







6.21 mktemp–建立临时文件
mktemp建立一个暂存文件供shell script使用
参数:
-q:执行时发生错误,不会显示任何信息
-u:暂存文件会在mktemp结束前先行删除
文件参数:必须是“自定名称.XXXXXX”的格式
mktemp log.XXX #名称可以自定义,后缀通过大写X的位数来指定位数,生成的后缀名称是随机的
6.22 patch–修补文件
patch指令让用户利用设置修补文件的方式,修改,更新原始文件。倘若一次仅修改一个文件,可直接在指令列中下达指令依序执行。如果配合修补文件的方式则能一次修补大批文件,这也是Linux系统核心的升级方法之一。
#使用patch指令将文件"testfile1"升级,其升级补丁文件为"testfile.patch",输入如下命令:
[root@host1 ~]# patch -p0 testfile1 testfile.patch #使用补丁程序升级文件
#使用该命令前,可以先使用指令"cat"查看"testfile1"的内容。在需要修改升级的文件与原文件之间使用指令"diff"比较可以生成补丁文件。具体操作如下所示:
[root@host1 ~]# cat testfile1 #查看testfile1的内容
Hello,This is the firstfile!
[root@host1 ~]# cat testfile2 #查看testfile2的内容
Hello,This is the secondfile!
[root@host1 ~]# diff testfile1 testfile2 #比较两个文件
1c1
<Hello,This is the firstfile!
---
>Hello,This is the secondfile!
#将比较结果保存到tetsfile.patch文件
[root@host1 ~]# diff testfile1 testfile2>testfile.patch
[root@host1 ~]# cat testfile.patch #查看补丁包的内容
1c1
<Hello,This is the firstfile!
---
>Hello,This is the secondfile!
#使用补丁包升级testfile1文件
[root@host1 ~]# patch -p0 testfile1 testfile.patch
patching file testfile1
[root@host1 ~]# cat testfile1 #再次查看testfile1的内容
#testfile1文件被修改为与testfile2一样的内容
Hello,This is the secondfile!
#注意:上述命令代码中,"$ diff testfile1 testfile2>testfile. patch"所使用的操作符">"表示将该操作符左边的文件数据写入到右边所指向的文件中。在这里,即是指将两个文件比较后的结果写入到文件"testfile.patch"中。
6.23 locate–查找文件或目录
#使用指令"slocate"显示文件名中含有关键字"fdisk"的文件路径信息,输入如下命令:
[root@host1 ~]# locate fdisk #显示文件名中含有fdisk关键字的文件的路径信息
执行以上命令后,指令执行的输出信息如下:
[root@host1 ~]# locate fdisk #显示文件名中含有fdisk 关键字的文件的路径信息
/root/cfdisk #搜索到的文件路径列表
/root/fdisk
/root/sfdisk
/usr/include/grub/ieee1275/ofdisk.h
/usr/share/doc/util-Linux/README.cfdisk
/usr/share/doc/util-Linux/README.fdisk.gz
/usr/share/doc/util-Linux/examples/sfdisk.examples.gz
6.24 split–将一个文件分割成数个
参数说明:
-<行数> : 指定每多少行切成一个小文件
-b<字节> : 指定每多少字节切成一个小文件
–help : 在线帮助
–version : 显示版本信息
-C<字节> : 与参数"-b"相似,但是在切 割时将尽量维持每行的完整性
[输出文件名] : 设置切割后文件的前置文件名, split会自动在前置文件名后再加上编号
#使用指令"split"将文件"README"每6行切割成一个文件,输入如下命令:
[root@host1 ~]# split -6 README #将README文件每六行分割成一个文件
#以上命令执行后,指令"split"会将原来的大文件"README"切割成多个以"x"开头的小文件。而在这些小文件中,每个文件都只有6行内容。
#使用指令"ls"查看当前目录结构,如下所示:
[root@host1 ~]# ls #执行ls指令
#获得当前目录结构
README xaa xad xag xab xae xah xac xaf xai
6.25 tmpwatch–删除暂存文件
参数:
-a或–all 删除任何类型的文件。
-f或–force 强制删除文件或目录,其效果类似rm指令的"-f"参数。
-q或–quiet 不显示指令执行过程。
-v或–verbose 详细显示指令执行过程。
-test 仅作测试,并不真的删除文件或目录。
#使用指令"tmpwatch"删除目录"/tmp"中超过一天未使用的文件,输入如下命令:
[root@host1 ~]# tmpwatch 24 /tmp/ #删除/tmp目录中超过一天未使用的文件
#以上命令执行后,其执行结果如下所示:
removing directctmp/orbit-tom if not empty
6.26 csplit–分割文件
将文件依照指定的范本样式予以切割后,分别保存成名称为xx00,xx01,xx02…的文件。若给予的文件名称为"-",则csplit指令会从标准输入设备读取数据。
参数:
-b<输出格式>或–suffix-format=<输出格式> 预设的输出格式其文件名称为xx00,xx01…等
-f<输出字首字符串>或–prefix=<输出字首字符串> 预设的输出字首字符串其文件名为xx00,xx01…等,如果你指定输出字首字符串为"hello",则输出的文件名称会变成hello00,hello01…等。
-k或–keep-files 保留文件,就算发生错误或中断执行,也不能删除已经输出保存的文件。
-n<输出文件名位数>或–digits=<输出文件名位数> 预设的输出文件名位数其文件名称为xx00,xx01…等,如果你指定输出文件名位数为"3",则输出的文件名称会变成xx000,xx001…等。
-q或-s或–quiet或–silent 不显示指令执行过程。
-z或–elide-empty-files 删除长度为0 Byte文件。
#将文本文件testfile以第 2 行为分界点切割成两份,使用如下命令:
csplit testfile 2
#testfile文件中的内容如下:
[root@host1 ~]# cat testfile #查看testfile 文件内容
hello Linux!
Linux is a free Unix-type operating system.
This is a Linux testfile!
Linux
#使用csplit命令,输出结果如下:
[root@host1 ~]# csplit testfile 2
13 #xx00文件字符个数
76 #xx01文件字符个数
#其中第1 行是第一个文件xx00的字符个数,同样,第2 行为第二个文件xx01的字符个数。同时,在testfile 的同目录下将生成两个文件,文件名分别为xx00、xx01,xx00 中的内容为:
[root@host1 ~]# cat xx00 #查看分割后的xx00文件内容
hello Linux! #testfile文件第1行的内容
#xx01 中的内容为:
[root@host1 ~]# cat xx01 #查看分割后的xx01文件内容
Linux is a free Unix-type operating system. #testfile文件第2行以后的内容
This is a Linux testfile!
Linux
6.27 chroot–用于改变根目录
chroot(change root)命令把根目录换成指定的目的目录
#改变根目录
[root@host1 ~]# chroot /mnt/ls //改变根目录
6.28 whereis/which --用于查找系统命令文件位置
参数:
-b 只查找二进制文件
-f 不显示文件名前的路径名称
-m 只查找说明文件
-M<目录> 只在设置的目录下查找说明文件
-s 只查找原始代码文件
-S<目录> 只在设置的目录下查找原始代码文件
-u 查找不包换只当类型的文件
//查看文件位置
[root@host1 ~]# whereis
//查看可执行文件位置
[root@host1 ~]# which
6.29 sort --对数据进行排序命令
sort默认会按照指定的默认语言的排序规则对文本文件进行排序。sort可针对文本文件的内容,以行为单位来排序。
参数:
-b 忽略每行前面开始处的空格字符。
-c 不排序,仅检查文件是否已经按照顺序排序。
-d 排序时,处理英文字母、数字及空格字符外,忽略其他的字符。
-f 排序时,将小写字母视为大写字母。
-g 按通用数值来排序
-k n1 n2 排序从n1位置开始,如果指定了n2则到n2结束。
-i 排序时忽略不可打印的字符。
-m 将几个排序好的文件进行合并。
-M 将前面3个字母依照月份的缩写进行排序。
-n 依照数值的大小排序。
-o<输出文件> 将排序后的结果存入指定的文件。
-r 以相反的顺序来排序。
-R 按随机生成的散列表的键值排序
-t<分隔字符> 指定排序时所用的栏位分隔字符。
+<起始栏位>-<结束栏位> 以指定的栏位来排序,范围由起始栏位到结束栏位的前一栏位。
–help 显示帮助。
–version 显示版本信息。
//将文件passwd按照第三个字段的数值大小进行排序,字段以;分隔区分
[root@host1 ~]# sort -n -t ':' -k 3 /etc/passwd
6.30 grep --搜索数据命令
参数:
--help 查看帮助
-c:只输出匹配行的计数
-i:不区分大小写
-h:查询多文件时不显示文件名
-l:查询多文件时只输出包含匹配字符的文件名
-n:显示匹配行及行号
-s:不显示不存在或无匹配文本的错误信息
-v:显示不包含匹配文本的所有行
-e:指定多个匹配模式
-w:字符串精确匹配
-o:只输出匹配的部分
--color=auto:可以将找到的关键词部分加上颜色的显示
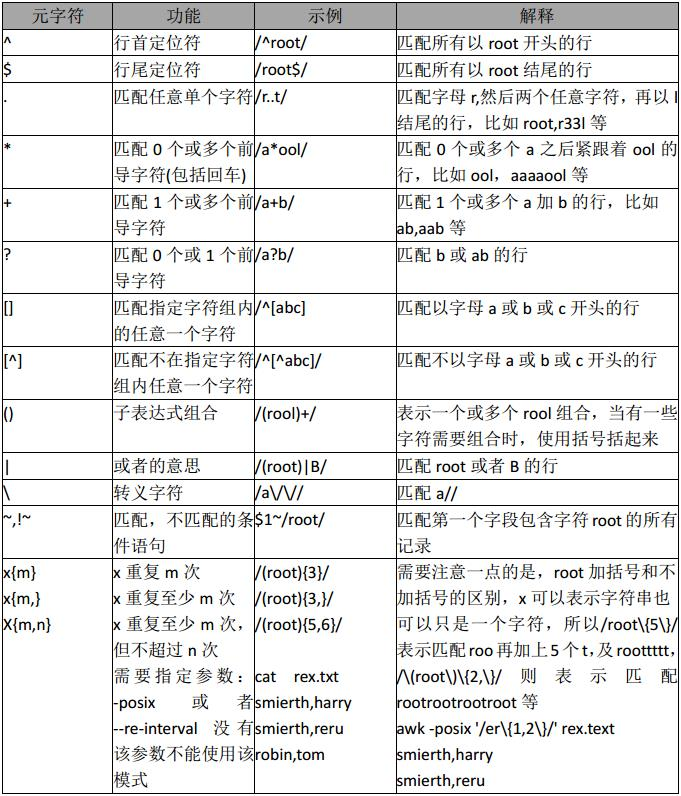
pattern正则表达式主要参数:
\:忽略正则表达式中特殊字符的原有含义
^:匹配正则表达式的开始行
$:匹配正则表达式的结束行
<:从匹配正则表达式的行开始
>:到匹配正则表达式的行结束
[-]:范围
.:所有的单个字符
*:所有字符,长度可以为0
//显示所有以d开头的文件中包含test的行
[root@host1 ~]# grep 'test' d*
//显示在aa,bb,cc文件中匹配test的行
[root@host1 ~]# grep 'test' aa bb cc
//显示aa文件中每个字符串至少有5个连续小写字符的字符串的行
[root@host1 ~]# grep '[a-z]\{5\}' aa
//需要搜索子目录
[root@host1 ~]# grep -r
//忽略子目录
[root@host1 ~]# grep -d skip
//通过管道将查到的内容输出到less文件上阅读
[root@host1 ~]# grep 'magic' /usr/src/local/* | less
//匹配多个字符串 grep -E 和 egrep 效果相同
[root@host1 ~]# cat test/test1.txt
1
2
3
[root@host1 ~]# grep -E '1|3' test/test1.txt
1
3
[root@host1 ~]# egrep '1|3' test/test1.txt
1
3
//匹配字符串不区分大小写
[root@host1 ~]# grep - i 'err' /var/log/messages
6.31 awk程序–适合文本处理和报表生成
awk是以文件的一行为处理单位的。awk每接收文件的一行,然后执行相应的命令,来处理文本。awk 作为三剑客的老大,功能非常强大,这里只汇总部分参数和模块,建议单独学习。
参数:
-F:指定分隔符,可指定一个或多个
内置变量:
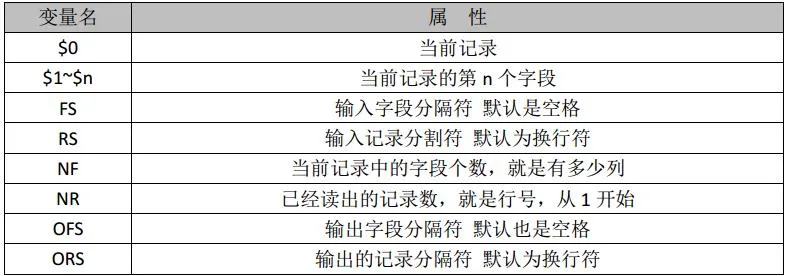
[root@host1 ~]# awk '{print $0}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
[root@host1 ~]# awk -F":" '{ print $1 }' /etc/passwd
root
bin
[root@host1 ~]# awk -F":" '{ print $1 $3 }' /etc/passwd
root0
bin1
[root@host1 ~]# awk -F":" '{ print $1 " " $3 }' /etc/passwd
root 0
bin 1
[root@host1 ~]# awk -F":" '{ print "username:" $1 "\t\tuid:" $3 }' /etc/passwd
username:root uid:0
username:bin uid:1
//只查看test.txt文件(100行)内第20到第30行的内容
[root@host1 ~]# awk '{if(NR>=20 && NR<=30) print $1}' test.txt
BEGIN 和 END 模块
BEGIN{} 行前处理,读取文件内容前执行,指令执行 1 次
{} 逐行处理,读取文件过程中执行,指令执行 n 次
END{} 行后处理,读取文件结束后执行,指令执行 1 次
//统计/etc/passwd的账户人数
[root@host1 ~]# awk '{count++;print $0;} END{print "user count is ",count}' /etc/passwd
user count is 40
//统计某个文件夹下的文件占用的字节数
[root@host1 ~]# ll |awk 'BEGIN {size=0;} {size=size+$5;} END{print "[end]size is ",size}'
[end]size is 5960140
awk 运算符
&&:逻辑与
||:逻辑或
[root@host1 ~]# awk 'BEGIN{a=5;a+=5;print a}'
10
[root@host1 ~]# awk 'BEGIN{a=1;b=2;print (a>2&&b>1,a=1||b>1)}'
0 1
//列出uid小于2的用户信息
[root@host1 ~]# awk -F : '$3>=0 && $3<2 {print $1,$3}' /etc/passwd
//列出100以内整数中7的倍数或是含7的数:
[root@host1 ~]# seq 100 | awk '$1%7==0 || $1~/7/'
//以冒号作为分隔符,匹配第5个字段是root的行
[root@host1 ~]# awk -F : '$5~/root/{print $0}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
//以冒号作为分隔符,匹配第1和第5个字段是root的行
[root@host1 ~]# awk -F: '($1=="root")&&($5=="root") {print $0}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
流程控制
分支结构:
- 单分支 if(条件){编辑指令}
- 双分支 if(条件){编辑指令 1} else {编辑指令 2}
- 多分支 if(条件){编辑指令 1} else {编辑指令 2} else {编辑指令 N}
[root@host1 ~]# awk 'BEGIN{a="100testaa";if(a~/100/) {print "ok"}}'
ok
[root@host1 ~]# awk 'BEGIN{a=11;if(a>=9){print "ok"}}'
ok
[root@host1 ~]# awk -F : '{if($7~/bash$/){i++} else {j++}} END {print i,j}' /etc/passwd
2 38
数组
定义数组 数组名 [ 下标 ] = 元素值
调用数组 数组名 [ 下标 ]
遍历数组 for (变量 in 数组名){print 数组名 [ 变量 ]}
[root@host1 ~]# awk 'BEGIN{a[0]=11;a[1]=88;print a[1],a[0]}'
88 11
6.32 sed命令–流式编辑器
sed编辑器被称作流编辑器。在交互式文本编辑器中(比如vim),你可以用键盘命令来交互式地插入,删除或替换数据中的文本。流编辑器则会在编辑器处理数据之前基于预先提供的一组规则来编辑数据流。
sed编辑器会执行以下操作:
(1)一次从输入中读取一行数据
(2)根据所提供的编辑器命令匹配数据
(3)按照命令修改流中的数据
(4)将新的数据输出到STDOUT
在流编辑器将所有命令与一行数据匹配完毕后,它会读取下一行数据并重复这个过程。在流编辑器处理完流中的所有数据行后,它就会终止。
sed [ 选项 ] ‘编辑指令’ 文件
选项:-n 屏蔽默认输出(全部文本)
- i 直接修改文件内容
-r 启用扩展的正则表达式,若与其他选项一起使用,应作为首个选项
//输出第2~4行
[root@host1 ~]# sed -n '2,4p' /etc/passwd
//输出全部
[root@host1 ~]# sed -n 'p' /etc/passwd
//输出包含root的行
[root@host1 ~]# sed -n '/root/p' /etc/passwd
//输出文件行数
[root@host1 ~]# sed -n '$=' /etc/passwd
//打印偶数行
[root@host1 ~]# sed -n '2~2p' /etc/passwd
动作指令:
| p | 打印行 | 2,4p 输出 2~4 行
2p;4p 输出 2、4 行 |
| — | — | — |
| d | 删除行 | 2,4d 删除 2~4 行 |
| s | 字符串替换 | s/old/new/ 将每行的第 1 个 old 替换为 new
s/old/new/3 将每行的第 3 个 old 替换为 new
s/old/new/g 将所有 old 替换为 new |
//替换第2行的2017为空
[root@host1 ~]# sed '2s/2017//2' a.txt
//只显示被替换的部分
[root@host1 ~]# sed -n 's/2017/xxx/p' a.txt
//将文件中每行的第一个,倒数第一个字符互换
[root@host1 ~]# sed -r 's/^(.)(.*)(.)$/\3\2\1/' test.txt
sed 多行文本处理
i 在指定行之前插入文本
a 在指定行之后追加文本
c 替换指定的行
[root@host1 ~]# sed '1i xxx' a.txt
//把a.txt另存为b.txt
[root@host1 ~]# sed '2w/b.txt' a.txt
sed 复制剪切
-H:模式空间 — [ 追加 ] — 保持空间 复制
-h:模式空间 — [ 覆盖 ] — 保持空间 复制
-G:保持空间 — [ 追加 ] — 模式空间 粘贴
-g:保持空间 — [ 覆盖 ] — 模式空间 粘贴
6.33 sleep --进程等待(睡眠)命令
参数说明:
–help : 显示辅助讯息
–version : 显示版本编号
number : 时间长度,后面可接 s、m、h 或 d
其中 s 为秒,m 为 分钟,h 为小时,d 为日数
//休眠5分钟
[root@host1 ~]# sleep 5m
//显示目前时间后延迟 1 分钟,之后再次显示时间
[root@host1 ~]# date;sleep 1m;date
6.34 jobs --显示后台作业信息
-l:显示进程号;
-p:仅任务对应的显示进程号;
-n:显示任务状态的变化;
-r:仅输出运行状态(running)的任务;
-s:仅输出停止状态(stoped)的任务。
6.35 nohup --不挂断执行命令 & --在后台运行命令
一般两个一起用 nohup command &
nohup /usr/local/node/bin/node /www/im/chat.js >> /usr/local/node/output.log 2>&1 &
6.36 2>&1
nohup /usr/local/node/bin/node /www/im/chat.js >> /usr/local/node/output.log 2>&1 &
对于& 1 更准确的说应该是文件描述符 1,而1标识标准输出,stdout。
对于2 ,表示标准错误,stderr。
2>&1 的意思就是将标准错误重定向到标准输出。这里标准输出可以指定到文件,也可以重定向到 /dev/null。那么标准错误也会输出到/dev/null,/dev/null相当于linux黑洞,数据会被丢弃掉。
stdout – 标准输出设备 。
stderr – 标准错误输出设备
两者默认向屏幕输出。
但如果用转向标准输出到磁盘文件,则可看出两者区别。stdout输出到磁盘文件,stderr在屏幕。
















 8930
8930

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









