










本文英文链接:https://github.com/OptimalBits/bull/tree/develop/docs
译文:嗨Sirius
什么是 Bull?
Bull 是一个 Node 库,它基于redis实现了一个快速、健壮的队列系统。
尽管可以直接使用 Redis 命令实现队列,但该库提供了一个 API,它处理所有低级细节并丰富了 Redis 基本功能,以便可以轻松处理更复杂的用例。
如果您不熟悉队列,您可能想知道为什么需要它们。队列可以以一种优雅的方式解决许多不同的问题,从平滑处理峰值到在微服务之间创建强大的通信通道,或者将繁重的工作从一台服务器卸载到许多较小的工作人员等等。
快速开始
Bull 是一个公共的 npm 包,可以使用 npm 或 yarn 安装:
$ npm install bull --save
or
$ yarn add bull
为了使用 Bull,您还需要运行 Redis 服务器。 对于本地开发,需要使用 docker.
Bull 默认会尝试连接到运行在 localhost:6379
@嗨Sirius:所以你的 Kubernetes 配置应该是
apiVersion: apps/v1
kind: Deployment
metadata:
name: expiration-redis-depl
spec:
replicas: 1
selector:
matchLabels:
app: expiration-redis
template:
metadata:
labels:
app: expiration-redis
spec:
containers:
- name: expiration-redis
image: redis
---
apiVersion: v1
kind: Service
metadata:
name: expiration-redis-srv
spec:
selector:
app: expiration-redis
ports:
- name: db
protocol: TCP
port: 6379
targetPort: 6379
简单队列
通过实例化 Bull 实例(instance)可以简单地创建队列:
const myFirstQueue = new Bull("my-first-queue");
一个队列实例通常可以有 3 个主要的不同角色:作业生产者(producer)、作业消费者(consumer)或/和事件侦听器(events listener)。
虽然一个给定的实例可以用于 3 个角色,但通常生产者和消费者被分为几个实例。一个给定的队列,总是由它的实例化名称引用(my-first-queue在上面的例子中),可以有许多生产者、许多消费者和许多侦听器。一个重要的方面是,即使当时没有可用的消费者,生产者也可以将作业 job 添加到队列中:队列提供异步通信,这是使它们如此强大的特性之一。
相反,您可以让一个或多个 workers 使用队列中的作业,它们将按照给定的顺序使用作业:FIFO 先进先出(默认)、LIFO 后进先出或根据优先级。
谈到 workers,他们可以在相同或不同的进程中,在同一台机器或集群中运行。Redis 将作为一个公共点,只要消费者或生产者可以连接到 Redis,他们将能够合作处理作业。
Producers 生产者
作业(job)生产者只是一些将作业添加到队列的 Node 程序,如下所示:
const myFirstQueue = new Bull("my-first-queue");
const job = await myFirstQueue.add({
foo: "bar",
});
As you can see a job is just a javascript object. This object needs to be serializable, more concrete it should be possible to JSON stringify it, since that is how it is going to be stored in Redis.
It is also possible to provide an options object after the job’s data, but we will cover that later on.
如您所见,job 只是一个 javascript 对象。这个对象需要是可序列化的,更具体地说,应该可以对它进行 JSON 字符串化,因为这就是它在 Redis 中的存储方式。
也可以在作业数据之后提供一个选项对象,但我们稍后会介绍。
Consumers 消费者
消费者或工作者(我们将在本指南中交替使用这两个术语)只不过是一个定义流程函数的 Node 程序,如下所示:
const myFirstQueue = new Bull("my-first-queue");
myFirstQueue.process(async (job) => {
return doSomething(job.data);
});
process每次工人空闲并且队列中有作业要处理时,都会调用该函数。由于添加作业时消费者不需要在线,因此队列中可能已经有许多作业在等待,因此该进程将一直忙于处理作业,直到所有作业都完成为止。
在上面的示例中,我们将流程函数定义为async,这是强烈推荐的定义它们的方式。如果您的 Node 运行时不支持 async/await,那么您可以在 process 函数结束时返回一个 Promise 以获得类似的结果。
您的流程函数返回的值将存储在作业对象中,稍后可以访问,例如在 completed 事件的侦听器中。
有时您需要向外部侦听器提供作业的进度 __progress__ 信息,这可以通过使用作业对象上的方法轻松完成:
myFirstQueue.process(async (job) => {
let progress = 0;
for (i = 0; i < 100; i++) {
await doSomething(job.data);
progress += 10;
job.progress(progress);
}
});
Listeners 监听者
最后,您可以只监听队列中发生的事件。侦听器可以是本地的,这意味着它们只会接收在给定队列实例中产生的通知,也可以是全局的,这意味着它们会侦听给定队列的所有事件。因此,您可以将侦听器附加到任何实例,甚至是充当消费者或生产者的实例。但请注意,如果队列不是消费者或生产者,本地事件将永远不会触发,在这种情况下您将需要使用全局事件。
const myFirstQueue = new Bull("my-first-queue");
// Define a local completed event
myFirstQueue.on("completed", (job, result) => {
console.log(`Job completed with result ${result}`);
});
A Job’s Lifecycle
为了充分发挥 Bull 队列的潜力,了解作业的生命周期很重要。从生产者调用add队列实例上的方法的那一刻起,作业进入一个生命周期,它将处于不同的状态,直到其完成或失败(尽管从技术上讲,失败的作业可以重试并获得新的生命周期)。
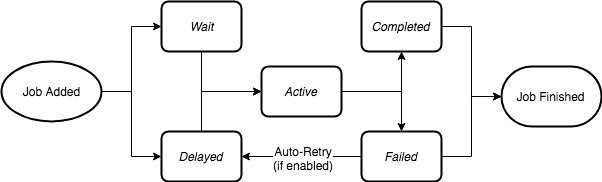
当一个作业被添加到队列中时,它可以处于两种状态之一,它可以处于“等待”状态,这实际上是一个等待列表,所有作业必须进入其中才能被处理,或者它可以处于“延迟”状态:延迟状态意味着该作业正在等待某个超时或被提升以进行处理,但是,延迟的作业不会被直接处理,而是被放置在开始等待列表并在工作人员空闲时立即处理。
作业的下一个状态是“活动”状态。活动状态由一个集合表示,并且是当前正在处理的作业,即它们正在运行在process前一章中解释的函数中。作业可以无限长时间处于活动状态,直到流程完成或引发异常,以便作业将以“已完成”或“失败”状态结束。
停滞的 jobs
在 Bull 中,我们定义了停滞工作的概念。停滞的作业是正在处理的作业,但 Bull 怀疑进程功能已挂起。当进程函数正在处理作业并且使 CPU 如此繁忙以至于工作人员无法告诉队列它仍在处理作业时,就会发生这种情况。
当作业停止时,根据作业设置,该作业可以由另一个空闲的工作人员重试,或者它可以只是移动到失败状态。
可以通过确保进程函数不会使 Node 事件循环保持太长时间(我们使用 Bull 默认选项讨论几秒钟)或使用单独的沙盒处理器来避免停滞的作业。
Events 事件
Bull 中的队列会生成一些在许多用例中有用的事件。对于给定的队列实例(工作人员),事件可以是本地的,例如,如果在给定的工作人员中完成了一项工作,则将为该实例发出本地事件。但是,可以通过添加global:本地事件名称的前缀来监听所有事件。然后我们可以监听给定队列的所有工作人员产生的所有事件。
A local complete event:
queue.on("completed", (job) => {
console.log(`Job with id ${job.id} has been completed`);
});
而事件的全局版本可以通过以下方式收听:
queue.on("global:completed", (jobId) => {
console.log(`Job with id ${jobId} has been completed`);
});
请注意,全局事件的签名与其本地对应的签名略有不同,在上面的示例中,它仅发送作业 id 而不是作业本身的完整实例,这是出于性能原因。
The list of available events can be found in the reference.
Queue Options
可以使用一些有用的选项来实例化队列,例如,您可以指定 Redis 服务器的位置和密码,以及一些其他有用的设置。所有这些设置都在 Bull 的参考资料中进行了描述,我们不会在这里重复它们,但是,我们将介绍一些用例。
Rate Limiter 速率限制器
可以创建限制单位时间内处理的作业数量的队列。限制器是按队列定义的,与工作人员的数量无关,因此您可以水平扩展并仍然轻松限制处理速率:
// Limit queue to max 1000 jobs per 5000 milliseconds.
const myRateLimitedQueue = new Queue("rateLimited", {
limiter: {
max: 1000,
duration: 5000,
},
});
当队列达到速率限制时,请求的作业将加入delayed队列。
Named jobs
可以为 job 工作命名。这不会改变队列的任何机制,但可以用于更清晰的代码和更好的 UI 工具可视化:
// Jobs producer
const myJob = await transcoderQueue.add("image", { input: "myimagefile" });
const myJob = await transcoderQueue.add("audio", { input: "myaudiofile" });
const myJob = await transcoderQueue.add("video", { input: "myvideofile" });
// Worker
transcoderQueue.process("image", processImage);
transcoderQueue.process("audio", processAudio);
transcoderQueue.process("video", processVideo);
请记住,每个队列实例都需要为每个命名作业提供一个处理器,否则您将遇到异常。
Sandboxed Processors 沙盒处理器
如上所述,在定义进程函数时,也可以提供并发设置。此设置允许工作人员并行处理多个作业。这些作业仍然在同一个 Node 进程中处理,如果这些作业是 IO 密集型的,它们将得到很好的处理。
有时作业更占用 CPU,这可能会锁定 Node 事件循环太久,Bull 可能会确定作业已停止。为了避免这种情况,可以在单独的 Node 进程中运行进程函数。在这种情况下,并发参数将决定允许运行的最大并发进程数。
我们将这种进程称为“沙盒”进程,它们还具有在崩溃时不会影响任何其他进程的特性,并且会自动生成一个新进程来替换它。
Job types
Bull 中的默认作业类型是“FIFO”(先进先出),这意味着作业按照它们进入队列的相同顺序进行处理。有时以不同的顺序处理作业很有用。
LIFO 后进先出
Lifo(后进先出)意味着作业被添加到队列的开头,因此一旦工人空闲就会被处理。
const myJob = await myqueue.add({ foo: "bar" }, { lifo: true });
Delayed 延迟
也可以将作业添加到队列中,这些作业在处理之前延迟了一定时间。请注意,延迟参数表示作业在处理之前将等待的最短时间。当延迟时间过去后,作业将被移动到队列的开头,并在工作人员空闲时立即处理。
// Delayed 5 seconds
const myJob = await myqueue.add({ foo: "bar" }, { delay: 5000 });
Prioritized 优先
可以将作业添加到具有优先级值的队列中。优先级较高的作业将比优先级较低的作业先处理。最高优先级为 1,并降低您使用的较大整数。请记住,优先级队列比标准队列慢一点(当前插入时间 O(n),n 是当前队列中等待的作业数,而不是标准队列的 O(1))。
const myJob = await myqueue.add({ foo: "bar" }, { priority: 3 });
Repeatable
可重复作业是根据 cron 规范或时间间隔无限期重复自身或直到达到给定最大日期或重复次数的特殊作业。
// Repeat every 10 seconds for 100 times.
const myJob = await myqueue.add(
{ foo: "bar" },
{
repeat: {
every: 10000,
limit: 100,
},
}
);
// Repeat payment job once every day at 3:15 (am)
paymentsQueue.add(paymentsData, { repeat: { cron: "15 3 * * *" } });
关于可重复作业有一些重要的注意事项:
Bull 足够聪明,不会在重复选项相同的情况下添加相同的可重复作业。(注意:作业 ID 是重复选项的一部分,因为:#603,因此传递作业 ID 将允许将具有相同 cron 的作业插入队列中)
如果没有工作人员在运行,则下次工作人员在线时将不会累积可重复的作业。
可以使用 removeRepeatable 方法删除可重复的作业。














 44
44











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









