







Redis键操作
- unlink key : 异步删除,非阻塞
- keys *查看当前库所有key (匹配:keys *1)
- exists key判断某个key是否存在
- type key 查看你的key是什么类型
- del key 删除指定的key数据
- unlink key 根据value选择非阻塞删除
- 仅将keys从keyspace元数据中删除,真正的删除会在后续异步操作。
- expire key 10 10秒钟:为给定的key设置过期时间
- ttl key 查看还有多少秒过期,-1表示永不过期,-2表示已过期
- select命令切换数据库
- dbsize查看当前数据库的key的数量
- flushdb清空当前库
- flushall通杀全部库
Value操作
String
二进制安全:代表数据是安全的
原子性操作,不会被指令插队:
- incr :将 key 中储存的数字值增1
只能对数字值操作,如果为空,新增值为1 - decr :将 key 中储存的数字值减1
只能对数字值操作,如果为空,新增值为-1 - incrby / decrby <步长>将 key 中储存的数字值增减。自定义步长。
- setex <过期时间> 设置键值的同时,设置过期时间,单位秒。
数据结构:简单动态字符串,类似于ArrayList,预分配冗余空间,可以减少内存频繁分配。小于1M,每次翻倍,多于1M,每次+1M,最大512M
List
数据结构: 当数据量小的时候是压缩列表,数据量大的时候是双向链表,简称quicklist,数据量小的时候用链表会造成空间浪费,需要一堆额外的prev和next指针Set
数据结构:Set数据结构是dict字典,字典是用哈希表实现的。类似于JAVA中的HashSet。根据hash函数获取到数据的位置,所以O(1)的时间复杂度Hash
类似于JAVA中的HashMap<String,Object>
数据结构:ziplist+hashtable 当field-value长度较短且个数较少时,使用ziplist,否则使用hashtable。Zset
类似于Set,但是每个元素都有一个得分,元素唯一,但是评分可以重复。- zrange
[WITHSCORES] :返回有序集 key 中,下标在 之间的元素,带WITHSCORES,可以让分数一起和值返回到结果集。
数据结构:
数据量少时用的是 Ziplist,占用空少
数据量大时用的跳跃表+Hash表,Hash表用于通过Value查得分 O(n),ZipList用于通过得分查Value,排序时用O(logn)
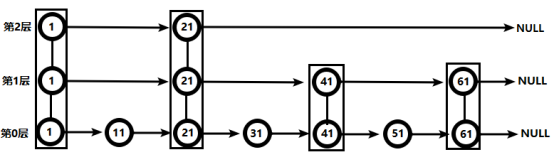
- zrange















 176
176











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









