







 本文提出了LIMU-BERT模型,利用无标签IMU数据进行自监督学习,提取泛化特征。LIMU-BERT通过融合、归一化和自注意力机制,学习到的表示可以改善下游任务的性能,如HAR和DPC。在低标注率和不同数据集上,LIMU-BERT相比于其他基线模型表现出优越的性能,证明了其有效性和泛化能力。
本文提出了LIMU-BERT模型,利用无标签IMU数据进行自监督学习,提取泛化特征。LIMU-BERT通过融合、归一化和自注意力机制,学习到的表示可以改善下游任务的性能,如HAR和DPC。在低标注率和不同数据集上,LIMU-BERT相比于其他基线模型表现出优越的性能,证明了其有效性和泛化能力。
LIMU-BERT: Unleashing the Potential of Unlabeled Data for IMU Sensing Applications
题目重点:
- 充分利用无标签数据
- 适用于IMU传感器应用(并没有指出specfic task)
文章核心:
如何根据IMU数据的特征设计出LIMU-Bert,从而提取出泛化特征。
ABSTRACT
本文并没有针对某一项任务而设计,而是从IMU应用角度出发,考虑大多数工作都需要大量且高质量的有标签数据,这需要high annotation和training costs,相比较而言无标签数据更加易得。所以设计了LIMU-Bert表征学习模型:
- 充分利用无标签数据
- 提取出泛化特征,如temporal relations和feature distributions
文章成果:
- 通过观察IMU数据,提出了适用于IMU应用的方法
- task-specific模型使用LIMU-BERT提取到的表征,可以通过少量的有标签数据取得优秀的performance
- 在HAR和DPC两个任务上进行验证,取得了好的效果
- 模型lightweight,可以部署到移动设备上
INTRODUCTION
目前工作遇到的困难
严重依赖于监督学习过程,其需要大量的有标签数据来训练模型。对有标签数据的大量需求,阻碍了实践中的使用。
- 由于有标签数据采集过程十分耗时耗力,所以十分稀缺。
- 需要采集大量的数据,保证移动设备,用户,环境等足够充分,才可以获得泛化的模型。
文章意义
为了解决有标签数据的挑战,该篇文章提出了一种自监督表征学习模型,可以利用大量的无标签数据来提取泛化的特征。之后,task-specific模型可以使用少量的无标签数据进行训练。(两阶段)
文章挑战
需要从IMU数据中得到哪些一般特征?
- distributions of individual measurements of IMU sensors(IMU传感器的单个测量值的分布)
eg 当实验人员的活动由站立变为走路时,acc和gyr的测量值变大
- temporal relations in continuous measurements(连续测量值的时间关系)
eg 当设备方向变化时,加速度计的三轴分量的相关性不同。
如何从IMU数据中提取出如上的泛化特征?
本文设计了数据融合和归一化、有效的训练方法、结构优化等技术,并将其嵌入到BERT框架中。
PRELIMINARIES
Representation Learning
BERT是一种有效的自然语言处理(NLP)自监督学习模型,具有两个自我监督的任务:MLM和NSP。BERT 可以学习文本数据中的上下文关系,并据此为每个单词生成有效的嵌入。经过自监督的训练过程后,预训练的模型可以与fine-tune连接起来,通过监督训练来执行各种NLP任务。
受BERT的启发,采用一种类似Bert有效的自监督技术。作为时间序列类型的数据,IMU传感器数据也包含了丰富的上下文关系。从未标记的IMU数据中提取有效的表征,可以提高下游模型的性能,并且降低对标签数据的要求。
Uniqueness of IMU Sensing
为了设计LIMU-BERT,使预训练模型适用于IMU数据应用,将IMU数据进行可视化,并分析其特征,这些特征将作为后续的指导。
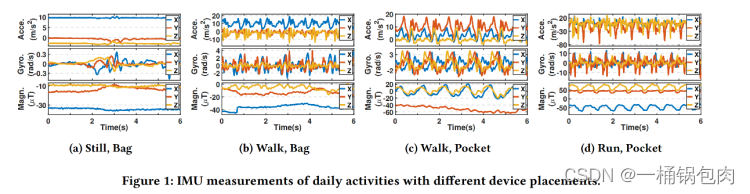
为了进行HAR和DPC两个任务,本文针对不同活动,传感器的不同位置进行了数据可视化,得出了以下三个方法指导:
Fusion matters
观察:在图(a)中,用户所处的状态是,将传感器放入包中,处于静止状态。观察到陀螺仪的数值波动很大,而加速度计的数值几乎不变。所以得出结论:陀螺仪对周围环境更加敏感。
如果仅使用陀螺仪数据,则环境噪声很多,难提取出高质量的表征。所以如果同时考虑加速度计数据和陀螺仪数据,将会削弱陀螺仪范围波动的影响。
结论:所以多个传感器的交叉引用可以提供更多信息并提高整体性能。
除此之外,考虑到多模态方向,表示学习模型应该支持多个IMU传感器的数据融合,所以在LIMU-BERT中应该考虑这个问题。
Distribution matters
观察:图(b),©,(d),可以观察到当用户走路时,陀螺仪读数在 (-5, 5) 范围内,而当用户跑步时,陀螺仪读数分布在-15到15之间。
在不同活动中,单个传感器的测量值的范围差异很大。(Range)
观察:图(b),©,可以观察到当设备放在包中,则 y 轴上的加速度计读数与其他两个轴相比读书都大,但当设备放在口袋中时,它们的相关性不同。
当设备放置不同时,每个传感器三轴读数之间的关系也会发生变化。(Relation)
结论:IMU读数的分布包含了丰富的信息,这是LIMU-BERT应该捕获的一个特征。所以如果我们想捕获一般特征,则任何可能会破坏分布信息的转换,都不应该应用。
Context matters(时间窗口?)
观察:图(a),由于人类活动很复杂,偶尔的波动是不可避免的。但是走路©和跑步(d)的数据有明显的周期性规律,这是区分它们与静止的特征,解释周期性的原因可以为步频等。通过观察用户在图1(b)和图1©中行走时的IMU读数,在口袋中的智能手机的读数有更显著的变化。这很可能是因为智能手机的方向随着腿的移动而经常改变。
结论:时间关系在IMU数据的表示学习中也起着重要的作用。
Potential Application
在该节中解释了为什么选择HAR和DPC两个任务。
DESIGN
总体设计
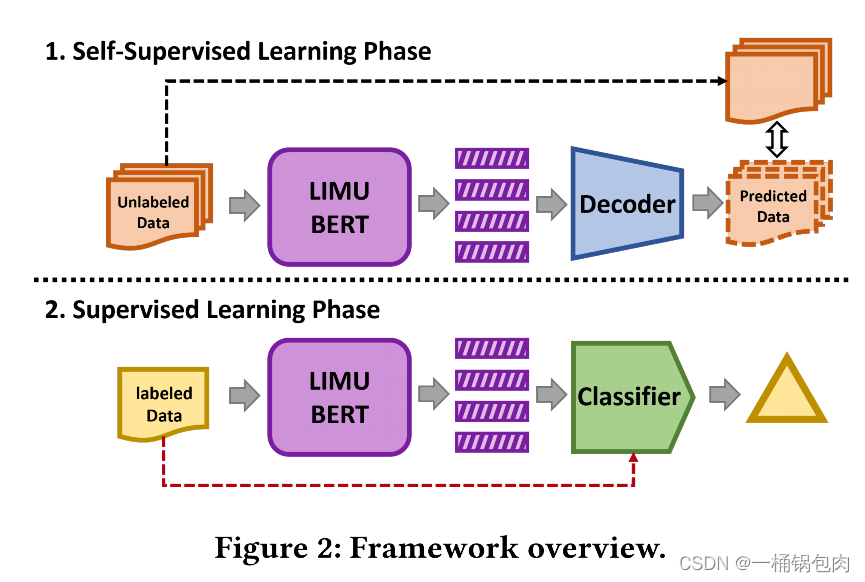
整个模型包括三个组件和两个阶段。
三个组件
LIMU-BERT:将未标记的IMU数据作为输入,并输出高级表示或特征。
Decoder:根据学习到的特征重构未标记的数据。
Classifier:用少量标记数
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









