









PANFORMER: A TRANSFORMER BASED MODEL FOR PAN-SHARPENING
(PANFORMER:一种基于transformer的PAN锐化模型)
全色锐化的目的是从同一颗卫星获取的低分辨率(LR)多光谱(MS)图像及其对应的全色(PAN)图像生成高分辨率(HR)多光谱(MS)图像。受最近深度学习社区的新时尚的启发,我们提出了一种新的基于Transformer的泛锐化模型。我们探索了Transformer在图像特征提取和融合方面的潜力。在视觉Transformer的成功开发之后,我们设计了一个具有自我注意力的双流网络,以从PAN和MS模态中提取模态特定的特征,并应用交叉注意力模块来合并光谱和空间特征。从增强的融合特征产生泛锐化图像。在GaoFen-2和WorldView-3图像上进行的大量实验表明,我们基于Transformer的模型取得了令人印象深刻的结果,并且优于许多现有的基于CNN的方法,这表明将Transformer引入泛锐化任务的巨大潜力。
介绍
在地理、土地测量、环境监测等实际应用中,需要同时具有高空间分辨率和高光谱分辨率的高质量遥感图像。大多数遥感传感器以一对方式提供图像:多光谱(MS)图像及其对应的全色(PAN)图像。MS图像具有丰富的光谱信息,但空间分辨率较低,而PAN图像具有高的空间分辨率,但只有一个波段。为了联合这两种模式的优势,泛锐化任务的重点是合并来自PAN和MS图像的互补信息,并创建高分辨率MS(HR MS)图像。
最近,深度学习在各种计算机视觉任务中取得了巨大的成功,激励研究人员开发利用深度神经网络的能力的泛锐化方法。PNN从超分辨率网络中借用了这个想法,设计了一个3层CNN来解决泛锐化问题。这项工作启发了许多后续研究。然而,它们中的大多数解决了从图像超分辨率视图的全色锐化,该图像超分辨率视图学习从联合PAN-MS空间到目标HR MS空间的非线性映射,其中PAN图像被视为输入的通道。考虑到PAN和MS图像之间的差异携带不同的信息,一些研究人员提出使用不同的子网络来提取两种模式的特征。
已经发现,捕获PAN和MS带之间的相关性并将它们纳入融合过程对于减少HR MS的光谱失真是必要的。然而,很少有作品考虑到这一点。在本文中,我们用一种新的基于Transformer的网络来解决这个问题。我们的方法引入了一种新的交叉注意块,能够跨PAN和MS模态建模冗余和互补信息。首先,我们构建了一个编码器与Transformer架构,以提取特定于模态的功能,分别从PAN和MS图像。然后,我们提出了一个交叉注意操作,以鼓励两种模式之间的信息交换。交叉注意模块可以捕获PAN和MS之间的复杂相关关系,这对于实现最佳融合性能至关重要。在头部中,我们应用恢复模块来生成最终的泛锐化图像。
贡献
1))我们设计了一个基于Transformer的泛锐化模型,称为PanFormer。据我们所知,这是Transformer首次应用于全色锐化任务。
2)我们设计了一个双流网络来提取特定于模态的特征,并将其与一个新的交叉注意模块融合。交叉注意模块能够捕获PAN和MS模态的冗余和互补信息,从而实现良好的全景锐化性能。
3)在GaoFen-2和WorldView-3数据集上的实验表明,与现有的基于CNN的模型相比,我们提出的方法具有竞争力的性能。
相关工作
Deep learning based pan-sharpening
近年来,深度学习技术进入了蓬勃发展的时期,并在各种计算机视觉领域表现出主导性的表现。观察到泛锐化任务与超分辨率具有类似的精神,Masi等人借用了SRCNN的想法,并提出了一个3层CNN模型来解决泛锐化。为了进一步提高性能,越来越多的研究人员致力于设计更深更宽的CNN架构来进行泛锐化。Yang等人设计了一个13层CNN模型。他们设法在残差学习和泛锐化之间建立了一座桥梁,其中网络学习预测实际上是LR MS和HR MS之间残差图像的高频细节。Yuan等人将深CNN与浅CNN相结合,形成多尺度解决方案。Liu等人设计了一个双流网络,分别从PAN和MS输入中提取增强的模态特定特征。在这项工作之后,PSGAN通过对抗学习进一步提高了其性能。
Vision Transformers
Transformer最早由Vaswani等人提出,用于机器翻译任务,随后成为大多数NLP任务的主流架构。受此启发,研究人员尝试设计视觉变形金刚,并在各种计算机视觉任务中获得了相对于CNN架构的显著改进,包括但不限于图像分类和图像生成。Dosovitskiy等人设计了一个Transformer,它直接应用于图像块序列,并在图像分类方面取得了令人印象深刻的性能。Parmar等人将Transformer扩展到序列建模公式,并显示其在建模文本序列中的有效性。最近,Liu等人提出了一种基于Transformer的视觉骨干网,该骨干网在广泛的视觉任务上大幅超越了以前最先进的骨干网,取得了重大突破。他们强调了类似Transformer的架构在视觉和语言之间统一建模的强大潜力。受此启发,我们的架构设计致力于捕获PAN和MS模态之间的相关和互补信息。
方法
图1说明了PanFormer的体系结构,包括三个模块:modality-specific编码器、交叉模式融合模块、图像恢复模块。
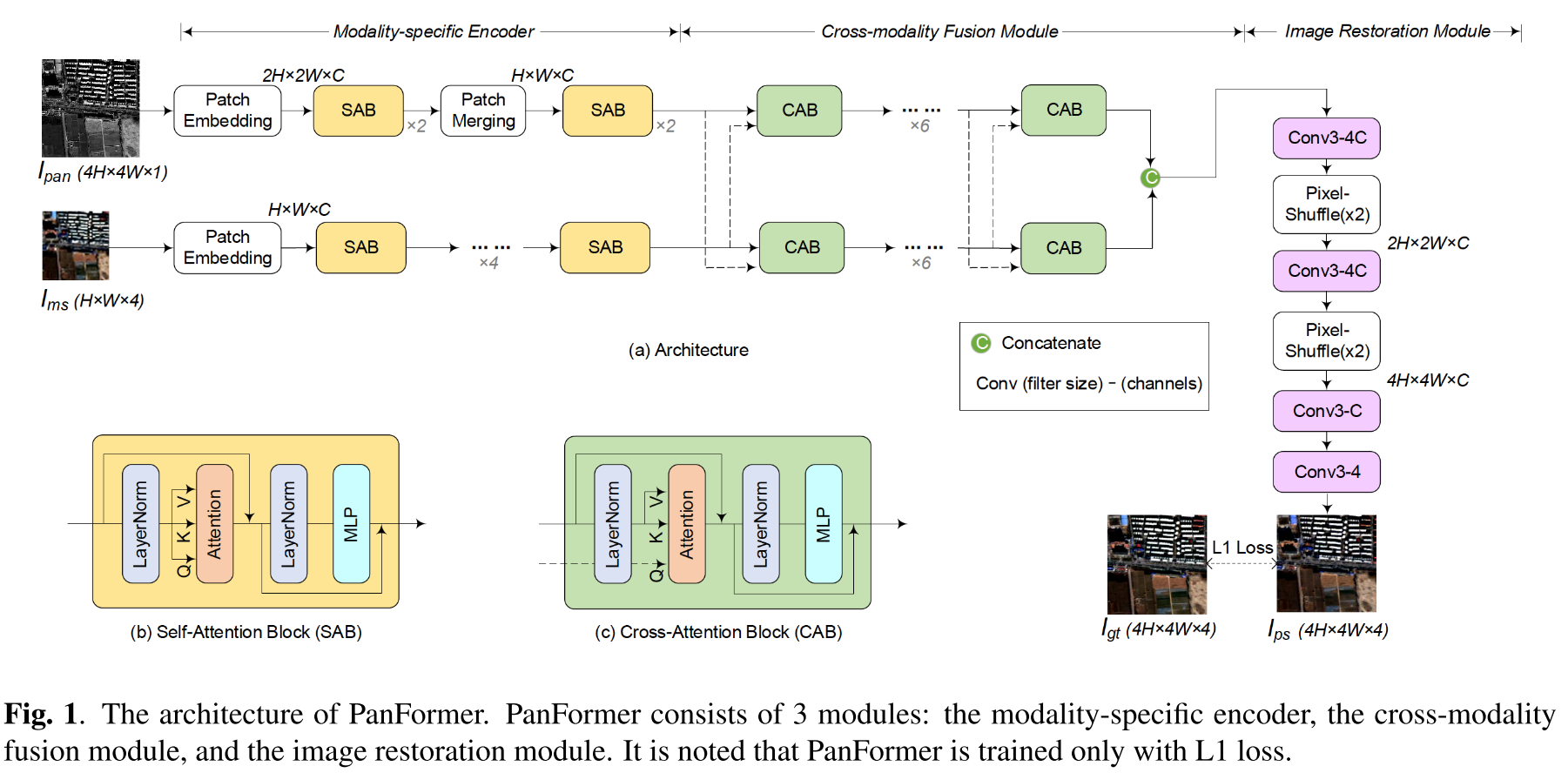
Modality-specific Encoder
我们构建了一个双路径编码器的模态特定的特征提取,其中每个路径处理的方式之一。图像首先被分割成非重叠的补丁,然后送入网络,然后通过线性嵌入投影到一个隐藏的维度(表示为C)。对于PAN图像,补丁大小被设置为2×2。它被转换成大小为2H×2W×C的张量。考虑到MS图像的低分辨率,我们保持其空间分辨率,只做线性嵌入,使其形状为H×W×C。然后,每个补丁被视为一个令牌,制定为一个序列,并由一系列的自我注意块处理。
Self-attention block (SAB)
由于PAN和MS是不同的模态,因此必须使用不同的编码器从它们中提取特征。每个编码器构建有自注意块的堆栈,以产生输入的模态特定的中间特征。每个SAB由两个LayerNorm层、一个自注意层和两个连续的MLP层 (但是图中只有一个MLP层?) 组成。详细架构在图1(b)中示出。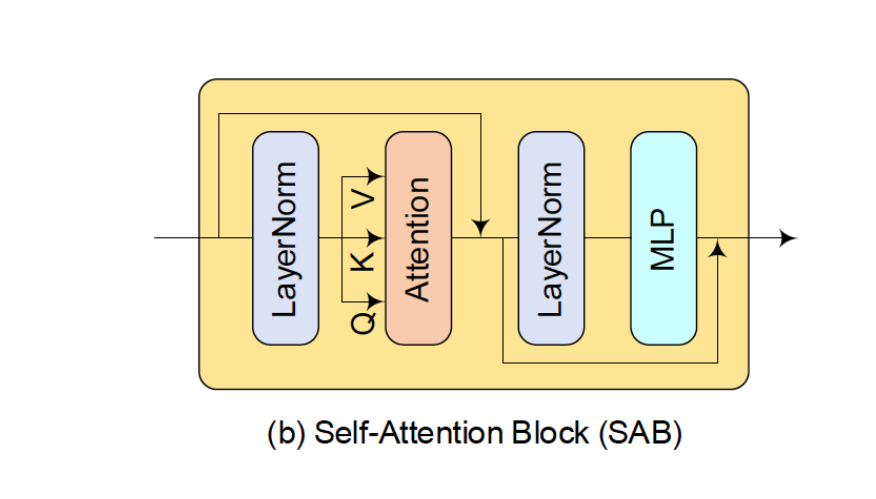
自我注意机制被定义为:
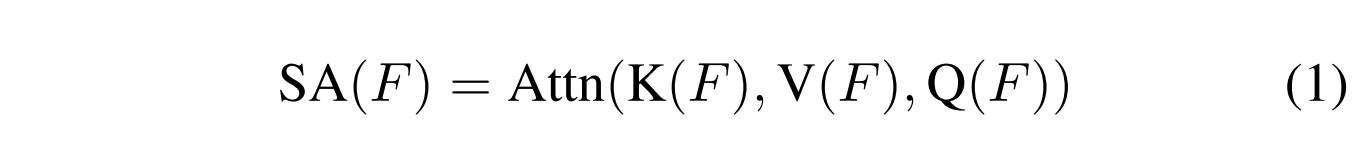
其中SA(·)代表自我关注,F是来自先前LayerNorm的特征向量,K(·)、V(·)、Q(·)是用于生成key, value和query(也称为K、V、Q)向量的线性投影。注意函数Attn(·)具有以下形式: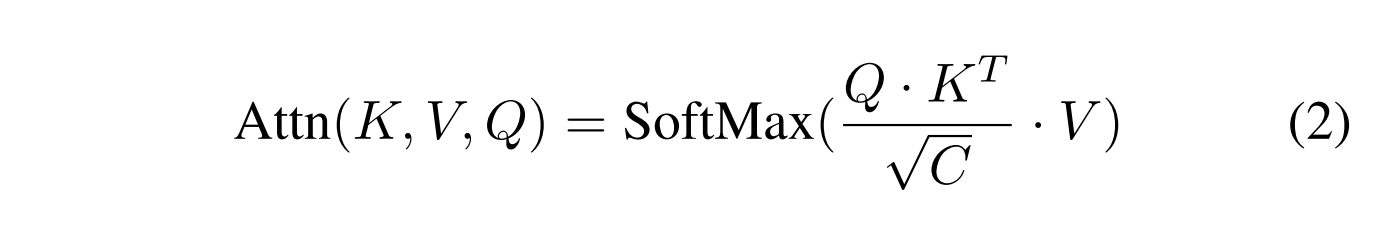
为了便于训练,在每个LayerNorm-X模块中应用残差连接,如图1(b)所示。在2层MLP之后应用GELU激活。
每个模态由4个SAB处理以提取模态特异性特征。对于PAN路径,我们在中间插入一个额外的补丁合并层来合并补丁,以达到与MS路径相同的大小(H×W×C)。受Swin Transformer的启发,我们使用基于窗口的自注意力构建SAB,其中注意力在局部窗口内计算以进行有效建模。
Cross-modality fusion module
PAN和MS图像高度相关,但包含互补信息。因此,对它们之间的跨模态关系进行建模是非常重要的。为了实现这一目标,我们开发了一个交叉注意块,并逐步融合这两种模式。
Cross-attention block (CAB)
给定两个特征Fa和Fb,它们的关系可以使用如下定义的注意力机制来建模,
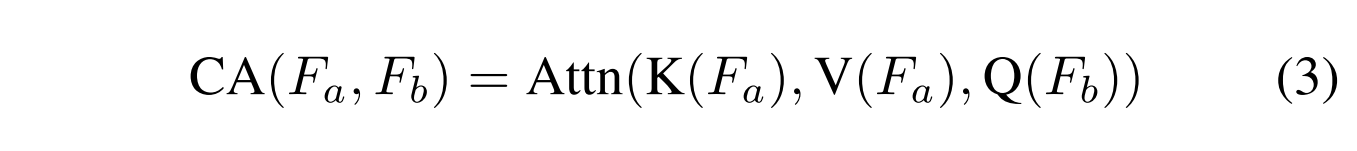
其中CA(·)是用于计算Fa和Fb之间的关系的注意力函数。我们使用相同的注意力函数方程(1)计算CA(·)。
具体来说,有两种不同的方式来制定交叉注意:K和V从PAN(或MS)图像导出,而Q从MS(或PAN)图像导出。为方便起见,我们称之为PAN-X-MS和MS-X-PAN。融合模块由6个CAB组成,如图1(a)所示。在这里,我们还采用移位窗口策略来实现有效的性能。
不同关注度的输出被连接以制定融合表示,其包含来自不同模态的信息并被馈送到下一个模块。
Image restoration module
最后,头部旨在基于来自跨模态融合模块的融合表示来产生最终的泛锐化图像。为了实现这一目标,我们设计了一个简单而高效的恢复模块。有4个卷积层,每个卷积层的滤波器大小为3×3,步长为1。前两层提取4C通道特征图,第三层提取C通道特征图,最后一层生成最终的4通道融合结果。特别地,前两个层之后是一个像素混洗层,其用于放大中间输出(×2)。我们在每个卷积层之前应用ReLU激活,除了第一个。
Loss Function
我们使用L1损失来训练我们的网络:
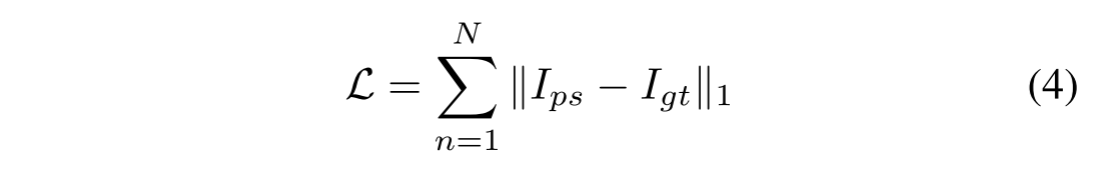
其中N是小批量中的训练样本的数量,Ips代表由我们的模型生成的泛锐化图像,并且Igt是对应的地面真值。














 641
641











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









