







Hadoop 单点模式的安装和部署
实验环境
Linux Ubuntu 16.04
1. 首先来配置SSH免密码登陆
双击桌面命令行终端,SSH免密码登陆需要在服务器执行以下命令,生成公钥和私钥对
ssh-keygen -t rsa
出现如下内容:
Enter file in which to save the key (/home/dolphin/.ssh/id_rsa):
回车即可,出现如下内容:
Enter passphrase (empty for no passphrase):
直接回车,出现内容:
Enter same passphrase again:
直接回车,创建完成,结果内容如下:
dolphin@tools:~$ ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/dolphin/.ssh/id_rsa):
Created directory '/home/dolphin/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/dolphin/.ssh/id_rsa.
Your public key has been saved in /home/dolphin/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:bpvXc/EXrv3cyXK/1nZbPEmDYQSm/vW4+RGNQWFY7Ss dolphin@tools.hadoop-s.desktop
The key's randomart image is:
+---[RSA 2048]----+
| o.+=o |
| o oo .|
| . o.. |
| . . ooo|
| S. o.+o|
| . . .E=++|
| o o .oB=|
| . o. o.*=%|
| o. **O%|
+----[SHA256]-----+
dolphin@tools:~$
此时ssh公钥和私钥已经生成完毕,且放置在/.ssh目录下。切换到/.ssh目录下
cd ~/.ssh
可以看到~/.ssh目录下的文件
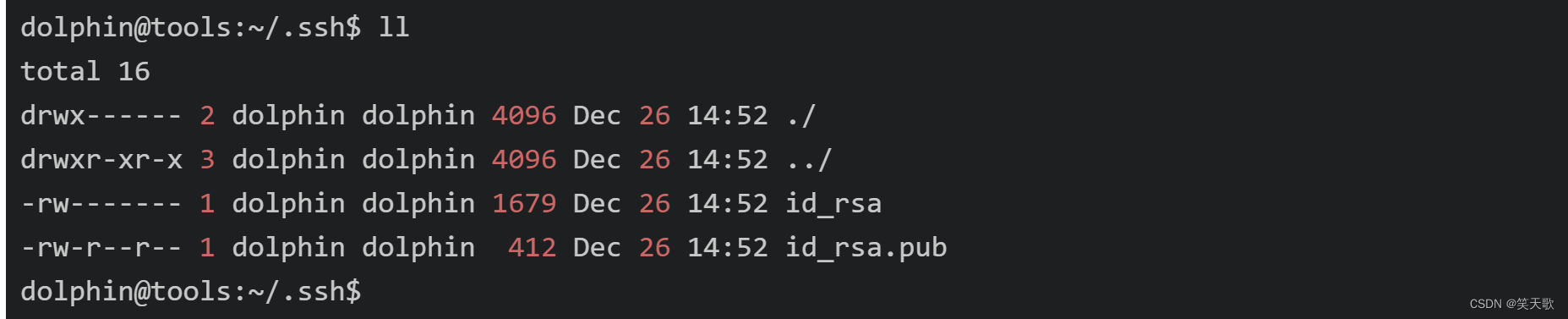
下面在~/.ssh目录下,创建一个空文本,名为authorized_keys
touch ~/.ssh/authorized_ke
h ~/.ssh/authorized_keys
将存储公钥文件的id_rsa.pub里的内容,追加到authorized_keys中
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
2. 测试ssh
下面执行ssh localhost测试ssh配置是否正确
ssh localhost
一次使用ssh访问,会提醒是否继续连接

输入yes
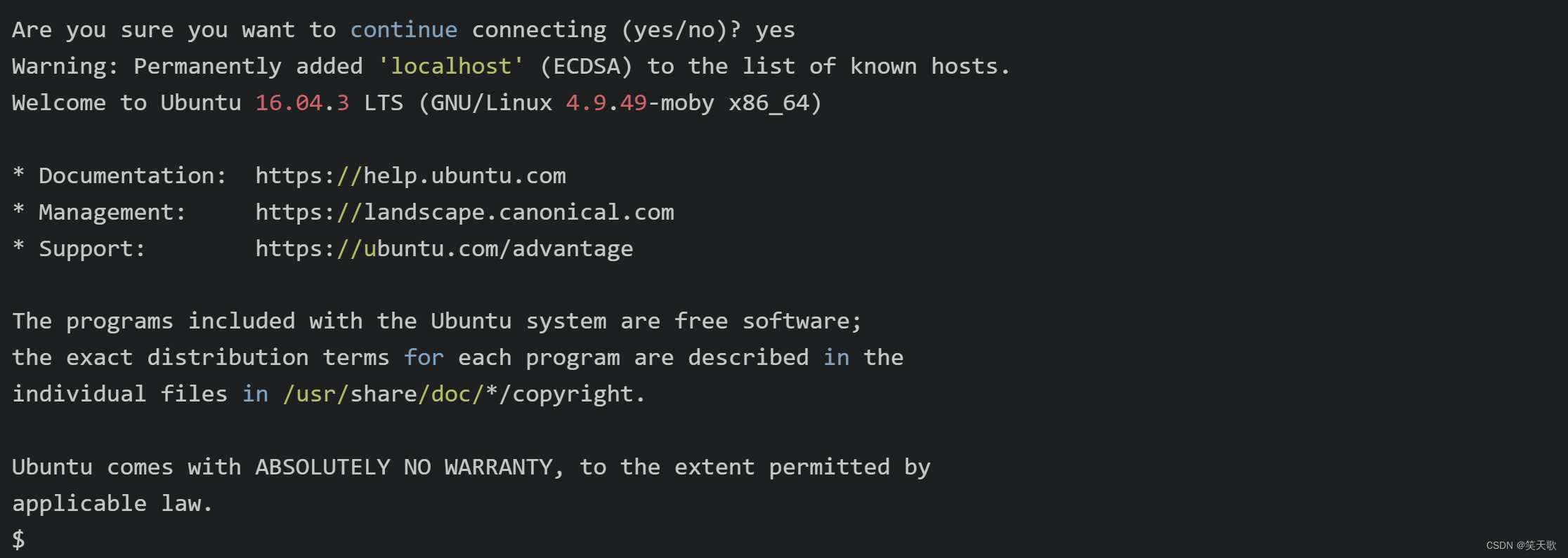
后续再执行ssh localhost时,就不用输入密码了
退出
exit
3. 下面首先来创建安装目录
sudo mkdir /apps
并为/apps目录切换所属的用户为dolphin及用户组为dolphin
udo chown -R dolphin:dolphin /apps
4. 配置HDFS
我们已经为您在/data/hadoop目录下载好了安装包:
jdk安装包:jdk-8u161-linux-x64.tar.gz
hadoop安装包:hadoop-3.0.0.tar.gz。
当您自己本地配置时请去官网下载:
jdk安装包:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
hadoop安装包:http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/
5. 安装jdk
将/data/hadoop目录下jdk-8u161-linux-x64.tar.gz 解压缩到/apps目录下。
tar -xzvf /data/hadoop/jdk-8u161-linux-x64.tar.gz -C /apps
其中,tar -xzvf 对文件进行解压缩,-C 指定解压后,将文件放到/apps目录下。
切换到/apps目录下,我们可以看到目录下内容如下:
cd /apps/
ls -l
下面将jdk1.8.0_161目录重命名为java,执行:
mv /apps/jdk1.8.0_161/ /apps/java
6. 下面来修改环境变量
系统环境变量或用户环境变量。我们在这里修改用户环境变量。
leafpad ~/.bashrc
输入上面的命令,打开存储环境变量的文件。在文件末尾空几行,将java的环境变量,追加进用户环境变量中。
#java
export JAVA_HOME=/apps/java
export PATH=$JAVA_HOME/bin:$PATH
保存并关闭编辑器
让环境变量生效。
source ~/.bashrc
执行source命令,让java环境变量生效。执行完毕后,可以输入java,来测试环境变量是否配置正确。
如果出现下面界面,则正常运行。
java -version
正常结果显示如下

7. 安装hadoop
切换到/data/hadoop目录下,将hadoop-3.0.0.tar.gz解压缩到/apps目录下。
tar -xzvf /data/hadoop/hadoop-3.0.0.tar.gz -C /apps/
为了便于操作,我们也将hadoop-3.0.0重命名为hadoop。
mv /apps/hadoop-3.0.0/ /apps/hadoop
8. 修改用户环境变量
将hadoop的路径添加到path中。先打开用户环境变量文件。
leafpad ~/.bashrc
将以下内容追加到环境变量~/.bashrc文件中。
#hadoop
export HADOOP_HOME=/apps/hadoop
export PATH=$HADOOP_HOME/bin:$PATH
让环境变量生效。
source ~/.bashrc
验证hadoop环境变量配置是否正常
hadoop version
结果内容如下:

9. 下面来修改hadoop本身相关的配置
首先切换到hadoop配置目录下。
cd /apps/hadoop/etc/hadoop
10. 配置hadoop-env.sh
输入leafpad /apps/hadoop/etc/hadoop/hadoop-env.sh,打开hadoop-env.sh配置文件。
leafpad /apps/hadoop/etc/hadoop/hadoop-env.sh
将下面JAVA_HOME追加到hadoop-env.sh文件中。
export JAVA_HOME=/apps/java
11. 配置core-site.xml
输入leafpad /apps/hadoop/etc/hadoop/core-site.xml,打开core-site.xml配置文件。
leafpad /apps/hadoop/etc/hadoop/core-site.xml
添加下面配置到
<configuration>与</configuration>
标签之间。
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
12. 配置hdfs-site.xml
输入leafpad /apps/hadoop/etc/hadoop/hdfs-site.xml,打开hdfs-site.xml配置文件。
leafpad /apps/hadoop/etc/hadoop/hdfs-site.xml
添加下面配置到
<configuration>与</configuration>
标签之间。
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
配置项说明:
dfs.replication,配置每个数据库备份数,由于目前我们使用1台节点,所以,设置为1,
如果设置为2的话,运行会报错。
13. 配置slaves
输入leafpad /apps/hadoop/etc/hadoop/slaves,打开slaves配置文件。
leafpad /apps/hadoop/etc/hadoop/slaves
将集群中slave角色的节点的主机名,添加进slaves文件中。目前只有一台节点,
所以slaves文件内容为:

14. 下面格式化HDFS文件系统。执行
hadoop namenode -format
15. 切换目录到/apps/hadoop/sbin目录下
cd /apps/hadoop/sbin/
16. 启动hadoop的hdfs相关进程
./start-dfs.sh
17. 输入jps查看HDFS相关进程是否已经启动
jps
我们可以看到以下相关进程
1072 Jps
599 NameNode
921 SecondaryNameNode
715 DataNode
18. 下面可以再进一步验证HDFS运行状态。先在HDFS上创建目录
hdfs dfs -mkdir /user
hdfs dfs -mkdir /user/dolphin
hdfs dfs -mkdir input
将输入文件复制到分布式文件系统中。
hdfs dfs -put /apps/hadoop/etc/hadoop/*.xml input
19. 执行下面命令
hadoop jar /apps/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.0.jar grep input output 'dfs[a-z.]+'
查看执行结果
hdfs dfs -cat output/*
显示如下
1 dfsadmin
1 dfs.replication
以上,便是HDFS安装过程。
20. 配置MapReduce
下面来配置MapReduce相关配置。再次切换到hadoop配置文件目录
cd /apps/hadoop/etc/hadoop
21. 配置mapred-site.xml
输入leafpad /apps/hadoop/etc/hadoop/mapred-site.xml,打开mapred-site.xml配置文件。
leafpad /apps/hadoop/etc/hadoop/mapred-site.xml
将mapreduce相关配置,添加到标签之间。
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
这里指定mapreduce任务处理所使用的框架。
22. 配置yarn-site.xml
输入leafpad /apps/hadoop/etc/hadoop/yarn-site.xml,打开yarn-site.xml配置文件。
leafpad /apps/hadoop/etc/hadoop/yarn-site.xml
将yarn相关配置,添加到标签之间。
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<property>
<name>yarn.nodemanager.disk-health-checker.max-disk-utilization-per-disk-percentage</name>
<value>98.5</value>
</property>
23. 启动
下面来启动计算层面相关进程,切换到hadoop启动目录。
cd /apps/hadoop/sbin/
24. 执行命令,启动yarn
./start-yarn.sh
执行:
jps
输出结果必须包含6个进程,结果如下:
864 DataNode
2210 Jps
1878 NodeManager
1081 SecondaryNameNode
1770 ResourceManager
748 NameNode
25. 执行测试
清空原先测试数据
hdfs dfs -rm -r output
hdfs dfs -rm -r input
添加新测试数据
touch /home/dolphin/test
echo 'test' > /home/dolphin/test
hdfs dfs -put /home/dolphin/test input
执行下面命令
hadoop jar /apps/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.0.jar wordcount input output
获取执行结果
hadoop fs -ls output
如果列表中结果包含”_SUCCESS“文件,代码集群运行成功。查看具体的执行结果,可以用如下命令:
hadoop fs -text output/part-r-00000
显示如下
test 1
至此,Hadoop 单点模式已经安装完成!
















 314
314











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









