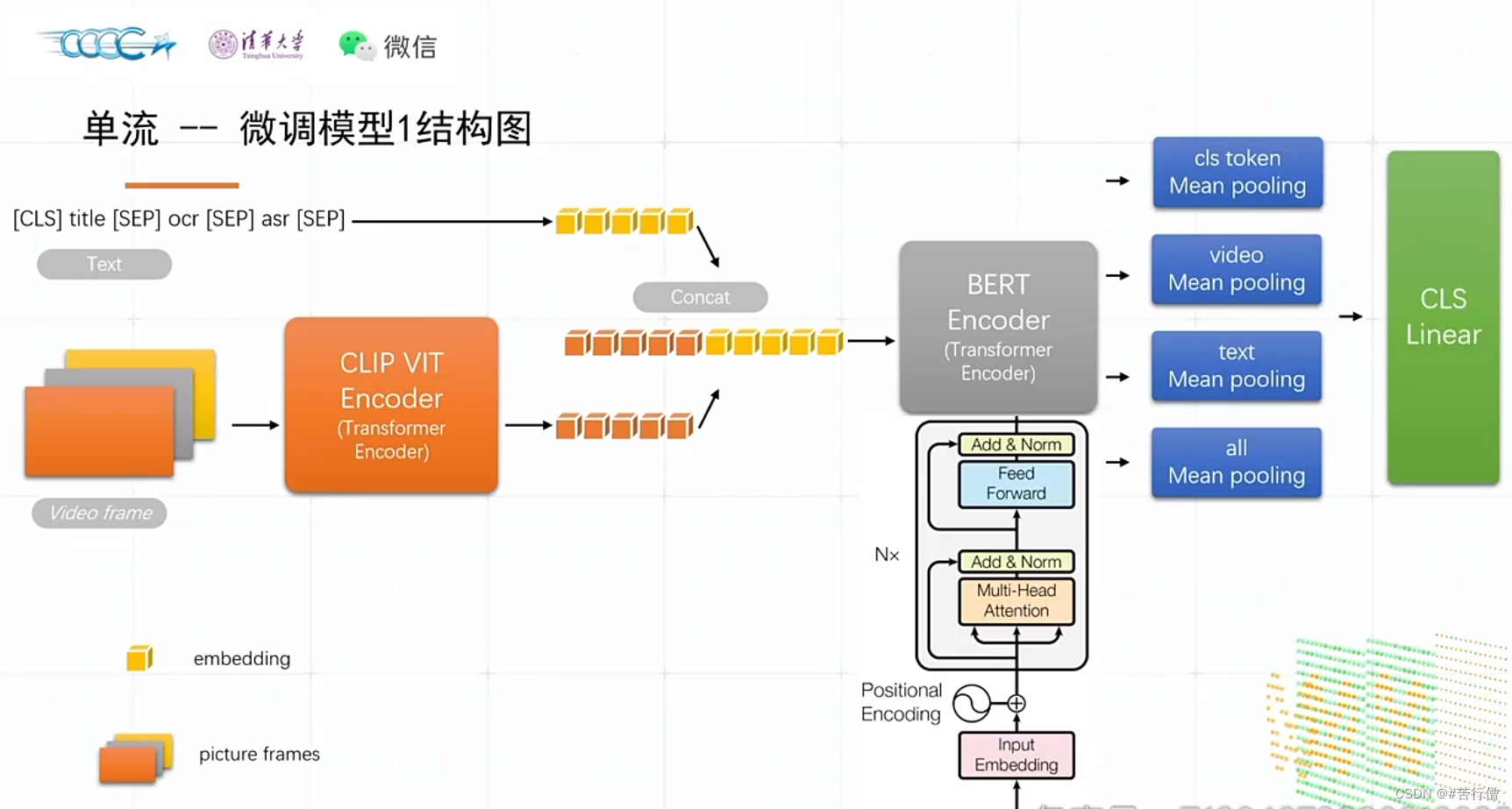
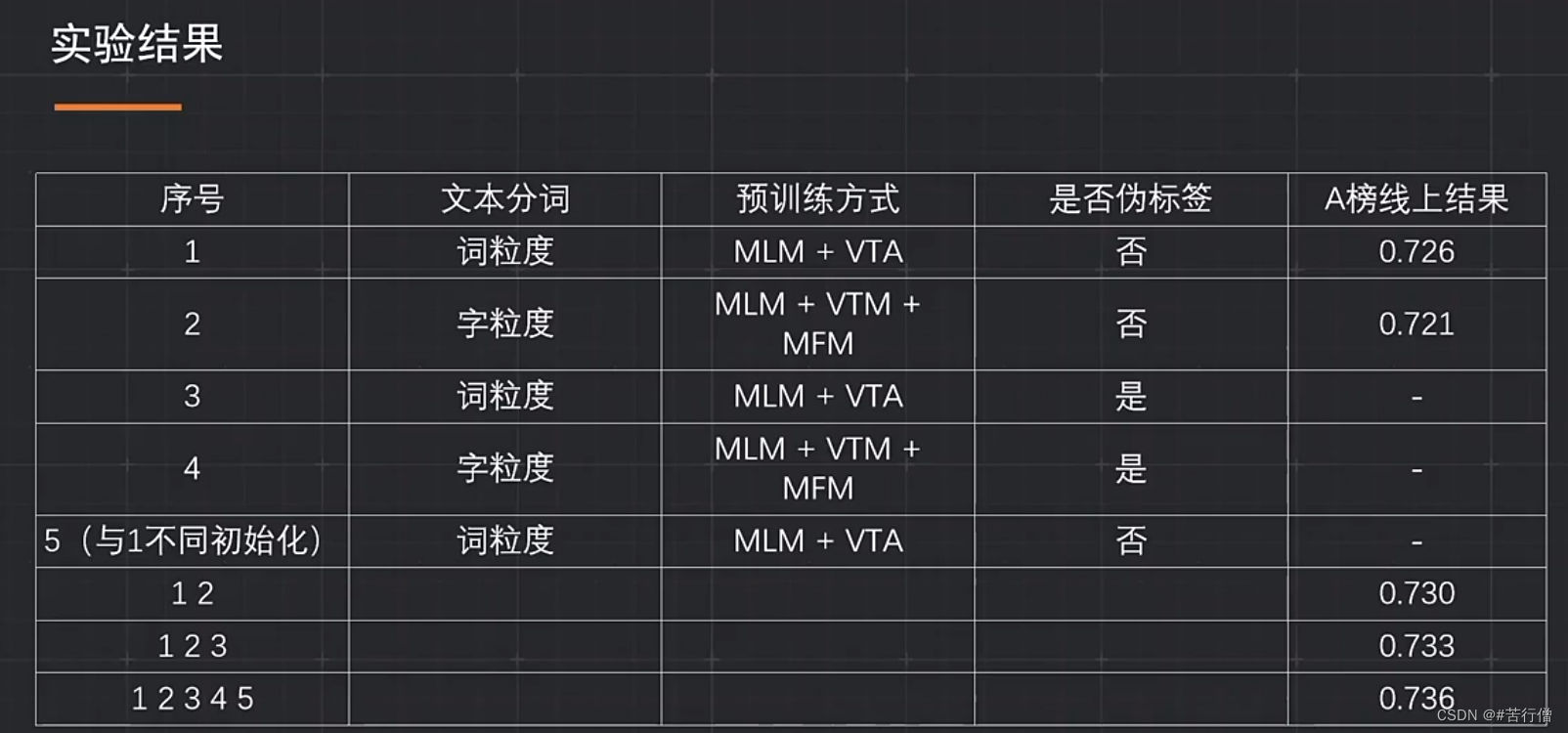
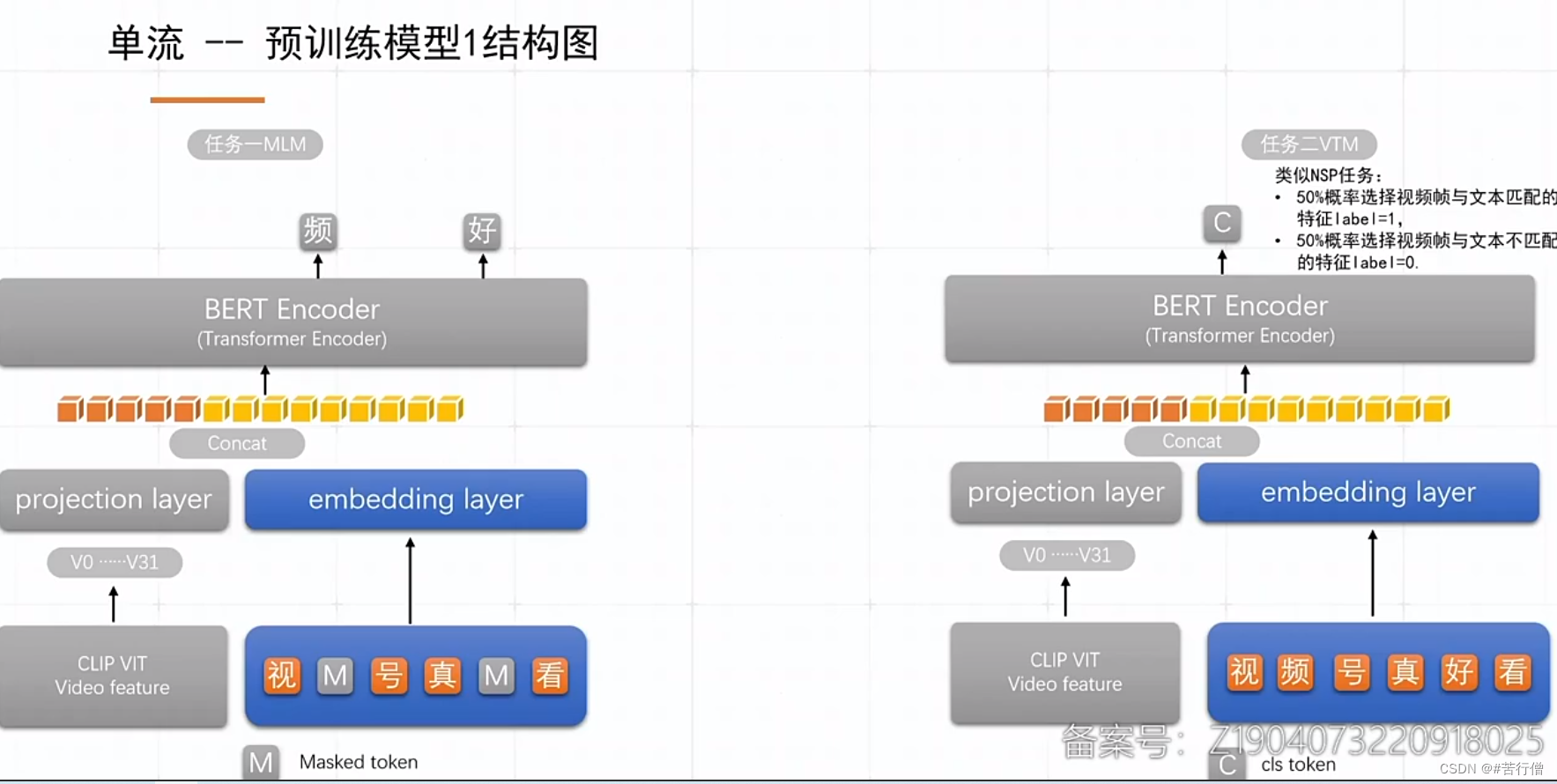
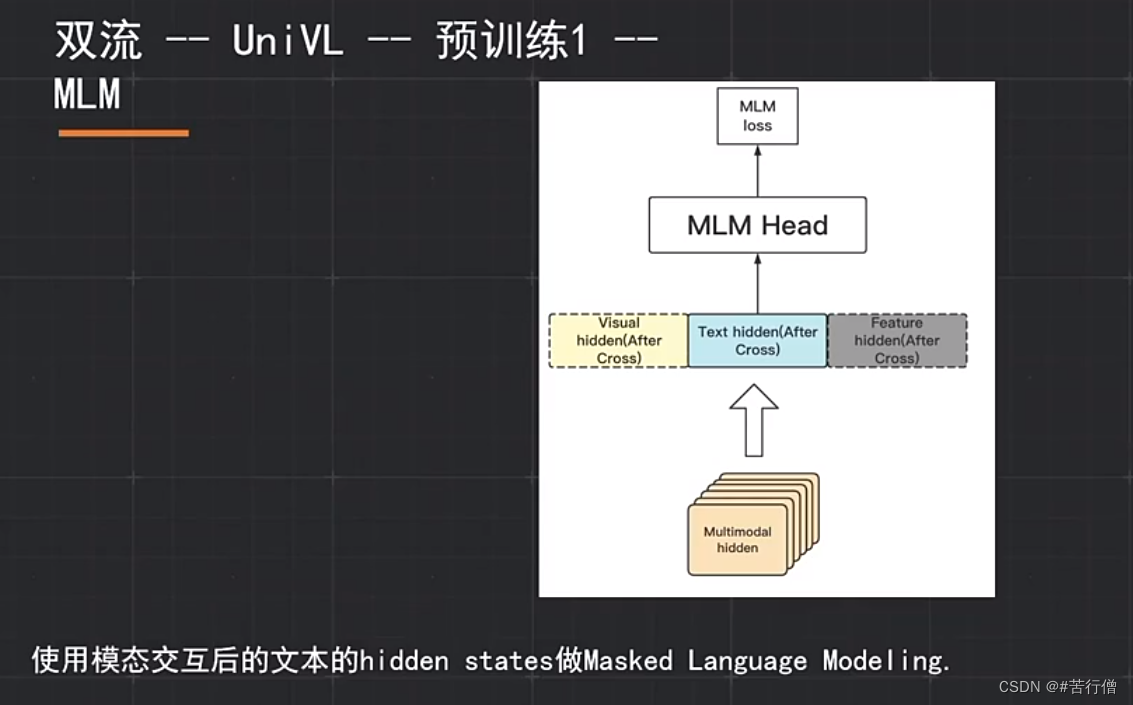
预训练任务:MLM,VTM(图文匹配)。
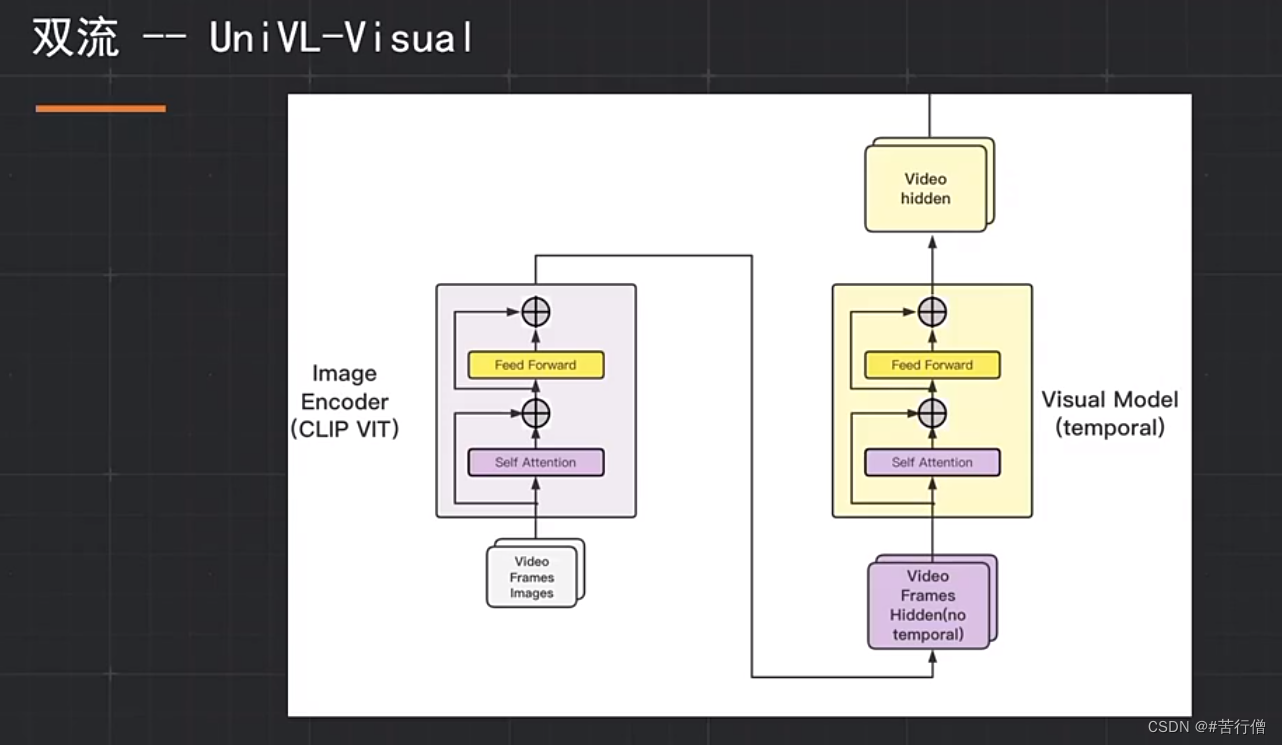
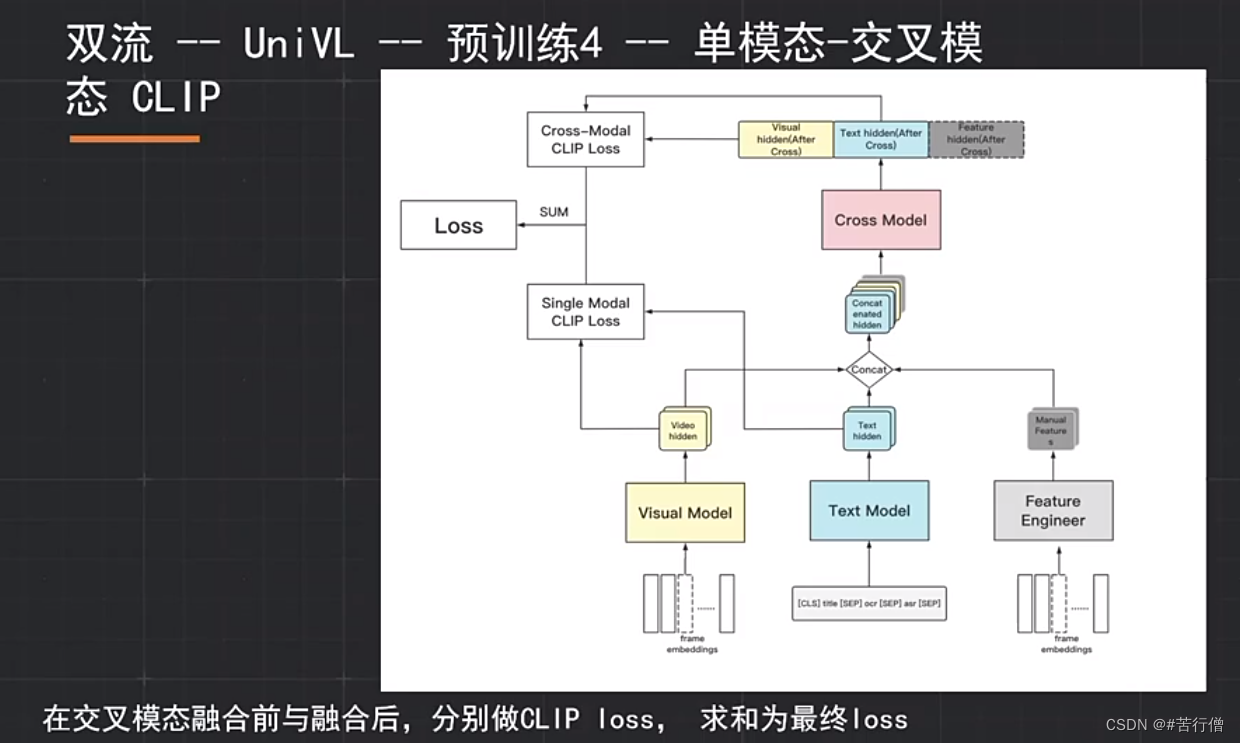
CLIP预训练:

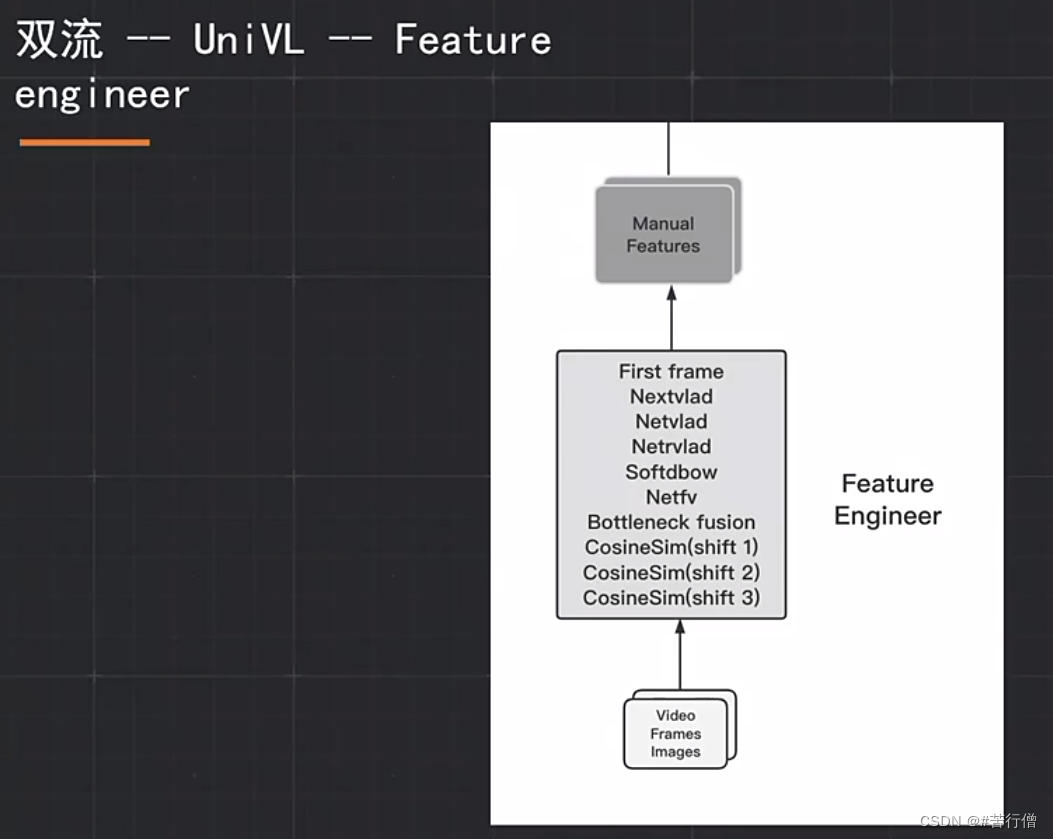
经过实验发现第一帧可作为强特征:

3种特征 cross attention融合(3层):



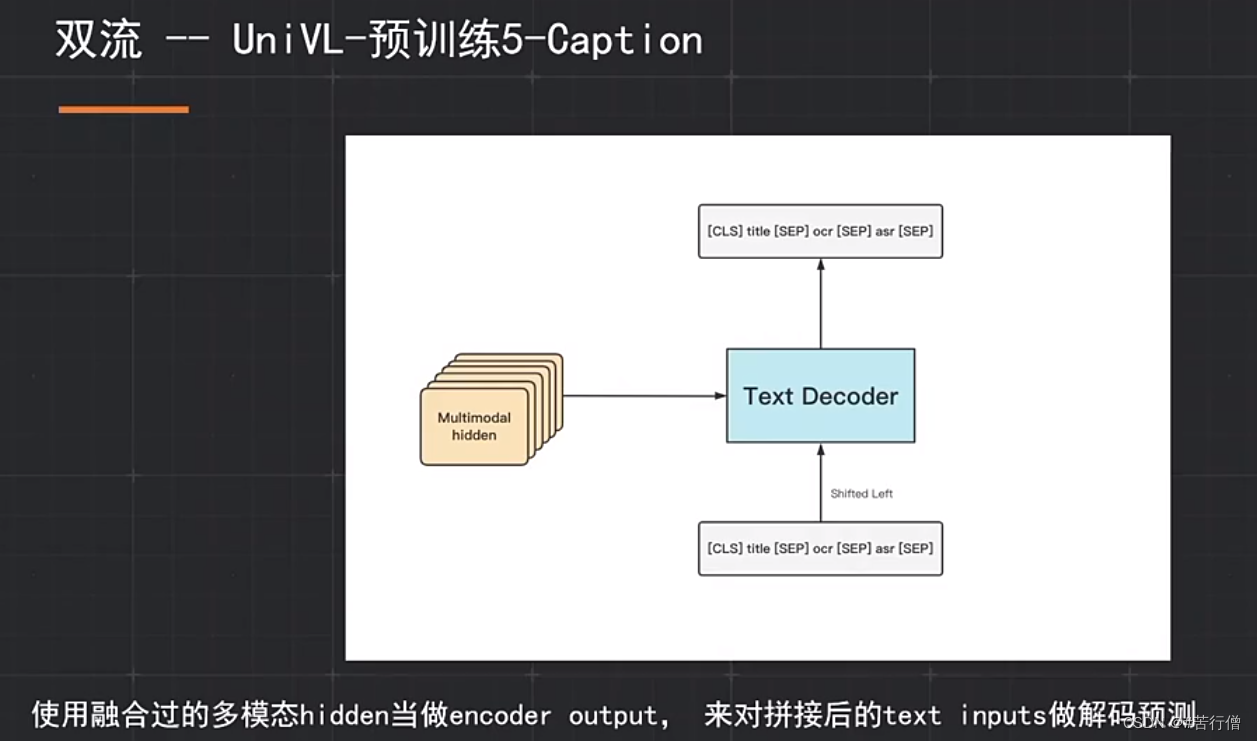


提问环节总结:
1、初赛准备了10几个预训练任务,不同预训练任务如何组合,消融实验成本太大,帧数缩小,用large模型来做可能效果更好,但时间不够去测试。
2、asr,ocr的噪声去除后发现性能下降。用asr的波形来做一个特征或许不错等。
3、模型加速方面 可考虑 蒸馏、剪枝、int8加速。
张正友老师最后总结: 【总体创新性不够,如title, asr, ocr直接拼接有点简单,不同模态的交互方式,还有不平衡问题的处理,打标问题等。】
大佬们都很强!向大佬学习!希望大佬们最后能够开源代码,促进大家的交流学习!😄😄

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











