







Momentum Contrast for Unsupervised Visual Representation Learning
 https://openaccess.thecvf.com/content_CVPR_2020/html/He_Momentum_Contrast_for_Unsupervised_Visual_Representation_Learning_CVPR_2020_paper.html
https://openaccess.thecvf.com/content_CVPR_2020/html/He_Momentum_Contrast_for_Unsupervised_Visual_Representation_Learning_CVPR_2020_paper.html收录:CVPR 2020 Best paper
代码: GitHub - facebookresearch/moco: PyTorch implementation of MoCo: https://arxiv.org/abs/1911.05722
1. 背景知识
A. 什么是对比学习
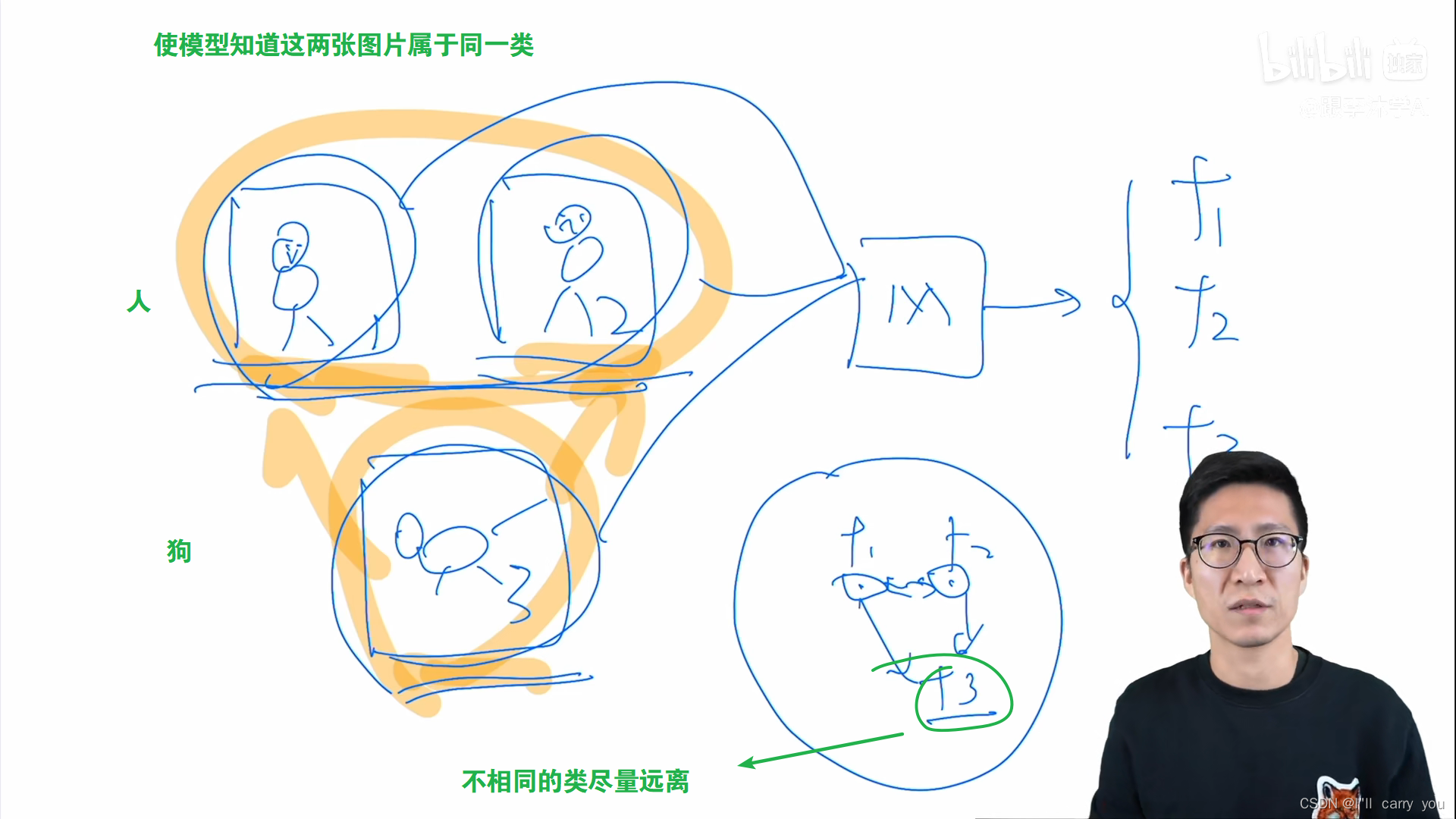
假如有两类,分别使用同一个特征提取器分别提取出特征。对比学习 希望在一个特征空间里,不同的类的特征尽量远离彼此。
B. 什么是无监督的训练方式?
在视觉领域,大家巧妙地设计代理任务,从而人为定义一些规则,这些规则可以用来定义哪些图片是相似的,哪些图片是不相似的,从而可以提供一个监督信号去训练模型,这也就是所谓的自监督训练
讲一个最广泛的代理任务:instance discrimination 如何定义哪些图片是相似的,哪些图片是不相似的呢? instance discrimination 是这么做的:只有从自己图片裁剪下来的才是正样本,属于同一类。其它都是负样本。(或者是一个物体的不同视角,一张图片是RGB还是灰度都可以作为正样本) 由此一来,每个图片都是自己的类。ImageNet就不是1000类,而是100多万类(图片总量)。
这样一个框架就是对比学习常见的实现方式了。看起来好像平平无奇,但对比学习就厉害的地方就是它的灵活性。只要你能找到一种方式定义什么是正样本,什么是负样本,剩下的操作都是比较标准。
大家大开脑洞去制定很多正样本负样本的规则,
比如在视频领域,同一视频的任意两帧都是正样本,而其它视频里所有帧都是负样本。
在NLP领域,NLP, simCSE 把同样的句子扔给模型,但是做 2 次 forward,通过不同的 dropout 得到一个句子的 2 个特征;和其它所有句子的特征都是负样本。
CMC 论文:一个物体的不同视角 view(正面、背面;RGB 图像和灰度图像;不同crop)都可以作为不同形式的正样本。
对比学习实在是太灵活了,哪个领域都能用。扩展到多模态领域,也就造就了open AI 的 CLIP 模型
3.Momentum

yt-1 是上一个时刻的输出, xt是当前的输入,m是动量超参,0~1。当m趋近于1的时候,就不怎么依赖当前的输入了。moco利用了这种特性,让字典学习的特征缓慢的更新,尽可能地保持一致。
摘要
MOCO用于无监督表征学习。我们从另外一个角度来理解对比学习,即从一个字典查询的角度来理解对比学习。moco中建立一个动态的字典,这个字典由两个部分组成:一个队列queue和一个移动平均的编码器 moving-averaged encoder。
这两个东西造就了一个更大的和更一致consistent的字典,对无监督的对比学习有很大的帮助。(队列中的样本不需要做梯度反传,因此可以在队列中存储很多负样本,从而使这个字典可以变得很大。使用移动平均编码器的目的是使队列中的样本特征尽可能保持一致,即不同的样本通过尽量相似的编码器获得特征的编码表示。)
moco under the comon linear protocol 在imageNet分类上能取得很好的结果(comon linear protocol 指 把预训练好的backbone 冻住,在加上一个linear protocol,分类,就能够做别的任务)更重要的是,moco学习到的特征能够很好的迁移到下游任务!(这是moco这篇文章的精髓,因为无监督学习的目的就是通过大规模无监督预训练,获得一个较好的预训练模型,然后能够部署在下游的其他任务上,这些下游任务通常可能没有那么多有标签数据可以用于模型训练)。MoCo can outperform its supervised pre-training counterpart in 7 detection/segmentation tasks on PASCAL VOC, COCO, and other datasets, sometimes surpassing it by large margins。这样,有监督和无监督之间的鸿沟在很大程度上被填平了。
1. introduction
GPT和BERT在NLP中证明了无监督预训练的成功。视觉领域中还是有监督占据主导地位。语言模型和视觉模型这种表现上的差异,原因可能来自于视觉和语言模型的原始信号空间的不同。语言模型任务中,原始信号空间是离散的。这些输入信号都是一些单词或者词根词缀,能够相对容易建立tokenized的字典。(tokenize:把某一个单词对映为某个特征)。有了这个字典,无监督学习能够较容易的基于它展开,(可以把字典里所有的key(条目)看成一个类别,从而无监督语言模型也类似有监督范式,即有类似于标签的东西来帮助模型进行学习,所以在NLP中,容易进行建模,且模型相对容易进行优化)。但是视觉的原始信号是在一个连续且高维的空间中的,它不像单词那样后很强的语义信息(单词能够浓缩的很好、很简洁)。所以图像(由于原始信号连续且高维
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









