






 本文介绍了使用Python的pandas库进行数据分析的基本操作,包括读取Excel数据、行列操作、缺失值处理、数据排序和统计分析。通过实例展示了如何筛选、添加、删除数据行和列,以及如何处理异常值。此外,还讨论了数据保存和数据透视表的使用。
本文介绍了使用Python的pandas库进行数据分析的基本操作,包括读取Excel数据、行列操作、缺失值处理、数据排序和统计分析。通过实例展示了如何筛选、添加、删除数据行和列,以及如何处理异常值。此外,还讨论了数据保存和数据透视表的使用。
文章目录
开发工具
Python数据分析,使用numpy、pandas、matplotlib库对excel表格进行分析。
- numpy系统是Python的一种开源的数值计算扩展。这种工具可用来存储和处理大型矩阵,比Python自身的嵌套列表结构(nested list structure)要高效得多(该结构也可以用来表示矩阵(matrix))。
- pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas最初被作为金融数据分析工具而开发出来,因此,pandas为时间序列分析提供了很好的支持。 Pandas的名称来自于面板数据(panel data)和python数据分析(data analysis)。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一。
- Matplotlib 是 Python 的绘图库。 它可与 NumPy 一起使用,提供了一种有效的 MatLab 开源替代方案。
参考课程:https://www.bilibili.com/video/BV1yi4y147A2
开发环境
Jupyter Notebook(此前被称为 IPython notebook)是一个交互式笔记本,支持运行 40 多种编程语言。在本文中,我们将介绍 Jupyter notebook 的主要特性,以及为什么对于希望编写漂亮的交互式文档的人来说是一个强大工具。
测试数据
使用爬取的豆瓣电影数据
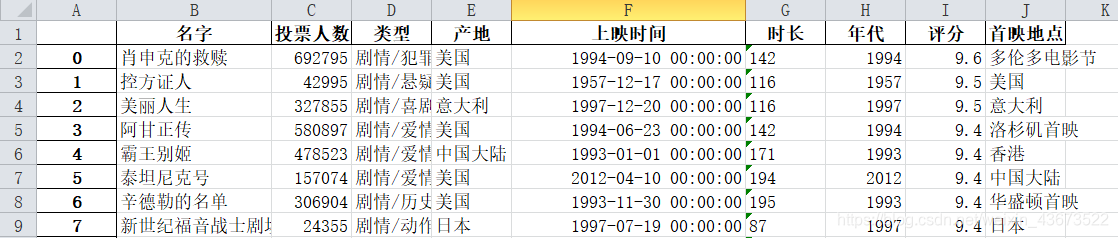

pandas进行数据操作
1.读取数据
导入numpy,pandas,matplotlib库
import numpy as np
import pandas as pd
import matplotlib as plot读取excel表格
df=pd.read_excel("豆瓣电影数据.xlsx")显示读取的前五行
df.head()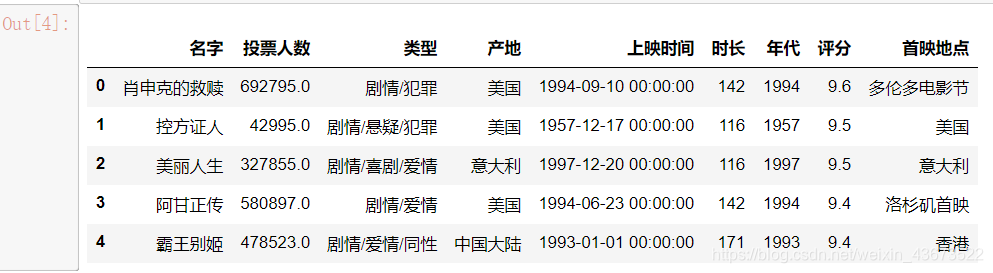
2.行操作
读取第一行
df.iloc[0]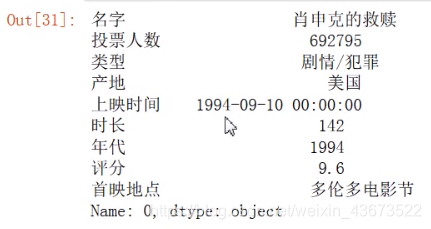
显示前几行
df.iloc[0:5]
#显示前五行
df.loc[0:5]
#显示前六行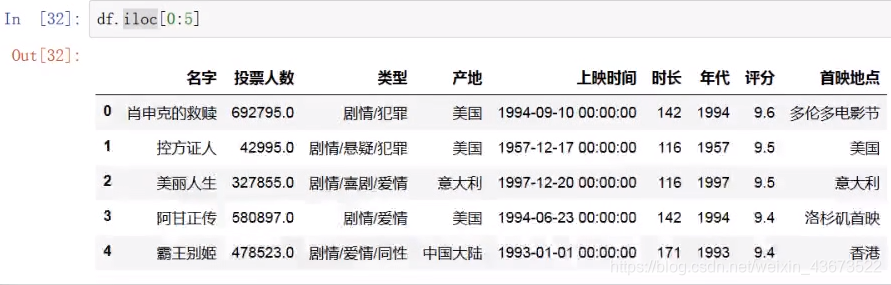
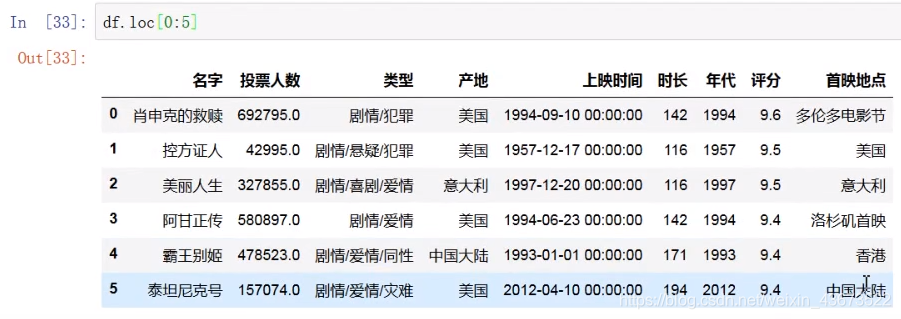
添加行
先建立一个字典,再将它转换为pd.Series类型
dit={'名字':'复仇者联盟3','投票人数':123456,'类型':'剧情/科幻','产地':'美国','上映时间':'2018-05-4 00:00:00','时长':142,'年代':2018,'评分':8.7,'首映地点':'美国'}
s=pd.Series(dit)
s.name=38738
df=df.append(s)
#添加入数据中
df[-5:]
#显示最后5行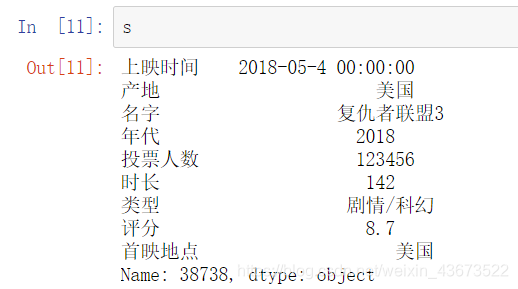
如下图,数据被添加进入

删除行
df=df.drop([38738])3.列操作
查看数据的列名称
df.columns
取数据的一列(前五行)
df['名字'][:5]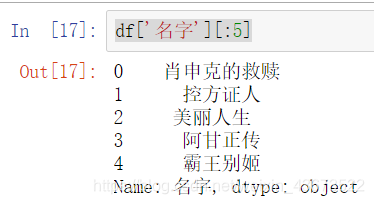
取数据的多列(前五行)
df[['名字','类型']][:5]
增加一列
df['序号']=range(1,len(df)+1)
#增加“序号”一列
df[:3]
#显示前三行 如图,添加了一个序号列
如图,添加了一个序号列
删除一列
df=df.drop("序号",axis=1)
axis为删除的方向
默认值axis=0,删除行
通过标签选择数据
df.loc[[.index],[.column]]
df.loc[1,'名字']
#取一个
df.loc[[2,4,6,10],['名字','评分']]
#取多行多列
4.条件选择
选取产地为美国的部分电影
df['产地']=='美国'
会输出一个布尔型的series,可以通过这个进行操作
df[df['产地']=='美国'][:3]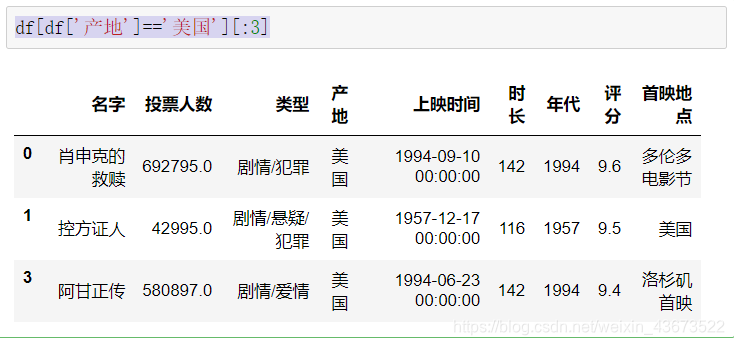
选取产地为美国的所有电影,并且评分大于9分的电影
df[(df.产地=='美国')&(df.评分>9)][:3]选取产地为美国或中国大陆的所有电影,并且评分大于9分的电影
df[(df.产地=='美国')|(df.产地=='中国大陆')&(df.评分>9)][:3]5.缺失值与异常值的处理
判断缺失值
df.isnull()
df.notnull()会返回一个二维布尔类型的series
df[df['名字'].isnull()][:5]
#找出名字为空的
填充缺失值
使用fillna()
df['评分'].fillna(np.mean(df['评分']),inplace=True)
#用评分的平均值填充评分缺失的项删除缺失值
df.dropna()参数:
how='all':删除全为空值的行或列
inplace=True:覆盖之前的数据
axis=0:选择行或列
处理异常值
对于异常值,一般来说数量很少,直接删除就行
df=df[df.投票人数>0]
df=df[df['投票人数']%1==0]6.数据保存
df.to_excel("movie_data.xlsx")
7.数剧转换
df['投票人数']=df['投票人数'].astype('int')
df['产地']=df['产地'].astype('str')pandas进行数据分析
1.排序
按照投票人数进行排序
df.sort_values(by='投票人数')
#默认升序
df.sort_values(by='投票人数',ascending=False)
#降序按照年代进行排序
df.sort_values(by='年代')多个值排序,先按照评分,再按照投票人数
df.sort_values(by=['评分','投票人数'],ascending=False)2.基本统计分析
(1)进行描述性统计
df.describe()
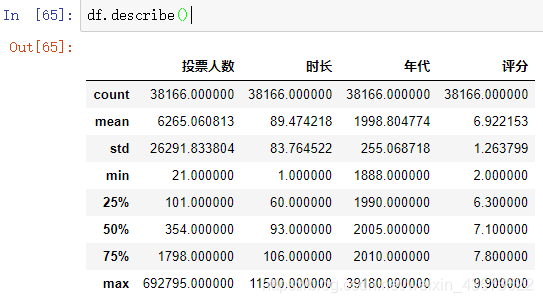
发现异常值,时长最长的为11500分,年代最大的为39180,删除.
df.drop(df[df.时长>1000].index,inplace=True)
df.drop(df[df.年代>2018].index,inplace=True)重新生成连续的index。
df.index=range(len(df))(2) 基本统计量
df['投票人数'].max() #最大值
df['投票人数'].min() #最小值
df['投票人数'].mean() #均值
df['投票人数'].median() #中位数
df['投票人数'].var() #方差
df['投票人数'].std() #标准差
df['投票人数'].sum() #求和(3) 相关系数,协方差
df[['投票人数','评分']].corr() #相关系数
df[['投票人数','评分']].cov() #协方差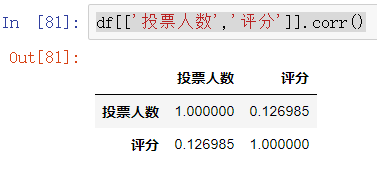
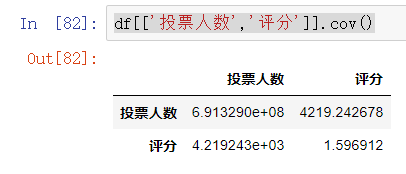
(4) 计数
统计唯一值个数,如统计产地
df['产地'].unique()
如果求产地数只需要用len()函数即可。
产地中包含一些重复的数据,比如美国和USA,德国和西德,俄罗斯和苏联,需要进行数据替换
df['产地'].replace('USA','美国',inplace=True)
df['产地'].replace(['西德','苏联'],['德国','俄罗斯'],inplace=True)统计年代数
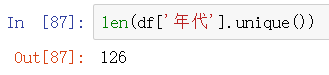
计算每一年电影的数量
电影产出前5的国家或地区
df['年代'].value_counts()
df['产地'].value_counts()[:5]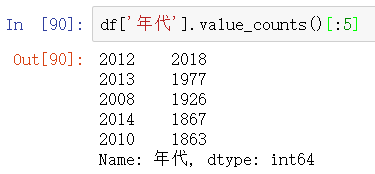

3.数据透视
excel表中数据透视表的使用非常广泛,其实Pandas也提供了一个类似的功能,名为pivot_table。
1.基础形式

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









