






Linux概述
Linux是一种开放源代码和自由传播的计算机操作系统,Linux这个词本身只表示Linux内核,但是人们已经习惯使用Linux来形容整个基于Linux内核,并且使用GNU计划中众多外围程序的操作系统。Linux内核由林纳斯•托瓦兹(Linus Torvalds)在1991年10月5日首次发布。
Linux能有今天的发展绝非偶然,将Linux加入GUN项目计划,使Linux遵循POSIX标准。
Vmware的三种网络模式
-
桥接模式

-
NAT模式

-
仅主机模式

Linux中用于网络传输的协议为 SSH ,用于远程文件管理的协议为 SFTP 。
Linux特点:多用户、多线程、多CPU。
Linux常用命令
Linux命令遵循的基本格式:Command [options] [arguments]
文件操作命令
-
ls
列出参数的属性信息(单词:list)
命令格式:ls [选项] [参数]
-
cd
切换目录(单词:change directory)
命令格式:cd 参数
选项 说明 -l 以详细信息的形式展示出当前目录下的文件 -a 显示当前目录下的全部文件(包括隐藏文件) -d 查看目录属性 -t 按创建时间顺序列出文件 -i 输出文件的inode编号 -R 列出当前目录下的所有文件信息,并以递归地方式显示各个子目录中的文件和子目录信息 -
pwd
打印当前工作目录的绝对路径(单词:print working directory)
命令格式:pwd
-
touch
更新已存在文件的时间标签,若文件不存在则新建文件(单词:touch)
命令格式:touch 参数
-
mkdir
创建目录(单词:make directory)
命令格式:mkdir [选项] 参数
选项 说明 -p 若路径中的目录不存在,则先创建目录; -v 查看文件创建过程。 -
rmdir
删除一个空目录(单词:remove directory)
命令格式:rmdir [-p] 目录
-
cp
将一个或多个源文件复制到指定目录(单词:copy)
命令格式:cp [选项] 源文件或目录 目标目录
选项 说明 -R 递归处理,将指定目录下的文件及子目录一并处理 -p 拷贝的同时不修改文件属性,包括所有者、所属组、权限和时间 -f 强行复制文件或目录,无论目的文件或目录是否已经存在 -
rm
删除目录中的文件或目录(单词:remove)
命令格式:rm [选项] 文件或目录
选项 说明 -f 强制删除文件或目录 -rf 选项-r与-f结合,删除目录中所有文件和子目录,并且不一一确认 -i 在删除文件或目录时对要删除的内容逐一进行确认(y/n)
文件查看命令
-
cat
打印文件内容到输出设备(单词:concatenate and display files)
命令格式:cat 文件名
-
more
分页显示文件内容
命令格式:more 文件名
快捷键 说明 f/Space 显示下一页 Enter 显示下一行 q/Q 退出 -
head
查看文件的前n行
命令格式:head –n 文件名
-
tail
查看文件的后n行
命令格式:tail –n 文件名
权限管理命令
Linux系统中将用户分为文件或目录的拥有者、同组用户、其他组用户和全部用户;
又根据用户对文件的权限,将用户权限分为读取权限(read)、写入权限(write)和执行权限(execute)。
| 权限 | 对应字符 | 文件 | 目录 |
|---|---|---|---|
| 读权限 | r | 可查看文件内容 | 可以列出目录中的内容 |
| 写权限 | w | 可修改文件内容 | 可以在目录中创建、删除文件 |
| 执行权限 | x | 可执行该文件 | 可以进入目录 |
-
chown
变更文件或目录的所有者(单词:change the owner of file)
命令格式:chown 用户 文件或目录
-
chgrp
变更文件或目录的所有者
命令格式:chgrp 用户 组名
文件搜索命令
-
which
查看命令所在路径
命令格式:which 命令
-
find
借助搜索关键字(文件名、文件大小、文件所有者等)查找文件或目录
命令格式:find 搜索路径 [选项] 搜索关键字
选项 说明 -name 根据文件名查找 -size 根据文件大小查找 -user 根据文件所有者查找 -
locate
借助搜索关键字查找文件或目录
命令格式:locate [选项] 搜索关键字
locate与find的区别:
- locate速度远胜find
- find搜索整个目录,locate搜索数据库/var/lib/locatedb,即便文件存在,数据库中没有记录,locate也搜索不到
-
grep
在文件中搜索与字符串匹配的行并输出
命令格式:grep 指定字符 源文件
网络管理与通信命令
-
ifconfig
配置和显示Linux内核中网络接口参数(单词:interfaces config)
命令格式:ifconfig [参数]
-
netstat
打印Linux系统中网络系统的状态信息
命令格式:netstat [选项]
选项 说明 -a 显示所有端口 -at 列出所有tcp端口 -au 列出所有udp端口 -
ping
测试主机之间网络的连通性
命令格式:ping [选项] [参数]
选项 说明 -c 设置回应次数 -s 设置数据包大小 -v 详细显示指令的执行过程 -
write
使当前用户向另一个用户发送信息
命令格式:write 用户名
-
wall
使当前用户向所有用户发送信息
命令格式:wall
压缩解压命令
-
zip/unzip
压缩文件,获得.zip格式的压缩包,压缩后保存源文件
命令格式: zip [-r] [压缩后文件名称] 文件或目录
unzip [选项] 压缩包包名
-
gzip/gunzip
压缩文件,获得.gz格式的压缩包,压缩后不保存源文件,若同时列出多个文件,则每个文件会被单独压缩。
命令格式: gzip [选项] 文件
gunzip [选项] 压缩包包名
-
bzip2/bunzip2
压缩文件,获得.bz2格式的压缩包,使用选项-k时保留源文件
命令格式: bzip2 [选项] 文件或目录
bunzip2 [选项] 压缩包包名
-
tar
打包多个目录或文件,通常与压缩命令一起使用
命令格式:tar [选项] 目录
选项 说明 -c 产生.tar打包文件 -v 打包时显示详细信息 -f 指定压缩后的文件名 -z 打包,同时通过gzip指令压缩备份文件,压缩后格式为.tar.gz -x 从打包文件中还原文件。
帮助命令
-
man
获取Linux系统的帮助文档——manpage中的帮助信息
命令格式:man [选项] 命令/配置文件
选项 说明 -a 在所有的man帮助手册中搜索 -p 指定内容时,使用分页程序 -M 指定man手册搜索的路径 -
info
获取Linux系统的帮助文档——manpage中的帮助信息
命令格式:man [选项] 命令/配置文件
选项 说明 -a 在所有的man帮助手册中搜索 -p 指定内容时,使用分页程序 -M 指定man手册搜索的路径 -
whatis
用于查询命令的功能, 并将查询结果打印到终端
命令格式:whatis 命令
-
whoami
用于打印当前有效的用户名称
命令格式:whoami
Linux常用工具
Vi编辑器是Linux系统下最基本的编辑器,工作在字符模式下,工作模式分为命令模式、插入模式和底行模式。
GCC编译器是由GUN开发的编程语言编译器,现已可编译C语言、Java、OC等多种编程语言。
GDB调试工具是Linux系统中使用的一种非常强大的调试工具。
vi/vim(重点)
编辑器用于在Linux环境下编写程序。Vi编辑器的工作模式分为三种:命令模式、插入模式和底行模式,这三种模式之间可以进行转换。
命令模式
命令模式下,可通过键盘控制光标的移动,实现文本内容的复制、粘贴、删除等操作。光标的移动可分为6个级别,分别为:字符级、行级、单词级、段落级、屏幕级和文档级。
光标移动有关操作:
| 操作符 | 说明 |
|---|---|
| “左键”或字母“h” | 使光标向字符的左边移动 |
| “右键”或字母“l” | 使光标向字符的右边移动 |
| “上键”或字母“k” | 使光标移动到上一行 |
| “下键”或字母“j” | 使光标移动到下一行 |
| 符号“$” | 使光标移动到当前行尾 |
| 数字“0” | 使光标移动到当前行首 |
| 字母“w” | 使光标移动到下一个单词的首字母 |
| 字母“e” | 使光标移动到本单词的尾字母 |
| 字母“b” | 使光标移动到本单词的首字母 |
| 符号“}” | 使光标移至段落结尾 |
| 符号“{” | 使光标移至段落开头 |
| 字母“H” | 使光标移至屏幕首部 |
| 字母“L” | 使光标移至屏幕尾部 |
| 字母“G” | 使光标移至文档尾行 |
| n+G | 使光标移至文档的第n行 |
删除有关操作:
| 操作符 | 说明 |
|---|---|
| 字母“x” | 删除光标所在的单个字符 |
| 字母“dd” | 删除光标所在的当前行 |
| n+dd | 删除包括光标所在行的后边n行内容 |
| d+$ | 删除光标位置到行尾的所有内容 |
复制和粘贴有关操作:
| 操作符 | 说明 |
|---|---|
| 字母“yy” | 复制光标当前所在行 |
| n+yy | 复制包括光标所在行后的n行内容 |
| y+e | 从光标所在位置开始复制直到当前单词结尾 |
| y+$ | 从光标所在位置开始复制直到当前行结尾 |
| y+{ | 从当前段落开始的位置复制到光标所在位置 |
| p | 将复制的内容粘贴到光标所在位置 |
插入模式
插入模式下,用户可对文件内容进行修改操作,此模式下的操作与Windows操作系统中记事本的操作类似。
底行模式
底行模式下可以对文件进行保存,也可进行查找、设置、退出编辑器等操作。
底行模式下常用的操作:
-
set nu。设置行号,仅对本次操作有效,当重新打开文本时,若需要行号,要重新设置。
-
set nonu。取消行号,仅对本次操作有效。
-
n。使光标移动到第n行。
-
/xx。在文件中查找“xx”,若查找结果不为空,可以使用“n”查找下一个,使用“N”查找上一个。
-
内容替换,其操作符和功能如表所示。
操作符 说明 : s/被替换内容/替换内容/ 替换光标所在行的第一个目标 : s/被替换内容/替换内容/g 替换光标所在行的全部目标 : %s/被替换内容/替换内容/g 替换整个文档中的全部目标 : %s/被替换内容/替换内容/gc 替换整个文档中的全部目标,且每替换一个内容都有相应的提示 -
保存和退出,其操作符和功能如表所示。
操作符 说明 :q 退出vi编辑器 :w 保存编辑后的内容 :wq 保存并退出vi编辑器 :q! 强行退出vi编辑器,不保存对文件的修改 :w! 对于没有修改权限的用户强行保存对文件的修改,并且修改后文件的所有者和所属组都有相应的变化 :wq! 强行保存文件并退出vi编辑器
模式转换
命令模式下:按i或者o进入插入模式;按:或/进入底行模式。
插入模式下:按esc进入命令模式。
底行模式下:可以和命令模式自动切换。
命令模式切换至插入模式的快捷方式:
| 操作符 | 说明 |
|---|---|
| 字母“a” | 光标向后移动一位进入编辑模式 |
| 字母“s” | 删除光标所在字母进入编辑模式 |
| 字母“o” | 在当前行之下新起一行进入编辑模式 |
| 字母“A” | 光标移动到当前行末尾进入编辑模式 |
| 字母“I” | 光标移动到当前行行首进入编辑模式 |
| 字母“S” | 删除光标所在行进入编辑模式 |
| 字母“O” | 在当前行之上新起一行进入编辑模式 |
配置vi编辑器
对用户家目录中的.vimrc文件进行编辑,常用的编辑如下表:
| 设置 | 说明 |
|---|---|
| set number | 设置行号 |
| set autoindent | 自动对齐 |
| set smartindent | 智能对齐 |
| set showmatch | 括号匹配 |
| set tabstop=4 | 使用tab键时为4个空格 |
| set mouse=a | 鼠标支持 |
| set cindent | 使用C语言格式对齐 |
gcc编译器
gcc编译过程分为四个步骤,分别是预处理、编译、汇编和链接。
gcc的编译流程:
-
在编译阶段,GCC会对经过预处理的文件进行语法、词法和语义分析,确定代码实际要做的工作,若检查无误,则生成相应的汇编代码文件。
-
汇编过程将编译后生成的汇编代码转换为机器可以执行的命令,即二进制指令,每一个汇编语句几乎都会对应一条机器指令。
-
链接过程是组装各个目标文件的过程,在这个过程中会解决符号依赖和库依赖关系,最终生成可执行文件。
命令格式:gcc [选项] 参数
| 选项 | 说明 |
|---|---|
| -o | 指定生成的输出文件 |
| -E | 仅执行编译预处理 |
| -S | 将C代码转换为汇编代码 |
| -wall | 显示警告信息 |
| -c | 仅执行编译操作,不进行连接操作 |
gdb调试工具
GDB可以逐条执行程序、操控程序的运行,并且随时可以查看程序中所有的内部状态,如各变量的值、传给函数的参数、当前执行的语句位置等,借此判断代码中的逻辑错误。
使用方法:
-
在代码中加入调试信息,并调试程序
$ gcc gdbtest.c –o app –g (gdb) gdb app -
列出程序代码,并设置断点
list 行号 b 行号 b 22 if i = 5 #在22行设定带条件的断点 info b #查看断点 disable Num #取消断点 -
查看变量名
p 变量名 -
继续执行
s —— 单步执行 n —— 单步执行且跳过标准函数库 finish —— 跳出当前函数 -
结束调试
continue —— 结束当前断点调试 quit —— 退出调试
用户与用户组管理
Linux操作系统中设立了用户和用户组的概念,在使用系统资源时必须有身份,因此用户需要先向系统管理员申请一个账号。Linux允许多个用户同时登陆操作系统,针对系统中的多名用户,Linux还设计了用户组的概念,为用户指定用户组,可以在需要时方便地对多个用户进行管理。
用户相关
用户添加:useradd [选项] 用户名
| 选项 | 说明 |
|---|---|
| -d | 指定用户登入时的目录 |
| -c | 指定账户的备注文字 |
| -e | 指定账号的有效期限 |
| -f | 缓冲天数,密码过期时在指定天数后关闭该账号 |
| -g | 指定用户所属组 |
| -G | 指定用户所属的附加用户组 |
| -m | 自动建立用户的登入目录 |
| -r | 创建系统账号 |
| -s | 指定用户的登陆shell |
| -u | 指定用户的用户ID。若添加-o选项,则用户ID可与其它用户重复 |
设置用户密码:passwd [选项] 用户名
| 选项 | 说明 |
|---|---|
| -l | 锁定密码,锁定后密码失效,无法登陆(新用户默认锁定) |
| -d | 删除密码,仅系统管理员可使用 |
| -S | 列出密码相关信息,仅系统管理员可使用 |
| -f | 强行执行 |
说明:
- root用户可随意修改密码,即便出现警告,也可成功保存。
- 普通用户在设置密码时应尽量复杂,避免与用户名相同。
- 修改当前登陆账户的密码时,可缺省用户名。
- 用户密码保存在/etc/shadow文件中。
- 使用tail命令查看/etc/shadow文件,确认为账户kdy设置的密码。
删除用户:userdel [选项] 用户名
| 选项 | 说明 |
|---|---|
| -f | 强制删除用户,即便该用户为当前用户 |
| -r | 删除用户的同时,删除与用户相关的所有文件 |
修改用户账号:usermod [选项] 用户名
| 选项 | 说明 |
|---|---|
| -c | 修改用户账号的备注信息 |
| -d | 修改用户的登入目录 |
| -e | 修改账号的有效期限 |
| -f | 修改缓冲天数,即修改密码过期后关闭账号的时间 |
| -g | 修改用户所属组 |
| -l | 修改用户账号名称 |
| -L | 锁定用户密码,使密码失效 |
| -s | 修改用户登陆后使用的shell |
| -u | 修改用户ID |
| -U | 解除密码锁定 |
用户切换:su [选项] username
| 参数 | 说明 |
|---|---|
| -c | 执行完指定的指令后,切换回原来的用户 |
| -l | 切换用户的同时,切换到对应用户的工作目录,环境变量也会随之改变 |
| -m,-p | 切换用户时,不改变环境变量 |
| -s | 指定要执行的shell |
说明:
- 使用su命令切换用户时,需要输入的是目标用户的密码。
- 选项与用户名缺省的情况下,只切换用户,但不改变用户环境。
- 由root用户切换到其它用户,可以不输入密码。
- 在命令行输入“exit”或“su -user”,可退出目标用户。
用户切换:sudo [选项] –u 用户 [命令]
| 选项 | 说明 |
|---|---|
| -b | 在后台执行命令 |
| -h | 显示帮助 |
| -H | 将HOME环境变量设置为新身份的HOME环境变量 |
| -k | 结束密码的有效期限 |
| -l | 列出目前用户可执行与无法执行的命令 |
| -p | 改变询问密码的提示符号 |
| -s | 执行指定的shell |
| -u | 以指定的用户作为新的身份,即切换到指定用户。默认切换到root用户 |
说明:
sudo命令可以视为受限的su,它可以使“部分”用户使用其它用户的身份执行命令。
在使用sudo命令之前,需要通过修改/etc/sudoers文件,为当前用户配置要使用的权限。
/etc/sudoers文件有一定的语法规范,为避免因修改后出现语法错误,应使用visudo命令打开文件进行修改。
如下所示为/etc/sudoers文件中的一条配置信息,该信息设置了root用户可能任何情境下执行任何命令。
root ALL=(ALL) ALL
用户组相关
添加用户组:groupadd [选项] 用户名
| 选项 | 说明 |
|---|---|
| -g | 指定新建用户组的组ID |
| -r | 创建系统用户组,组ID取值范围为1~499 |
| -o | 允许创建组ID已存在的用户组 |
删除用户组:groupdel 参数
切换用户组:newgrp 用户组名
shell编程(重点)
Shell既是一种命令语言,又是一种程序设计语言(即Shell脚本)。作为一种基于命令的语言,Shell交互式地解释和执行用户输入的命令;作为程序设计语言,Shell中可以定义变量、传递参数,并提供了许多高级语言所有的流程控制结构。
Shell最重要的功能是命令解释器,Linux系统中的所有可执行文件都可以在shell中执行。
Linux系统中的可执行文件可以分为五类:
-
Linux命令:用来使系统执行某种操作的指令,存放在/bin和/sbin目录下;
-
内置命令:存放于Shell内部的命令的解释程序,是一些常用的命令。可以使用“type 命令名”的方式来查看某个命令是否为内置命令;
-
实用程序:存放于/usr/bin、/usr/sbin、/usr/local/bin等目录下的程序,如ls、which等;
-
用户程序:由用户编写的,经过编译后可执行的文件;
-
Shell脚本:使用Shell语言编写的批处理文件。
输入输出重定向
Linux系统中将从终端输入数据称为标准输入,将打印数据到终端称为标准输出,并设置了3个标准文件,分别关联标准输入、标准输出以及标准错误输出信息,标准输入文件的编号为0,默认设备是键盘;标准输出文件的编号为1,默认设备是显示器;标准错误文件的编号为2,默认设备也是显示器。
Shell默认从终端接收用户命令,并将命令执行过程中产生的错误与命令的执行结果打印到终端,但并非任何时候用户都希望使用默认设置,这种情况下,可使用重定向,更改命令获取与信息输出的方向。
所谓重定向,即使用用户指定的文件而非默认资源(键盘、显示器)来获取或接收文件。
重定向可分为三种:
-
输入重定向
-
输出重定向
-
错误重定向
输入重定向
实现输入重定向的运算符为“<”,具体格式如下:
命令:<文件名
示例:wall<file
输出重定向
实现输出重定向的运算符为“>”,具体格式如下:
命令:>文件名
示例:cat /etc/passwd > file
使用>运算符时,输出的信息将以覆盖的方式打印到文件file中,若想保留文件file中原有的内容,可使用运算符“>>”,该运算符将以追加的形式将结果打印到file文件。
错误重定向
重定向标准错误信息使用运算符“>”和“>>”,其格式如下:
命令:2>文件名
说明:
其中“2”代表标准错误文件的编号,实际上,输入重定向和输出重定向还可写为如下格式:
命令 0<文件名
命令 1>文件名
只是当其文件编号0、1出现在重定向符号左侧时,可以被省略。
可以使用运算符“&”通过文件编号引用文件,该运算符表示“等同于”,如“2>&1”则表示将标准错误重定向到标准输出中。
管道
在shell编程中,“|”被称为管道符号,用于连接两个命令,其格式如下:
命令1 | 命令2 | … | 命令n
管道可使前一个命令的输出作为后一个命令的输入,由此实现较为复杂的功能。
示例:ls –l /etc | grep init
命令连接符
使用“;”运算符间隔的命令,会按照先后次序依次执行。
使用“&&”连接符连接的命令,其前后命令的执行遵循逻辑与关系,只有该连接符之前的命令执行成功后,它后面的命令才被执行。
使用“||”连接符链接的命令,其前后命令的执行遵循逻辑或关系,只有该连接符之前的命令执行失败时,才会执行后面的命令。
文本提取器
awk [-F分隔符1] ‘{print $1 [“分隔符2”] $2}’
说明:
-F选项用于指定分隔符,若缺省则以空格分割;分隔符2用于设置打印提取项时使用的分隔符
示例:awk –F: ‘{print $1 “ ”$3}’ /etc/passwd cat /etc/passwd | awk -F: ‘{print $1 “ ”$3}’
变量
变量的定义
变量定义规则:
- Shell中的变量在使用之前无需定义,可以在使用的同时创建。
- Shell中的变量没有明确的分类,一般情况下,一个变量保存一个串。
- Shell中的变量若要进行计算,需使用工具程序进行转换。
- Shell变量的变量名由字母、数字和下划线组成,开头只能是字母或下划线。
- 若shell变量中出现其它字符,则表示变量名到此前为止。
- 给变量赋值时,等号两端不能有空格,其格式为“变量名=值”,若要给变量赋空值,缺省格式中“值”的部分,跟上换行符即可。
- 若变量中含有空格,必须使用引号将变量括起。
- Shell中可以使用关键字“readonly”将变量设置为只读变量。
变量的引用
Shell中通过“$”符号来引用变量,用于区分变量与普通字符串,若要输出已定义的变量,其格式如下:
echo $var
其中echo类似于C语言中的printf()函数,用于实现变量或字符串的打印功能。
需要说明的是,在使用echo打印变量时,单引号与双引号的效果略有差异,使用单引号引起的 v a r 会 打 印 该 字 符 串 “ var会打印该字符串“ var会打印该字符串“var”,而使用双引号引起的$var则打印变量var中存储的值。
变量的输入
Shell脚本中可以使用read命令从终端读取信息,该命令的功能类似于C语言中的scanf()函数,其格式如下:
read 变量名
当脚本执行到read语句时,终端会阻塞等待用户输入,并将用户输入的数据赋给read语句中的变量。
变量的分类
-
环境变量
环境变量又称永久变量,此类变量不仅可以作用于单个脚本,还可用于创建该变量的Shell以及从该Shell派生的子Shell或进程中。
环境变量使用”export”关键字设定或创建,若要将一个本地变量更改为环境变量,可使用以下方法:
export 变量名
若要创建一个环境变量,则使用以下格式:
export 变量名=值
-
位置变量
位置变量即执行脚本时传入脚本中,对应位置的变量,类似函数的参数,引用方法为“$”加上参数的位置,如:$0、$1、$2,其中$0比较特殊,表示脚本的命令,其余依次表示传入脚本中第一个参数、第二个参数等。使用shift可以移动位置变量对应的参数,shift每执行一次,参数序列顺序左移一个位置,移出去的参数不可再用。
-
标准变量
标准变量也是环境变量,在bash环境建立时生成,该变量自动解析,通过查看etc目录下的profile文件可以查看系统中的标准环境变量;使用env命令可以查看系统中的环境变量,包括环境变量和标准变量。
-
特殊变量
Shell中定义了一些特殊的变量,这些变量及含义分别如下:
-
#。传递到脚本或函数的参数数量。
-
?。上个命令执行情况,0表示成功,其它值表示失败。
-
$。运行脚本的进程id。
-
*。传递给脚本或函数的所有参数。
-
变量的运算
-
let
let命令可以进行算术运算和数值表达式测试,let命令的使用格式如下:
let 表达式
echo “i=“$i
示例:
i=1 echo "i=“$i let i=i+2 echo "i="$i let "i=i+4" echo "i="$i执行结果:
i= 1 i= 3 i= 7let命令也可以使用如下形式代替:((算术表达式))
示例:((i+=3))
-
expr
Expr命令可以对整型变量进行算术运算,使用expr命令时可以使两个数值直接进行运算,例如进行加法运算“3+5”,则在命令行直接输入以下语句:
expr 3 + 5
运算的结果会直接在命令行输出。
若要通过变量的引用进行运算,添加“$”即可。
说明:
- 若表达式中是遍历,使用“$”引用即可。
- 运算符与变量或数据之间需要有一个空格。
- 若要在脚本中使用expr命令,需要使用符号“`”(该按键一般位于Tab键之上)将其内嵌到等式当中。
条件判断
test命令的语法格式如下:
test 选项 参数
若要检测某个文件是否存在,可使用如下语句进行判断:
if test –f file
在此段代码中,条件语句会根据test命令的退出码来决定是否执行。
-
字符串比较
条件 说明 str1=str2 若字符串str1等于str2,则结果为真 str1!=str2 若字符串str1不等于str2,则结果为真 –n str 若字符串str不为空,则结果为真 –z str 若字符串str为空,则结果为真 -
算术比较
条件 说明 expr1 –eq expr2 若表达式expr1与expr2返回值相同,则结果为真 expr1 –ne expr2 若表达式expr1与expr2返回值不同,则结果为真 expr1 –gt expr2 若表达式expr1返回值大于expr2返回值,则结果为真 expr1 –ge expr2 若表达式expr1返回值大于等于expr2返回值,则结果为真 expr1 –lt expr2 若表达式expr1返回值小于expr2返回值,则结果为真 expr1 –le expr2 若表达式expr1返回值小于等于expr2返回值,则结果为真 !expr 若表达式结果为假,则结果为真 -
文件测试
条件 说明 -d file 若文件file是目录,则结果为真 -f file 若文件file是普通文件,则结果为真 -r file 若文件file可读,则结果为真 -w file 若文件file可写,则结果为真 -x file 若文件file可执行,则结果为真 -s file 若文件file大小不为0,则结果为真 -a file 若文件file存在,则结果为真
if条件语句
-
单分支if语句
示例: #!/bin/sh #单分支if语句 read filename if [ -d $filename ];then echo $filename" is a directory" fi exit 0 执行脚本,输出结果如下: Videos Videos is a directory -
双分支if语句
示例: #!/bin/sh #双分支if语句 read filename if [ -d $filename ];then echo $filename" is a directory" else echo $filename" is't a directory" fi exit 0 执行脚本,输出结果如下: hello hello is't a directory -
多分枝if语句
示例: #!/bin/sh read filename if [ -d $filename ];then ls $filename elif [ -x $filename ];then echo "This is a executable file." else echo "This is not a executable file." fi exit 0
select语句
Shell中select语句可以将选项列表做出类似目录的形式,以交互的形式选择列表中的数据,传入select语句中的主体部分加以执行。
select语句实质上也是一个循环语句,若不添加break关键字,程序将无法跳出select结构。
示例:
#!/bin/sh
#select条件语句
echo "What do you want to study?"
select subject in "Android" "Java" "C++" "IOS"
do
echo "You have selected $subject."
break
done
exit 0
执行脚本,输出结果如下:
What do you want to study?
1) Android
2) Java
3) C++
4) IOS
#? 3 #选择选项3
You have selected C++. #输出结果
case语句
case语句可以将一个变量的内容与多个选项进行匹配,若匹配成功,则执行该条件下对应的语句。
示例1:
#!/bin/sh
echo -e "a:\c"
read a
echo -e "b:\c"
read b
echo -e "select(+ - * /):\c"
read var
case $var in
'+') echo "a+b="`expr $a "+" $b`;;
"-") echo "a-b="`expr $a "-" $b`;;
"*") echo "a*b="`expr $a "*" $b`;;
"/") echo "a/b="`expr $a "/" $b`;;
*) echo "error"
esac
exit 0
示例2:
#!/bin/sh
read var
case $var in
yes | y |Y) echo "true";;
no | n | N) echo "flase";;
*) echo "input error"
esac
exit 0
循环语句
for循环
示例1:
#!/bin/sh
for month in Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
do
echo -e "$month\t\c"
done
echo
exit 0
执行脚本,输出结果如下:
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
需要注意的是,变量列表中的每个变量可以使用引号单独引起,但是不能将整个列表置于一对引号中,因为使用一对引号引起的值,会被视为一个变量。
示例2:
示例:
#!/bin/sh
for file in ~/itheima/*.bxg
do
rm $file
echo "$file has been deleted."
done
exit 0
其中*表示通配符,*.bxg表示文件名以.bxg结尾的文件。
执行该脚本,执行结果如下:
/home/itheima/itheima/11.bxg has been deleted.
/home/itheima/itheima/22.bxg has been deleted.
/home/itheima/itheima/33.bxg has been deleted.
其中变量是在当前循环中使用的一个对象,用来接收变量列表中的元素;变量列表是整个循环要操作的对象的集合,可以是字符串集合或文件名、参数等等,变量列表的值会被逐个赋给变量。
while循环
在while循环中,当表达式的值为假时,停止循环,否则循环将一直进行。此处表达式外的“[]”表示的是[命令,而非语法格式中的中括号,不能省略。
示例:
#!/bin/sh
count=1
sum=0
while [ $count -le 100 ]
do
sum=`expr $sum + $count`
count=`expr $count + 1`
done
echo "sum=$sum"
exit 0
执行该脚本,输出的结果如下:
sum=5050
until循环
示例:
#!/bin/sh
#until
i=1
until [ $i -gt 3 ]
do
echo "the number is $i."
i=`expr $i + 1`
done
exit 0
执行该脚本,输出的结果如下:
the number is 1.
the number is 2.
the number is 3.
shell脚本调试
Shell编程中可以通过Shell提供的一些选项,对脚本文件进行调试,其中常用的调试选项有:-n、-v、-x,这些选项的功能分别如下:
- -n。不执行脚本,仅检查脚本中的语法问题;
- -v。在执行脚本的过程中,将执行过的脚本命令打印到屏幕;
- -x。将用到的脚本内容打印到屏幕上。
shell中的函数
shell中函数的格式如下:
[function] 函数名[()]{
代码段
[return int]
}
说明:
- function关键字可以省略
- 函数名后的()可以省略,若省略,函数名与{之间需有一个空格
- return语句可以省略,若无return语句,函数返回代码段中最后一条命令的执行结果
示例:
#!/bin/sh
#function hello
function hello(){
echo "hello itheima."
}
#main
hello #hello函数调用
exit 0
Shell编程中可通过位置变量向脚本中传递参数,Shell脚本的函数没有参数列表,但亦可通过环境变量向其中传递参数。函数中的位置变量不与脚本中的位置变量冲突,函数中的位置变量在函数调用处传入,脚本中的位置变量在脚本执行时传入。
示例:
#!/bin/sh
function fun(){
a=10
echo "fun:a=$a"
}
a=5
echo "main:a=$a"
fun #函数调用
echo "main:a=$a"
exit 0
执行该脚本,脚本的执行结果如下:
main:a=5
fun:a=10
main:a=10
Shell脚本中可以通过“local”关键字来定义一个仅作用于函数的局部变量。
示例:
#!/bin/sh
function fun(){
local a=10
echo "fun:a=$a"
}
a=5
echo "main:a=$a"
fun #函数调用
echo "main:a=$a"
exit 0
执行此脚本代码,脚本的执行结果如下:
main:a=5
fun:a=10
main:a=5
文件系统与操作
磁盘是计算机中的主要存储设备,一般由主轴、盘片和读写磁头组成。
磁盘中包含多张盘片,每张盘片包含上下两个盘面,盘片固定在磁盘的主轴上,盘片的每个盘面都有一个固定在动臂上的读写磁头;计算机中的数据存储在磁盘的盘面上,盘片随主轴的旋转而转动,固定在动臂上的读写磁头在盘片转动的同时,读取盘面上存储的信息。
磁盘的盘片又可细分,每张盘片上有许多磁道,多张盘片上半径相同的磁道组成的圆柱面称为柱面,一张盘片有多少磁道,磁盘就有多少柱面。磁道是读写磁头读写的轨迹,读写磁头可以在动臂的带动下切换访问的柱面。
磁盘上的盘片被细分为多个大小相同的扇区,扇区是磁盘空间的基本单位,一般来说,一个扇区的大小为512字节。
磁盘中第一个扇区非常重要,其中存储了与磁盘正常使用相关的重要信息,分别为:主引导记录、磁盘分区表和魔数。
主引导记录(Master Boot Record)占用446字节,其中包含一段被称为引导加载流程(Boot Loader)的程序,计算机启动后,会到磁盘0扇面的0扇区去读取MBR中的内容,只有MBR中的程序正确无误,计算机才能正常开机。
磁盘分区表(partition table)占用64个字节,其中记录整块磁盘的分区状态,每个分区的信息需要16个字节,因此磁盘分区表若只记录分区信息,便最多只能存储4个分区的分区信息。
魔数(Magic Number)占用2个字节,用来标识MBR是否有效。
Linux系统中遵循“一切皆文件”的思想,Linux下的设备也会被视为文件,硬盘作为设备的一种,其对应的文件被存储于系统的/dev目录下。若磁盘为SATA类型,则磁盘路径名为/dev/sda,四个分区在/dev目录下对应的文件名如下所示:
P1:/dev/sda1
P2:/dev/sda2
P3:/dev/sda3
P4:/dev/sda4
目录
登录系统后,在当前命令窗口下输入命令:
ls /
树状目录结构:(Linux的一切资源都挂载在这个 / 根节点下)
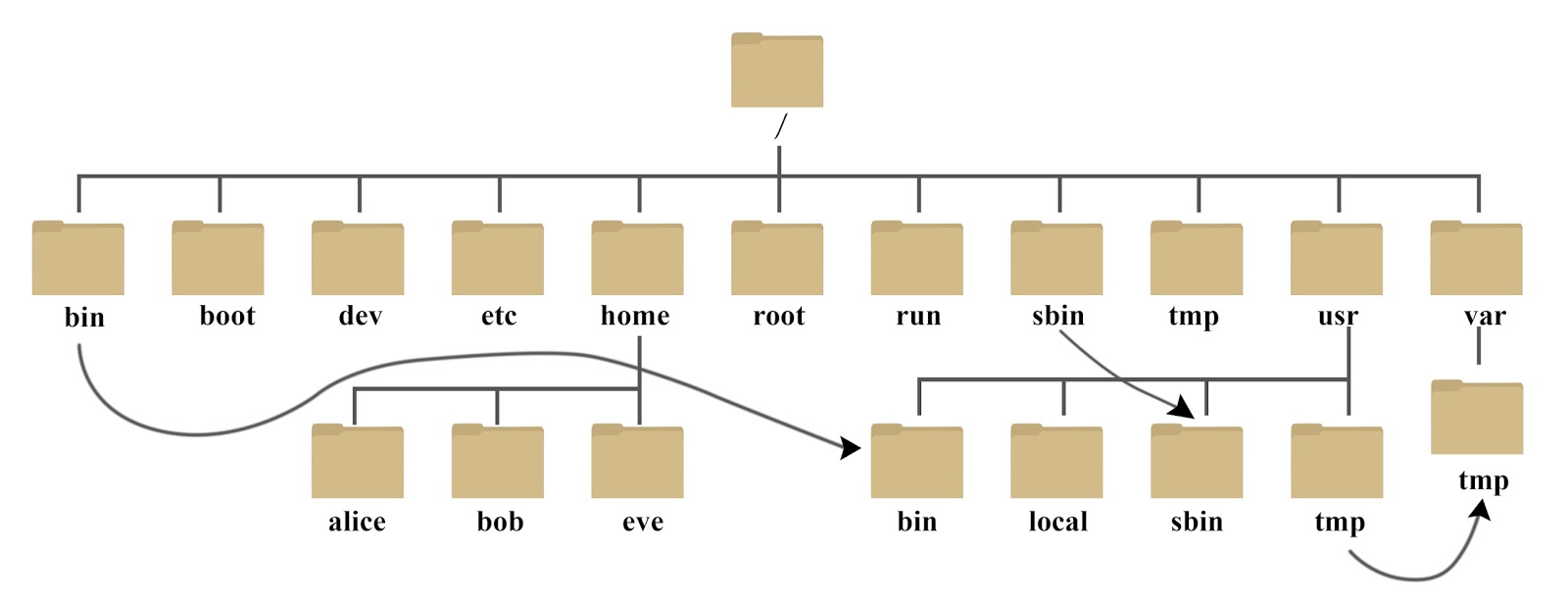
以下是对这些目录的解释:
- /:根目录,只包含目录,不包含具体文件;
- /bin:存放可执行的文件,如常用命令ls、mkdir、rm等,都以二进制文件的形式存放在该目录中;
- /dev:存放设备文件,包括块设备文件(如磁盘对应文件)、字符设备文件(如键盘对应文件)等;
- /root:超级用户,即管理员的工作目录;
- /home:普通用户的工作目录,每个用户都有一个/home目录;
- /lib:主要存放动态链接共享库文件,类似于Windows中的.dll文件,该目录中的文件一般以.a、.dll、.so结尾(后缀不代表文件类型);也会存放与内核模块相关的文件;
- /boot:存放操作系统启动时需要用到的文件,如内核文件、引导程序文件等;
- /etc:主要包含系统管理文件和配置文件;
- /mnt:存储挂载存储设备的挂载目录;
- /proc:存放系统内存的映射,可直接通过访问该目录来获取系统信息;
- /opt:存放附加的应用程序软件包;
- /tmp:存放临时文件,重启系统后该目录的文件不会被保存;每个用户都能创建该目录,但不能删除其它用户的/tmp目录;
- /swap:存放虚拟内存交换时所用文件;
- /usr:包含所有的用户程序(/usr/bin)、库文件(/usr/lib)、文档(/usr/share/doc)等,是占用空间最大的目录。
inode与dentry
Linux系统中将文件的属性与数据分开存储,文件中的数据存放的区域称为数据区,文件属性又被称为元数据,存放文件属性的区域称为元数据区,基于这种文件存储方式,Linux文件系统中定义了两个与文件相关的、至关重要的概念:索引结点和目录项。
inode
索引结点(index node,简称inode)的实质是一个结构体,主要功能是保存文件的属性信息(如所有者、所属区、权限、文件大小、时间戳等),Linux系统中的每个文件都会被分配一个inode,当有文件创建时,系统会在inode表中获取一个空闲的inode,分配给这个文件。inode存储在inode表中,inode表存储inode和inode的编号(inumber),inode表在文件系统创建之时便被创建,因此文件系统中可存储的文件数量也在文件系统创建时已确定。
dentry
Linux文件系统中的索引结点保存着文件的诸多属性信息,但并未保存文件的文件名。实际上,Linux系统中文件的文件名并不保存在文件中,而是保存在存放该文件的目录中。
Linux系统中定义了一个被称为目录项(dentry)的结构体,该结构体主要存储文件的文件名与inode编号,系统通过读取目录项中的文件名和文件的inumber,来判断文件是否存在于这个目录中。dentry中允许同一个inode对应不同的文件名,但不允许相同的文件名对应不同的inode。
fdisk/mkf2es
Linux系统中提供了fdisk命令和mkf2es命令,分别用于创建、管理磁盘分区,和创建文件系统。
fdisk
fdisk命令可以查看当前系统中的磁盘,以及磁盘中的分区情况,也可以用于磁盘分区。
命令格式:fdisk [选项] [参数]
常用的选项为-l,该选项可以列出指定设备的分区表状况
| 按键 | 说明 |
|---|---|
| p | 打印分区信息 |
| n | 创建一个新的分区 |
| d | 删除一个分区 |
| w | 将分区信息写入分区表,保存并退出 |
| q | 退出但不保存 |
mkf2es
mkf2es命令可为磁盘分区创建ext2、ext3文件系统。
命令格式:fdisk [选项] [参数]
Mkfs命令亦可为磁盘分区创建系统,其常用选项为-t,参数一般为文件系统类型。
| 选项 | 说明 |
|---|---|
| -b<区块大小> | 指定区块大小,单位为字节 |
| -c | 检查是否有损坏的区块 |
| -f<不连续区段大小> | 指定不连续区段的大小,单位为字节 |
| -F | 忽视设备,强制执行mke2fs |
| -N | 指定inode的数目 |
| -S | 仅写入superblock与GDT |
df
df命令用于查看与磁盘空间相关的信息。
命令格式:df [选项] [参数]
df的参数可以是文件,但打印的信息会是该文件所在文件系统磁盘的使用情况。
du
du即disk usage,意为磁盘使用情况,该命令可以计算文件或目录占用的磁盘空间。
命令格式:du [选项] [参数]
du的参数一般为目录或文件,选项可以对显示信息进行控制。当选项与参数都缺省时,该命令会逐级进入当前工作目录与其所有子目录,检测目录占用的磁盘块数,并在最后显示工作目录占用的总块数。
| 选项 | 说明 |
|---|---|
| -a | 显示所有目录以及目录中每个文件所占用的磁盘空间 |
| -s | 只显示目录及文件占用磁盘块的总和 |
| -b/-k/-m/-g | 以b/kb/mb/Gb为单位,显示目标占用磁盘块的总和 |
| -x | 以最初处理时的文件系统为准,跳过不同文件系统上的文件 |
| -D | 显示指定符号链接的源文件大小 |
ext2/ext3文件系统
ext2文件系统
如图所示,为磁盘分区格式化为ext2文件系统后的结构布局。

图中磁盘分区的第一个部分为启动块(Boot Block),启动块占用一个块空间,用来存储磁盘的分区信息和启动信息。图5-5中启动块之后是多个块组,每个块组中包含6部分,即:超级块(Super Block)、块组描述符(GDT)、块位图(Block Bitmap)、位图(Inode Bitmap)、位表(Inode Table)、数据块(Data Blocks)。
ext2文件系统的结构有以下几个优点:
- 可有效防止磁盘碎片的产生,减少磁盘传送次数,降低系统消耗
- 管理员可根据给定分区的大小,预计分区中存放的文件数,从而确定分区中inode的数量,保证磁盘空间利用率
- 降低对存放于一个单独块组中的文件并行访问时磁盘的平均寻道时间
- 支持快速符号链接
ext3文件系统
ext3是一个完全兼容ext2文件系统的日志文件系统,它在ext2的基础上,添加了一个被称为日志的块,专门来记录写入或修订文件时的步骤。
日志文件系统可以按照不同的方式进行工作,ext3中可通过对/etc/fstab文件中的data属性进行设置来修改文件系统的工作模式。日志文件系统的工作模式分为三种,其设置方式分别如下:
data=journal
data=ordered
data=writeback
数据块寻址
Linux文件系统中文件的属性信息和数据分开存放,系统通过文件inode中的索引项Block来查找文件数据。Block索引项是一个数组,包含15个索引项,其中:
Block[0]~Block[11]是直接索引项;
Block[12]为间接索引项;
Block[13]为二级间接索引项;
Block[14]为三级间接索引项。

虚拟文件系统
虚拟文件系统又称虚拟文件切换系统(Virtual Filesystem Switch),是操作系统中文件系统的虚拟层,其下才是具体的文件系统。虚拟文件系统的主要功能,是实现多种文件系统操作接口的统一,既能让上层的调用者使用同一套接口与底层的各种文件系统交互,又能对文件系统提供一个标准接口,使Linux系统能同时支持多种文件系统。虚拟文件系统与上层应用以及底层的各种文件系统之间的关系如图所示。

挂载
所谓挂载,是指将一个目录作为入口,将磁盘分区中的数据放置在以该目录为根结点的目录关系树中,这相当于为文件系统与磁盘进行了链接,指定了某个分区中文件系统访问的位置。
Linux系统中根目录是整个磁盘访问的基点,因此根目录必须要挂载到某个分区。
Linux系统中通过mount命令和unmount命令实现分区的挂载和卸除。
mount
Linux系统中可以使用mount命令将某个分区挂载到目录
mount命令常用的格式如下:mount [选项] [参数] 设备 挂载点
mount命令常用的选项有两个,分别为-t和-o。
-t用于指定待挂载设备的文件系统类型,常见的类型如下:
- p光盘/光盘镜像:iso9660;
- pDOS fat16文件系统:msdos;
- pWindows 9x fat32文件系统:vfat;
- pWindows NT ntfs文件系统:ntfs;
- pMount Windows文件网络共享:smbfs;
- pUNIX(LINUX)文件网络共享:nfs。
-o主要用来描述设备的挂载方式,常用的挂载方式如表所示。
| 方式 | 说明 |
|---|---|
| loop | 将一个文件视为硬盘分区挂载到系统 |
| ro | read-only,采用只读的方式挂载设备(即系统只能对设备进行读操作) |
| rw | 采用读写的方式挂载设备 |
| iocharset | 指定访问文件系统所用的字符集 |
| remount | 重新挂载 |
挂载移动硬盘
假设新添设备的设备名为/dev/sdb,其中的逻辑分区为/dev/sdb5,要将该逻辑分区挂载到/mnt/dir1,则需使用如下命令:
mount /dev/sdb5 /mnt/dir1
移动硬盘是一个硬件设备,在挂载之前,需要先将该设备连接到主机。为了确定新连接的设备在系统中的文件名,应先使用“fdisk -l”命令了解当前系统中的磁盘以及分区情况,之后连接移动硬盘,再次执行“fdisk -l”命令,通过比对,从而获得新连接设备的名称与分情况。此时才可以使用mount命令挂载硬盘或其某个分区到指定目录下,需要注意,指定的目录必须已经存在。
挂载镜像文件
镜像文件类似文件压缩包,但它无法直接使用,需先利用虚拟光驱工具将其解压。镜像文件可以视为光盘的“提取物”,它也可以挂载到Linux系统中使用。
假如在/usr目录下有一名为test.iso的镜像文件,要求以读写的方式从源目录/usr/test.iso挂载到目标目录/home/itheima,则需使用如下命令:
mount -o rw –t iso9660 /usr/test.iso /home/itheima
umount
当需要挂载的分区只是一个移动存储设备(如移动硬盘)时,要进行的工作是在该设备与主机之间进行文件传输,那么在文件传输完毕之后,需要卸下该分区。Linux系统中卸下分区的命令是umount。
该命令的格式如下:umount [选项] [参数]
umount命令的参数通常为设备名与挂载点,即它可以通过设备名或挂载点来卸载分区。若以挂载点为参数,假设挂载点目录为/mnt,则使用的命令如下:
umount /mnt
通常以挂载点为参数卸载分区,因为以设备为参数时,可能会因设备正忙或无法响应,导致卸载失败。也可以为命令添加选项“-l”,该选项代表“lazy mount”,使用该选项时,系统会立刻从文件层次结构中卸载指定的设备,但在空闲时才清除文件系统的所有引用。
Linux的文件类型
“ls -l”命令打印的文件属性信息中的第一个字符,便代表文件的类型,该字符有7种取值,分别对应不同的文件:
- d:directory,目录文件;
- l:link,符号链接文件;
- s:socket,套接字文件;
- b:block,块设备文件;
- c:character,字符设备文件;
- p:pile,管道文件;
- -:不属于以上任一种文件的普通文件。
文件描述符
文件描述符(File Descriptor)是一个非负整数,它实质上是一个索引值,存储于由内核维护的该进程打开的文件描述符表中。
系统为每一个进程维护了一个文件描述符表(open file description table),用于存储进程打开文件的文件描述符,进程打开的普通文件其文件描述符从3开始。
存在于进程中的文件描述符是进程级别的,除此之外,内核也对所有打开的文件维护了一个文件描述符表,这是一个系统级的文件描述符表,该表又称打开文件表(open file table),表中的记录被称为打开文件句柄(open file handle)。
一个打开文件句柄中与一个已打开文件相关的信息如下所示:
- 当前文件偏移量;
- 打开文件时所用的状态标识;
- 文件访问模式;
- 与信号驱动相关的设置;
- 对该文件inode对象的引用;
- 文件类型和访问权限;
- 指向该文件所持有的锁列表的指针;
- 文件的各种属性信息。
文件I/O
内核中存在一系列具备预定功能的函数,操作系统将这些函数功能抽象为一组被称为系统调用的接口,提供给应用程序使用,open()、read()、write()、lseek()、close()等都是系统调用中与I/O操作相关的接口。
Linux系统调用中的文件I/O又被称为无缓存I/O,除此之外,在程序编写时我们还可以使用一种有缓存的I/O。有缓存的I/O又被称为标准I/O,是符合ANSI C标准的I/O处理,标准I/O有两个优点,一是执行系统调用read()和write()的次数较少;二是不依赖系统内核,可移植性强。
open()函数
open()函数的功能是打开或创建一个文件,该函数存在于系统函数库fcntl.h中,其函数声明如下:
int open(const char *pathname,int flags,[mode_t mode]);
| 宏 | 说明 |
|---|---|
| O_RDONLY | 以只读方式打开文件 |
| O_WRONLY | 以只写方式打开文件 |
| O_RDWR | 以读写方式打开文件 |
| O_CREAT | 创建一个文件并打开,若文件已存在则会出错 |
| O_EXCL | 测试文件是否存在,若不存在,则创建文件 |
| O_NOCTTY | 若pathname为终端设备,则不会将该设备分配给对应进程作为控制终端 |
| O_TRUNC | 当以只写或读写方式成功打开文件时,将文件长度截断为0 |
| O_APPEND | 以追加的方式打开文件 |
| mode | 说明 |
|---|---|
| S_IRWXU | 文件所有者对文件具有读、写与执行权限 |
| S_IRUSR | 文件所有者对文件具有读权限 |
| S_IWUSR | 文件所有者对文件具有写权限 |
| S_IXUSR | 文件所有者对文件具有执行权限 |
| S_IRWXG | 文件所属组对该文件有读、写与执行权限 |
| S_IRGRP | 文件所属组对该文件有读权限 |
| S_IWGRP | 文件所属组对该文件有写权限 |
| S_IXGRP | 文件所属组对该文件有执行权限 |
| S_IRWXO | 其他人对该文件有读、写与执行权限 |
| S_IROTH | 其他人对该文件有读权限 |
| S_IWOTH | 其他人对该文件有写权限 |
| S_IXOTH | 其他人对该文件有执行权限 |
read()函数
read函数用于从已打开的设备或文件中读取数据,该函数存在于函数库unistd.h中,其函数声明如下:
ssize_t read(int fd, void *buf, size_t count);
参数列表:
- fd为从open()或creat()函数获取的文件描述符
- buf为缓冲区
- count为计划读取的字节数
write()函数
write()函数用于向已打开的设备或文件中写入数据,该函数存在于函数库unistd.h中,其函数声明如下:
ssize_t write(int fd, const void *buf, size_t count);
参数列表:
-
fd为文件描述符
-
buf为需要输出的缓冲区
-
count为最大输出字节数。
lseek()函数
每个打开的文件都有一个当前文件偏移量(current file offset),该数值是一个非负整数,表示当前文件的读写位置,Linux系统中可以通过系统调用lseek()对该数值进行修改,lseek()函数位于函数库unistd.h中,其函数声明如下:
off_t lseek(int fd, off_t offset, int whence);
参数列表:
-
fd为文件描述符
-
offset用于对文件偏移量的设置,该参数值可正可负
-
whence用于控制设置当前文件偏移量的方法
close()函数
打开的文件在操作结束后应该主动关闭,Linux系统调用中用于关闭文件的函数为close()函数,该函数的使用方法很简单,只要在函数中传入文件描述符,便可关闭文件。close()函数位于函数库unistd.h中,其声明如下:
int close(int fd);
若函数close()成功调用,则返回0,否则返回-1。
stat()函数
stat()函数用于获取文件的属性,该函数存在于函数库sys/stat.h中,其声明如下:
int stat(const char *path, struct stat *buf);
access()函数
access()函数用于测试文件是否拥有某种权限,该函数存在于库函数unistd.h中,其声明如下:
int access(const char *pathname, int mode);
Linux进程管理
多道程序设计
多道程序设计,是指计算机允许多个相互独立的程序同时进入内存,在内核的管理控制之下,相互之间穿插运行。多道程序设计必须有硬件基础作为保障。
进程对CPU的使用权是由内核分配的,内核必须知道内存中有多少个进程,并且知道此时正在使用CPU的进程,这就要求内核必须能够区分进程,并可获取进程的相关属性。
进程的属性保存在一个被称为进程控制块(Process Contral Block,简称PCB)的结构体中,内核为每个进程维护了一个进程控制块,用于管理相应进程的属性信息。 PCB的本质是一个task_struct结构体,其中包括进程控制符(Process Identifier,PID)、进程组、进程环境、进程的运行状态等。
Linux内核通过管理PCB,来调度进程。
标识符
Linux系统中进程的标识符主要有:进程标识符、父进程标识符、用户标识符和组标识符。
- 进程标识符:简称pid,是进程的唯一标识。
- 父进程标识符:简称ppid,标识该进程的父进程,即创建进程的进程所对应的pid。
- 用户标识符:简称uid,标识创建该进程的用户。此外euid标识有效用户标识符。
- 组标识符:简称gid,标识创建进程用户的所属组。Euid对应的组标识符即为egid。
进程状态
通常进程的状态被划分为五种:初始态、就绪态、运行态、睡眠态和终止态。当初始化完成后,进程会立刻转化为就绪态。
-
就绪态:处于就绪态(Ready)的进程,所需的其它资源已分配到位,此时只等待cpu,当可以使用cpu时,进程会立刻变为运行态。
-
运行态:进程处于运行态(Execting)时会占用cpu,处于此状态的进程的数目必定小于等于处理器的数目,即每个cpu上至多能运行一个进程。
-
睡眠态:处于睡眠态(Sleeping)的进程会因某种原因而暂时不能占有cpu。睡眠态分为不可中断的睡眠和可中断的睡眠。
-
终止态:处于终止态的进程已运行完毕,此时进程不会被调度,也不会再占用CPU。
寄存器
cpu中寄存器的数量是有限的,若进程p1的时间片结束,进程p2将获得cpu, cpu中的寄存器应给进程p2使用。但进程p1可能尚未执行结束,在之后的某个时间片,进程p1需重新获得cpu的使用权。因此在进程切换时,应先保存寄存器中存储的进程p1的数据,以便进程p1再次使用cpu时,能从中断的位置继续向下执行。
页表指针
当程序运行时,系统会为程序开辟一段4G大小的虚拟内存,其中0~3G的虚拟地址用于英语存放程序的代码段、数据段等信息,当虚拟内存与物理内存相映射时,各个虚拟内存中地址相同的数据,会被MMU(Memory Management Unit,内存管理单元)映射到内存中不同的物理地址,为保证内核能根据进程中的虚拟地址在物理磁盘中找到进程中所需的数据,PCB应存储虚拟地址与物理地址的对应关系。
Linux系统采用分页存储的方式管理内存:在进程装载入内存之前,系统将用户进程的逻辑地址空间分成若干个大小相等的片,这些片称为页面或页,并为各个页编号;相应地,内存空间也使用相同的方式,划分为与逻辑地址页面大小相同的块并进行编号。之后当为进程分配内存时,以块为单位,将进程中的若干个页装入多个可以不相邻的物理块中。此时逻辑地址与物理地址间应有个对应关系。Linux操作系统中使用页表来存储这个对应关系,这个页表的实质是一个结构体。
进程组与会话
打开音乐播放器播放音乐时,音乐播放、歌词显示、时间控制等多个进程都会被启动,虽然实际上用户只启动了一个进程,但用户启动的这个进程会主动启动各种实现功能所需的附加进程,此时这些进程被视为同一个进程组(process group)中的进程,进程组由用户启动的进程创建,用户启动的进程是进程组中的领导进程(process group leader)。进程组中领导进程的pid亦是识别进程组的进程组id,即pgid。
会话(session)是进程组的集合,会话中的每个进程组称为一个工作(job)。
会话由其中的进程创建,创建会话的进程称为会话的领导进程(session leader),会话领导进程的pid也是标识会话的会话id,即sid。
一个会话中一般有一个进程组工作在前台,使用终端,其余进程组工作在后台(在终端执行命令时,在命令之后添加“&”则将命令启动的进程放在后台执行)。会话的意义在于可在同一个终端执行多个进程组。
进程控制
Linux系统中对进程的控制主要包含:进程创建、进程任务转变、进程同步和退出进程,Linux提供了一些与进程控制相关的接口,常用的接口为:fork()、exec函数族、wait()、exit()等。
fork()
Linux使用fork()函数创建进程。fork函数是Linux多任务系统实现的基础,它包含在函数库unistd.h中,其函数声明如下:
pid_t fork(void);
调用fork()函数创建的进程称为子进程,调用fork()函数的进程为父进程。调用fork()函数后,系统会创建一个与原进程近乎相同的进程,之后父子进程都继续往下执行。
exec函数族
使用fork()函数创建的子进程,其中包含的程序代码完全相同,只是能根据fork()函数的返回值,执行不同的代码分支。
而是由exec函数族中的函数,则可以根据指定的文件名或路径,找到可执行文件,用该文件取代调用该函数的进程中的程序,再从该文件的main()函数开始,执行文件的内容。
在程序中fork()函数和exec函数族后进程与其中数据的变化情况如图所示。

exec函数族中包含6个函数,分别为:execl()、execlp()、execle()、execv()、execvp()、execve(),它们包含在系统库unistd.h中,函数声明分别如下:
int execl(const char *path, const char *arg, ...);
int execlp(const char *file, const char *arg, ...);
int execle(const char *path, const char *arg, ..., char * const envp[]);
int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);
int execve(const char *path, char *const argv[], char *const envp[]);
exit()
Linux系统中进程的退出通过exit()函数实现。exit()函数存在于系统函数库stdlib.h中,其函数声明如下:
void exit(int status);
其中参数status表示进程的退出状态,0表示正常退出,非零表示异常退出。标准C中定义了两个宏:EXIT_SUCCESS和EXIT_FAILURE,分别表示正常退出和非正常退出。
Linux系统中有一个与exit()函数非常相似的函数——_exit(),_exit()函数定义在unistd.h中,其函数声明如下:
void _exit(int status);
进程同步
我们把异步环境下的一组并发进程,因相互制约而互相发送消息、进行互相合作、互相等待,使得各进程按一定的速度执行的过程称为进程间的同步。
使用sleep()函数使父进程阻塞等待子进程执行,控制进程间的执行顺序,只是一种权宜之计,在实际应用中,很难使用这种方法在保证效率的前提下,精确地实现进程同步。
Linux系统中提供了wait()函数和waitpid()函数,来获取进程状态,实现进程同步。
wait()函数
wait()存在于系统库函数sys/wait.h中,函数声明如下:
pid_t wait(int *status);
调用wait()函数的进程会被挂起,进入阻塞状态,直到捕获到子进程的退出信息,wait()函数才会返回。
函数中的参数status是一个int*类型的指针,它用来保存子进程退出时的状态信息,一般将该参数设为NULL。
若wait()调用成功,wait()会返回子进程的进程ID;若调用失败,wait()返回-1,errno被设置为ECHILD。
若status不为空,wait()函数会获取子进程的退出状态保存在参数status的低8位中。Linux系统中定义了一组用于判断进程退出状态的宏函数,其中最基础的是WIFEXITED()和WEXITSTATUS(),它们的参数也是一个整型的status。宏函数的功能分别如下:
-
WIFEXITED(status):用于判断子程序是否正常退出,若是,则返回非零值;否则返回0。
-
WEXITSTATUS(status):WEXITSTATUS()通常与WIFEXITED()结合使用,若WIFEXITED返回非零值,即正常退出时,使用该宏可以提取出子进程的返回值。
waitpid()函数
waitpid()函数同样位于系统函数库sys/wait.h中,它的函数声明如下:
pid_t waitpid(pid_t pid,int *status,int options);
参数pid一般是进程的pid,但也会有其它取值。参数pid的取值及其意义分别如下:
- pid>0时,只等待pid与该参数相同的子进程,若该子进程退出,waitpid()函数就会返回;若该子进程仍未结束,waitpid()函数一直等待该进程;
- pid=-1时,waitpid()函数与wait()函数作用相同,将阻塞等待并回收一个子进程;
- pid=0时,等待同一个进程组的所有子进程,若子进程加入了其它进程组,waitpid()将不再关心它的状态;
- pid<-1时,等待指定进程组中的任何子进程,进程组的id等于pid的绝对值。
参数options提供控制waitpid()的选项,该选项是一个常量,或由“|”连接的两个常量。该选项支持的选项如下:
-
WNOHANG。即使子进程没有终止,waitpid()也会立即返回,即不会使父进程阻塞。
-
WUNTRACED。如果子进程暂停执行,则waitpid()立刻返回。
另外若不想使用该参数,可以将其值设置为0。
waitpid()函数可以等待指定的子进程,也可以在父进程不阻塞的情况下获取子进程状态,相对于wait()来说,它的使用更为灵活。
进程管理命令
ps
查看当前系统中正在运行的进程(单词:Process Status)
命令格式: ps [选项] [参数]
ps命令BSD风格的常用选项:
| 选项 | 说明 |
|---|---|
| a | 显示当前终端机下的所有进程,包括其它用户启动的进程 |
| u | 以用户的形式,显示系统中的进程 |
| x | 忽视终端机,显示所有进程 |
| e | 显示每个进程使用的环境变量 |
| r | 只列出当前终端机中正在执行的进程 |
ps命令SysV风格的常用选项:
| 选项 | 说明 |
|---|---|
| -a | 显示所有终端机中除阶段作业领导之外的进程 |
| -e | 显示所有进程 |
| -f | 除默认显示外,显示UID、PPID、C、STIME项 |
| -o | 指定显示哪些字段,字段名可以使用长格式,也可以使用“%字符”的短格式指定,多个字段名使用逗号分割 |
| -l | 使用详细的格式显示进程信息,等同于BSD风格的选项l |
top
显示执行命令那一刻系统中进程的相关信息
命令格式:top [选项]
top命令可以实时观察系统的整体运行情况,默认时间间隔为3秒,即每3秒更新一次页面,类似Windows系统中的任务管理器,是一个很实用的系统性能监测工具。
| 热键 | 说明 |
|---|---|
| l | 控制是否显示平均负载和启动时间(第1行) |
| t | 控制是否显示进程统计信息和cpu状态信息(第2、3行) |
| m | 控制是否显示内存信息(第4、5行) |
| M | 根据常驻内存集RES大小为进程排序 |
| P | 根据%CPU为进程排序 |
| T | 根据TIME+为进程排序 |
| r | 重置一个进程的优先级 |
| i | 忽略闲置和僵死的进程 |
| k | 终止一个进程 |
pstree
以树状图的形式显示系统中的进程
命令格式:pstree [选项]
| 选项 | 说明 |
|---|---|
| -a | 显示每个进程的完整命令(包括路径、参数等) |
| -c | 不使用精简标识法 |
| -h | 列出树状图,特别标明当前正在执行的进程 |
| -u | 显示用户名称 |
| -n | 使用程序识别码排序(默认以程序名称排序) |
pgrep
根据进程名从进程队列中查找进程,查找成功后默认显示进程的pid
命令格式:pgrep [选项] [参数]
| 选项 | 说明 |
|---|---|
| -o | 仅显示同名进程中pid最小的进程 |
| -n | 仅显示同名进程中pid最大的进程 |
| -p | 指定进程父进程的pid |
| -t | 指定开启进程的终端 |
| -u | 指定进程的有效用户id |
nice
设置Linux系统中进程的nice值
命令格式:nice [选项] [参数]
nice选项常用的选项为-n,n表示优先级,是一个整数。
bg和fg
Linux系统中可以使用bg命令和fg命令,使进程在前台和后台之间进行切换。
bg
将进程放入后台运行,使前台可以执行其它任务。
命令格式:bg 参数
fg
将后台的进程调往前台。
命令格式:fg 作业号
job
使用jobs命令可以查看Linux系统中的作业列表及作业状态,进程中的作业也有编号,编号从1开始。Linux系统中作业从用户角度进行编号,进程从系统管理员的角度进行编号。
命令格式:jobs [选项] [参数]
当选项和参数缺省时,默认显示作业编号、作业状态和启动作业的命令。
| 选项 | 说明 |
|---|---|
| -l | 显示进程号 |
| -p | 仅显示作业对应的进程号 |
| -n | 显示作业状态的变化 |
| -r | 仅显示运行状态的任务 |
| -s | 仅显示停止状态的任务 |
kill
kill命令用来终止正在运行的进程,它的工作原理是发送某个信号到指定进程,以终止该进程。
命令格式:kill [选项] [参数]















 4659
4659

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









