







 文章探讨了云原生时序数据库Lindorm的特点、优势,包括高写入吞吐和低延迟查询,以及面临的大规模写入和查询挑战。文章详细介绍了Lindorm的系统架构,包括TSProxy和TSCore组件,以及针对存储引擎和索引的优化措施。
文章探讨了云原生时序数据库Lindorm的特点、优势,包括高写入吞吐和低延迟查询,以及面临的大规模写入和查询挑战。文章详细介绍了Lindorm的系统架构,包括TSProxy和TSCore组件,以及针对存储引擎和索引的优化措施。
 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
引言
云原生时序数据库目前来看还是一个没有行业标准架构特殊数据库分支,各大云厂商都有自己的集群化实现,从谷歌的Monarch,阿里的Lindorm,腾讯的CTSDB,到垂直领域的InfluxDB IOX,TDengine,IotDB,都是各有的特点和适合的领域。终究不存在银弹,强如各大头部厂商也只是在做Trade off…
优势
- 大量活跃时间线下高写入吞吐和低延迟读取
- 允许用户使用SQL直接进行异常检测和时间序列预测算法
- 在节点扩展的过程中也能保证稳定的性能
挑战
- 海量时间线下的写入,Lindorm认为挑战在于海量时间线导致
forward index过大,占用空间大,导致查询写入过程中造成大量的内存交换。 - 海量时间线查询的高延迟,Lindorm认为挑战在于从索引中通过tags获取时间线的后的聚合过程,以及计算的过程无法很好的并行化
- 认为基于规则的度量数据分析通常无法准确识别性能问题,所以需要引入机器学习分析时序数据
- 认为现有存储与计算没有分离的TSDB存在扩容时的性能问题
系统架构
Lindorm Tsdb包含四个主要组件,其中TSProxy和TSCore允许水平扩容:
- TSProxy
- TSCore
- Lindorm ML
- Lindorm DFS

路由策略非常简洁,TSProxy负责路由请求,通过时间和serieskey两个维度路由请求,对于一个请求先基于时间判断shard group的归属,其次在一个shard group内部基于series key hash做分片。
一个用户的读写请求会拆分到多个shard上,每个TsCore管理多个shard,这可以使得一段时间内一个serieskey的所有数据位于同一个shard。在单独的shard上,数据以及其对应的索引数据首先存储在内存中,随后持久化到所有TsCore共享的DFS中。
其次TsCore扩容时可以选择创建一个新的shard group,不改变历史数据的物理分布,这样在扩容时无需迁移数据,不影响线上服务质量。当然时序的分裂要做成类似于kv的分裂也很困难,因为数据的组织格式是series key+field级别的列存,路由方式是serieskey hash,而查询的维度是time+tags,在分裂期间很难在一个引擎中支持两个哈希区间的查询,其次迁移期间索引和数据都需要拆分。

可以看到这个架构融合了shared-nothing 和 shared-storage的设计,计算与存储分离。
TsCore/TsProxy层面shared-nothing,可水平扩展提升读写性能。DFS层面shared-storage,负责提供高可用。
可以看到TsCore层面没有选择一致性算法提供高可用,而是依赖于共享存储;我个人觉得这样的做法并不是最优,因为当一个TsCore故障时立马补充一个TsCore,需要先重放没有落DFS的WAL后才能提供服务。而一致性算法中副本可以是一个状态机,切主后立即提供服务。
值得一提的是路由信息,也就是TsCore到shards的映射关系存储在ZooKeeper中,这让我有理由怀疑Lindorm集群的路由推送效率,其次ZooKeeper作为控制面也无法完成一些高级的调度策略(比如基于集群的各种指标判断是否分裂和配置项下发)。
细节/优化
存储引擎
- TSD文件和索引携带TTL,在后台压缩期间判断是否删除
- DFS中可以根据TSD的时间戳判断是否要存入更便宜的介质中(DFS由
ESSD cloud disk和Object Storage Service构成) - 无锁压缩用于内存数据,以提高内存利用率;WAL日志采用字典批量压缩,以减少IO;TSD中采用Delta-of-delta, XOR, ZigZag, RLE等常规算法压缩
索引
- 由于大量短时间序列的存在(容器的创建销毁,会议号,视频ID等),很多序列会迅速失效,所以在一个shard内部需要继续基于时间划分
time partitions,每个time partitions内部包含独立的索引。 - 当
time partitions过多时,启动采用lazy loading,优先加载最新分区,异步加载历史分区。 forward index和inverted index在memtable中写入,触发刷新时memtable中的两个索引分别生成FwdIdx和InvIdx文件- 为了加速索引的查找速度,后台合并减少文件数,其次每个文件中添加
bloom filter[1],最后使用Block Cache缓存部分文件内容 forward index访问频率远大于inverted index,写入过程中需要判断是否存在某个serieskey,查询时需要获取tsid对应的serieskey;所以引入seriescache,Block cache缓存文件数据,而seriescache缓存ID到serieskey之间的映射,采用LRU淘汰,因为serieskey较大,选择MD5替换serieskey。- 根据不同的Tag在倒排索引中获取ID List,利用RoaringBitmap做列表合并
- 考虑到历史时间序列处于非活跃状态,采用时间分区来提高内存利用率,历史shard的常驻内存适当减少
写入
- SQL引擎采用
Apache Calcite,写入采用insert语句,但是写路径通过引擎性能较差,所以实现了一个简易的写入解析器,bypass SQL引擎 - SQL prepare可以用于客户端的批量写入优化
查询
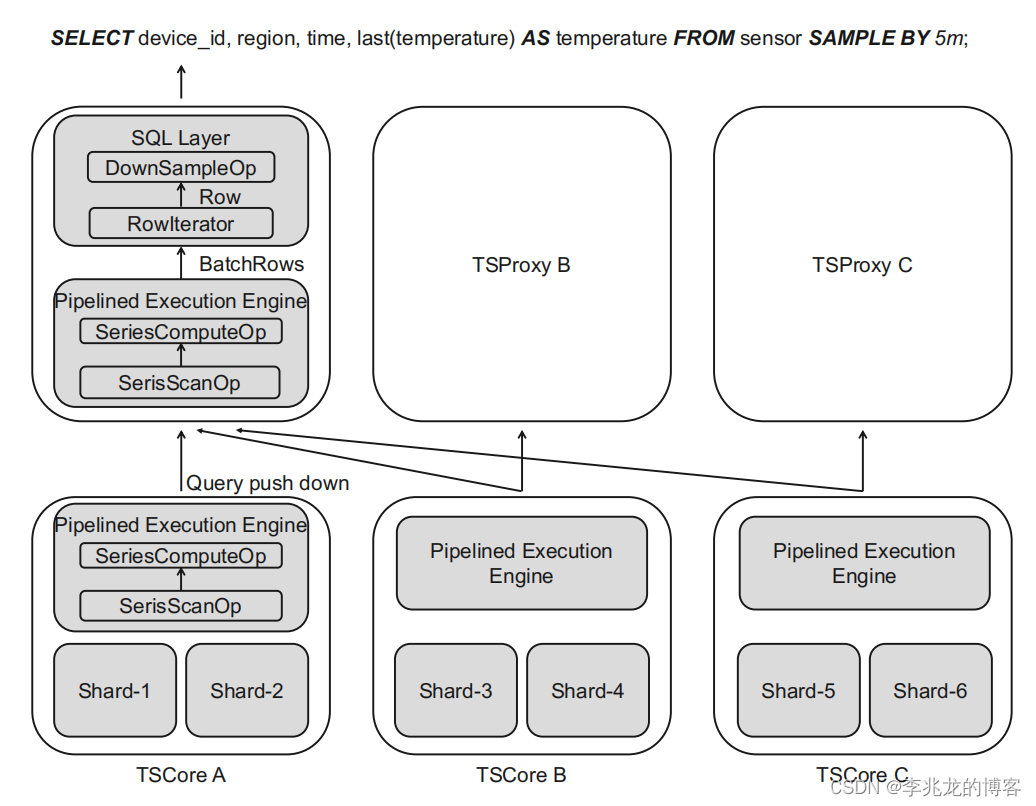
TSProxy和TsCore均实现的pipelined execution engine,支持计算下推,允许多个TsCore之间并行计算,此外一个TsCore的多个partition,一个partition的多个shard之间都可以并行计算。行迭代器驱动整个流水线引擎执行,可以在流水线中自定义时间线维度的算子,数据会流经pipeline中所有的算子,完成后释放这部分内存。- 引擎中的算子基于是否
downsampling被划分为两类;
a.downsampling: aggregation (DSAgg) , interpolation (Filling)
b.non-downsampling: rate of change (Rate) , obtaining the difference (Delta). - 预降采样,为了减小预将采样对于写入的影响,只有在memtable被下刷到共享存储和压缩时才会执行预降采样。
- 实现了跨time-series的算子(series_max?)
经验
- 节点故障很常见,新
TSCore在接管故障TSCore时需要重放完WAL才能提供服务,这可能造成服务中断,所以设计了WAL异步载入,先允许写,重放完成后允许读 - 采用图表化多字段模型,并支持SQL不但有助于用户理解,而且方便DBA解决问题
- 启动预降采样可以用8%的存储空间换取80%的查询延迟,DFS中存储分层,允许历史数据存储在对象存储,且于实时查询和连续查询相比资源消耗极低
- 没有流水线执行引擎必须一次读出所有数据,导致内存耗尽
- first/last使用频繁,这需要高qps和低延迟,为此Lindorm专门设计了一种缓存,在查询时,每个时间序列的最新值都会被缓存起来,并在该时间序列写入新数据点时进行更新,实施这种缓存后查询响应时间缩短了 85%
Ablation Study
Lindorm认为性能的关键在于两点:
- push-down optimization in the pipeline streaming execution engine
- seriescache for the forward index.
对照实验结果如下:

很好理解,没有计算下推的情况TsProxy需要计算全部的数据,第一数据传输量大,第二没有节点级别并行化

效果非常明显,写吞吐提升在23.8%到232%,而且对于where time > now() -2h group by * , time(5m)的查询时延也降低了15.3到32.2%
总结
文章中可以看出不少地方存在改进空间,但是不得不承认Lindorm TSDB可学习的地方很多,感谢Lindorm团队的无私奉献。
参考:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











