









1)HDFS HA 之所以有这么方案,是因为在hadoop1中的hdfs中只存在1个namenode,当namenode出现故障时,整个集群都会受到影响甚至歇菜,所以hadoop在2.0以后推出了HA方案。
2)这个方案准备了2个namenode,一个active的namenode和一个standby的namenode,active的负责所有对外操作,standby的只是作为一个备份,当active的出现故障以后,standby顶上保证整个集群的运转。
3)为了保证standby和active之间能互相替换,两者之间内容必须一致,所以2.0以后给两者提供了一个叫做JNS的互相独立的进程,active进行的所有改变,都会持久化记录到JNS中。standby观察到JNS发生改变时,会把这些改变应用到自己身上,并持续观察。当故障发生时,standby切换成active,在故障发生之前两者的内容必须保持完全一致。
4)为了保证两者的block的信息都是最新的,在datenode中配置了两个namenode,通过心跳机制同时向两个namenode汇报block的有效信息。
5)为了保证只有一个active状态的namenode,不然两个namenode同时写入,会造成数据的异常或丢失,这种情况叫做“脑裂”,一方面JNS只允许一个active进行写入操作,另一方面在JNS中会有一个防护进程,当故障转移时,不确认之前的active是否停止,这个进程会主动进行切断之前的active。
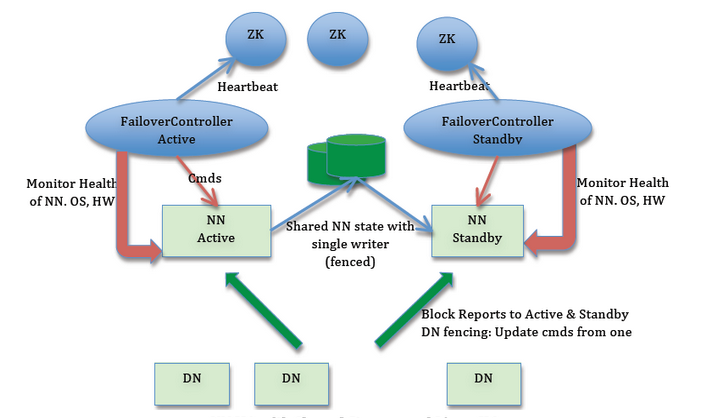
6)集群启动后一个namenode是active状态的,负责客户端的操作,以及负责将editlog存储到本地和JNS上;standby会持续观察JNS的editlog并周期性的获取editlog应用到自身。为保证两个namenode的完全一致性,在datenode中设置两个namenode并通过心跳机制向两个namenode汇报block的信息。为了实现热备,添加了failovercontroller和zookeeper,failovercontroller和zookeeper进行通讯,它通过zookeeper的选举机制,和rpc让namenode在active和standby之间转换。
7)hdfs自动故障转移
hdfs自动故障转移是通过zookeeper实现的,zookeeper主要由zookeeper和zcfc两个组件
zookeeper集群的主要作用有两个:
一是故障监控,nameode和zookeeper之间持有一个session会话,如果namenode故障,则session会话失效,zookeeper会找到另外一台namenode,然后出发failovercontroller。
二是namenode选举,当active的namenode失效以后,standby会获得一个排他锁,拥有这个锁的就是下一个active。
ZKFC是zookeeper 的客户端,主要是监控和管理namenode的状态,每一台namenode上都有;ZKFC主要由三个作用,一是故障检测,ZKFC会周期的ping namenode并记录namenode的状态,二是管理zookeeper的会话,ZKFC持有zookeeper和namenode之间的session会话,并且当namenode是active状态的时候,还会有排它锁,如果namenode出现故障,会话失效,删除排它锁;三是选举,namenode失效时,zookeeper重启一台namenode。















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









