







1、M3DB介绍
Uber 之前开源了已在内部使用多年的指标平台 —— M3 ,这是一个基于分布式时序数据库 M3DB 构建的度量平台,可每秒聚合 5 亿个指标,并且以每秒 2000 万笔的速度持续存储这些结果。

Uber 表示,为促进在全球的运营发展,他们需要能够在任何特定时间快速存储和访问后端系统上的数十亿个指标。一直到 2014 年底,Uber 的所有服务、基础设施和服务器都是将指标发送到基于 Graphite 的系统中,该系统将这些资料以 Whisper 档案格式储存到分片 Carbon 丛集。此外,还将 Grafana 用于仪表板,Nagios 用于告警,并通过来源控制脚本发出 Graphite 阈值检查。但由于扩展 Carbon 集群需要手动重新分片的过程,并且由于缺乏副本,任何单一节点的磁盘故障都会导致其相关指标的永久性丢失。简而言之,随着公司的不断发展,这种解决方案无法再满足其需求。
在评估现有的解决方案后,Uber 没有找到能够满足其资源效率或规模目标,并能够作为自助服务平台运行的开源替代方案。因此在 2015 年,M3 诞生。起初,M3 几乎全部采用完全开源的组件来完成基本角色,像是用于聚合的 statsite ,用于时序存储具备 Date Tiered Compaction Strategy 的 Cassandra ,以及用于索引的 ElasticSearch 。基于运营负担,成本效率和不断增长的功能集考虑,M3 逐渐形成自己的组件,功能也超越原本使用的方案。
M3 目前拥有超过 66 亿条时序数据,每秒聚合5亿个指标,并在全球范围内每秒持续存储 2000 万个指标(使用 M3DB),批量写入将每个指标持久保存到不同区域的三个副本中。它还允许工程师编写度量策略,以不同的时间长度和不同粒度对资料进行保存。这使得工程师和数据科学家能以不同的留存规则,精细和智能地存储有不同保留需求的时序数据。
在 Uber,由于很多团队在广泛使用 Prometheus ,如何很好地搭配使用是很重要的事。通过一个 sidecar 组件 M3 Coordinator ,M3 集成了 Prometheus 。该组件会向本地区域的 M3DB 实例写入数据,并将查询扩展至“区域间协调器”(inter-regional coordinator)。
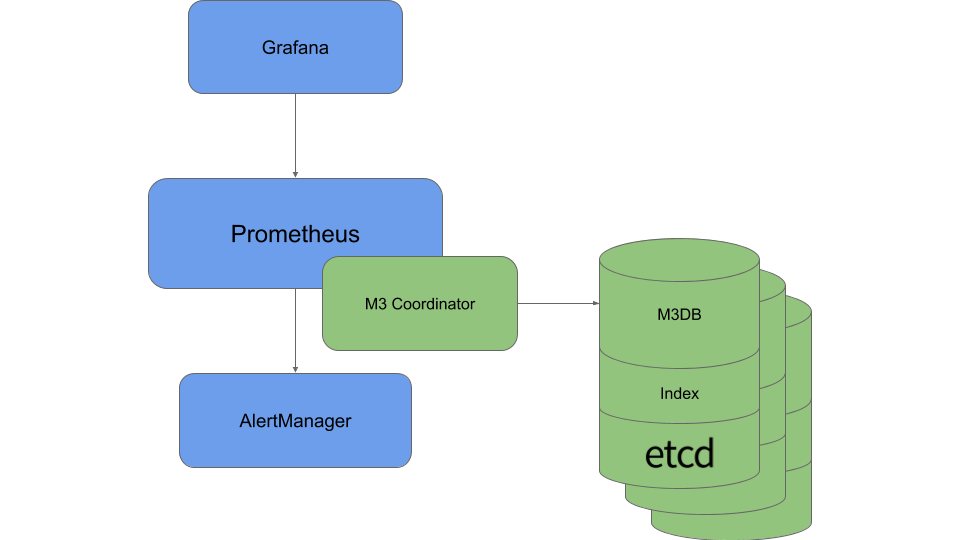
基于 Uber 日益增长的度量存储工作负载的经验,M3 具备以下特性:
- 优化指标管道的每个部分,为工程师提供尽可能多的存储空间,以实现最少的硬件支出成本。
- 通过自定义压缩算法 M3TSZ 确保数据尽可能高度压缩以减少硬件占用空间。
- 由于多数数据资料为“一次写入,永不读取”,尽量保持精简的内存占用空间以避免内存成为瓶颈。
- 尽可能避免压缩整理,通过缩小采样,以增加主机资源的利用率,从而实现更多并发写入,并提供稳定的写入/读取延迟。
- 时序数据采用本地存储,无需时刻警惕高写入量操作。
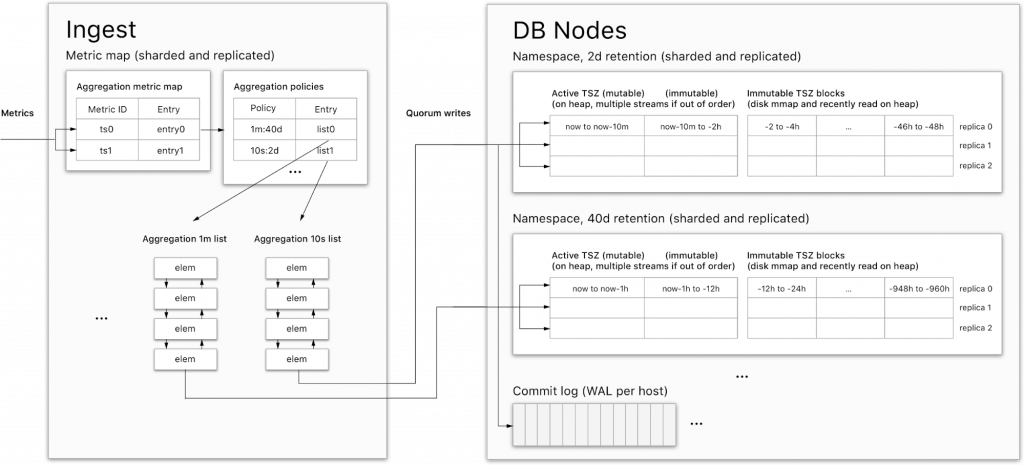
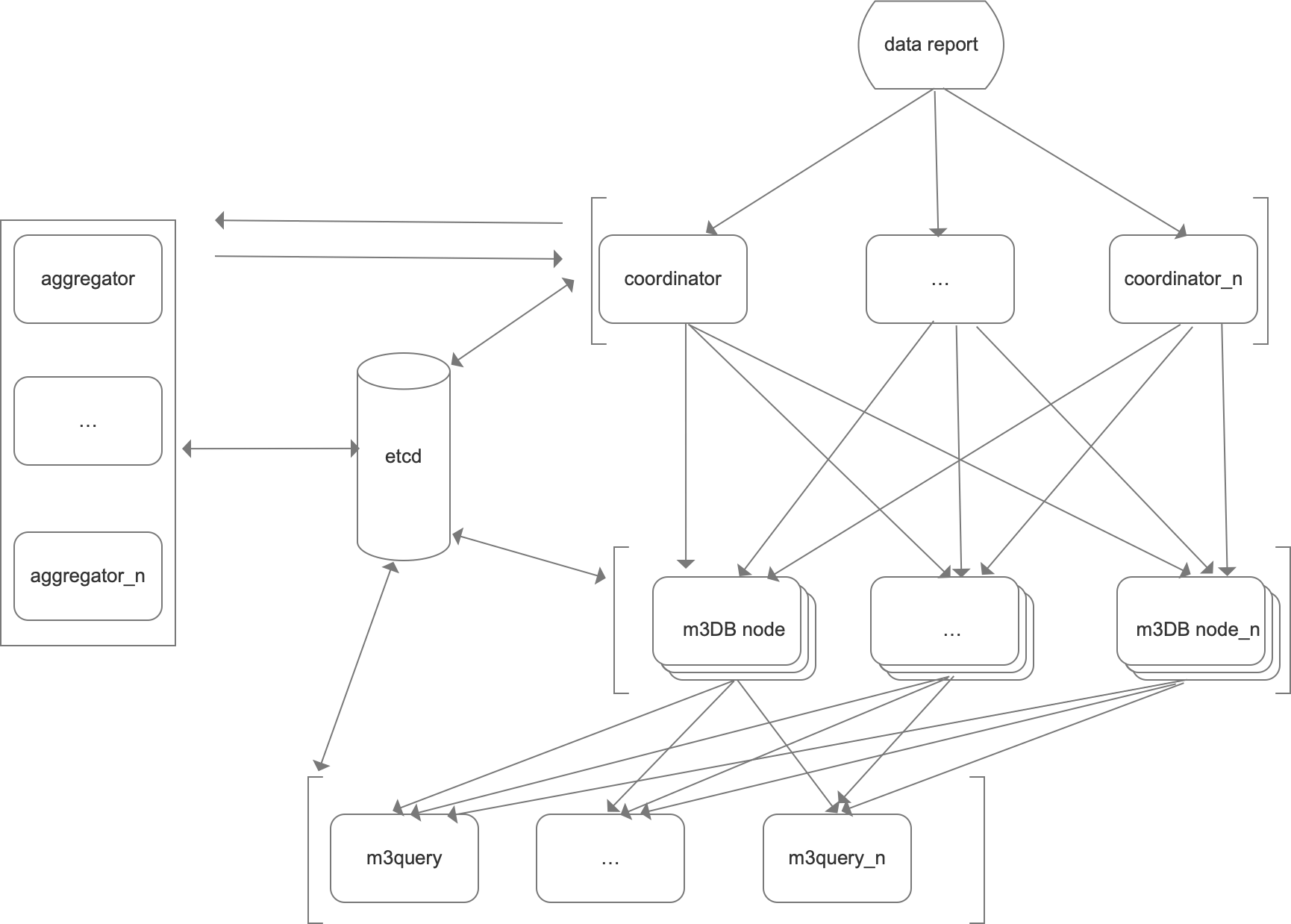
2、M3 DBNode 分布式安装(外置etcd)
1、https://github.com/m3db/m3/releases/tag/v1.1.0 下载安装包
2、准备机器,因为本次为集群安装,我准备了3个节点,来进行安装节点如下
| hostname | ip |
|---|---|
| Bs-bd-develop-003 | 10.0.100.187 |
| Bs-bd-develop-004 | 10.0.100.189 |
| Bs-bd-develop-005 | 10.0.100.188 |
3、解压压缩包
tar -zxvf m3_1.1.0_linux_amd64.tar.gz -C /opt/apps/
4、修改文件夹名称
mv m3_1.1.0_linux_amd64/ m3db
5、建立相关目录
mkdir m3kv
chmod 777 m3kv
mkdir data
6、创建m3dbnode配置文件
touch m3dbnode-cluster.yml
配置文件解析
# 如果要启用嵌入式M3Coordinator实例,请包括此字段,如果你有外置的coordinator,请干掉这个coordinator 和listenAddress
coordinator:
# M3Coordinator 监听端口
listenAddress: 0.0.0.0:7201
# M3Coordinator的日志配置
logging:
level: info
# M3Coordinator 自身性能监控
metrics:
scope:
# 应用在性能监控中所有指标的前缀
prefix: "coordinator"
prometheus:
# 暴露Prometheus scrape端点的路径和地址。
handlerPath: /metrics
listenAddress: 0.0.0.0:7203
sanitization: prometheus
# 抽样率指标,使用1.0为无抽样。
samplingRate: 1.0
extended: none
tagOptions:
# 用于从标记生成度量ID的配置设置。
idScheme: quoted
db:
# 日志级别
logging:
level: info
# M3DB metrics 性能监控配置.
metrics:
prometheus:
# 暴露Prometheus scrape端点的路径和地址。
handlerPath: /metrics
sanitization: prometheus
# 抽样率指标,使用1.0为无抽样。
samplingRate: 1.0
extended: detailed
# 侦听本地thrift/tchannel API的地址。
listenAddress: 0.0.0.0:9000
# 侦听本地thrift/tchannel API的地址。
clusterListenAddress: 0.0.0.0:9001
# 要侦听本地 json/http api 的地址(主要用于调试)。
httpNodeListenAddress: 0.0.0.0:9002
# 要侦听本地 json/http api 的地址(主要用于调试)。
httpClusterListenAddress: 0.0.0.0:9003
# 要侦听本地 debug api 的地址(主要用于debug)。
debugListenAddress: 0.0.0.0:9004
# 用于解析实例主机 ID 的配置。
hostID:
# 如果配置为config的话那么就从该value值下解析主机,如果配置为hostname的话,会获取当前主机名称为value
resolver: config
value: hostname
client:
# 写一致性等级
writeConsistencyLevel: majority
# 读一致性等级
readConsistencyLevel: unstrict_majority
# 写超时时间
writeTimeout: 10s
# 读超时时间
fetchTimeout: 15s
# 与集群的链接超时时间
connectTimeout: 20s
# 重试写入的配置。
writeRetry:
initialBackoff: 500ms
backoffFactor: 3
maxRetries: 2
jitter: true
# Configuration for retrying reads.
fetchRetry:
initialBackoff: 500ms
backoffFactor: 2
maxRetries: 3
jitter: true
# 在此之前,节点的后台健康检查可能失败的次数
# 考虑到节点不健康的检查
backgroundHealthCheckFailLimit: 4
backgroundHealthCheckFailThrottleFactor: 0.5
# go gc 配置
gcPercentage: 100
# 是否异步创建新的series(建议这么做。可以提高吞吐量)
writeNewSeriesAsync: true
writeNewSeriesBackoffDuration: 2ms
bootstrap:
commitlog:
# 已损坏的提交日志的末尾是否导致引导程序出错。
returnUnfulfilledForCorruptCommitLogFiles: false
cache:
# 数据库块的缓存策略。
series:
policy: lru
commitlog:
# 刷新commitlog之前缓冲的最大字节数。
flushMaxBytes: 524288
# 在刷新提交日志之前,可以保持缓冲的最大时间数据量。
flushEvery: 1s
# # 配置提交日志队列。高吞吐量设置可能要求更高的值。当然,更高的值将使用更多的内存。
queue:
calculationType: fixed
size: 2097152
filesystem:
# 存储M3DB数据的目录,尽量找大磁盘
filePathPrefix: /var/lib/m3db
# 用于 M3DB i/o 的各种固定大小的缓冲区。
writeBufferSize: 65536
dataReadBufferSize: 65536
infoReadBufferSize: 128
seekReadBufferSize: 4096
# 像flushing 这样的后台操作可以写入磁盘的最大速率和快照写入速率,以防止干扰正常的提交日志,如果底层磁盘比较好,那么可以增加一些,可以提高一些吞吐量
throughputLimitMbps: 1000.0
throughputCheckEvery: 128
# 这个功能当前不支持,请不要开启
repair:
enabled: false
throttle: 2m
checkInterval: 1m
# etcd 配置
discovery:
config:
service:
# KV 环境 zone 和 service。从etcd当中读取kv数据。请保留这些默认配置,除非你知道你在做什么
env: default_env
zone: embedded
service: m3db
# 存储kv的地址
cacheDir: /var/lib/m3kv
# etcd集群配置
etcdClusters:
- zone: embedded
endpoints:
- 127.0.0.1:2379
# 只有在运行具有嵌入式 etcd 的 M3DB 集群时才应该存在。也就是说用外部etcd的时候请删除该配置
seedNodes:
initialCluster:
- hostID: m3db_local
endpoint: http://127.0.0.1:2380
我们要修改的如下,其他请根据自身情况酌情修改:
-
seedNodes 嵌入式etcd需要的配置
-
etcdClusters etcd集群配置
-
filePathPrefix 存储数据目录
-
cacheDir kv缓存目录
最终配置文件为:
# Include this field if you want to enable an embedded M3Coordinator instance.
logging:
level: debug
# Configuration for emitting M3DB metrics.
metrics:
prometheus:
# Path to expose Prometheus scrape endpoint.
handlerPath: /metrics
sanitization: prometheus
# Sampling rate for metrics, use 1.0 for no sampling.
samplingRate: 1.0
extended: detailed
# Address to listen on for local thrift/tchannel APIs.
listenAddress: 0.0.0.0:9000
# Address to listen on for cluster thrift/tchannel APIs.
clusterListenAddress: 0.0.0.0:9001
httpNodeListenAddress: 0.0.0.0:9002
httpClusterListenAddress: 0.0.0.0:9003
# Address to listen on for debug APIs (pprof, etc).
debugListenAddress: 0.0.0.0:9004
# Configuration for resolving the instances host ID.
hostID:
# "Config" resolver states that the host ID will be resolved from this file.
resolver: hostname
client:
# Consistency level for writes.
writeConsistencyLevel: majority
# Consistency level for reads.
readConsistencyLevel: unstrict_majority
# Timeout for writes.
writeTimeout: 10s
# Timeout for reads.
fetchTimeout: 15s
# Timeout for establishing a connection to the cluster.
connectTimeout: 20s
# Configuration for retrying writes.
writeRetry:
initialBackoff: 500ms
backoffFactor: 3
maxRetries: 2
jitter: true
# Configuration for retrying reads.
fetchRetry:
initialBackoff: 500ms
backoffFactor: 2
maxRetries: 3
jitter: true
backgroundHealthCheckFailLimit: 4
# Sets GOGC value.
# Whether new series should be created asynchronously (recommended value
# of true for high throughput.)
writeNewSeriesAsync: true
writeNewSeriesBackoffDuration: 2ms
bootstrap:
commitlog:
# Whether tail end of corrupted commit logs cause an error on bootstrap.
returnUnfulfilledForCorruptCommitLogFiles: false
cache:
# Caching policy for database blocks.
series:
flushMaxBytes: 52428800
flushEvery: 1s
# values. Higher values will use more memory.
queue:
calculationType: fixed
size: 20971520
filesystem:
# Directory to store M3DB data in.
filePathPrefix: /data/local/m3db/data
# Various fixed-sized buffers used for M3DB I/O.
throughputCheckEvery: 128
# This feature is currently not working, do not enable.
repair:
enabled: false
throttle: 2m
checkInterval: 1m
# etcd configuration.
discovery:
config:
service:
# KV environment, zone, and service from which to write/read KV data (placement
# and configuration). Leave these as the default values unless you know what
# you're doing.
env: default_env
zone: embedded
service: m3db
# Directory to store cached etcd data in.
cacheDir: /bs/running/m3db/m3kv
# Configuration to identify the etcd hosts this node should connect to.
etcdClusters:
- zone: embedded
endpoints:
- 10.0.100.185:2379
- 10.0.100.190:2379
- 10.0.100.191:2379
7、创建启动脚本
nohup m3_1.1.0_linux_amd64/m3dbnode -f m3dbnode-cluster.yml &
8、同步m3db 文件夹
9、依次启动m3db
3、M3 Coordinator 安装
1、机器规划
| Hostname | Ip |
|---|---|
| bs-bd-develop-002 | 10.0.100.185 |
| bs-bd-develop-007 | 10.0.100.190 |
| bs-bd-develop-006 | 10.0.100.191 |
2、解压压缩包
3、coordinator配置文件
logging:
level: info
clusters:
- namespaces:
- namespace: default
retention: 48h
type: unaggregated
- namespace: agg
retention: 168h
type: aggregated
resolution: 10s
- namespace: agg_1m_168h
retention: 168h
type: aggregated
resolution: 1m
- namespace: agg_1h_168h
retention: 168h
type: aggregated
resolution: 1h
client:
config:
service:
env: default_env
zone: embedded
service: m3db
cacheDir: /bs/running/m3db/m3kv
etcdClusters:
- zone: embedded
endpoints:
- 10.0.100.185:2379
- 10.0.100.190:2379
- 10.0.100.191:2379
writeConsistencyLevel: majority
readConsistencyLevel: unstrict_majority
downsample:
remoteAggregator:
client:
type: m3msg
m3msg:
producer:
writer:
topicName: aggregator_ingest
topicServiceOverride:
zone: embedded
environment: namespace/m3db-cluster-name
placement:
isStaged: true
placementServiceOverride:
namespaces:
placement: /placement
connection:
numConnections: 4
messagePool:
size: 16384
watermark:
low: 0.2
high: 0.5
ingest:
ingester:
workerPoolSize: 10000
opPool:
size: 10000
retry:
maxRetries: 3
jitter: true
logSampleRate: 0.01
m3msg:
server:
listenAddress: "0.0.0.0:7507"
retry:
maxBackoff: 10s
jitter: true
4、依次启动coordinator
./m3coordinator -f conf/m3coordinator-cluster.yml
4、NameSpace配置
1、创建placement
curl -X POST 10.0.100.185:7201/api/v1/services/m3db/placement/init -d '{
"num_shards": "64",
"replication_factor": "1",
"instances": [
{
"id": "bs-bd-develop-003",
"isolation_group": "bizseer-m3-1",
"zone": "embedded",
"weight": 100,
"endpoint": "10.0.100.187:9000",
"hostname": "bs-bd-develop-003",
"port": 9000
},
{
"id": "bs-bd-develop-004",
"isolation_group": "bizseer-m3-2",
"zone": "embedded",
"weight": 100,
"endpoint": "10.0.100.189:9000",
"hostname": "bs-bd-develop-004",
"port": 9000
},
{
"id": "bs-bd-develop-005",
"isolation_group": "bizseer-m3-3",
"zone": "embedded",
"weight": 100,
"endpoint": "10.0.100.188:9000",
"hostname": "bs-bd-develop-005",
"port": 9000
}
]
}'
2、创建namespace
curl -X POST http://10.0.100.185:7201/api/v1/services/m3db/namespace -d '{
"name": "default",
"options": {
"bootstrapEnabled": true,
"flushEnabled": true,
"writesToCommitLog": true,
"cleanupEnabled": true,
"snapshotEnabled": true,
"repairEnabled": false,
"retentionOptions": {
"retentionPeriodDuration": "168h",
"blockSizeDuration": "2h",
"bufferFutureDuration": "10m",
"bufferPastDuration": "10m",
"blockDataExpiry": true,
"blockDataExpiryAfterNotAccessPeriodNanos": "300000000000"
},
"indexOptions": {
"enabled": true,
"blockSizeDuration": "2h"
},
"aggregationOptions": {
"aggregations": [
{
"aggregated": false,
"attributes": { "resolutionDuration": "10s" }
}
]
}
}
}'
curl -X POST http://10.0.100.185:7201/api/v1/services/m3db/namespace -d '{
"name": "agg",
"options": {
"bootstrapEnabled": true,
"flushEnabled": true,
"writesToCommitLog": true,
"cleanupEnabled": true,
"snapshotEnabled": true,
"repairEnabled": false,
"retentionOptions": {
"retentionPeriodDuration": "168h",
"blockSizeDuration": "2h",
"bufferFutureDuration": "10m",
"bufferPastDuration": "10m",
"blockDataExpiry": true,
"blockDataExpiryAfterNotAccessPeriodNanos": "300000000000"
},
"indexOptions": {
"enabled": true,
"blockSizeDuration": "2h"
},
"aggregationOptions": {
"aggregations": [
{
"aggregated": true,
"attributes": { "resolutionDuration": "10s" }
}
]
}
}
}'
3、ready操作
curl -X POST http://10.0.100.185:7201/api/v1/services/m3db/namespace/ready -d '{
"name": "default"
}'
curl -X POST http://10.0.100.185:7201/api/v1/services/m3db/namespace/ready -d '{
"name": "agg"
}'
5、M3 Agg 安装

1、初始化聚合器拓扑
curl -vvvsSf -H "Cluster-Environment-Name: namespace/m3db-cluster-name" -X POST http://10.0.100.185:7201/api/v1/services/m3aggregator/placement/init -d '{
"instances": [
{
"endpoint": "10.0.100.185:6000",
"zone": "embedded",
"weight": 100,
"hostname": "bs-bd-develop-002",
"port": 6000,
"isolation_group": "bs-agg-1",
"id": "bs-bd-develop-002"
},
{
"endpoint": "10.0.100.190:6000",
"zone": "embedded",
"weight": 100,
"hostname": "bs-bd-develop-007",
"port": 6000,
"isolation_group": "bs-agg-2",
"id": "bs-bd-develop-007"
},
{
"endpoint": "10.0.100.191:6000",
"zone": "embedded",
"weight": 100,
"hostname": "bs-bd-develop-006",
"port": 6000,
"isolation_group": "bs-agg-3",
"id": "bs-bd-develop-006"
}
],
"num_shards": 32,
"replication_factor": 1
}'
2、初始化m3msg主题,以便m3aggregator从m3coordinator接收以聚合度量
curl -vvvsSf -H "Cluster-Environment-Name: namespace/m3db-cluster-name" -H "Topic-Name: aggregator_ingest" -X POST http://10.0.100.185:7201/api/v1/topic/init -d '{
"numberOfShards": 64
}'
3、将m3aggregagtor消费者组添加到摄取主题
curl -vvvsSf -H "Cluster-Environment-Name: namespace/m3db-cluster-name" -H "Topic-Name: aggregator_ingest" -X POST http://10.0.100.185:7201/api/v1/topic -d '{
"consumerService": {
"consumptionType": "REPLICATED",
"serviceId": {
"environment": "namespace/m3db-cluster-name",
"name": "m3aggregator",
"zone": "embedded"
},
"messageTtlNanos": "300000000000"
}
}'
4、初始化m3coordinator拓扑
curl -vvvsSf -H "Cluster-Environment-Name: namespace/m3db-cluster-name" -X POST http://10.0.100.185:7201/api/v1/services/m3coordinator/placement/init -d '{
"instances": [
{
"hostname": "bs-bd-develop-006",
"endpoint": "10.0.100.191:7507",
"id": "bs-bd-develop-006",
"zone": "embedded",
"port": 7507
},
{
"hostname": "bs-bd-develop-007",
"endpoint": "10.0.100.190:7507",
"id": "bs-bd-develop-007",
"zone": "embedded",
"port": 7507
},
{
"hostname": "bs-bd-develop-002",
"endpoint": "10.0.100.185:7507",
"id": "bs-bd-develop-002",
"zone": "embedded",
"port": 7507
}
]
}'
5、将m3coordinator消费者组添加到出站主题
curl -vvvsSf -H "Cluster-Environment-Name: namespace/m3db-cluster-name" -H "Topic-Name: aggregated_metrics" -X POST http://10.0.100.185:7201/api/v1/topic -d '{
"consumerService": {
"consumptionType": "SHARED",
"serviceId": {
"environment": "namespace/m3db-cluster-name",
"name": "m3coordinator",
"zone": "embedded"
},
"messageTtlNanos": "300000000000"
}
}'
6、重启以上配置的coor并且添加以下配置
downsample:
remoteAggregator:
client:
type: m3msg
m3msg:
producer:
writer:
topicName: aggregator_ingest
topicServiceOverride:
zone: embedded
environment: namespace/m3db-cluster-name
placement:
isStaged: true
placementServiceOverride:
namespaces:
placement: /placement
connection:
numConnections: 4
messagePool:
size: 16384
watermark:
low: 0.2
high: 0.5
ingest:
ingester:
workerPoolSize: 10000
opPool:
size: 10000
retry:
maxRetries: 3
jitter: true
logSampleRate: 0.01
m3msg:
server:
listenAddress: "0.0.0.0:7507"
retry:
maxBackoff: 10s
jitter: true
7、依次在所定义的节点安装agg节点并,配置文件如下
logging:
level: info
metrics:
scope:
prefix: m3aggregator
prometheus:
onError: none
handlerPath: /metrics
listenAddress: 0.0.0.0:6002
timerType: histogram
sanitization: prometheus
samplingRate: 1.0
extended: none
m3msg:
server:
listenAddress: 0.0.0.0:6000
retry:
maxBackoff: 10s
jitter: true
consumer:
messagePool:
size: 16384
watermark:
low: 0.2
high: 0.5
http:
listenAddress: 0.0.0.0:6001
readTimeout: 60s
writeTimeout: 60s
kvClient:
etcd:
env: namespace/m3db-cluster-name
zone: embedded
service: m3aggregator
cacheDir: /bs/running/m3db/m3kv_agg
etcdClusters:
- zone: embedded
endpoints:
- 10.0.100.185:2379
- 10.0.100.190:2379
- 10.0.100.191:2379
runtimeOptions:
kvConfig:
environment: namespace/m3db-cluster-name
zone: embedded
writeValuesPerMetricLimitPerSecondKey: write-values-per-metric-limit-per-second
writeValuesPerMetricLimitPerSecond: 0
writeNewMetricLimitClusterPerSecondKey: write-new-metric-limit-cluster-per-second
writeNewMetricLimitClusterPerSecond: 0
writeNewMetricNoLimitWarmupDuration: 0
aggregator:
hostID:
resolver: hostname
instanceID:
type: host_id
verboseErrors: true
metricPrefix: ""
counterPrefix: ""
timerPrefix: ""
gaugePrefix: ""
aggregationTypes:
counterTransformFnType: empty
timerTransformFnType: suffix
gaugeTransformFnType: empty
aggregationTypesPool:
size: 1024
quantilesPool:
buckets:
- count: 256
capacity: 4
- count: 128
capacity: 8
stream:
eps: 0.001
capacity: 32
streamPool:
size: 4096
samplePool:
size: 4096
floatsPool:
buckets:
- count: 4096
capacity: 16
- count: 2048
capacity: 32
- count: 1024
capacity: 64
client:
type: m3msg
m3msg:
producer:
writer:
topicName: aggregator_ingest
topicServiceOverride:
zone: embedded
environment: namespace/m3db-cluster-name
placement:
isStaged: true
placementServiceOverride:
namespaces:
placement: /placement
messagePool:
size: 16384
watermark:
low: 0.2
high: 0.5
placementManager:
kvConfig:
namespace: /placement
environment: namespace/m3db-cluster-name
zone: embedded
placementWatcher:
key: m3aggregator
initWatchTimeout: 10s
hashType: murmur32
bufferDurationBeforeShardCutover: 10m
bufferDurationAfterShardCutoff: 10m
bufferDurationForFutureTimedMetric: 10m # Allow test to write into future.
resignTimeout: 1m
flushTimesManager:
kvConfig:
environment: namespace/m3db-cluster-name
zone: embedded
flushTimesKeyFmt: shardset/%d/flush
flushTimesPersistRetrier:
initialBackoff: 100ms
backoffFactor: 2.0
maxBackoff: 2s
maxRetries: 3
electionManager:
election:
leaderTimeout: 10s
resignTimeout: 10s
ttlSeconds: 10
serviceID:
name: m3aggregator
environment: namespace/m3db-cluster-name
zone: embedded
electionKeyFmt: shardset/%d/lock
campaignRetrier:
initialBackoff: 100ms
backoffFactor: 2.0
maxBackoff: 2s
forever: true
jitter: true
changeRetrier:
initialBackoff: 100ms
backoffFactor: 2.0
maxBackoff: 5s
forever: true
jitter: true
resignRetrier:
initialBackoff: 100ms
backoffFactor: 2.0
maxBackoff: 5s
forever: true
jitter: true
campaignStateCheckInterval: 1s
shardCutoffCheckOffset: 30s
flushManager:
checkEvery: 1s
jitterEnabled: true
maxJitters:
- flushInterval: 5s
maxJitterPercent: 1.0
- flushInterval: 10s
maxJitterPercent: 0.5
- flushInterval: 1m
maxJitterPercent: 0.5
- flushInterval: 10m
maxJitterPercent: 0.5
- flushInterval: 1h
maxJitterPercent: 0.25
numWorkersPerCPU: 0.5
flushTimesPersistEvery: 10s
maxBufferSize: 5m
forcedFlushWindowSize: 10s
flush:
handlers:
- dynamicBackend:
name: m3msg
hashType: murmur32
producer:
writer:
topicName: aggregated_metrics
topicServiceOverride:
zone: embedded
environment: namespace/m3db-cluster-name
messagePool:
size: 16384
watermark:
low: 0.2
high: 0.5
passthrough:
enabled: true
forwarding:
maxConstDelay: 5m # Need to add some buffer window, since timed metrics by default are delayed by 1min.
entryTTL: 1h
entryCheckInterval: 10m
maxTimerBatchSizePerWrite: 140
defaultStoragePolicies: []
maxNumCachedSourceSets: 2
discardNaNAggregatedValues: true
entryPool:
size: 4096
counterElemPool:
size: 4096
timerElemPool:
size: 4096
gaugeElemPool:
size: 4096
6、M3 Query安装
1、配置文件如下,安装即可
listenAddress: 0.0.0.0:7501
metrics:
prometheus:
listenAddress: 0.0.0.0:7503
samplingRate: 1.0
clusters:
- namespaces:
- namespace: default
retention: 48h
type: unaggregated
- namespace: agg
retention: 168h
type: aggregated
resolution: 10s
- namespace: agg_1m_168h
retention: 168h
type: aggregated
resolution: 1m
- namespace: agg_1h_168h
retention: 168h
type: aggregated
resolution: 1h
client:
config:
service:
env: default_env
zone: embedded
service: m3db
cacheDir: /bs/running/m3db/m3kv_query
etcdClusters:
- zone: embedded
endpoints:
- 10.0.100.185:2379
- 10.0.100.190:2379
- 10.0.100.191:2379
readConsistencyLevel: unstrict_majority
query:
defaultEngine: prometheus
7、问题
1、在namespace创建后的状态并不是ready状态 而是UNKNOW,但是agg节点是可以运行的
2、要是想多时间段聚合,需要配置多个namespace,并且配置不同的聚合时间窗口
引用:
https://www.oschina.net/news/99377/uber-open-source-m3















 881
881











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









