







文章目录
特点:
非过程化、简单易学、易迁移、高度统一
4种语言子集:
- **DDL(Data Definition Language,数据定义语言):**定义、修改、删除数据模式,通常包括
CREATE TABLE、ALTER TABLE、DROP TABLE等操作。 - **DQL(Data Query Language,数据查询语言):**查询数据。DQL指的是以
SELECT命令开始的SQL语句,对数据表中的数据进行投影、选择、连接等操作。 - **DML(Data Manipulation Language,数据操作语言):**插入、删除、更新数据,主要包括
INSERT、DELETE、UPDATE等操作。 - **DCL(Data Control Language,数据控制语言):**控制用户对数据的访问权限,主要包括
GRANT、REVOKE等操作。
1. 数据类型
-
字符串型

-
数值类型

-
时间/日期

-
常用类型说明

2. 表模型定义
2.1 创建表 - CREATE
在关系模型中,每个关系是一个数据实体,在SQL中可以通过CREATE TABLE命令创建一个基本表来代表一个“关系”,具体语句如下:
CREATE TABLES 表名 (
列名 列数据类型,
列名 列数据类型,
......
)
例2-1 创建一个包含仓库信息的基本表:
CREATE TABLE warehouse (
w_id SMALLINT,
w_name VARCHAR(10),
w_street_1 VARCHAR(20),
w_street_2 VARCHAR(20),
w_city VARCHAR(20),
w_state CHAR(2),
w_zip CHAR(9),
w_tax DECIMAL(4,2),
w_ytd DECIMAL(12,2)
);
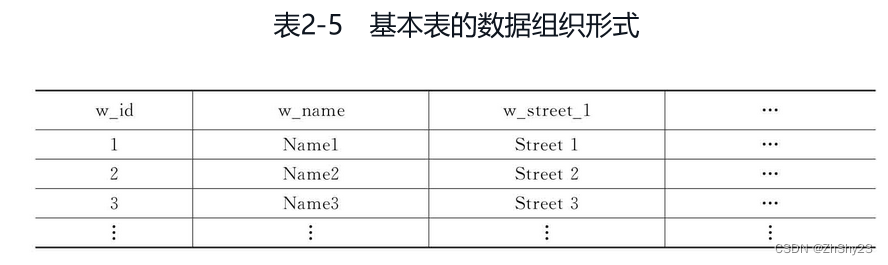
其中CREATE TABLE创建一个保存仓库信息的基本表,warehouse是要创建的基本表的名称,warehouse基本表中有9个列(属性),每个列都有自己固有的数据类型,可以根据列的要求指定其对应的长度、精度等信息,例如w_id是仓库的编号信息,通过SAMALLINT类型表示编号,而w_name是仓库的名称,为VARCHAR类型,其最大长度是10。
warehouse基本表建立之后,在数据库内会建立一个模式,DML语句、DQL语句会根据这个模式来访问warehouse表中的数据。
基本表的数据组织形式:
2.2 修改表 - ALTER TABLE
在基本表创建之后,还可以通过ALTER TABLE语句来修改基本表的模式,可以增加新的列、删除已有的列、修改列的类型等。
例2-2 在warehouse基本表中增加一个mgr_id(管理员编号)的列。
ALTER TABLE warehouse ADD COLUMN mgr_id INTEGER;
如果基本表中已经存在数据,那么在增加了新的列之后,默认会将这个列中的值指定为NULL。
2.3 删除列 - ALTER TABLE…DROP COLUMN…
如果要删除基本表中的某个列,则可以使用ALTER TABLE…DROP COLUMN…语句实现。
例2-3 在warehouse基本表中删除管理员编号的列。
ALTER TABLE warehouse DROP COLUMN mgr_id;
2.4 修改列类型 - ALTER TABLE…ALTER COLUMN…
如果要修改基本表中某个列的类型,则可以通过ALTER TABLE…ALTER COLUMN…语句实现。
例2-4 修改warehouse基本表中w_id列的类型。
ALTER TABLE warehouse ALTER COLUMN w_id TYPE INTEGER;
修改列的数据类型时会导致基本表中的数据类型同时被强制转换类型,因此需要数据库本身支持转换前的数据类型和转换后的数据类型满足“类型兼容。
如果将warehouse基本表中的w_city列转换为INTEGER类型,由于w_city列本身是字符串类型(且字符串内容为非数值型字符),这种转换有可能是无法正常进行的。
2.5 删除表 - DROP TABLE
如果一个基本表已经没有用了,则可以通过DROP TABLE语句将其删除。
例2-5 删除warehouse基本表。
DROP TABLE warehouse;
基本表的删除分为两种模式:RESTRICTED模式和CASCADE模式。
如果没有指定具体的模式,则使用默认的RESTRICTED模式,该模式只尝试删除基本表本身,如果基本表上有依赖项,例如视图、触发器、外键等,那么删除不成功。
而CASCADE模式下,会同时删除基本表相关的所有依赖项。
例2-6 以CASCADE模式删除warehouse基本表,删除基本表的同时视图也会被删除。
CREATE VIEW warehouse_view AS SELECT * FROM warehouse;
DROP TABLE warehouse CASCADE;
3. 数据完整性检查
关系模型的数据完整性主要是为了保证数据不会被破坏,具体可以分为域完整性、实体完整性、参照完整性和用户定义完整性,其中用户定义完整性是指用户在具体的应用环境下对数据库提出的约束要求。
在创建基本表的同时,还可以指定表中数据完整性约束,例如在创建warehouse基本表时,通过分析可以得到如下结论:
- 不同的仓库必须有不同的
w_id,且w_id不能为NULL。 - 仓库必须有具体的名称,不能为
NULL。 - 仓库所在的街区地址的长度不能为
0。 - 仓库所在的国家默认为
'CN'。
例2-7 创建带有完整性约束的基本表。
CREATE TABLE warehouse (
w_id SMALLINT PRIMARY KEY,
w_name VARCHAR(10) NOT NULL,
w_street_1 VARCHAR(20) CHECK(LENGTH(w_street_1) <> 0),
w_street_2 VARCHAR(20) CHECK(LENGTH(w_street_2) <> 0),
w_city VARCHAR(20),
w_state CHAR(2) DEFAULT 'CN',
w_zip CHAR(9),
w_tax DECIMAL(4,2),
w_ytd DECIMAL(12,2)
);
如果向warehouse基本表中写入不符合完整性约束的值,那么数据不能被写入,数据库会提示错误。
例2-8: 向w_name列中写入NULL值,不符合完整性约束,写入数据时会报错,数据写入不成功。具体语句如下:
INSERT INTO warehouse VALUES(1, NULL, '', '', NULL, 'CN', NULL, 1.0, 1.0);
ERROR: null value in column "w_name" violates not-null constraint
DETAIL: Failing row contains (1, null, , , null, CN, null, 1.00, 1.00).
除了在列定义之后指定完整性约束之外,还可以使用表级的完整性约束来指定。
例2-9: 在表定义上指定完整性约束,注意NULL约束只能在列定义上指定。具体语句如下:
CREATE TABLE warehouse (
w_id SMALLINT,
w_name VARCHAR(10) NOT NULL, # 设置NULL约束
w_street_1 VARCHAR(20),
w_street_2 VARCHAR(20),
w_city VARCHAR(20),
w_state CHAR(2) DEFAULT 'CN', # 设置默认值
w_zip CHAR(9),
w_tax DECIMAL(4,2),
w_ytd DECIMAL(12,2).
CONSTRAINT w_id_pkey PRIMArY KEY(w_id), # 增加主键约束
CONSTRAINT w_street_1 CHECK(LENGTH(w_street_1) < 100), # 增加CHECK约束
CONSTRAINT w_street_2 CHECK(LENGTH(w_street_2) < 100), # 增加CHECK约束
);
当一个表中的某一列或多列恰好引用的是另一个表的主键(或具有唯一性)时,可以考虑将其定义为外键,外键表示两个表之间相互的关联关系,包含主键的表通常可以称为主表,而包含外键的表则可以称为从表。外键的定义可以直接在属性上定义,也可以在基本表的创建语句中定义,两种方法本质上没有区别。
例2-10: 在新建订单表(new_orders)中引用了仓库表(warehouse)的列作为外键。具体语句如下:
CREATE TABLE new_orders
(
no_o_id INTEGER NOT NULL,
no_d_id SMALLINT NOT NULL,
no_w_id SMALLINT NOT NULL REFERENCES warehouse(w_id)
);
除了在创建基本表的同时指定完整性约束之外,还可以通过ALTER TABLE语句对完整性约束进行修改。
例2-11: 在基本表warehouse上增加主键列。
ALTER TABLE warehouse ADD PRIMARY KEY (w_id);
例2-12: 在基本表warehouse上增加CHECK约束。
ALTER TABLE warehouse ADD CHECK(LENGTH(w_street_1) < 100);
例2-13: 在基本表warehouse上增加外键引用。
ALTER TABLE warehouse ADD FOREIGN KEY(no_w_id) REFERENCES warehouse(w_id);
例2-14: 在基本表new_orders上增加唯一列。
ALTER TABLE new_orders ADD UNIQUE(no_o_id, no_d_id, no_w_id);
4. 插入、删除、更新数据
基本表创建之后是一个空的集合,这时就可以对基本表做DML操作,如插入、删除以及更新基本表中的数据。
例2-15: 向new_orders基本表中插入数据。
INSERT INTO new_orders VALUES(1,1,1);
INSERT INTO new_orders VALUES(2,2,2);
例2-16: 删除new_orders基本表中no_o_id=3的元组。
INSERT INTO new_orders VALUES(3,3,3);
DELETE FROM new_orders WHERE no_o_id = 3;
例2-17: 更新new_orders基本表中的no_w_id列的值为3。
UPDATE new_orders SET no_w_id = 3 WHERE no_o_id = 2;
5. 简单查询
最基本的SQL查询结构通常由SELECT、FROM、WHERE构成,其中包含了关系代数中的投影(Projection)、选择(Selection)和连接(Join)。
SELECT projection FROM join WHERE selection;
连接(Join)可以由一个基本表构成,也可以是多个基本表的连接结果.选择(Selection)操作是一组针对连接操作产生的结果的表达式,这些表达式为BOOL类型,它们对连接产生的结果做过滤,过滤之后的元组会组成新的中间关系.- 最后由
投影(Projection)操作输出。
例2-18: 获得warehouse基本表中的数据
SELECT w_name FROM warehouse WHERE w_id = 1;
对应的关系代数表达式:
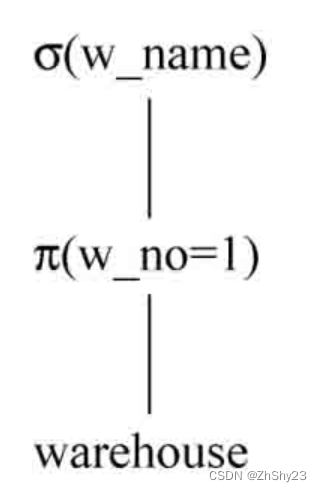
6. 连接操作
如果FROM关键字后有超过2个及以上(含2个)的表参与连接操作,则该查询可以称为连接查询,也可以叫作多表查询。
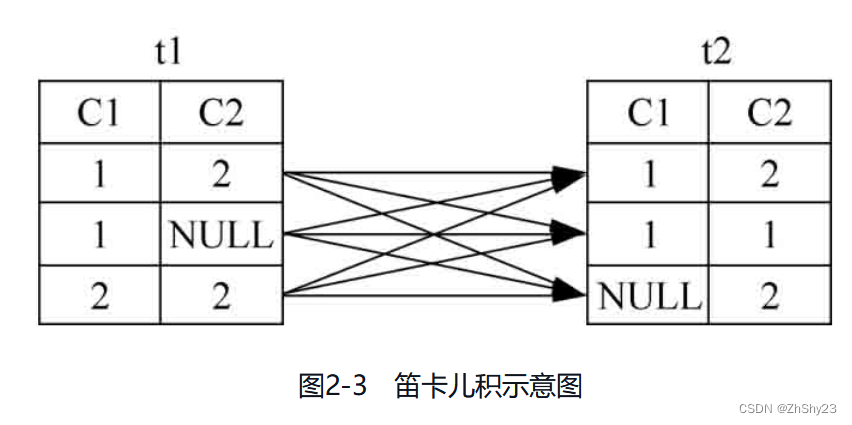
连接查询是SQL中最基本的操作,它的本质是多个表之间做笛卡儿积,借由这个思想又衍生出自然连接、θ连接等。

CREATE TABLE t1 (
C1 INTEGER,
C2 INTEGER
);
INSERT INTO t1 VALUES (1,2), (1,NULL), (2,2);
CREATE TABLE t2 (
C1 INTEGER,
C2 INTEGER
);
INSERT INTO t2 VALUES (1,2), (1,1), (NULL,2);
CREATE TABLE t3 (
C1 INTEGER,
C2 INTEGER
);
INSERT INTO t3 VALUES (1,1), (1,2);
6.1 WHERE连接
通常的多表连接可以通过如下形式来实现:
SELECT projection FROM t1, t2, t3 ... WHERE selection;
例2-19: 对t1、t2、t3这3个表做连接操作,通过“,”间隔,位于FROM关键字的后面,表示需要将这3个表做连接操作。
SELECT * FROM t1, t2, t3 WHERE t1.c1 = 1;
6.2 JOIN连接
如果2个基本表确定做笛卡儿积操作,则可以在SQL中显式地指定做笛卡儿积的关键字。
例2-20: 对表t1、表t2做笛卡儿积
SELECT * FROM t1 CROSS JOIN t2;
c1 | c2 | c1 | c2
----+----+----+----
1 | 2 | 1 | 2
1 | 2 | 1 | 1
1 | 2 | | 2
1 | | 1 | 2
1 | | 1 | 1
1 | | | 2
2 | 2 | 1 | 2
2 | 2 | 1 | 1
2 | 2 | | 2
(9 rows)
6.2.1 等值连接与自然连接
-
等值连接
连接操作还能指定连接条件,如果连接条件中是等值条件,那么这种连接可以称为等值连接。
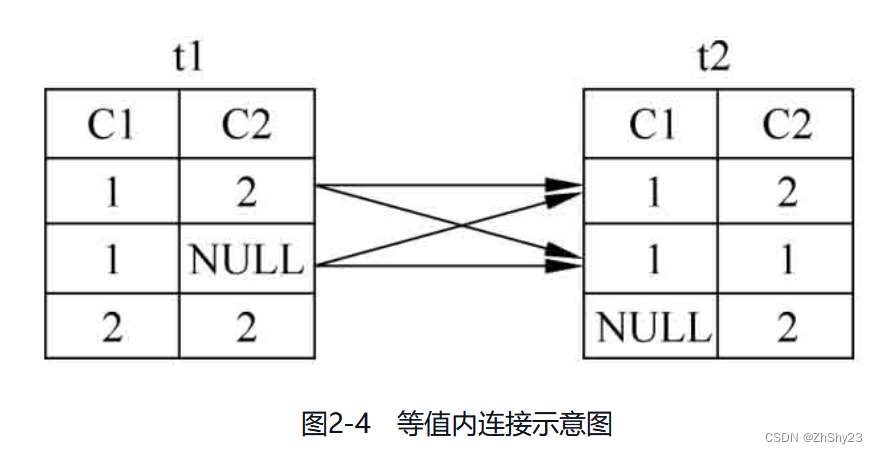
例2-21: 对表t1、t2做等值内连接
SELECT * FROM t1 INNER JOIN t2 ON t1.c1 = t2.c1; c1 | c2 | c1 | c2 ----+----+----+---- 1 | 2 | 1 | 1 1 | 2 | 1 | 2 1 | | 1 | 1 1 | | 1 | 2 (4 rows) -
自然连接
在等值连接的基础上,还衍生出来一种新的连接方式:自然连接。如果进行连接的两个基本表中有相同的属性,那么自然连接会在这些相同的属性上自动做等值连接,而且会自动去掉重复的属性,而等值连接会保留两个表中重复的属性。
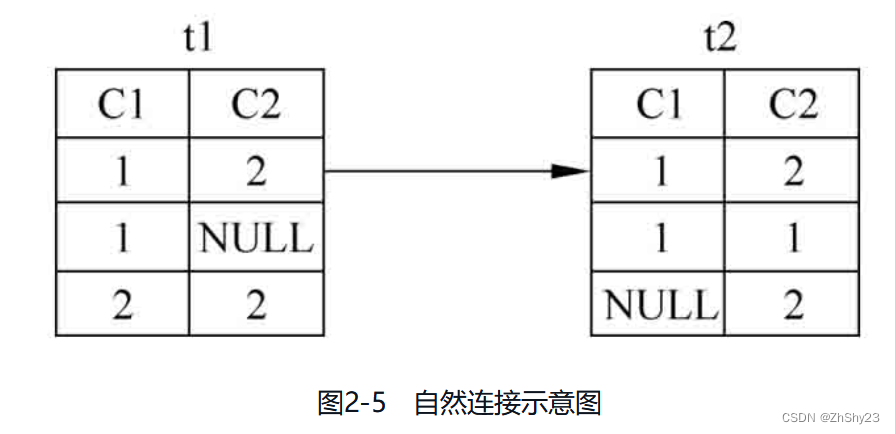
例2-22: 对表t1、t2做自然连接
SELECT * FROM t1 NATURAL JOIN t2; c1 | c2 ----+---- 1 | 2 (1 row)
6.2.2 连接结果 - 内、外、半连接
另外从连接结果的角度来划分,连接又可以分为内连接(Inner Join)、外连接(Outer Join)、半连接(Semi Join)

-
内连接
例2-23: 对表t2、表t3做等值内连接
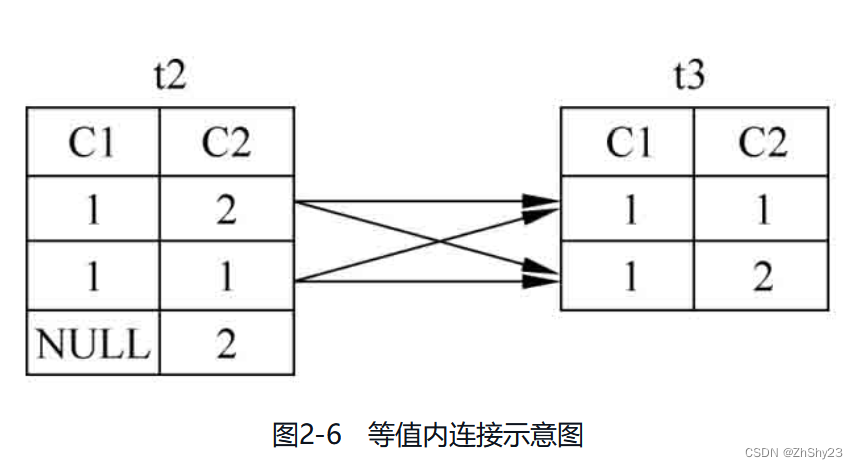
SELECT * FROM t2 INNER JOIN t3 ON t2.c1 = t3.c1; c1 | c2 | c1 | c2 ----+----+----+---- 1 | 2 | 1 | 2 1 | 2 | 1 | 1 1 | 1 | 1 | 2 1 | 1 | 1 | 1 (4 rows) -
外连接
例2-24: 对表t1、表t2做等值左外连接
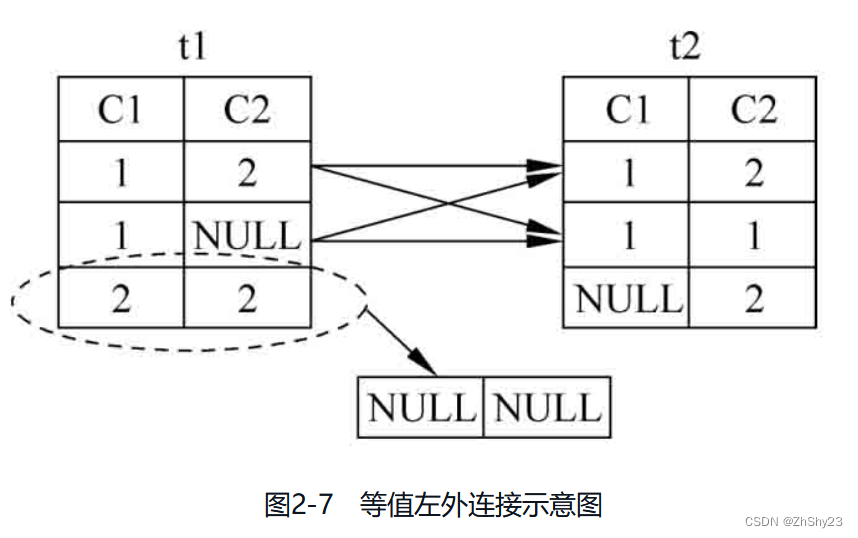
SELECT * FROM t1 LEFT JOIN t2 ON t1.c1 = t2.c1; c1 | c2 | c1 | c2 ----+----+----+---- 1 | 2 | 1 | 1 1 | 2 | 1 | 2 1 | | 1 | 1 1 | | 1 | 2 2 | 2 | | (5 rows)例2-25: 对表t1、表t2做等值右外连接
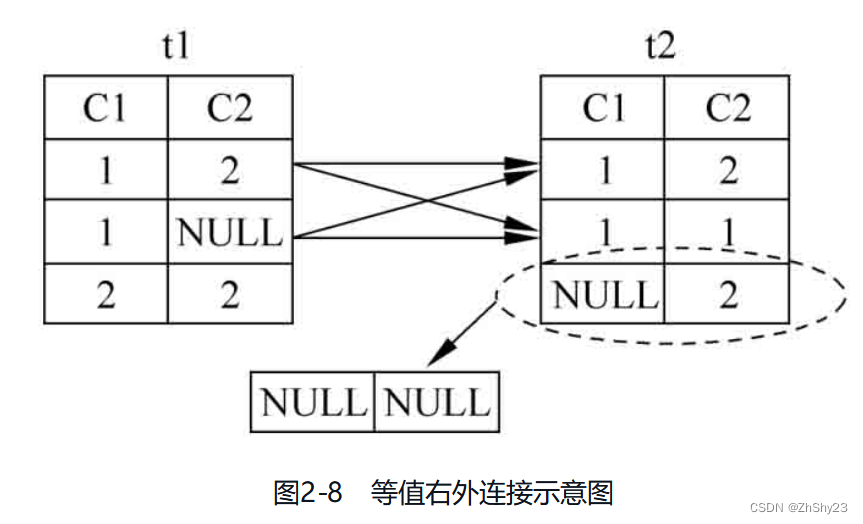
SELECT * FROM t1 RIGHT JOIN t2 ON t1.c1 = t2.c1; c1 | c2 | c1 | c2 ----+----+----+---- 1 | | 1 | 2 1 | 2 | 1 | 2 1 | | 1 | 1 1 | 2 | 1 | 1 | | | 2 (5 rows) -
全连接
例2-26: 对表t1、表t2做等值全连接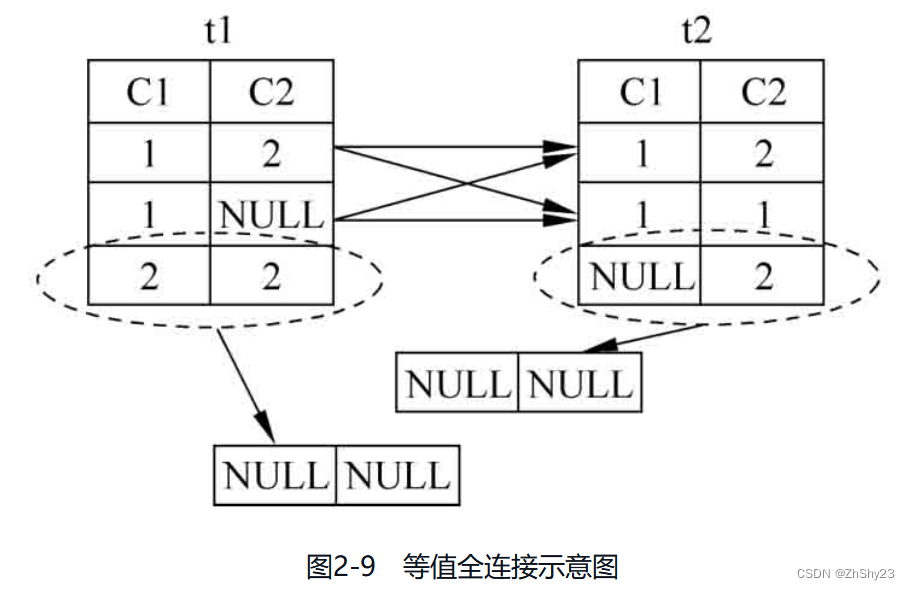
SELECT * FROM t1 FULL JOIN t2 ON t1.c1 = t2.c1; c1 | c2 | c1 | c2 ----+----+----+---- 1 | 2 | 1 | 1 1 | 2 | 1 | 2 1 | | 1 | 1 1 | | 1 | 2 2 | 2 | | | | | 2 (6 rows)
6.2.3 Semi Join
例2-27: 对表t1、表t2做Semi Join操作,对于t1表中的t1.c1,都在t2表中探测有没有和其相等的t2.c1,如果能找到就代表符合条件,和普通的连接不同的是,只要找到第一个和其相等的t2.c1就代表满足连接条件.
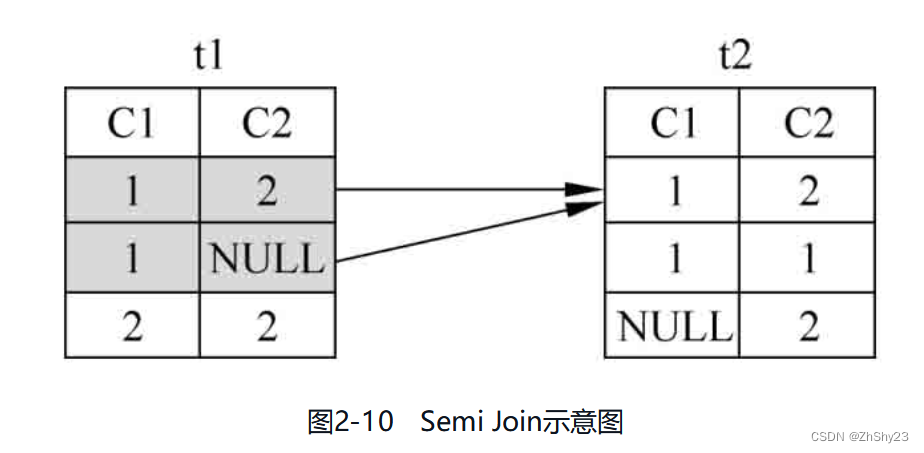
SELECT * FROM t1 WHERE t1.c1 IN (SELECT t2.c1 FROM t2);
c1 | c2
----+----
1 | 2
1 |
(2 rows)
6.2.4 Anti-Semi Join
例2-28: 对表t1、表t2做Anti-Semi Join操作,和Semi Join操作相对应,对于t1表中的t1.c1,只要在t2表中找到一个相等的t2.c1,就不满足连接条件
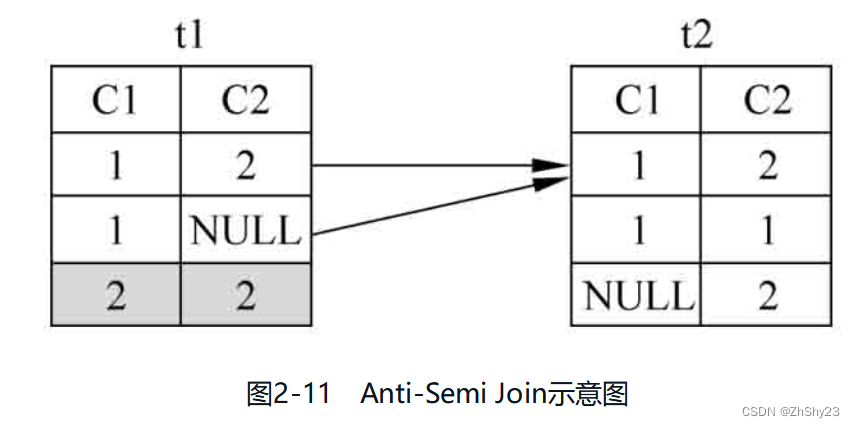
SELECT * FROM t1 WHERE t1.c1 NOT IN (SELECT t2.c1 FROM t2 WHERE t2.c1 IS NOT NULL);
c1 | c2
----+----
2 | 2
(1 row)
7. 集合操作

7.1 UNION - 并操作
例2-29: 对表t1、表t2做UNION操作
SELECT * FROM t1 UNION SELECT * FROM t2;
c1 | c2
----+----
1 | 1
1 |
| 2
1 | 2
2 | 2
(5 rows)
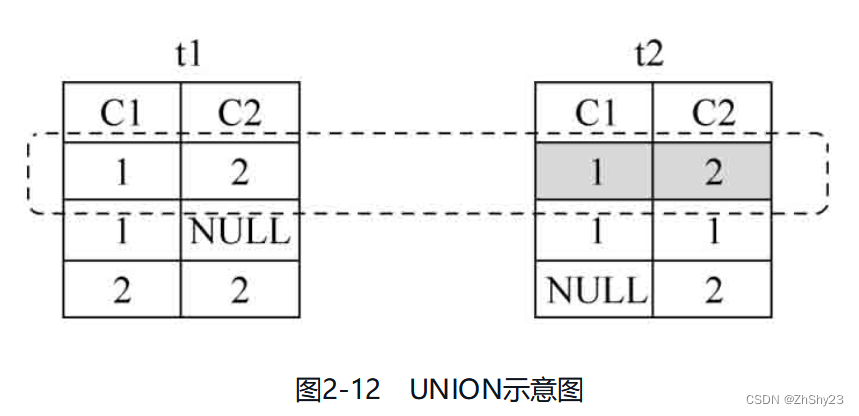
7.2 EXCEPT - 差操作
例2-30: 对表t1、表t2做EXCEPT操作
SELECT * FROM t1 EXCEPT SELECT * FROM t2;
c1 | c2
----+----
1 |
2 | 2
(2 rows)
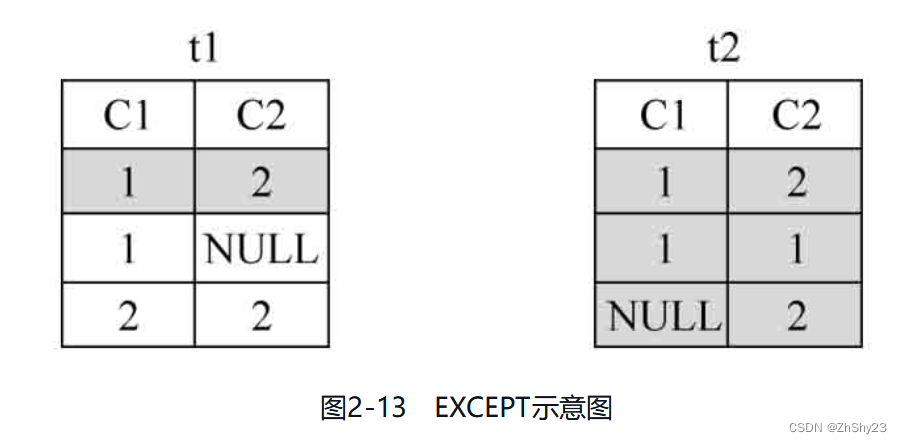
7.3 INTERSECT - 交集
例2-31: 对表t1、表t2做INTERSECT操作
SELECT * FROM t1 INTERSECT SELECT * FROM t2;
c1 | c2
----+----
1 | 2
(1 row)
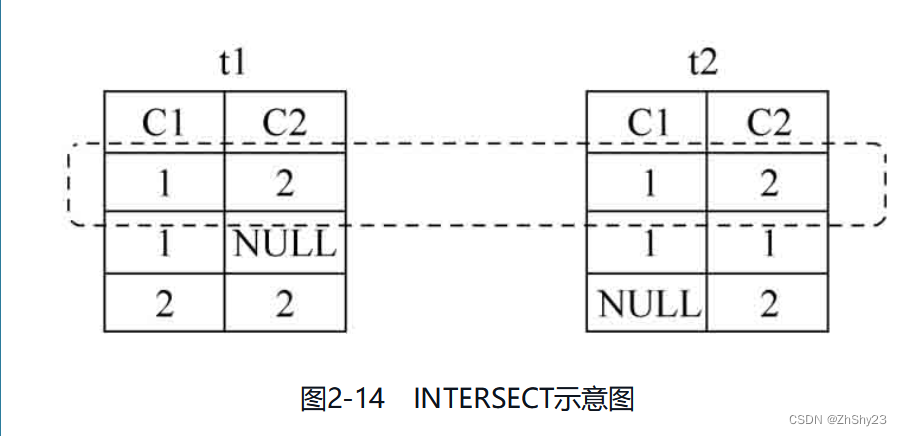
7.4 DISTINCT - 去重
从示例的结果可以看出,结果集中还做了去重的操作。也就是说,UNION、EXCEPT、INTERSECT中还隐式地隐含DISTINCT操作,如果显式地指定上DISTINCT关键字,它们将得到相同的结果。
-
UNION DISTINCT
例2-32: 对表t1、表t2做UNION DISTINCT操作SELECT * FROM t1 UNION DISTINCT SELECT * FROM t2; c1 | c2 ----+---- 1 | 1 1 | | 2 1 | 2 2 | 2 (5 rows)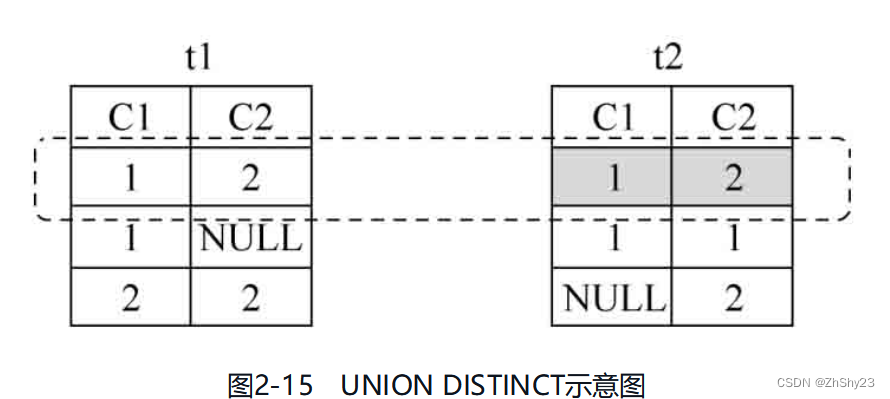
-
UNION ALL
如果不需要进行去重,可以通过指定ALL关键字实现。
例2-33: 对表t1、表t2做UNION ALL操作SELECT * FROM t1 UNION ALL SELECT * FROM t2; c1 | c2 ----+---- 1 | 2 1 | 2 | 2 1 | 2 1 | 1 | 2 (6 rows)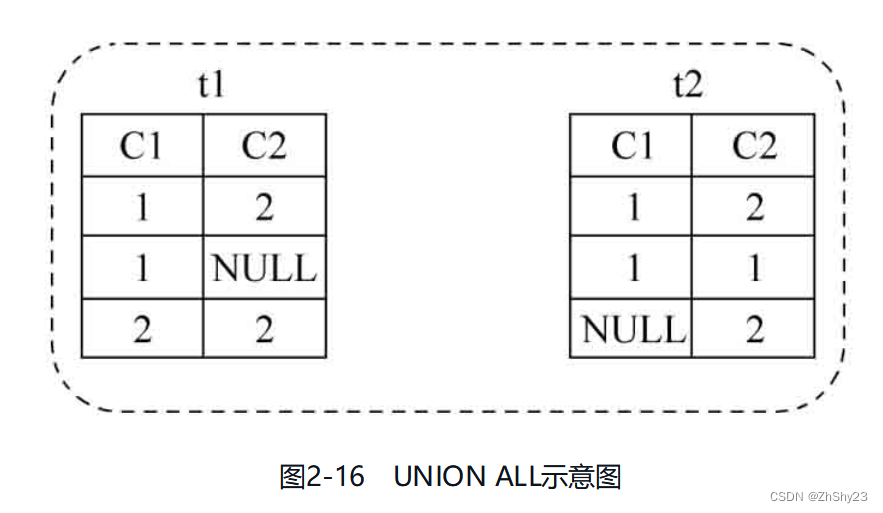
8. 聚集与分组操作
8.1 COUNT - 计数
- 对于
COUNT函数,可以将参数指定为“*”,这样就会统计所有的元组数量,即使元组中包含NULL值,仍然会进行统计。
例2-34: 对t1表的所有元组数量进行统计SELECT COUNT(*) FROM t1; count ------- 3 (1 row) - 如果给
COUNT函数的参数指定为表达式(或列值),则只统计表达式结果为非NULL值的个数。
例2-35: 对t1表的c2列中的非NULL值的个数进行统计SELECT COUNT(c2) FROM t1; count ------- 2 (1 row) - 如果在参数中指定了
DISTINCT关键字,则先对结果中的值去掉重复值,然后再统计数量,如果不指定DISTINCT,则默认为ALL。
**例2-36:**对t1表的c1列中的非NULL值的个数进行统计,去掉重复值。SELECT COUNT(DISTINCT t1.c1) FROM t1; count ------- 2 (1 row)
8.2 SUM - 求和
例2-37: 对表t1的c1列做求和操作。
SELECT SUM(c1) FROM t1;
sum
-----
4
(1 row)
8.3 AVG - 平均值
**例2-38:**对表t1的c1列求平均值。
SELECT AVG(c1) FROM t1;
avg
--------------------
1.3333333333333333
(1 row)
8.4 MAX - 最大值
SELECT MAX(c1) FROM t1;
max
-----
2
(1 row)
8.5 MIN - 最小值
SELECT MIN(c1) FROM t1;
min
-----
1
(1 row)
8.6 GROUP BY - 分组
在实际场景中,可能会统计每个组织所包含的人数,假设有一个组织成员信息表:
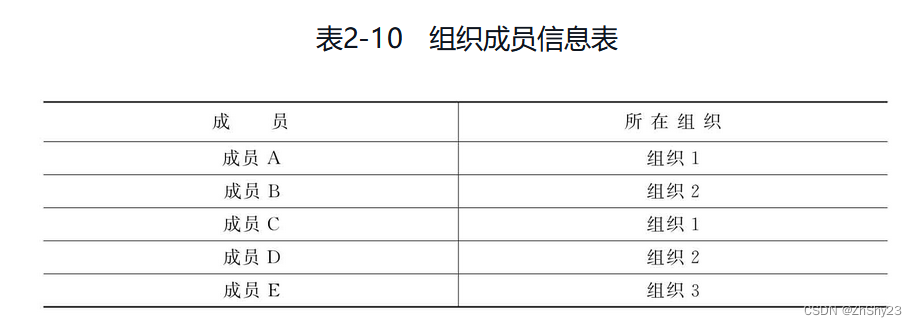
那么要获得每个组织的人数就需要执行多次查询才能实现
SELECT COUNT(*) FROM 成员 WHERE 成员组织 = 1;
SELECT COUNT(*) FROM 成员 WHERE 成员组织 = 2;
...
使用分组方法可以方便地解决这个问题,分组方法使用GROUP BY关键字来指定,通常形式如下:
GROUP BY column1, column2, ...
如果要简化上面的多条语句,则可以通过GROUP BY方法来实现,下面的方法可以统计每个组织中成员的数量:
SELECT 组织, COUNT(*) FROM 成员 GROUP BY 成员组织;
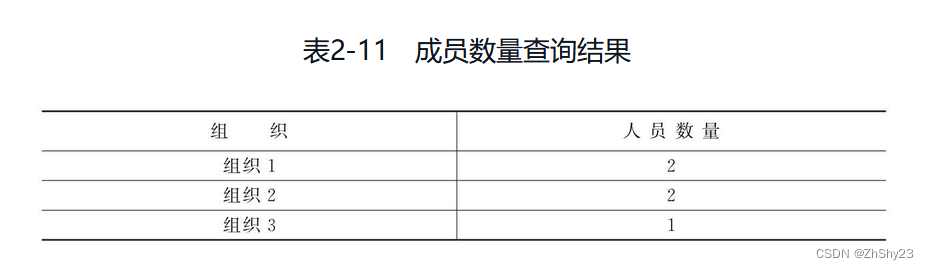
另外还可以考虑使用HAVING操作帮助筛选出符合条件的成员(找出成员人数大于1的成员组织)
SELECT 组织, COUNT(*) FROM 成员 GROUP BY 成员组织 HAVING COUNT(*) > 1;
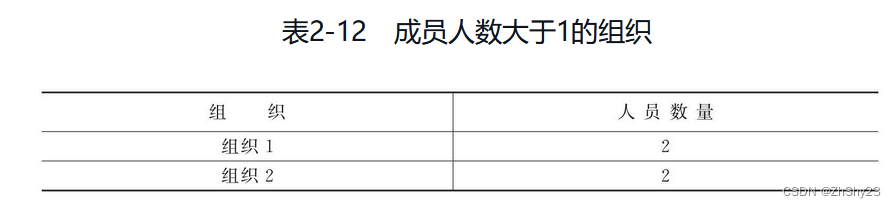
例2-39: 根据表t1的c2列做分组,求每个分组内c1的个数。
SELECT c2, COUNT(c1) FROM t1 GROUP BY c2;
c2 | count
----+-------
| 1
2 | 2
(2 rows)
例2-40: 根据表t1的c2列做分组,求每个分组内c1的个数,将个数大于1的分组投影出来。
SELECT c2, COUNT(c1) FROM t1 GROUP BY c2 HAVING COUNT(c1) > 1;
c2 | count
----+-------
2 | 2
(1 row)
9. 创建索引
常见的索引有B树索引、哈希(Hash)索引、位图索引等。
创建索引使用的是CREATE INDEX语句,它需要制定索引的名称以及要创建索引的基本表和基本表上的候选列。
CREATE INDEX <索引名> ON <基本表名> (<列名1>, <列名2>, ...);
例2-41: 为warehouse基本表创建一个基于w_id列的索引,默认是B树索引。具体语句如下:
CREATE INDEX warehouse_index ON warehouse (w_id);
可以通过UNIQUE关键字来指定创建的索引是否具有唯一性。
例2-42: 为new_orders基本表创建一个基于全部列的索引。具体语句如下:
CREATE TABLE new_orders
(
no_o_id INTEGER NOT NULL,
no_d_id SMALLINT NOT NULL,
no_w_id SMALLINT NOT NULL
);
CREATE UNIQUE INDEX new_orders_index ON new_orders(no_o_id, no_d_id, no_w_id);
UNIQUE关键字指定的唯一性和主键的唯一性有一些不同。主键中的所有列不能有NULL值,而UNIQUE关键字创建的唯一索引可以允许有NULL值,由于NULL值在SQL中代表的是不确定的值,无法做等值比较,所以UNIQUE索引的唯一性表现在可以具有NULL值,而且可以有多组NULL值。
例2-43: 即使new_orders基本表上有UNIQUE索引,也可以插入多组NULL值。具体语句如下:
CREATE UNIQUE INDEX new_orders_index ON new_orders(no_o_id, no_d_id, no_w_id);
INSERT INTO new_orders VALUES(NULL, NULL, NULL);
INSERT INTO new_orders VALUES(NULL, NULL, NULL);
10. 视图与物化视图
一个数据库通常分成外模式、模式和内模式三种模式:
- 外模式:也叫用户模式,是用户所能访问的一组数据视图,和某一应用的逻辑结构有关,是从模式中导出的一个子集,针对某一具体应用控制访问的可见性。
- 模式:数据库内所包含的逻辑结构,包括基本表的定义等。
- 内模式:数据库内部数据的存储方式,包括数据是否加密、压缩等。
数据库中的视图属于数据库的外模式,可以在不暴露整个数据库逻辑模型的基础上,让用户访问所需的数据。
例2-44:创建一个与warehouse表相关的视图,只能显示仓库的名称。具体语句如下:
CREATE VIEW warehouse_name AS SELECT w_name FROM warehouse;
例2-45:创建一个与warehouse表相关的视图,只显示编号小于10的仓库的名称和地址。具体语句如下:
CREATE VIEW warehouse_idlt10 AS SELECT w_name, w_street_1 FROM warehouse WHERE w_id < 10;
访问视图的方法和访问基本表完全一样,因此可以直接使用SELECT语句来访问视图。由于视图本身是一个“虚表”,是由模式映射出来的一种外模式,本身不保存数据,因此当基本表的数据发生变化时,视图中的数据也会同时发生变化。
视图本身不保存数据,这种特质也决定了无法对所有的视图进行INSERT、UPDATE、DELETE操作,通常数据库只支持针对比较简单的视图做增、删、改的操作.
例2-46:通过视图修改warehouse表中仓库的名称。具体语句如下:
CREATE VIEW warehouse_view AS SELECT * FROM warehouse;
UPDATE warehouse_view SET w_name = 'bj' where w_name = 'lf';
除了普通的视图之外,还有一种物化视图。物化视图本身是保存数据的,它和普通视图的区别是在DML操作中,对普通视图的操作会映射到基本表,而对物化视图的操作则直接作用到物化视图本身。
当基本表的数据发生变化时,物化视图中的数据也会同步地发生相同的变化。由于物化视图通常是基本表的子集,因此如果要查询的数据在物化视图中时,直接访问物化视图会提高访问效率,但是同时也会带来维护的开销。如果一个基本表频繁地被INSERT、DELETE、UPDATE语句操作数据,那么物化视图同步更新带来的开销可能就会大于访问性能提升所带来的好处,因此需要根据应用的具体情况决定是否使用物化视图。
例2-47:创建一个warehouse name相关的物化视图。具体语句如下:
CREATE MATERIALIZED VIEW warehouse_name AS SELECT w_name FROM warehouse;
11. 访问控制
SQL可以针对不同的数据库对象赋予不同的权限,这样就可以限制用户对数据的不必要访问,提高数据访问的安全性。
常见的SQL权限如下:
SELECT/UPDATE/DELETE/INSERT:访问、修改基本表或视图的权限;REFERENCES:在基本表上创建外键约束的权限;TRIGGER:在基本表上创建触发器的权限;EXECUTE:存储过程的执行权限;GRANT:用户可以通过GRANT语句来授予权限。REVOKE:用户可以通过REVOKE语句来收回权限。
例2-48:将warehouse表的SELECT权限授予用户U1。具体语句如下:
CREATE SELECT ON TABLE warehouse TO U1;
例2-49:将warehouse表的(w_id,w_name)列的SELECT权限授予用户U1。具体语句如下:
CREATE SELECT (w_id, w_name) ON TABLE warehouse TO U1;
例2-50:将warehouse表的SELECT权限从用户U1收回。具体语句如下:
REVOKE SELECT ON TABLE warehouse TO U1;
例2-51:将warehouse表的(w_id,w_name)列的SELECT权限从用户U1收回。具体语句如下:
REVOKE SELECT (w_id, w_name) ON TABLE warehouse TO U1;
12. 事务处理语句
事务是由一组SQL语句序列构成的原子操作集合,它具有原子性、一致性、隔离性和持久性的特点。
用户在开始执行一个SQL语句时,实际上就已经开始了一个隐式的事务,而SQL语句执行结束,隐式的事务也会根据SQL语句的执行成功与否分别进行提交(Commit)或者回滚(Rollback)操作。
但是对于多条SQL语句组成的事务,则需要显式地指定**事务块(Transaction Block)**的边界,通常通过如下SQL命令来指定事务块。
BEGIN:开始一个事务。COMMIT:在事务块中的所有SQL语句成功执行后,将事务提交,事务一旦提交,事务块中的所有修改就会被记录下来,不会产生数据丢失,保证事务的持久性。ROLLBACK:在事务执行失败时,需要将已经在事务块中执行过的SQL语句所产生的修改进行回滚,或者应用程序需要临时中断事务时,也可以显式地通过ROLLBACK命令回滚事务,在数据库重启时也会对未完成的事务做ROLLBACK处理。
例2-52:对warehouse表中的w-name(仓库名称)进行修改,然后事务提交,名称修改成功。具体语句如下:
BEGIN;
UPDATE warehouse SET w_name = 'W_LF' WHERE w_id = 1;
COMMIT;
例2-53:对warehouse表中的w-name(仓库名称)进行修改,然后事务提交,名称没有被真正地修改。具体语句如下:
BEGIN;
UPDATE warehouse SET w_name = 'W_LF' WHERE w_id = 1;
ROLLBACK;

















 1401
1401











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











