







1.理论介绍
CFS调度器(Completely Fair Scheduler)是所有普通进程所依赖的调度器,其优先级为100-139,常常用于用户程序;
此调度器实现了SCHED_NORMAL、SCHED_BATCH 、SCHED_IDLE策略,CFS的全称为完全公平的调度器,
其中cpu上的队列通过cfs_rq指向其哈希表,调度实体sched_entity通过红黑树进行组织;
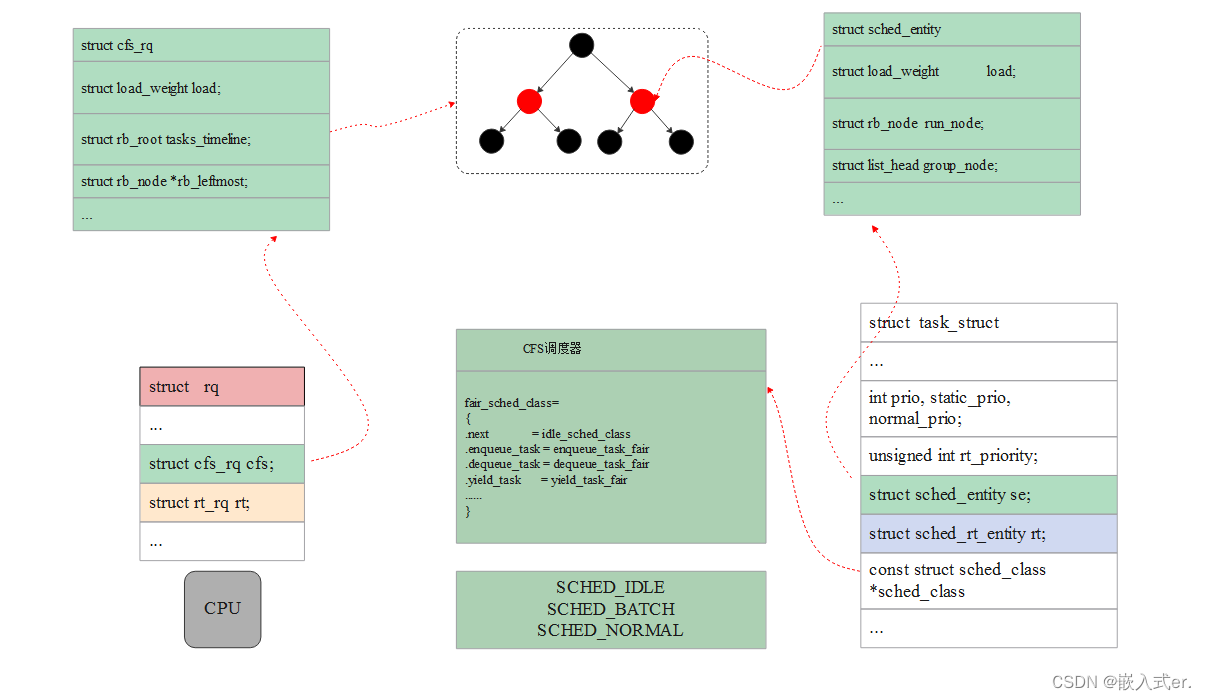
2.CFS调度器的实现
/*
* All the scheduling class methods:
*/
static const struct sched_class fair_sched_class = {
.next = &idle_sched_class,
.enqueue_task = enqueue_task_fair,
.dequeue_task = dequeue_task_fair,
.yield_task = yield_task_fair,
.yield_to_task = yield_to_task_fair,
.check_preempt_curr = check_preempt_wakeup,
.pick_next_task = pick_next_task_fair,
.put_prev_task = put_prev_task_fair,
#ifdef CONFIG_SMP
.select_task_rq = select_task_rq_fair,
.rq_online = rq_online_fair,
.rq_offline = rq_offline_fair,
.task_waking = task_waking_fair,
#endif
.set_curr_task = set_curr_task_fair,
.task_tick = task_tick_fair,
.task_fork = task_fork_fair,
.prio_changed = prio_changed_fair,
.switched_from = switched_from_fair,
.switched_to = switched_to_fair,
.get_rr_interval = get_rr_interval_fair,
#ifdef CONFIG_FAIR_GROUP_SCHED
.task_move_group = task_move_group_fair,
#endif
};
CFS调度器通过每个进程的虚拟运行时间(vruntime)来衡量哪个进程最值得被调度. CFS中的就绪队列是一棵以vruntime为键值的红黑树,虚拟时间越小的进程越靠近整个红黑树的最左端。
3.虚拟运行时间vruntime
CFS调度器的核心是虚拟运行时间vruntime。虚拟运行时间与两个参数有关:
1.进程运行时间有关
2.进程优先级有关。
总体来说,进程占用CPU时间越长,进程优先级越低,其vruntime就越大。vruntime越小,代表CPU对进程的占有越少,那么后续就需要优先执行它;反之,vruntime越大,代表CPU对进程的占有越多,那么后续就需要对它做出一定的惩罚,减少对它的执行。
CFS调度器就是要在各个进程间维持一种相对的公平,一方面不能过多占有某个进程,也不多过分欠缺某个进程,所有进程同属于一个系统,任何一个进程运行太少,都会影响整个大家庭。
所有的CFS调度器的进程以vruntime为键值加入红黑树,vruntime越小,在红黑树的位置越靠左,vruntime越大,在红黑树的位置越考右。CFS调度器从最左边的进程开始调度,进程被调度后,vruntime增加,进程因而向右移动。
进程的权重跟与优先级是一一对应的。如果没有进程优先级,那么所有进程的vruntime增加的速度是一样的,进而获得的CPU时间片也是一样的。但是有些进程确实更加重要,任务更加繁重,理应获得更多的CPU时间,所以就引入了优先级的概念,优先级越高,就越应该受到CPU的优待,也即获得更多的CPU时间。所以高优先级进程的vruntime增加的速度应该要更慢一点。Linux分给普通进程的优先级是100-139,其中100代表最高优先级,139代表最低优先级。优先级与权重的关系由下面的表定义:
内核中为了快速计算,利用数组来对应每一个优先级的权重,可以看见优先级越高,权重越大,
虚拟运行其实最终的计算公式为:vruntime = delta_exec * weight / lw.weight;
delta_exec为实际的执行时间,weight为1024固定值,对应的优先级为0,lw.weight为优先级转换出的权重信息。
可以看见权重越大,其虚拟运行时间越小,这样就可以在vruntime中体现出优先级的概念,进而进行调度。
static const int prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};
4.pick_next_task
在CFS下实际的函数指针为pick_next_task_fair,目的是获取到CFS队列的下一个需要调度的线程,其通过红黑树进行组织,
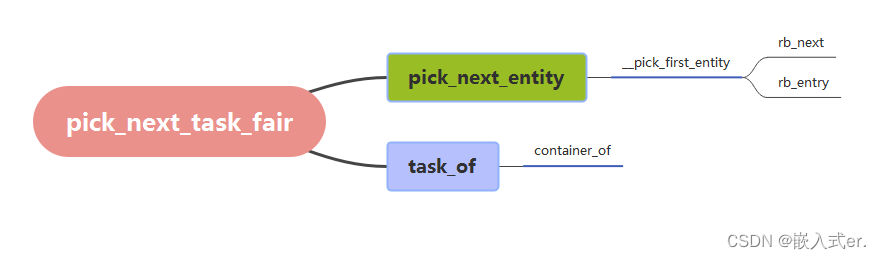
5.enqueue_task和dequeue_task
enqueue_task_fair-> enqueue_entity->__enqueue_entity
__enqueue_entity将调度实体加入到CFS运行队列红黑树中。
1、遍历红黑树,通过vruntime作为key找到调度实体插入的节点位置;
2、调用entity_before比较插入的调度实体和当前节点vruntime;
3、调度实体小于当前节点的vruntime,则红黑树向左遍历;
4、调度实体大于当前节点的vruntime,则红黑树向右遍历,同时说明调度实体不可能是最左节点;
5、需要说明的一点是红黑树左侧的调度实体总是优先被选中执行(pick_next_task_fair);
6、调度实体插入红黑树,完成入队。
dequeue_task_fair->dequeue_entity->__dequeue_entity
这个其实是进程入队列的相反操作,出队列,在红黑树中删除对应的进程实体。
6.yield_task
有时候,task在运行过程中, 只需要短暂放弃CPU,而不需要休眠,则调用,其实就是将调度实体放在skip的运行队列中。
/*
* sched_yield() is very simple
*
* The magic of dealing with the ->skip buddy is in pick_next_entity.
*/
static void yield_task_fair(struct rq *rq)
{
struct task_struct *curr = rq->curr;
struct cfs_rq *cfs_rq = task_cfs_rq(curr);
struct sched_entity *se = &curr->se;
/*
* Are we the only task in the tree?
*/
if (unlikely(rq->nr_running == 1))
return;
clear_buddies(cfs_rq, se);
if (curr->policy != SCHED_BATCH) {
update_rq_clock(rq);
/*
* Update run-time statistics of the 'current'.
*/
update_curr(cfs_rq);
}
set_skip_buddy(se);
}















 343
343











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









