







可以使用elk+FileBeat实现分布式日志收集,分布式日志收集是干嘛的 ,比如说以我们的项目为例,
每个项目都会写属于自己的一个日志文件
在springboot项目中,当我们通过java-jar指令执行,
执行完毕之后指定日志文件.每一个服务,项目都会指定日志文件
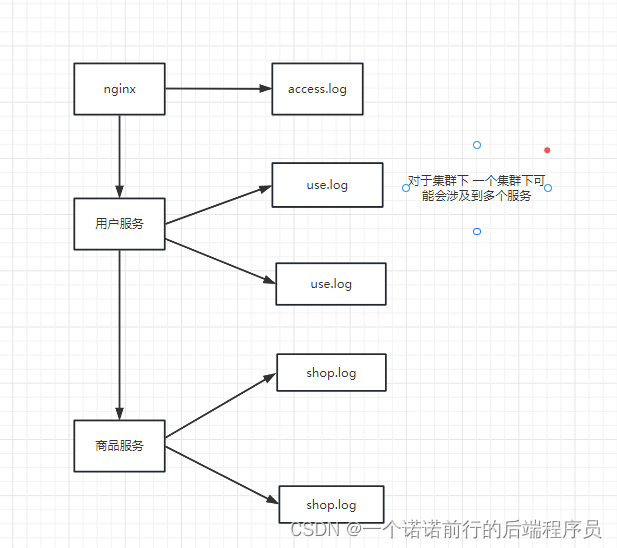
这个时候就会有一个问题 我的日志是分散的,再加上我们使用微服务项目,每个服务会有一个很多实例
也就是说当一个client来一个请求,最后你就没有办法确定你这个请求具体打在哪一个pod上了,因为会有负载均衡,很多时候如果出现问题了,我们查询日志就会很难~
比如说我此时nginx---->用户服务,我用户服务部署了3台服务,客户端发来请求之后如果出现错误了
怎么排查,我三台机器上都去查询log日志,看那个地方出错了,我才能去进行问题的排查,这样的效率很低
分布式日志采集就是去做这个事情的,我可以通过一个组件,将这些分布式日志收集到一个地方去进行统一管理
就像日志中心一样
这样我不管我请求发送到哪一个服务上,我都可以在统一的地方对问题进行排查
我们可以通过FileBeat+elk实现分布式日志收集,将nginx或者微服务的日志全部通过filebeat这个组件进行采集
采集之后统一发给logstash,通过logstash在再将日志发送到es中借助于kibana 进行展示
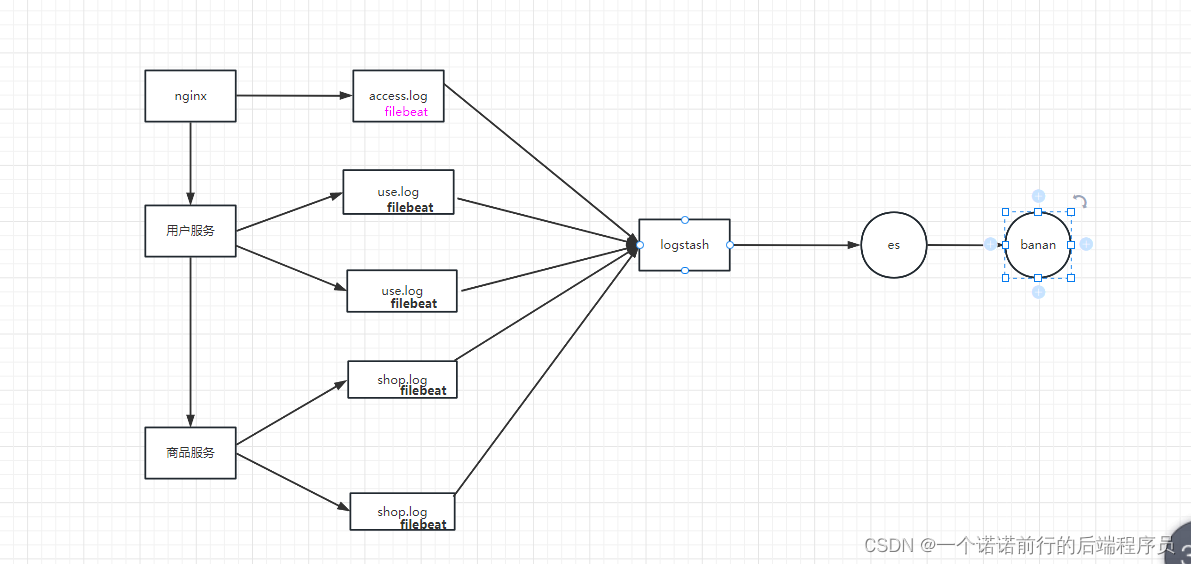
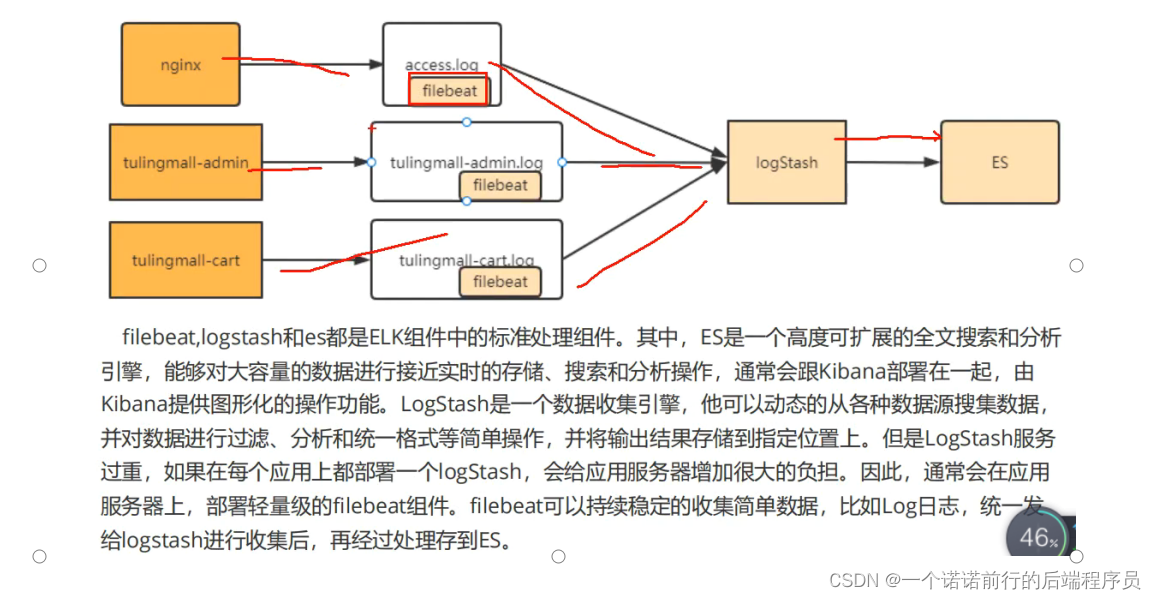
es主要做日志收集的,kibana 可以做es的图形化管理,
logstash和filebeat都是可以用来做日志收集的
他们可以收集很多渠道的日志 但是logstash服务比较重,它启动的比较慢,占用的资源比较多
fileBeat比较轻量级 占的资源比较少,通常来说我们单独部署logstash,用filebeat和我们的应用程序
部署在一起收集日志,将收集的日志发送到logstash上进行统一的处理,比如说做一些格式的整理,再发送到es中
日志采集 是对你的落地文件进行采集,
nginx会产生日志access.log 这个nginx日志就比较适合用filebeat采集
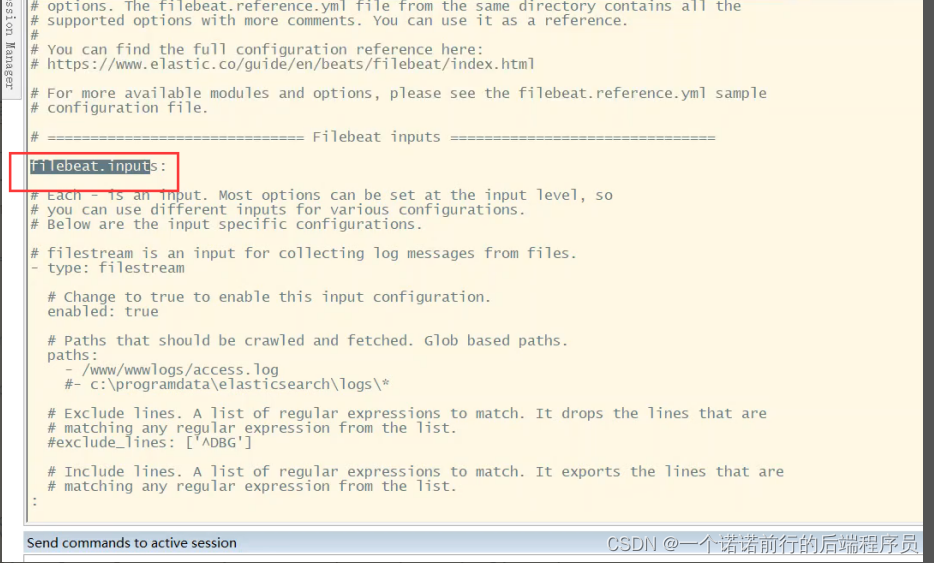
fileBeat软件中会有一个filebeat.yml文件,我们只需要配置好
filebeat从哪里采集数据,filebeat采集的日志 发送到哪里去
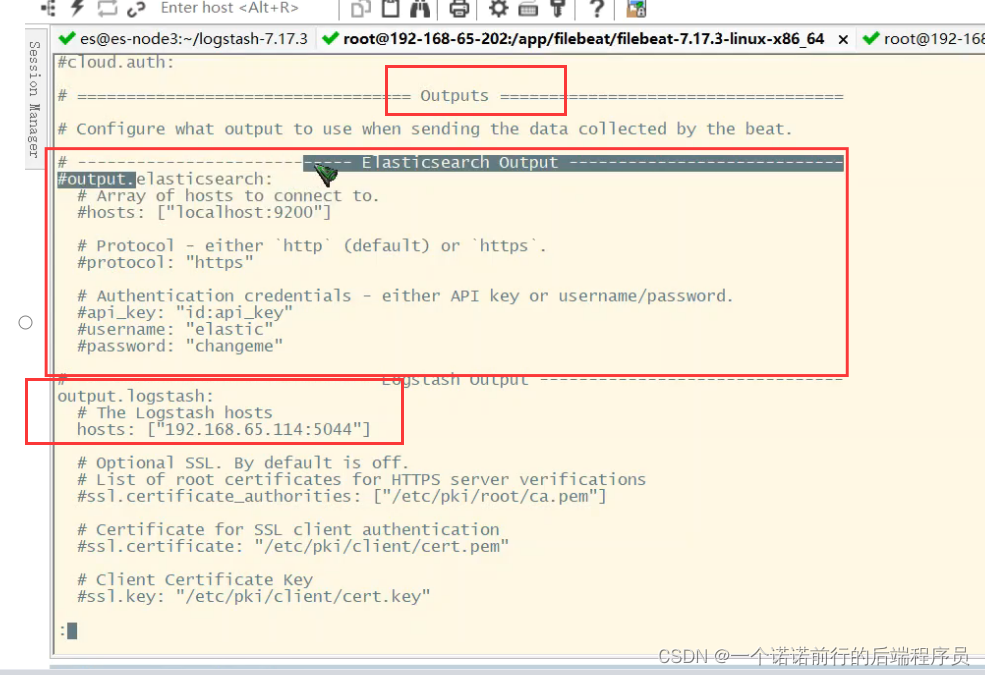
filebeat采集的东西可以直接发送es上去 ,就是我不经过任何处理 可以直接发送到es
也就是input和output
---------------------------------------------------------------------->>>>>>>
logstash中也有一个文件需要配置 也同样是input和output就是我需要收集filebeat的日志,然后经过filter的一些处理 过滤 输出到es
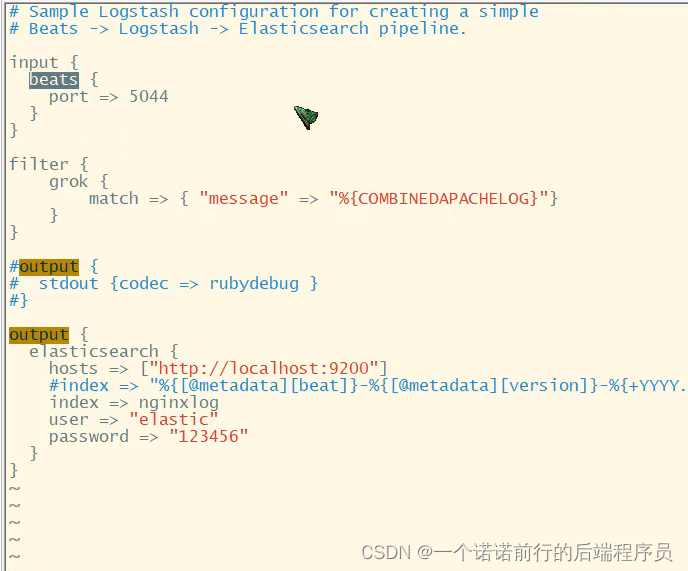
@@@发送给索引为nginxlog的索引上
我们这里做一个配置 通过filebeat采集数据输入到logstash
这里做一个filter 对日志进行规整 经过这么一个过滤器 对文件进行过滤 过滤完毕之后输出到es
这里的filter的目的就是将我们的日志进行拆分,拆分成一个个字段
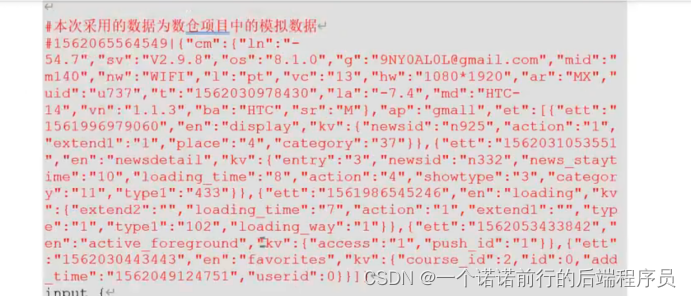
比如说这个就是我们的nginx 日志

这里的filter拆分的默认逻辑是这样的

filebeat进行收集nginx的.log文件,写完之后我们就会经过logstash将这一行日志 ,就是filebeat读取到的是这一行日志access.log,这一行日志经过logstash的filter拆分之后 ,(此时日志就会有对应的格式了)之后发送到es
前端访问页面--->nginx(access.log) --->经过filebeat采集 采集成一行行的文本发送给logstash logstash 进行拆分拆分完成之后形成字段。
日志采集有什么用,基本上这个日志所有项目都需要采集的,我们可以通过用es命令就可以进行排查生产问题
我们最常用的pv,uv 就可以从这个nginx的日志数据来 我的前端页面有多少次访问 uv
有多少个不同的人来访问我们的系统 这是我们去考虑我们网站的一个
受欢迎的很重要的指标
对于pv 我每一次点击就会产生这么一个日志 每一个记录就相当于一个pv,现在如果我要统计当天的pv有多少, 就是要统计 当前的nginxLog索引上在今天有多少条日志,我基于es的查询语句就可以进行统计
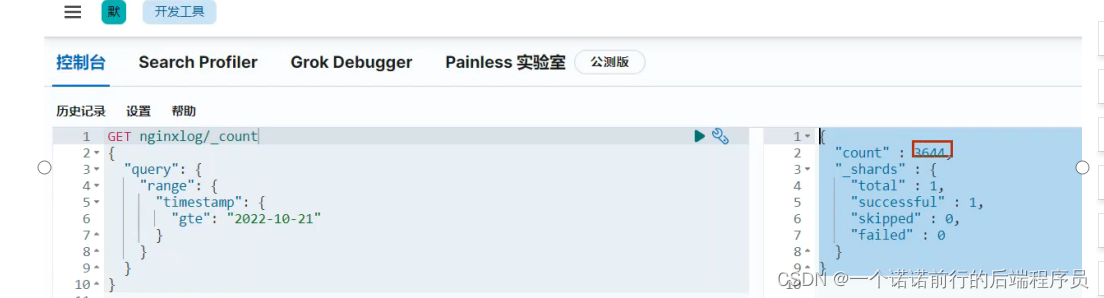
这就是我们今天的pv,有多少人访问我的前端页面,我们今天的pv 这就是nginx日志 每次访问nginx就会加一条日志
接下来就是要统计我们的uv,同一个人你不管点击多少次页面,都只能算一次uv, 我可以基于ip进行进行分组
我要统计当前有多少不同的ip地址
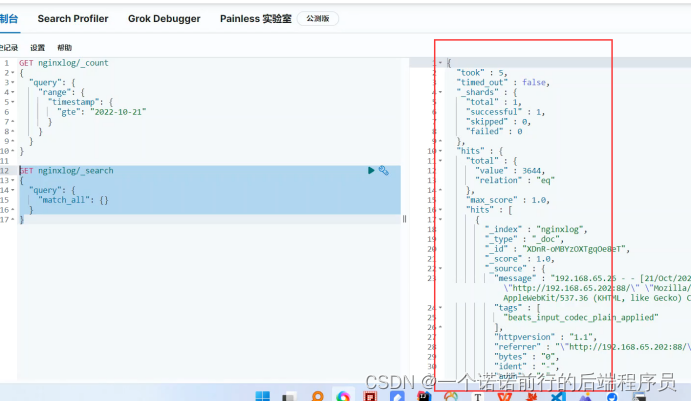
我们现在从nginx落地日志开始 基于文本收集方式统计pv 和uv
我们吧这些日志收集起来 还有没有其他用处 出了nginx访问pv和uv 这个基本上是所有项目通用的
我也可以把我们springboot项目日志进行收集, 这样以后排查问题好排查
filebeat是一个轻量级日志采集器,logstash是负责日志传输和聚合的
导入到es非关系型数据之后 用kabana做查询和展示的 在这一套技术中logstash扮演了日志传输的角色
filebeat相比较而言 filebeat比logstash更小巧简洁
可以使用filebeat代替logstash 相对而言更加简单 ,对资源消耗更加低点
filebeat主要功能就是用来采集日志的
filebeat是常用的一种 所以我们的的filebeat最核心的做法也是将日志导入到es中 ,同时用kibana做展示


logstash主要有各种过滤功能,比如说多个节点部署logstash,对资源的损耗就会多一些,替换成filebeat
对资源的损耗就会下降下来,然后再将filebeat采集的日志统一发送到logstash中去
filebeat 默认是关闭的 就是不监控任何地方的,对应监控的路径 写一个文件路径,就是监控这个路径下的
文件,将日志进行收集 然后发送到output中去
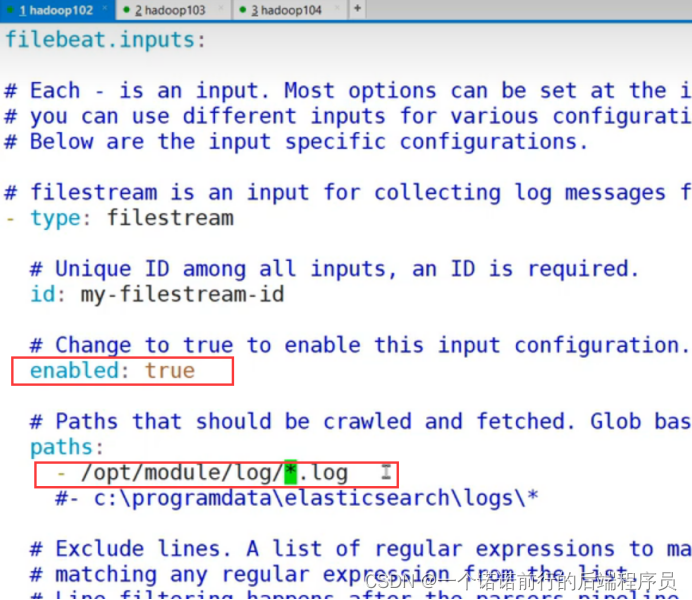
比如说我们下面就是 开启filebeat的日志收集
然后路径就是 /opt/module/log/*.log
意思是收集 /opt/module/log/*.log 下的日志
/opt/module/log/*.log 监控以.log为结尾的文件
这个地方一定要打开 不然你是监控不到数据的
logstash 也是接受filebeat的日志,发送到es中 filter 会对数据进行什么处理
input 从哪里接受数据 (filebeat)
filter 怎么对数据进行处理 ()
outPut 输出到哪里
比如说以下json数据,logstash会以竖线分割,然后再左边为source,右边为target
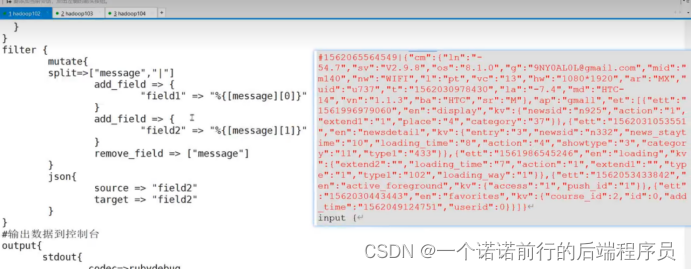
写log文件--->/log目录--->filebeat监控----》logstash(处理之后)--->输出到控制台
启动filebeat
在实际开发中 可能会在多台节点都部署成filebeat r然后吧他发送到同一个logstash 这样比你每一个节点都部署logsstash要节省资源 资源的消耗要小一些
--------------------------------------------->>>>>>>>
filebeat会将数据输出到es logstash kafka redis 中
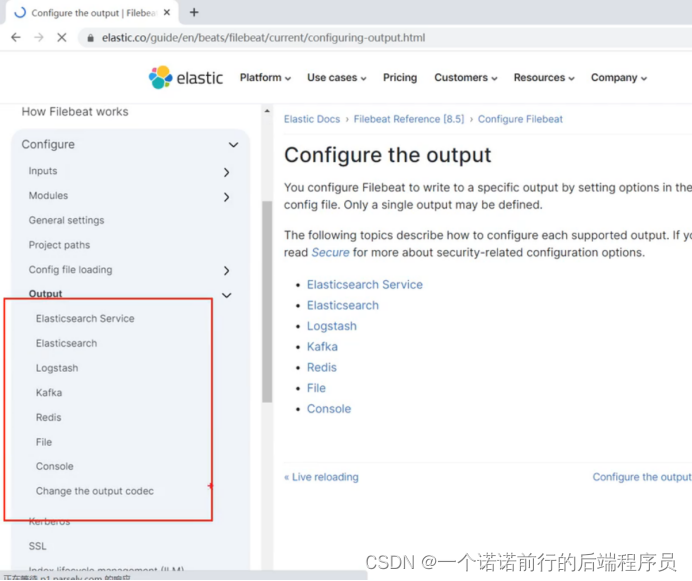
##
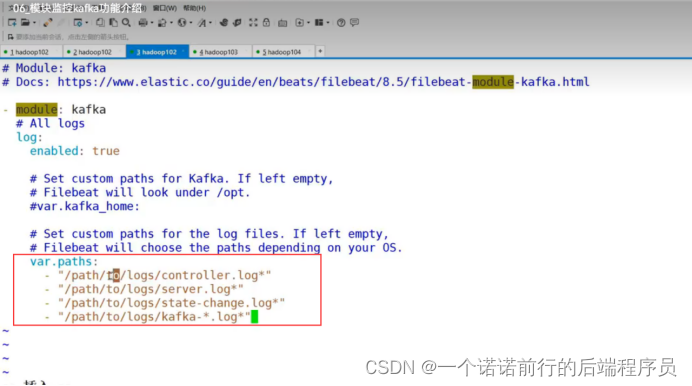
filebeat监控kafka日志 filebeat中有各种模块,在filebeat的modules中, 如果监控kafka对应的日志
,只需要吧对应的yml打开就可以了
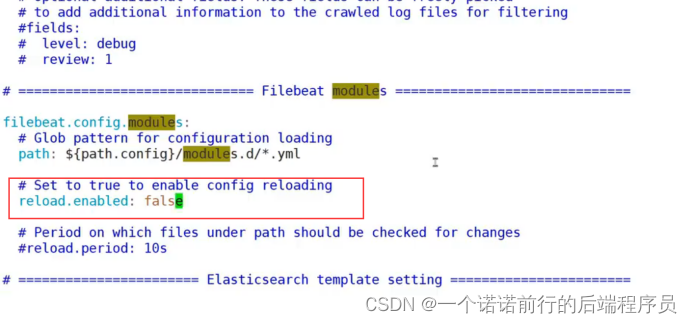
filebeat默认是disabled,我们也需要去打开

开启模块监控的功能 filebeat就可以监控这些模块 了,这样filebeat就可以监控监控各个框架的日志的用法
filebeat可以直接吧数据发送到我es中,如果我数据不用清洗之类的操作,可以直接发送到es中














 1115
1115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









