






 本文提出了一种名为SDDGAN的新型端到端模型,用于红外和可见光图像融合,以增强语义一致性和场景表示能力。通过信息量判别(IQD)块和双重鉴别器,SDDGAN能自适应地融合不同语义对象,保留其特征。IQD块生成融合权重,而双重鉴别器确保了红外和可见信息的保留。实验结果表明,SDDGAN生成的融合图像在信息量和语义一致性上表现出色,适用于目标识别和语义分割等高级应用。
本文提出了一种名为SDDGAN的新型端到端模型,用于红外和可见光图像融合,以增强语义一致性和场景表示能力。通过信息量判别(IQD)块和双重鉴别器,SDDGAN能自适应地融合不同语义对象,保留其特征。IQD块生成融合权重,而双重鉴别器确保了红外和可见信息的保留。实验结果表明,SDDGAN生成的融合图像在信息量和语义一致性上表现出色,适用于目标识别和语义分割等高级应用。
Semantic-supervised Infrared and Visible Image Fusion via a Dual-discriminator Generative Adversarial Network
(通过双重鉴别器生成对抗网络进行语义监督的红外和可见光图像融合)
我们提出了一种新的端到端模型,以在红外和可见光图像融合中获得语义上更加一致的图像,称为语义监督的双鉴别器生成对抗网络 (SDDGAN)。特别是,我们设计了一个信息量判别 (IQD) 块来指导融合进程。对于每个源图像,块确定用于保留每个语义对象的特征的权重。通过这种方式,生成器学习通过不同的权重融合各种语义对象以保留其特征。此外,使用双重鉴别器来识别融合图像中红外和可见信息的分布。每个鉴别器都作用于融合图像中不同语义对象的特定模态 (红外/可见),以保留和增强其模态特征。因此,我们融合的图像更具信息性。红外图像中的热辐射和可见图像纹理细节都可以很好地保留。
介绍
图像融合旨在为后续的高级应用程序提供服务,例如目标识别和语义分割。因此,融合图像应该具有更好的语义表达能力,包含更多的语义信息。我们将其概括为 “高级语义感知”。为此,我们提出了一种端到端模型,称为语义监督双鉴别器生成对抗网络 (SDDGAN),该模型可以提高融合图像的高级语义一致性。我们首先设计了一个特殊的信息量判别 (IQD) 块,为每个语义对象生成适当的融合权重,以保留其特征并监督图像融合过程; 从而,生成器可以学习不同语义对象的融合机制。然后,我们应用双重鉴别器来识别融合图像中红外和可见信息的分布; 每个鉴别器都作用于不同语义对象的某种模态 (红外/可见)。IQD块引导生成的融合图像具有高度信息性和语义一致性。双重鉴别器有助于保留和增强融合图像中不同语义对象的模态特征。结果,我们的融合图像获得了很高的语义一致性和场景表示能力,这有利于后续的应用程序和任务。
贡献
1)我们设计了一个特殊的信息量判别 (IQD) 块,以确定融合图像中每个对象的保存程度并监督图像融合过程; 融合图像具有相当大的信息量,并且具有很高的场景表示能力。
2)提议的双重鉴别器作用于不同语义对象的不同模态 (红外/可见),从而在融合图像中保留并增强了它们的模态特征。
3)提出的SDDGAN是端到端的,并以自动方式统一了特征提取和融合。
4)由于其更简单的生成器网络,因此拟议的SDDGAN在效率上优于最新方法。
相关工作
Traditional Fusion Methods
传统的图像融合算法手动设计特征提取和融合规则,以保留源图像的基础特征。
基于多尺度变换的方法是最流行的图像融合方法,包括金字塔变换,小波变换,非子采样contourlet变换和边缘保留滤波器。他们将源图像分解为子图像,并设计特定的融合规则来重建融合图像。Liu等人提出了一种基于可转向金字塔的方法,该方法将多尺度分解与差分测量相结合,提高了特征提取能力。Madheswari等人在离散小波变换 (DWT) 域中设计了粒子群优化图像融合框架,该框架可以通过双树离散小波变换 (DTDWT) 和粒子群优化来优化融合图像。Hu等人介绍了一种基于多尺度定向双边滤波器的方法 (MDBF),该方法结合了双边滤波器和定向滤波器组的特点来表示图像的固有几何结构。
基于稀疏表示的方法旨在学习一个过度完整的字典,然后用稀疏的表示系数表征源图像的背景和纹理细节。Yang等人引入了同时正交匹配追踪技术,以确保将不同的源图像稀疏地分解为字典基的同一子集; 从而可以准确地表示图像信息。Liu等人提出了一种自适应稀疏表示 (ASR) 模型,该模型可以从众多高质量图像补丁中学习一组紧凑的子词典,并在图像融合过程中自适应地选择其中一个子词典。Wang等人设计了一种基于稀疏表示和压缩感知的图像融合方法。他们压缩了传感数据,并获得了压缩样本上的稀疏系数。最后,根据组合的稀疏系数重建融合图像。
基于显著性的方法使用显著性以自下而上的方式吸引人类视觉注意力。它们可以保持突出目标区域的完整性,同时改善人类的视觉效果。因此,它们在图像融合中得到了广泛的应用。Han等人在马尔可夫随机场 (MRFs) 的基础上,提出了一种显著感知的融合算法来增强融合图像的可视化。Zhao等人设计了一种基于局部窗口的频率调整方法,该方法可以计算视觉显着性图,并显示每个像素和区域的人们对图像的关注权重。Shibata等人利用局部对比度测量局部显著性,然后采用泊松图像编辑,融合源图像的梯度信息,构造输出图像。其他图像融合算法,例如基于子空间的方法和混合方法,可以激发图像融合的新思路和新观点。
Deep Learning-based Fusion Methods
近年来,由于神经网络的强大功能,基于深度学习的图像融合方法备受关注。它们可以从源图像中自动提取有效特征,并从本质上描述输入数据和目标数据之间的复杂关系。这些方法通常依赖于卷积神经网络 (CNN)。Liu等人提出了一种多焦点图像融合方法。他们使用深度卷积神经网络来学习焦点图和源图像之间的直接映射。随后,他们生成了活动级别的测量和融合规则。
(略)
Generative Adversarial Networks
最近,许多生成对抗网络 (generative adversarial networks,GANs) 被提出来生成图像,例如FusionGAN 、MEF-GAN、AttententionFGAN、DDcGAN。受GANs的启发,Guo等人提出了一种自动嵌入生成对抗网络 (AEGAN),通过从自动编码器中提取的潜在嵌入来合成高分辨率图像。Liu等人提出了一种用于深度视图综合的自洽生成网络 (SCGN)。Yin等人 提出了一种先验感知的生成对抗网络 (PA-GAN),以从具有极端曝光的两个低动态范围 (LDR) 图像中产生高动态范围 (HDR) 图像。
(GAN的公式演变:略)
方法
Problem Formulation
给定红外图像Ir和可见光图像Iv,我们的目标是学习一个生成器G,该生成器可以从源图像中提取最有效的特征,并生成具有增强视觉效果的信息融合图像,从而促进后续处理和应用。但是,不同的语义对象具有不同的特征,其表示的场景信息在不同的方式中差异很大。我们没有为整个图像设计一系列新的图像融合规则,而是将图像融合问题表述为其中不同语义对象的融合。更具体地说,我们设计了一个IQD块,该块可以根据其自身的特征和内容确定融合图像中每个语义对象的保存程度,以监督图像融合过程。此外,我们在网络中使用双重鉴别器来识别红外和可见信息的分布。每个鉴别器都作用于融合图像中语义对象的一种模态,以通过与G的对抗性游戏来保留和增强其模型特征。因此,G的训练目标可以被制定为最小化以下目标:
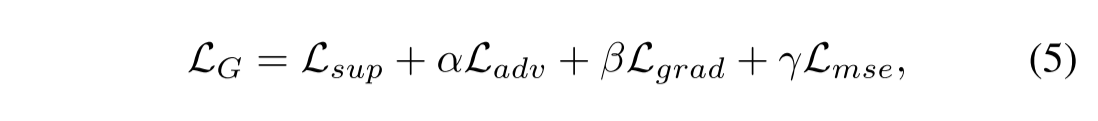
其中Lsup和Ladv分别表示监督损失和对抗损失。具体地,IQD块可以为每个语义对象生成不同的融合权重,Lsup表示在不同融合权重下每个语义对象在融合图像和源图像中的总距离。Ladv代表生成器G试图愚弄鉴别器。Lgrad和Lmse是梯度损失和均方误差 (MSE) 损失,以迫使融合图像保留来自源图像的大量信息。α,β 和 γ 是正则化项。因此,判别者的目标是最大化对抗性损失Ladv。
Information Quantity Discrimination Block
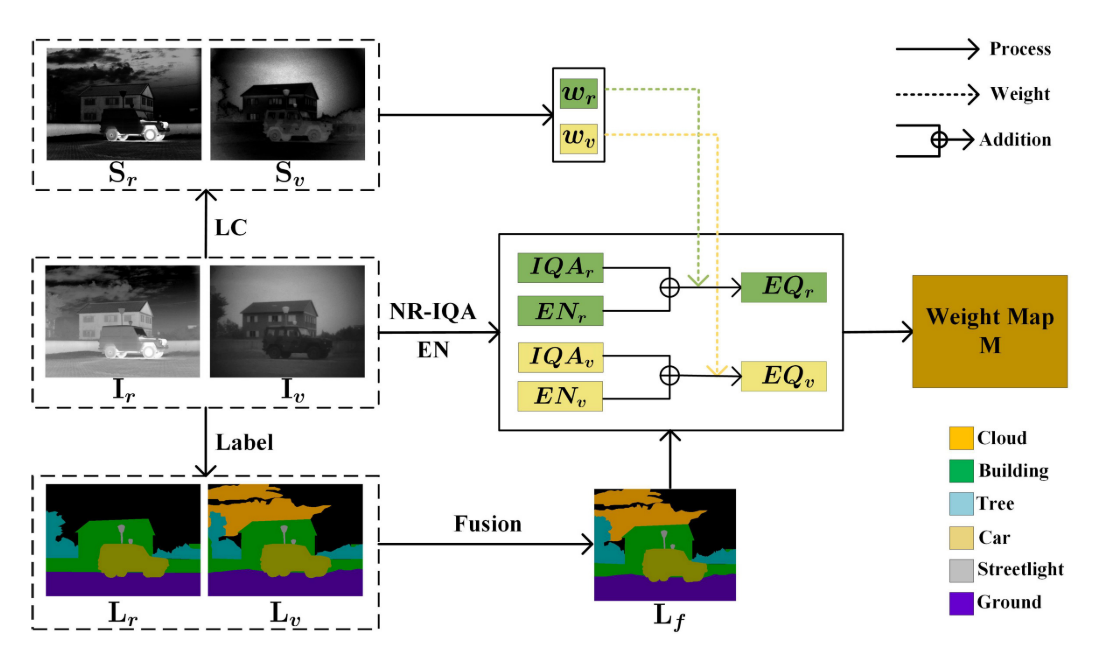
(信息量判别块的示意图。Ir和Iv分别表示红外图像和可见光图像。Lf表示标记图像Lr和Lv的融合结果,以提供每个语义对象的位置。Sr和Sv是显著性检测结果。我们使用LC,NR-IQA和EN来计算每个语义对象的包含信息EQ,并利用权重图M来表达它们在融合图像中的保留程度。该模块仅在训练过程中用于监督图像融合网络)
为了评估每个语义对象的保留程度,我们建立了一个特殊的信息量判别 (IQD) 块,该块由无参考图像质量评估 (NR-IQA),熵 (EN)和显着性 (LC,亮度对比度) 。如图1所示。我们使用NR-IQA来评估源图像中每个对象区域的质量。它可以测量物体区域质量是否由于特定类型的失真而下降,例如模糊,压缩,阻塞效应和各种形式的噪声。

如图2(a)-(b) 所示,通过反射光对可见图像进行成像,并且可见图像中的对象倾向于具有较高的IQA。但是,IQA只能评估对象区域的质量,而不考虑其他方面。典型的例子如图2© 所示。可见图像中的云区域具有更高的IQA,而红外图像中的云区域具有更完整的场景表示。直观地说,我们更喜欢它的融合结果更接近红外图像。从理论上讲,来自融合图像中保存的源图像的语义对象的信息越多越好。因此,我们应用客观度量EN来估计每个语义对象中的信息量。数学上,EN的定义如下:
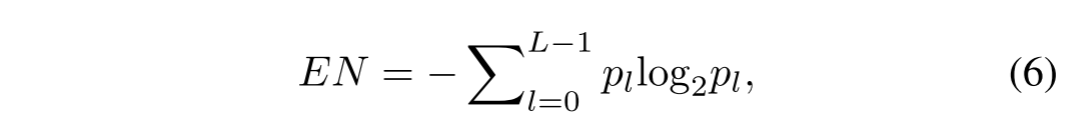
其中L是灰度等级的数量,通常设置为256。pl是相应水平的概率。红外图像中的车和人由于热辐射而显著,如图2(d) 所示,这不能使用EN和nr-iqa来计算。因此,我们添加LC作为评估标准,以确保这些特征可以很好地保留在融合图像中。图像I中像素Ik的显著性值定义为:
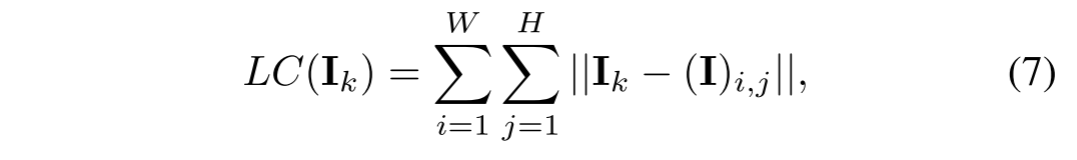
其中,Ii,j的值在 [0; 255] 的范围内,并且 | | · | | 表示颜色距离度量,并且通常使用欧式距离。EN可以确保在融合图像中获得可观的信息,而LC可以保持目标区域的重要性。然而,它们都对噪音敏感。作为补充,IQA可以评估噪声和其他降低图像质量的问题。因此,NR-IQA、EN和LC的组合是一个综合的评价标准,可以有效地计算每个语义对象的包含信息。
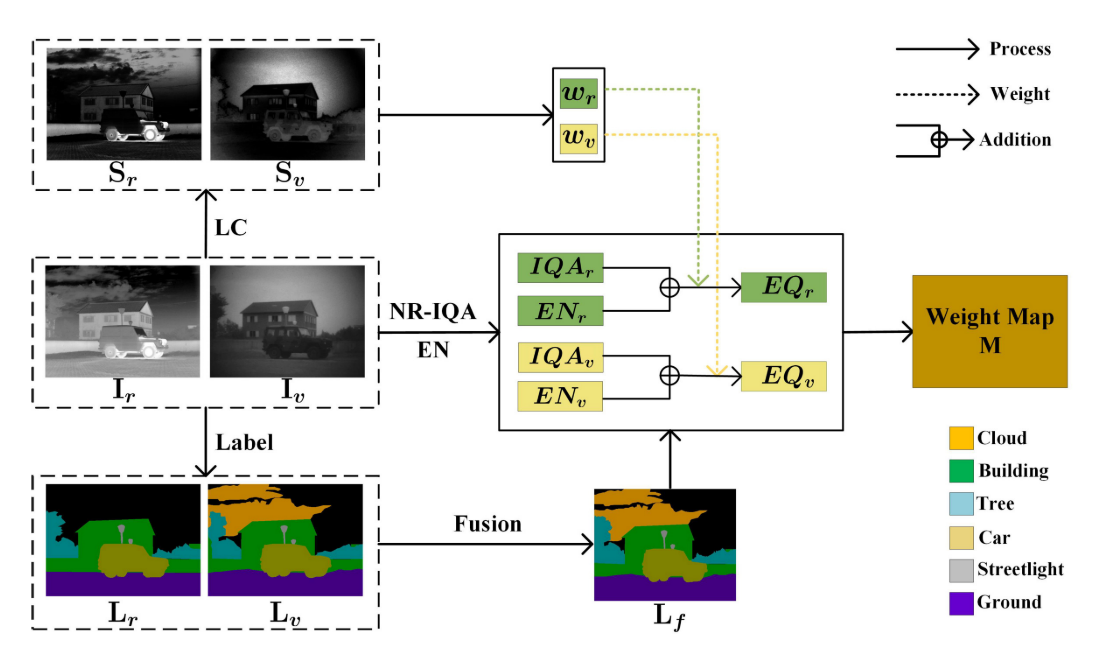
IQD块的最终目标是生成权重图M,该权重图可以表达融合图像中不同语义对象的保存程度,并监督图像融合过程。如图1所示,我们首先对红外图像Ir和可见图像Iv进行标记,以获取标记图像Lr和Lv。尽管如此,由于成像原理的差异,部分语义对象仅由Ir或Iv捕获。因此,我们将带标签的图像Lr和Lv与预先设计的规则融合在一起,以获取完整的标签Lf,这可以帮助我们确定源图像中每个语义对象的位置。在我们的测试过程中不需要标记的图像。我们计算Ir和Iv中每个语义对象的包含信息EQ,可以定义如下:

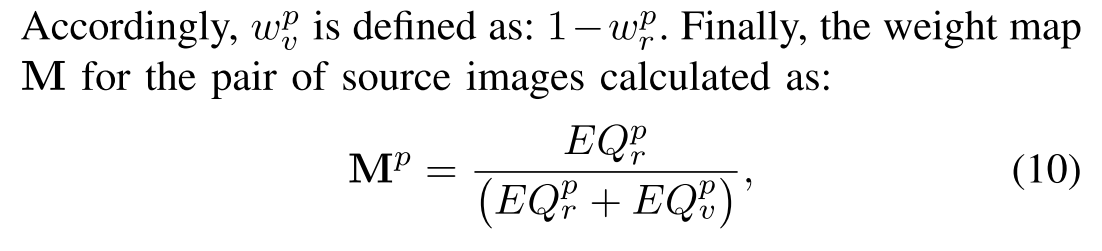
其中M^p表示权重图M中的语义对象区域p,其值表示p在Ir中的保留度,p在Iv中的保留度定义为: 1 − M^p。 如果M^p<0.5,则Iv中的p包含丰富的纹理细节。 如果M^p> 0.5,则由于热辐射,Ir中的p显著。
Generative Adversarial Network with Dual Discriminators
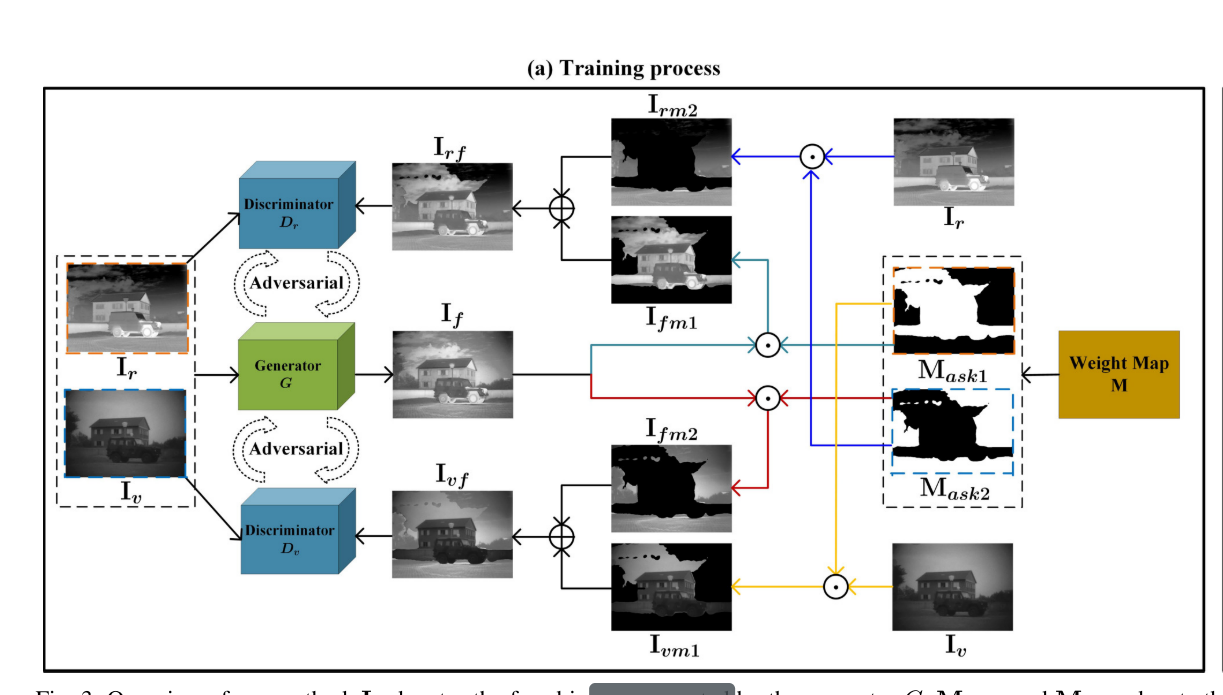
我们的SDDGAN的整个框架如图3(a) 所示。我们使用两个鉴别器Dr和Dv与G进行对抗性游戏; 我们分别将Ir和Iv视为真实数据。特别是,我们不使用If作为Dr和Dv的假数据,而是使用重建图像Irf和Ivf,其中Irf可以定义为:

相反,黑色区域表示其内部语义对象的融合结果应接近于Iv。我们使用来自真实数据Ir的Irm2来替换If中的非红外偏好部分。因此,Dr被训练以识别Ir的分布并约束G以在红外语义对象区域中保留Ir的实质特征。类似地,鉴别器Dv识别Iv的分布,并被训练以区分由Iv和If组成的真实图像Iv和假图像Ivf。因此,Dv迫使G生成在可见语义对象区域中保留Iv的纹理细节的结果。两个鉴别器在If中作用于语义对象的不同部分,而不与之交互。因此,在训练之后,融合图像If可以保留红外和可见光图像的所需特征,并且不需要在生成器和鉴别器之间寻求平衡点。
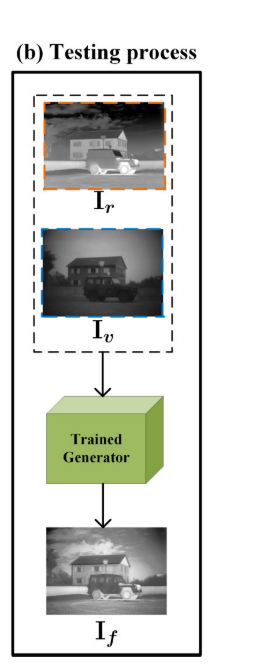
我们方法测试一下过程如图3(b) 所示。我们仅将源图像Ir和Iv输入到经过训练的生成器中,并输出最终的融合图像If。
Loss Function
我们提出的SDDGAN的损失函数可以分为两部分: 生成器G的损失函数和两个鉴别器Dr和Dv的损失函数。生成器损失LG用Eq (5) 表示,包括监督损失Lsup、对抗损失Ladv、梯度损失Lgrad和MSE损失Lmse。
监督损失Lsup可以定义为:
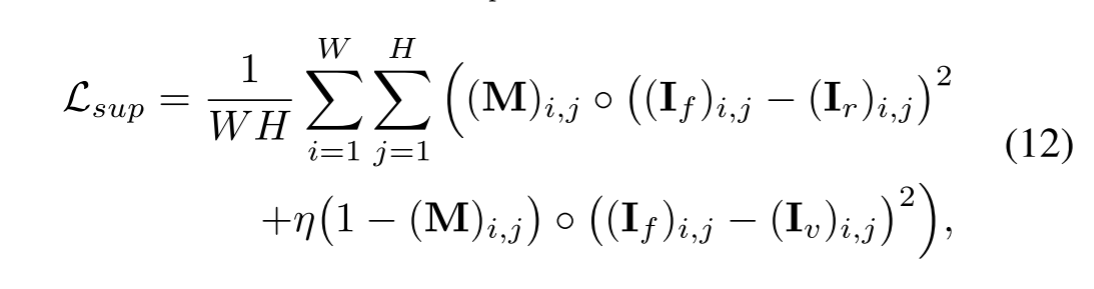
其中W和H分别表示输入图像的宽度和高度。M中的 (M)i,j表示源图像中不同语义对象的融合权重,它们的值在不同语义区域中是不同的。因此,它可以确定融合图像中每个语义对象的保存程度,η 是一个正参数,控制两个项之间的权衡。
第二损失Ladv表示生成器G和两个鉴别器之间的对抗损失,可以定义为:

第三损失Lgrad表示梯度约束。我们强制融合图像If具有类似于Ir和Iv的梯度,可以表示如下:

第四损失Lmse代表MSE损失。我们应用MSE损失来约束融合图像以包含来自源图像的大量信息,可以定义为:
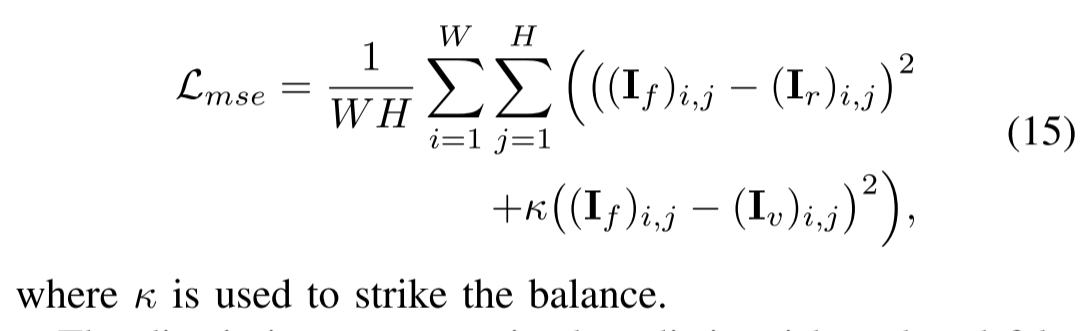
对判别器进行了训练,以区分真实数据和虚假数据,并输出标量,该标量估计输入来自真实数据而不是G的概率。这两个判别器的对抗性损失定义如下:
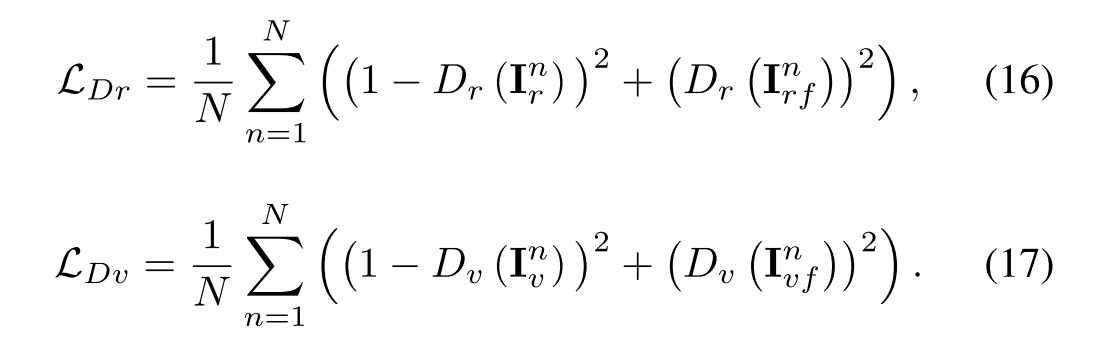
Network Architecture
Generator Architecture
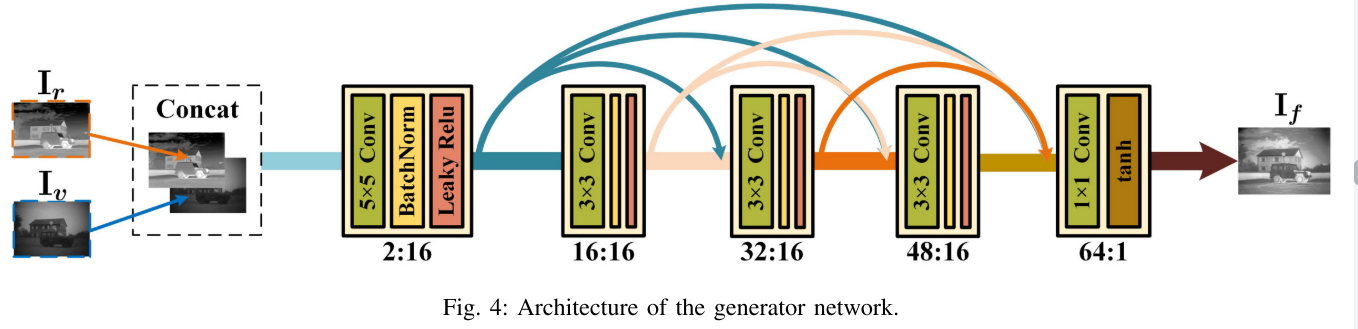
我们的生成器G的网络架构如图4所示。我们在通道维度上连接红外和可见图像,并将它们用作G的输入。输出是最终的融合图像。G由五个常见的卷积层组成。对于每个卷积层,填充设置为SAME(SAME用来保证在卷积过程中不改变输入图像的大小),步幅设置为1。因此,特征图的大小不会改变。在所有卷积层中,我们采用批归一化和激活功能来克服数据初始化的敏感性并避免消失的梯度。对于前四层,我们采用批归一化和Leaky ReLU激活函数来提高G的鲁棒性; 对于最后一层,我们仅使用tanh激活函数。五个卷积层中的内核大小为5 × 5、3 × 3和1 × 1。卷积核的数量为16、16和1。我们在前四层中从密集连接的卷积网络中应用密集连接的层。如图4中的箭头所示,我们以前馈方式在每个层和所有层之间建立连接,以进行特征重用,防止在卷积过程中删除一些重要信息。因此,五层的输入和输出通道分别为2:16、16:16、32: 16、48: 16和64: 1。
Discriminator Architecture
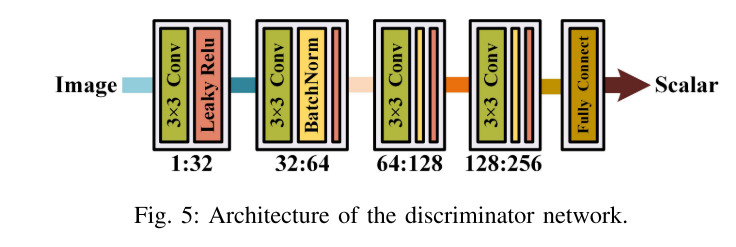
我们的网络中有两个判别器Dr和Dv。它们具有相同的体系结构,如图5所示,它们都用作分类器,生成标量以估计来自真实数据而不是G的输入图像的概率。我们的鉴别器的体系结构是一个简单的五层卷积神经网络。步幅设置为2,填充设置为有效。因此,不需要池化层。我们在第二,第三和第四卷积层中应用批归一化,并在前四层中采用Leaky ReLU激活功能。最后一层是全连接层,主要用于分类。从第一层到第四层,内核大小设置为3 × 3,卷积内核的数量设置为32、64、128和256。因此,输入和输出通道是1: 32、32: 64、64: 128和128: 256。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









